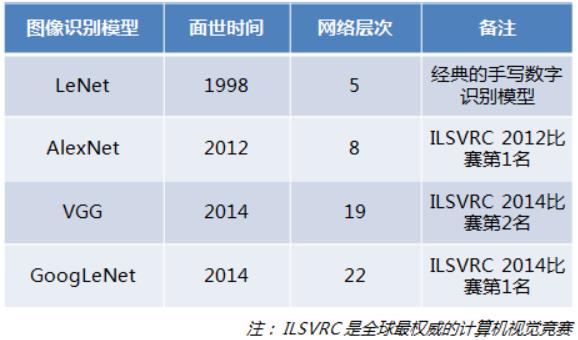
[人工智能-深度学习-32]:卷积神经网络CNN - 常见分类网络- AlexNet
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-深度学习-32]:卷积神经网络CNN - 常见分类网络- AlexNet相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120837261
目录
第1章 卷积神经网络基础
1.1 卷积神经发展与进化史

AlexNet是深度学习的起点,后续各种深度学习的网络或算法,都是源于AlexNet网络。
 https://blog.csdn.net/HiWangWenBing/article/details/120835303
https://blog.csdn.net/HiWangWenBing/article/details/1208353031.2 卷积神经网络的核心要素
1.3 卷积神经网络的描述方法
1.4 人工智能三巨头 + 华人圈名人

Yoshua Bengio、Yann LeCun、Geoffrey Hinton共同获得了2018年的图灵奖。
杰弗里·埃弗里斯特·辛顿(Geoffrey Everest Hinton),计算机学家、心理学家,被称为“神经网络之父”、“深度学习鼻祖”。Hinton是机器学习领域的加拿大首席学者,是加拿大高等研究院赞助的“神经计算和自适应感知”项目的领导者,是盖茨比计算神经科学中心的创始人,目前担任多伦多大学计算机科学系教授。2013年3月,谷歌收购 Hinton 的公司 DNNResearch 后,他便随即加入谷歌,直至目前一直在 Google Brain 中担任要职。
Yoshua Bengio是蒙特利尔大学(Université de Montréal)的终身教授,任教超过22年,是蒙特利尔大学机器学习研究所(MILA)的负责人,是CIFAR项目的负责人之一,负责神经计算和自适应感知器等方面,又是加拿大统计学习算法学会的主席,是ApSTAT技术的发起人与研发大牛。Bengio在蒙特利尔大学任教之前,是AT&T贝尔实验室 & MIT的机器学习博士后。
Yann LeCun,担任Facebook首席人工智能科学家和纽约大学教授,1987年至1988年,Yann LeCun是多伦多大学Geoffrey Hinton实验室的博士后研究员。
第2章 AlexNet概述
2.1 AlexNet的作者其人

乌克兰出生、加拿大长大的Alex Krizhevsky,是Hinton在多伦多大学计算机科学博士生,2012 年,在 Hinton 的指导下, Alex Krizhevsky 和 Hinton 的另一个学生 IIya Sutskever 参加了当年的 ImageNet 挑战赛。ImageNet 是一个大型视觉数据集,由李飞飞所主导创造,拥有 1400 多万张标注过的图像。2010 年起,基于 ImageNet 数据集的视觉识别挑战赛每年举办一次。
Alex Krizhevsky和 Sutskever用Alex Krizhevsky设计的卷积神经网络(CNN)参加比赛。两个研究深度学习没几年的学生,却以 10.8% 的巨大优势击败了其他对手,包括一些学术界的顶级团队。而Alex Krizhevsky 设计的那个神经网络,后来被命名为 AlexNet。
2.2 AlexNet概述
AlexNet网络是Hinton率领的谷歌团队(Alex Krizhevsky,Ilya Sutskever,Geoffrey E. Hinton)在2010年的ImageNet大赛获得冠军的一个神经网络。
如果用全连接神经网络处理大尺寸图像具有三个明显的缺点:
(1)首先将图像展开为一维向量会丢失空间信息;
(2)其次参数过多效率低下,训练困难、耗时;
(3)同时大量的参数也很快会导致网络过拟合。
而使用卷积神经网络可以很好地解决上面的三个问题。
AlexNet网络,是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。在那年之后,更多的更深的神经网路被提出,比如优秀的vgg,GoogleLeNet。其官方提供的数据模型,准确率达到57.1%,top 1-5 达到80.2%. 这相对于传统的机器学习分类算法而言,已经相当的出色.
论文:《ImageNet Classification with Deep Convolutional Neural Networks》
与常规神经网络不同,卷积神经网络的各层中的神经元是3维排列的:宽度、高度和深度。其中的宽度和高度是很好理解的,因为本身卷积就是一个二维模板,但是在卷积神经网络中的深度指的是卷积核神经元的第三个维度,而不是整个网络的深度,整个网络的深度指的是网络的层数。
2.3 AlexNet的特点
AlexNet中包含了几个比较新的技术点,也首次在CNN中成功应用了ReLU、Dropout和LRN等Trick。同时AlexNet也使用了GPU进行运算加速。
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。
AlexNet主要使用到的新技术点如下:
(1)ReLU的成功使用与推广
成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
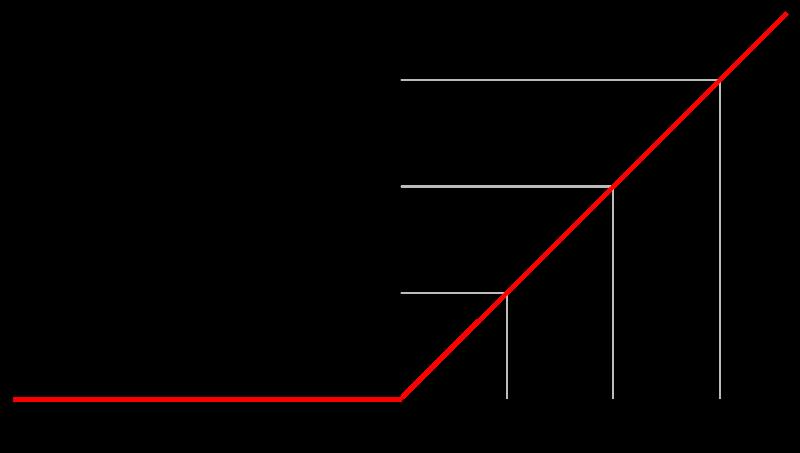
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
(2)Dropout的首次实用化
训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
深度学习架构现在变得越来越深,dropout作为一个防过拟合的手段,使用也越来越普遍。
2012年,Dropout的想法被首次提出,它的出现彻底改变了深度学习进度,之后深度学习方向(反馈模型)开始展现优势,传统的机器学习慢慢的消声。
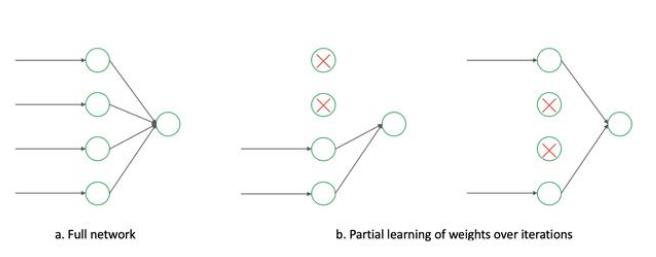
dropout改变之前稠密网络中,权重统一学习,参数统一更新的模式,提出在每次训练迭代中,让网络中的部分参数得到学习,即部分参数得到更新,部分参数保持不更新。
这种方法,看起来简单,但是却解决了,困扰了深度学习方向,一直只能用浅层网络,无法使用深度网络的尴尬局面,(因为随着网络的层数加大,过拟合问题一定会出现)
(3)首次使用最大池化
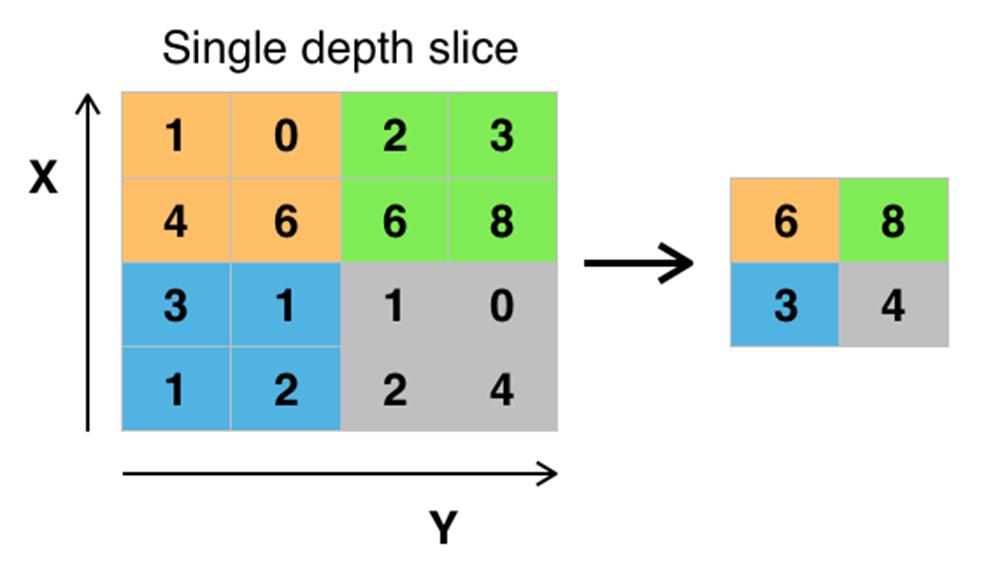
在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
常用的池化方法有最大池化(max-pooling)和均值池化(mean-pooling)。根据相关理论,特征提取的误差主要来自两个方面:
(1)邻域大小受限造成的估计值方差增大;
(2)卷积层参数误差造成估计均值的偏移。
一般来说,mean-pooling能减小第一种误差,更多的保留图像的背景信息,max-pooling能减小第二种误差,更多的保留纹理信息。与mean-pooling近似,在局部意义上,则服从max-pooling的准则。
max-pooling卷积核的大小一般是2×2。 非常大的输入量可能需要4x4。 但是,选择较大的形状会显着降低信号的尺寸,并可能导致信息过度丢失。 通常,不重叠的池化窗口表现最好。
(4)LRN(局部归一化)竞争机制
提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
LRN(Local Response Normalization) 是一种提高深度学习准确度的技术方法。 LRN 一般是在激活、 池化函数后的一种方法。
(5)GPU并行运算
使用CUDA GPU加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。
AlexNet使用了两块GTX 580 GPU进行训练,单个GTX 580只有3GB显存,这限制了可训练的网络的最大规模。因此作者将AlexNet分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。因为GPU之间通信方便,可以互相访问显存,而不需要通过主机内存,所以同时使用多块GPU也是非常高效的。同时,AlexNet的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
(6)数据增强
随机地从256*256的原始图像中截取224*224大小的区域(以及水平翻转的镜像),相当于增加了2*(256-224)^2=2048倍的数据量。
如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力,这类似人眼,人眼可以实时的、以各种角度观看和学习一个物理。进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。同时,AlexNet论文中提到了会对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%。

第3章 AlexNet网络结构阐述
3.1 网络架构描述:厚度法
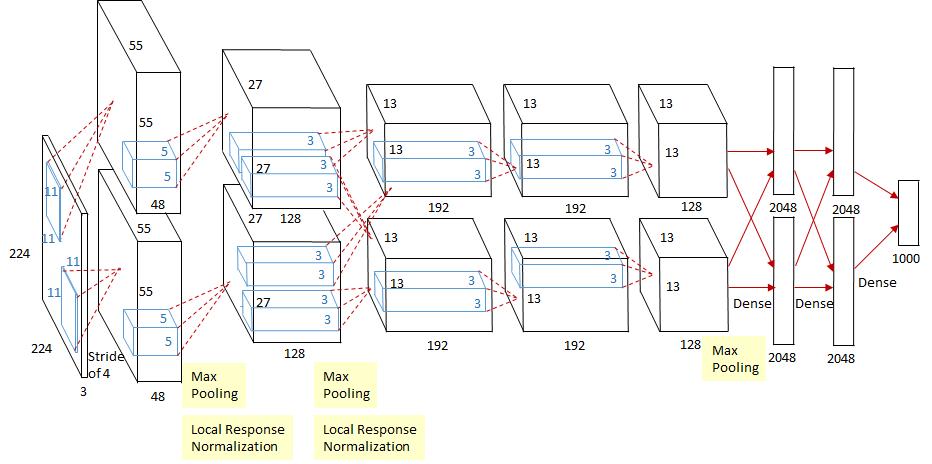
在上图中,该网络有上下两路,两路是完全相同的并行单元,之所以这样表示,而不是合成一路,是因为当时的单个GPU没有那么大的内存,AlexNet是通过两个物理的GPU同时训练。逻辑上,上下两路是可以合在一起的。
(0)输入层:
- 224 * 224 * 3的三通道图片
(1)卷积层1
- 卷积核的尺寸:11 * 11, 从目前 来看,还是偏大的。
- 卷积核的平移步长:4:目前来来看,也是偏大的
- 填充层:0, 无填充
- 卷积核的卷积输出:55 * 55
- 卷积核的个数:48 * 2 = 96
(2)卷积层2:
- 卷积核的尺寸:5 * 5,
- 卷积核的卷积输出:27 * 27
- 卷积核的个数:128 * 2 = 256
(3)卷积层3:
- 卷积核的尺寸:3 * 3,
- 卷积核的卷积输出:13 * 13
- 卷积核的个数:192 * 2 = 384
(4)卷积层4:
- 卷积核的尺寸:3 * 3,
- 卷积核的卷积输出:13 * 13
- 卷积核的个数:192 * 2 = 384
(5)卷积层5:
- 卷积核的尺寸:3 * 3,
- 卷积核的卷积输出:13 * 13
- 卷积核的个数:128 * 128 = 256
(6)全连接层1:
- 输入:13 * 13 * 256 = 43,264 (进入全连接网络的特征数据)
- 神经元个数:2048 * 2 = 4096
- 输出:4096
(7)全连接层2:
- 输入:4096
- 神经元个数:2048 * 2 = 4096
- 输出:4096
(8)输出层
- 输入:4096 (进行最后分类的特征数据)
- 神经元个数:1000
- 输出:1000(支持1000个分类)
备注:由于激活函数和池化层不是神经元,因此没有在上图中体现。
3.2 网络架构描述:垂直法

(1)采用了最大池化(Max Pooling),池化核为3 * 3, 步长为2
(2)Local Response Normal:局部归一化竞争机制,后来被验证,用处不大。
(3)总的参数个数:35K + 307K + 884 + 1.3M + 442K + 37M + 16M + 4M = 59.968M
(4)等效FLOPs(是“每秒所执行的浮点运算次数”):720M
- 全连接层的参数大小与浮点计算量的关系是:一致的、相等的。
- 卷积层的参数虽然少(如上图中卷积层1的参数= 35K = 11*11*3 * 96),等卷积的计算量一点都不少(如卷积层1的参数计算量=105M),且远远大于全连接网络。
- 卷积层的参数大小与浮点计算量的关系是 = 卷积尺寸(长*宽*高)* 特征图尺寸(长*宽*卷积核数量),例如,第一个卷积层的计算量 = (11 * 11 *3) * (55 * 55 * 96) = 105,415, 200
3.3 分层解读

作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120837261
以上是关于[人工智能-深度学习-32]:卷积神经网络CNN - 常见分类网络- AlexNet的主要内容,如果未能解决你的问题,请参考以下文章