对比学习(Contrastive Learning)在CV与NLP领域中的研究进展
Posted 对白'
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对比学习(Contrastive Learning)在CV与NLP领域中的研究进展相关的知识,希望对你有一定的参考价值。
对比学习方法(CV)
对比学习要做什么?
有监督训练的典型问题,就是标注数据是有限的。
目前NLP领域的经验,自监督预训练使用的数据量越大,模型越复杂,那么模型能够吸收的知识越多,对下游任务效果来说越好。这可能是自从Bert出现以来,一再被反复证明。
所以对比学习的出现,是图像领域为了解决“在没有更大标注数据集的情况下,如何采用自监督预训练模式,来从中吸取图像本身的先验知识分布,得到一个预训练的模型”。
对比学习是自监督学习的一种,也就是说,不依赖标注数据,要从无标注图像中自己学习知识。
目前,对比学习貌似处于“无明确定义、有指导原则”的状态,它的指导原则是:通过自动构造相似实例和不相似实例,要求习得一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远。
对比学习Paper都会涉及到的一些关键点:
-
如何构造相似实例,以及不相似实例;
-
如何构造能够遵循上述指导原则的表示学习模型结构;
-
以及如何防止模型坍塌(Model Collapse);
SimCLR:一个典型的负例对比学习方法
SimCLR它是图像领域2020年ICML会议提出的,是一个比较“标准”的对比学习模型。
第一,它相对于之前的模型效果有明显的提升;第二,它采取对称结构,整体相对简洁清晰;第三,它奠定的结构,已成为其它对比学习模型的标准构成部分。
如何构造正负例

正例构造方法如上图所示。对于某张图片,我们从可能的增强操作集合T中,随机抽取两种:t1T及t2T,分别作用在原始图像上,形成两张经过增强的新图像,两者互为正例。训练时,Batch内任意其它图像,都可做为x1或x2的负例。
对比学习希望习得某个表示模型,它能够将图片映射到某个投影空间,并在这个空间内拉近正例的距离,推远负例距离。也就是说,迫使表示模型能够忽略表面因素,学习图像的内在一致结构信息,即学会某些类型的不变性,比如遮挡不变性、旋转不变性、颜色不变性等。SimCLR证明了,如果能够同时融合多种图像增强操作,增加对比学习模型任务难度,对于对比学习效果有明显提升作用。
构造表示学习系统
指导原则:通过这个系统,将训练数据投影到某个表示空间内,并采取一定的方法,使得正例距离比较近,负例距离比较远。
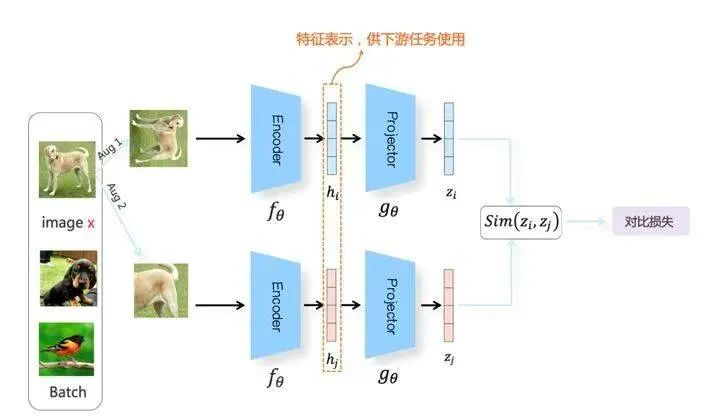
上图展示了SimCLR模型的整体结构。是的,它是一个双塔模型,不过图像领域一般叫Branch(上下两个分支)。
我们随机从无标训练数据中取N个构成一个Batch,对于Batch里的任意图像,根据上述方法构造正例,形成两个图像增强视图:Aug1和Aug2。Aug1 和Aug2各自包含N个增强数据,并分别经过上下两个分支,对增强图像做非线性变换,这两个分支就是SimCLR设计出的表示学习所需的投影函数,负责将图像数据投影到某个表示空间。
以上分支为例。Aug1首先经过特征编码器Encoder(一般采用ResNet做为模型结构,这里以函数 fθ代表),经CNN转换成对应的特征表示 。之后,是另外一个非线性变换结构Projector(由[FC->BN->ReLU->FC]两层MLP构成,这里以函数 gθ代表),进一步将特征表示hi映射成另外一个空间里的向量zi。这样,增强图像经过 gθ(fθ(x)) 两次非线性变换,就将增强图像投影到了表示空间,下分枝的Aug2过程类似。(问题:为什么这种投影操作,要做两次:经验结果)。
对于Batch内某张图像x来说,在Aug1和Aug2里的对应的增强后图像分别是xi和xj,他们互为正例,而xi和Aug1及Aug2里除xj之外的其它任意2N-2个图像都互为负例。在经过变换后,增强图像被投影到表示空间。通过定义合适的损失函数,来实现“正例距离较近,负例距离较远”的目标。
距离度量函数
首先需要一个度量函数,以判断两个向量在投影空间里的距离远近,一般采用相似性函数来作为距离度量标准。
具体而言,相似性计算函数采取对表示向量L2正则后的点积或者表示向量间的Cosine相似性:

损失函数
损失函数很关键,SimCLR的损失函数采用InfoNCE Loss,某个例子对应的InfoNCE损失为:

其中代表两个正例相应的Embedding。
InfoNCE函数,分子部分鼓励正例相似度越高越好,也就是在表示空间内距离越近越好;而分母部分,则鼓励任意负例之间的向量相似度越低越好,也就是距离越远越好。
上面介绍了SimCLR的关键做法,本身这个过程,其实是标准的预训练模式;利用海量的无标注图像数据,根据对比学习指导原则,学习出好的Encoder模型以及它对应产生的特征表示。所谓好的Encoder,就是说输入图像,它能学会并抽取出关键特征,这个过程跟Bert模型通过MLM自监督预训练其实目的相同,只是做法有差异。学好Encoder后,可以在解决下游具体任务的时候,用学到的参数初始化Encoder中的ResNet模型,用下游任务标注数据来Fine-tuning模型参数,期待预训练阶段学到的知识对下游任务有迁移作用。由此可见,SimCLR看着有很多构件,比如Encoder、Projector、图像增强、InfoNCE损失函数,其实我们最后要的,只是Encoder,而其它所有构件以及损失函数,只是用于训练出高质量Encoder的辅助结构。目前所有对比学习模型都是如此,这点还请注意。
SimCLR的贡献,一个是证明了复合图像增强很重要;另外一个就是这个Projector结构。这两者结合,给对比学习系统带来很大的性能提升,将对比学习性能提升到或者超过了有监督模型,在此之后的对比学习模型,基本都采取了Encoder+Projector的两次映射结构,以及复合图像增强方法。
评判对比学习系统的标准

对比学习在做特征表示相似性计算时,要先对表示向量做L2正则,之后再做点积计算,或者直接采用Cosine相似性,为什么要这么做呢?
很多研究表明,把特征表示映射到单位超球面上,有很多好处。这里有两个关键,一个是单位长度,一个是超球面。首先,相比带有向量长度信息的点积,在去掉长度信息后的单位长度向量操作,能增加深度学习模型的训练稳定性。另外,当表示向量被映射到超球面上,如果模型的表示能力足够好,能够把相似的例子在超球面上聚集到较近区域,那么很容易使用线性分类器把某类和其它类区分开(参考上图)。在对比学习模型里,对学习到的表示向量进行L2正则,或者采用Cosine相似性,就等价于将表示向量投影到了单位超球面上进行相互比较。
很多对比学习模型相关实验也证明了:对表示向量进行L2正则能提升模型效果。
Alignment和Uniformity
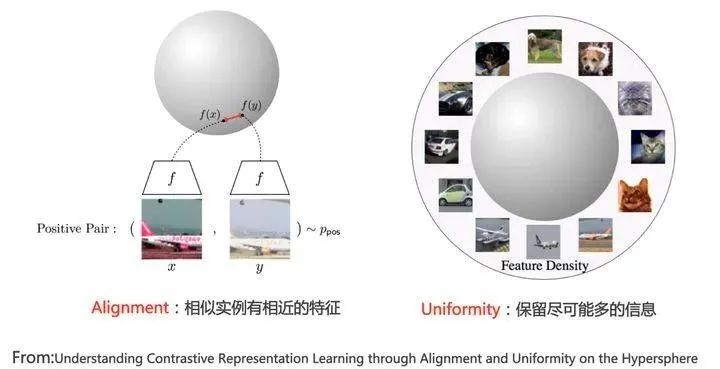
论文 《Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere》,对好的对比学习系统进行了探讨。它提出好的对比学习系统应该具备两个属性。
-
**Alignment:**指的是相似的例子,也就是正例,映射到单位超球面后,应该有接近的特征,也即是说,在超球面上距离比较近
-
**Uniformity:**指的是系统应该倾向在特征里保留尽可能多的信息,这等价于使得映射到单位超球面的特征,尽可能均匀地分布在球面上,分布得越均匀,意味着保留的信息越充分。分布均匀意味着两两有差异,也意味着各自保有独有信息,这代表信息保留充分。
模型坍塌(Collapse)

Uniformity特性的极端反例,是所有数据映射到单位超球面同一个点上,这极度违背了Uniformity原则,因为这代表所有数据的信息都被丢掉了,体现为数据极度不均匀得分布到了超球面同一个点上。也就是说,所有数据经过特征表示映射过程后,都收敛到了同一个常数解,一般将这种异常情况称为模型坍塌(Collapse)(参考上图)。
重新审视类似SimCLR结构的对比学习模型
可以看到,对比学习模型结构里的上下两个分枝,首先会将正例对,或者负例对,通过两次非线性映射,将训练数据投影到单位超球面上。然后通过体现优化目标的InfoNCE损失函数,来调整这些映射到单位超球面上的点之间的拓扑结构关系,希望能将正例在超球面上距离拉近,负例在超球面上推远。那么损失函数InfoNCE又是怎么达成这一点的呢?
分子部分体现出“Alignment”属性,它鼓励正例在单位超球面的距离越近越好;而分母里负例,则体现了“Uniformity”属性,它鼓励任意两对负例,在单位超球面上,两两距离越远越好。
**温度超参 τ 有什么作用呢?**目前很多实验表明,对比学习模型要想效果比较好,温度超参 τ 要设置一个比较小的数值,一般设置为0.1或者0.2。问题是:将这个超参设大或设小,它是如何影响模型优化过程的呢?目前的研究结果表明,InfoNCE是个能够感知负例难度的损失函数,而之所以能做到这点,主要依赖超参。
对比学习方法分类(图像)
如果从防止模型坍塌的不同方法角度,我们可大致把现有方法划分为四种:基于负例的对比学习方法、基于对比聚类的方法、基于不对称网络结构的方法,以及基于冗余消除损失函数的方法。
对比学习方法归类
基于负例的对比学习方法

所有在损失函数中采用负例的对比学习方法,都是靠负例的Uniformity特性,来防止模型坍塌的,这包括SimCLR系列及Moco系列等很多典型对比学习模型
基于对比聚类的方法

代表模型SwAV。
对于Batch内某张图像x来说,假设其经过图像增强Aug1和Aug2后,获得增强图像x1,x2,x1与x2则互为正例。x1走上分枝,x2走下分枝,SwAV对Aug1和Aug2中的表示向量,根据Sinkhorn-Knopp算法,在线对Batch内数据进行聚类。SwAV要求表示学习模型根据x1预测x2所在的类,同样的,也要求x2预测x1所在的类。
该方法要求某个投影点在超球面上,向另外一个投影点所属的聚类中心靠近,体现了Alignment原则;和其它聚类中心越远越好,这体现了Uniformity属性。
SwAV面临模型坍塌问题,具体表现形式为:Batch内所有实例都聚类到同一个类里。所以为了防止模型坍塌,SwAV对聚类增加了约束条件,要求Batch内实例比较均匀地聚类到不同的类别中。本质上,它与直接采用负例的对比学习模型,在防止模型坍塌方面作用机制是类似的,是一种隐形的负例。
基于不对称网络结构的方法

代表模型BYOL:只用正例来训练对比学习模型,靠上下分枝的结构不对称,防止模型坍塌。
基于冗余消除损失函数的方法
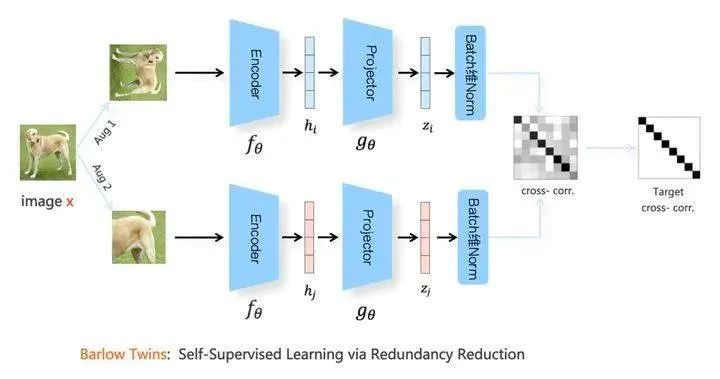
代表模型 Barlow Twins。
既没有使用负例,也没有使用不对称结构,主要靠替换了一个新的损失函数,可称之为“冗余消除损失函数”,来防止模型坍塌。
实验结果
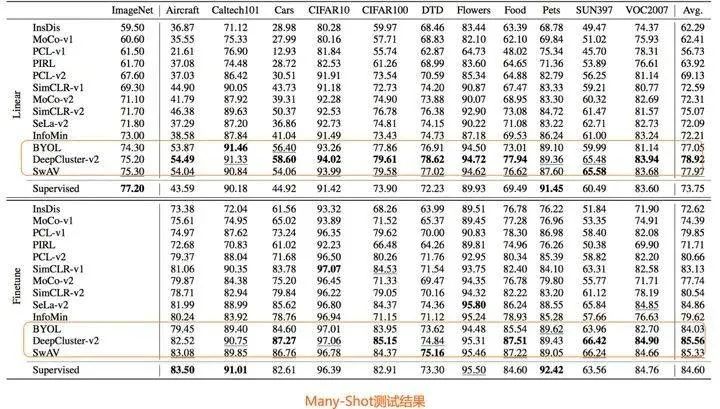
目前绝大多数对比学习模型在做模型训练的时候,采用的是ImageNet数据集,在评测的时候,主要实验也是在ImageNet上做的,那么问题是:对比学习本质上是种自监督预训练模型,希望能够从ImageNet数据集上自监督地学到一些图像先验知识与结构。那么,这种从ImageNet数据集学到的知识,能否很好地迁移到其它数据集呢?
论文“How Well Do Self-Supervised Models Transfer?”对13个知名自监督模型,在40多种数据集上进行相对公平地对比测试,得出了一些很有价值的结论。
对比学习方法(NLP)
CV领域的对比学习研究在近两年风生水起,也逐渐影响到NLP领域,从2020年起,NLP领域逐渐有一些利用对比学习思想,自监督训练sentence-embedding的idea。
我自己的调研中,通过如何运用Contrastive Learning思想,分成两类:
-
损失联合方式自监督:将CL的loss和其他loss混合,通过联合优化,使CL起到效果:CLEAR,DeCLUTER,SCCL。
-
非联合方法自监督:构造增强样本,fine-tune模型:Bert-CT,ConSERT,SimCSE。
下面分别从背景、方案、数据增强方法和实验效果介绍几个典型模型。
损失联合方式自监督
1.CLEAR
链接:
https://arxiv.org/pdf/2012.15466.pdf
**背景:**作者认为,当前的预训练模型都是基于word-level的,没有基于sentence-level的目标,对sentence的效果不好。
**方案:**word-level和sentence-level的loss联合。

对比损失函数:

**数据增强方法:**token层

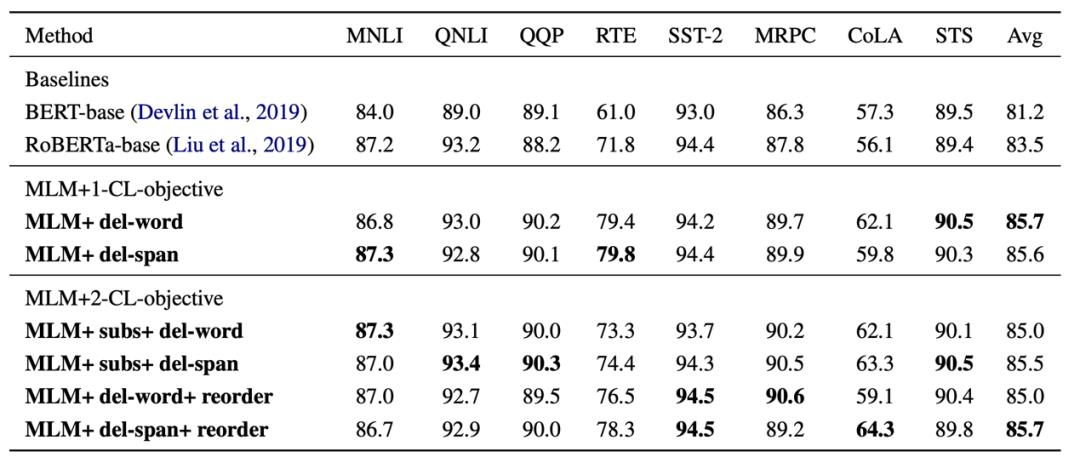
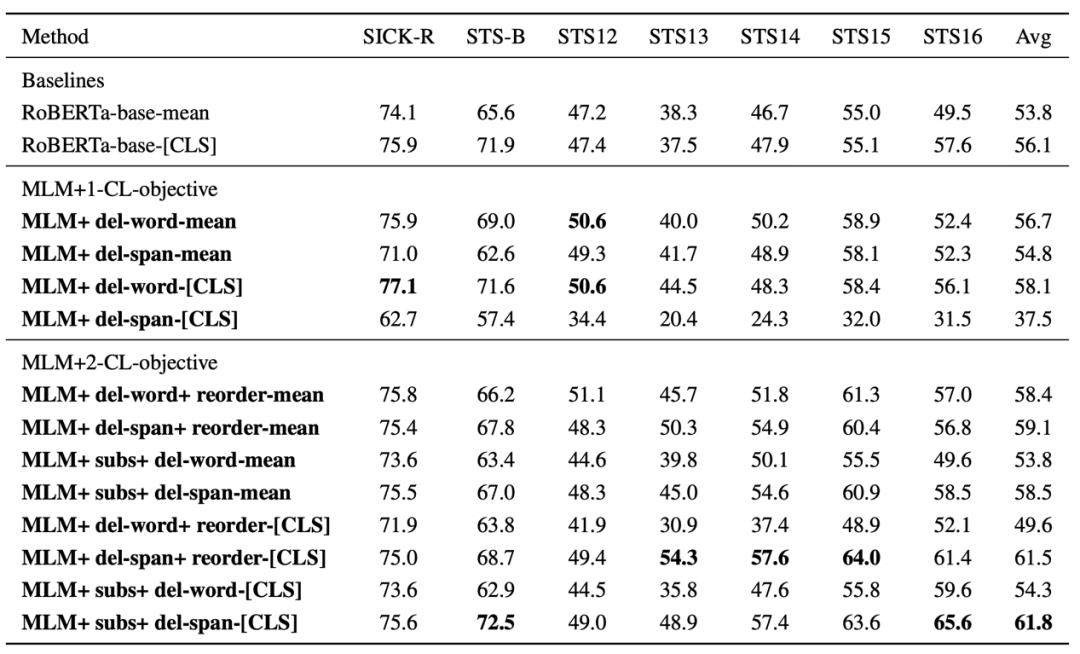
实验效果:
GLUE:
SentEval:
2.DeCLUTR
**链接:**https://arxiv.org/abs/2006.03659
**方案:**是一个不用训练数据的自监督的方法,是对pretrain过程的优化。
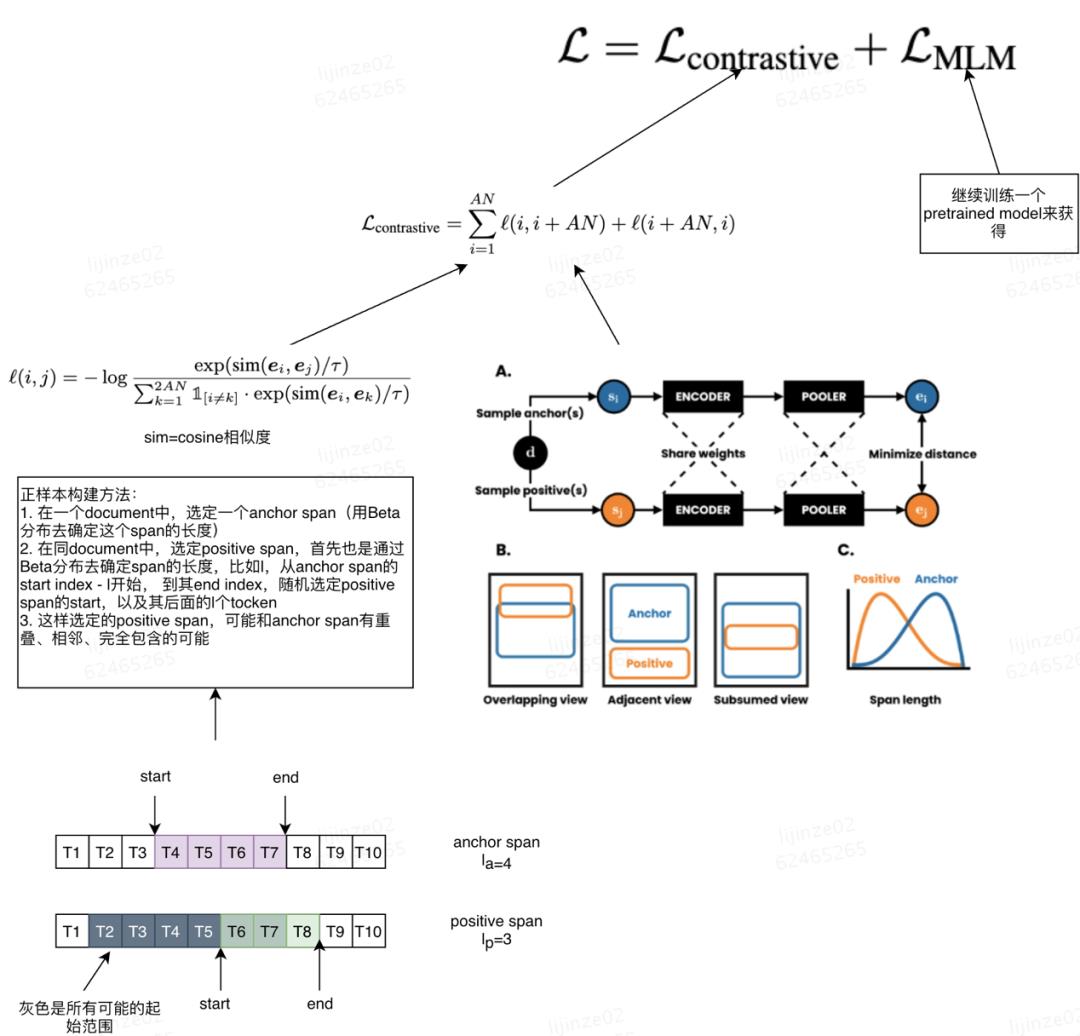
数据增强方法:
方案:选N个document组成一个batch,每个document取A个anchor,就有AN个,anchor取一个positive,也有AN个,共2AN个点。对于每一个点,除了和它组成正例的一对的2个,其他2AN-2都是负例
宗旨:认为距离anchor span越近的文本越相似,因此anchor span和它周边的span作为正例
用不同的Beta分布去限制anchor和positive span的长度,一般anchor比positive要长,而且anchor最长可以到512。
作者认为:
1. 长anchor可以让embedding达到同时表征sentence级别和paragraph级别的作用
2. 这样配置下游任务效果好 a)学到了global-to-local的信息 b)生成多个positive后可以获得diversity的信息
3. 因为一个batch里有多个文档,不同文档的span组成的负例是easy负例,同文档的span组成的负例是hard负例。
**实验效果:**对比学习过程中的ENCODER和MLM部分的Pretrained model是RoBerta和DistillRoBerta,pooling用的mean pooling。
**扩展知识:**Bert vs RoBerta vs AlBert

评测数据集是SentEval,SentEval是一个用于评估句子表征的工具包,包含 17 个下游任务,其输入是句子表示,输出是预测结果。
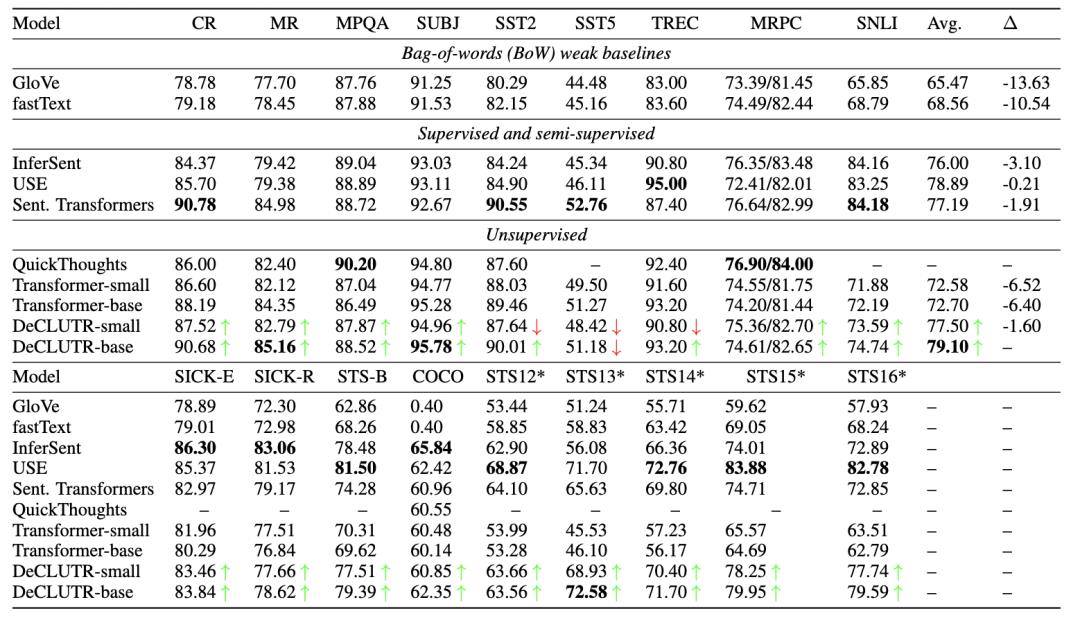
可以看到本文方案往往不是最优的那个,但是作者对比了 没用对比学习方法和用了对比学习方法(最后的Transformer-* VS DeCLUTER-*)的结果,说明了自己方案有效。
3.Supporting Clustering with Contrastive Learning
**链接:**https://arxiv.org/abs/2103.12953(NAACL 2021)
**背景:**在学习过程的开始阶段,不同的类别常常在表征空间中相互重叠,对如何实现不同类别之间的良好分离,带来了巨大的挑战。
**方案:**利用对比学习,去做更好的分离。通过联合优化top-down聚类损失和bottom-up 实体级别的对比loss,来达到同时优化intra-cluster和inter-cluster的目的。

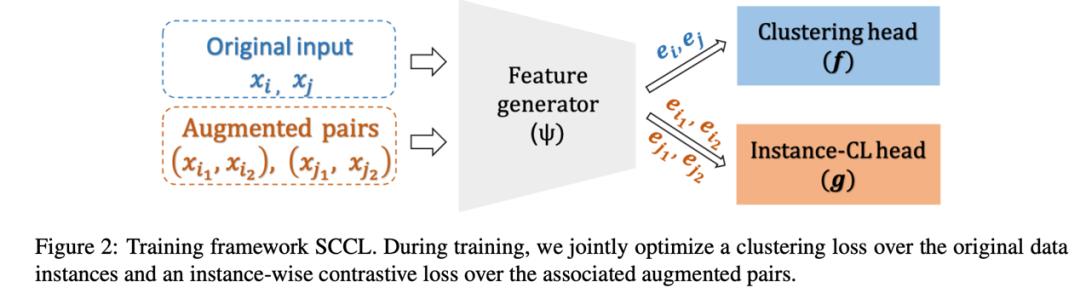
分Instance-CL部分和Clustering部分两个部分。
Instance-CL:
-
随机选M个样本组成一个batch,数据增强方法生成2M个样本,依然是从一个样本中生成的2个为一对正样本,和其他2M-2组成负样本
-
数据增强方法:
-
每个样本用InfoCNE去算loss, Instance-CL loss 为2M样本的平均值。

数据增强方法:
-
WordNet Augmenter:用wordNet中的同义词进行替换;
-
Contextual Augmenter:用pretrained model去找最合适的词去进行插入或替换;
-
Paraphrase via back translation:翻译成一种语言再翻译回来;
实验效果:

非联合方式自监督
1.BERT-CT (ICLR2021)
**背景:**从各种预训练模型的某层中取出的embedding,并不能很好表征句子,而且越接近目标的层,效果越不好。作者认为训练目标极为重要。
**方案:**用两个超参不一样的模型来取sentence embedding,尽可能让正例对的点积更大,负例对的点积更小。
数据增强方法:
正例:同句子的不同embedding;
负例:随机选7个不同的句子;
实验效果:

2.SimCSE
**链接:**https://arxiv.org/abs/2104.08821
**背景:**直接用BERT句向量做无监督语义相似度计算效果会很差,任意两个句子的BERT句向量的相似度都相当高,其中一个原因是向量分布的非线性和奇异性,正好,对比学习的目标之一就是学习到分布均匀的向量表示,因此我们可以借助对比学习间接达到规整表示空间的效果,这又回到了正样本构建的问题上来,而本文的创新点之一正是无监督条件下的正样本构建。
**方案&数据增强方法:**本文作者提出可以通过随机采样dropout mask来生成xi+,回想一下,在标准的Transformer中,dropout mask被放置在全连接层和注意力求和操作上,其中z是随机生成的dropout mask,由于dropout mask是随机生成的,所以在训练阶段,将同一个样本分两次输入到同一个编码器中,我们会得到两个不同的表示向量z,z’,将z’作为正样本,则模型的训练目标为:

这种通过改变dropout mask生成正样本的方法可以看作是数据增强的最小形式,因为原样本和生成的正样本的语义是完全一致的(注意语义一致和语义相关的区别),只是生成的embedding不同而已。
实验效果:

你好,我是对白,硕士毕业于清华,现大厂算法工程师,拿过八家大厂的SSP offer。
本科时独立创业五年,成立两家公司,并拿过总计三百多万元融资(已到账),项目入选南京321高层次创业人才引进计划。创业做过无人机、机器人和互联网教育,保研后选择退出。
我每周至少更新一篇原创,分享自己的算法技术、创业心得和人生感悟。我正在努力实现人生中的第一个小目标,上方关注后可以加我私信交流。
期待你关注我的公众号,我们一起前行。

以上是关于对比学习(Contrastive Learning)在CV与NLP领域中的研究进展的主要内容,如果未能解决你的问题,请参考以下文章
对比学习(Contrastive Learning)在CV与NLP领域中的研究进展
深度学习核心技术精讲100篇(三十七)-利用Contrastive Learning对抗数据噪声:对比学习在微博场景的实践
论文笔记:COST: CONTRASTIVE LEARNING OF DISENTANGLEDSEASONAL-TREND REPRESENTATIONS FORTIME SERIES FOREC
LightGCL: Simple Yet Effective Graph Contrastive Learning for Recommendation
论文解读——《A Simple Framework for Contrastive Learning of Visual Representations》
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval