论文解读——《A Simple Framework for Contrastive Learning of Visual Representations》
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读——《A Simple Framework for Contrastive Learning of Visual Representations》相关的知识,希望对你有一定的参考价值。
1 题目
《A Simple Framework for Contrastive Learning of Visual Representations》
作者: Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton
2 介绍
本文主要介绍 SimCLR框架。
定义:
SimCLR:一个简单的视觉表示对比学习框架,不仅比以前的工作更出色,而且也更简单,既不需要专门的架构,也不需要储存库。
性能:
在 $ImageNet$ 上大大优于以前的自监督和半监督学习方法。在 $SimCLR$ 学习的自监督表示上训练的 线性分类器 实现了 $76.5%$ 的 $top-1$ 准确率,相对于之前的最新技术水平提高了 $7 \\%$,与监督 $ResNet-50$(下图中的 $gray cross$) 的性能相匹配。当仅对 $1 \\% $ 的标签进行微调时,我们实现了 $85.8\\%$ 的 $top-5$ 准确率,在标签数量减少 $100$ 倍的情况下优于 $AlexNet$。
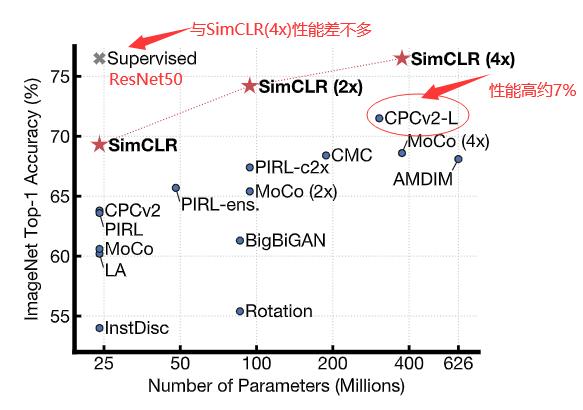
PS:在 $ImageNet$ 训练线性分类器,比较准确性。
图解:
1、随着模型的增大($Parameters$的增加),$SimCLR$ 的性能也在不断的增加,体现了 $SimCLR$ 贡献3:“对比学习的好处在于使用更大的批量和更多的训练步骤”。
2、$SimCLR$ 性能在 $ImageNet$ 上的性能远高于其他方法除$Sup ResNet50$。
SimCLR框架优势:
- 多个数据增强组合对于定义产生有效表示的对比预测任务至关重要。 此外,无监督的对比学习受益于比监督学习更强的数据增强。
- 在表示和对比损失之间引入可学习的非线性变换,大大提高了学习表示的质量。
- 具有对比交叉熵损失的表示学习受益于归一化嵌入和适当的温度参数 $\\tau$。
- 对比学习与监督学习相比,受益于更大的批量($Batch$)和更长的训练时间。 与监督学习一样,对比学习也受益于更深更广的网络。
3 方法
3.1 对比学习框架
对比学习是一种为机器学习模型描述相似和不同事物的任务的方法。它试图教机器区分相似和不同的事物。


$SimCLR$ 最终目的是最大化同一数据示例的不同增强视图之间的一致性来学习表示,即 $max \\ similar(\\mathbf{v_1} ,\\mathbf{v_2} )$
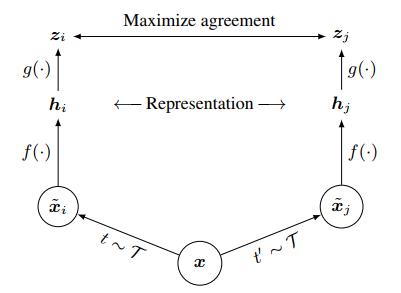
$SimCLR$ 框架包括以下四个主要组件:
1、随机数据增强模块。随机转换任何给定的数据示例,生成同一数据示例的两个相关视图,表示并定义 ${\\widetilde{x}_i }$和 ${\\widetilde{x}_j}$ 是正对。本文组合应用三种增强:随机裁剪然后调整回原始大小$(random cropping and resize back)$、随机颜色失真$(color distortions)$ 和 随机高斯模糊$(random Gaussian blur)$。
2、基础编码器(base encoder) $f(\\cdot )$。用于从生成的视图中提取表示向量,允许选择各种网络架构。本文选择 $ResNet$ 获得$h_i=f(\\widetilde{x}_i )=ResNet(\\widetilde{x}_i)$,生成的表示$h_i \\in R^d$是平均池化层$(average pooling layer)$后的输出。
3、投影头(projection head) $g(·) $将表示映射到应用对比损失的空间。 本文使用一个带有一个隐藏层的 $MLP$ 来获得 $z_i =g(h_i)=w^{(2)}\\sigma (w^{(1)}h_i)$ 其中 $\\sigma$是一个 $ReLU$ 非线性函数。此外,发现在 $z_i $而非 $h_i $ 上定义对比损失是有益的。
4、对比损失函数(contrastive loss function)。 给定 $batch$ 中一组生成的视图 $\\{\\widetilde{x}_k \\}$,其中包括一对正例 ${\\widetilde{x}_i }$ 和 ${\\widetilde{x}_j}$ ,对比预测任务旨在对给定 ${\\widetilde{x}_i}$ 识别 $\\{{\\widetilde{x}_j} \\}_{k\\ne i } $ 中的${\\widetilde{x}_j}$ 。
随机抽取 $N$ 个样本的小批量样本,并在从小批量样本上生成增强视图,从而产生 $2N$ 个数据点。 本文无明确地指定负例,而是给定一个正对$(positive pair)$,将小批量中的其他 $2N − 2 $个增强示例视为负示例。本文定义相似度为余弦相似度$sim(u,v)=\\frac{u^Tv}{||u||\\ ||v||} $。则一对正对 $(i,j)$的损失函数定义为:
$l_{i,j}=-log( \\frac{exp(sim(z_i,z_j)/\\tau )}{ {\\textstyle \\sum_{k=1}^{2N}}1_{[k\\ne i]} \\ exp(sim(z_i,z_j)/\\tau) } )$
其中 $1_{[k\\ne i]} \\in \\{0,1\\}$ 是指示函数,当 $k\\ne i$ 为 $1$ 。$\\tau$是温度参数。最终损失是在小批量中计算所有正对 $(i,j)$ 和 $(j,i)$ 的。为方便起见,将其称为 $NT-Xent$(归一化温度标度交叉熵损失)。
算法流程

图解算法流程:
Step1:随机数据增强模块
首先,原始图像数据集生成若干大小为 $N$ 的 $batch$。这里假设取一批大小为 $N = 2$ 的 $batch$。本文使用 $8192$ 的大 $batch$。

定义随机数据增强函数 $T$ ,本文应用 $random (crop and resize back + color distortions + Gaussian blur)$。
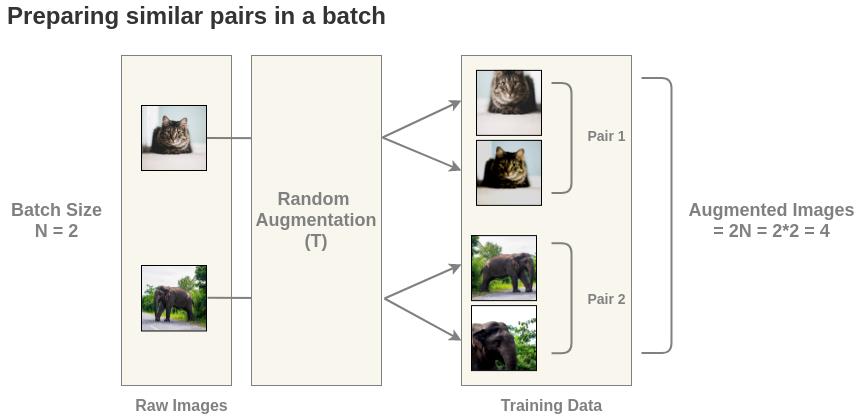
对于 $batch$ 中的每一幅图像,使用随机数据增强函数 $T$ 得到一对$view$。对 $batch$ 为 $2$ 的情况,得到 $2N = 4$ 张图像。
Step2:基础编码器(base encoder) $f(\\cdot )$
对增强过的图像通过一个编码器来获得图像表示。所使用的编码器是通用的,可与其他架构替换。下面的两个编码器共享权值,得到表示$vector$ $h_i$和$h_j$。
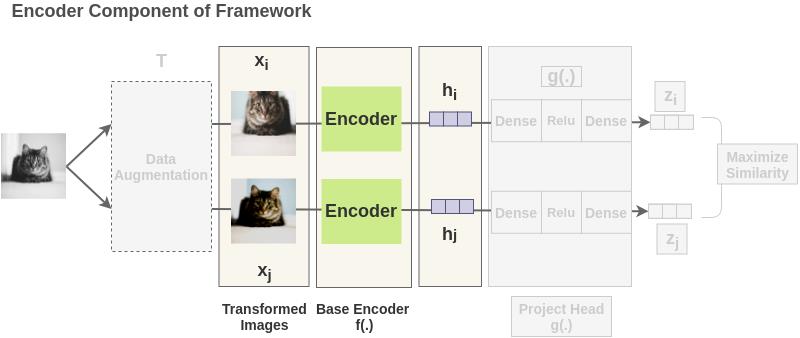
在本文中,作者使用 $ResNet-50$ 架构作为编码器。输出是一个 $2048$ 维的向量 $h$。

Step:投影头(projection head) $g(·) $将表示映射到应用对比损失的空间。
本文使用一个带有一个隐藏层的 $MLP$ 来获得 $z_i =g(h_i)=w^{(2)}\\sigma (w^{(1)}h_i)$ 其中 $\\sigma$是一个 $ReLU$ 非线性函数。
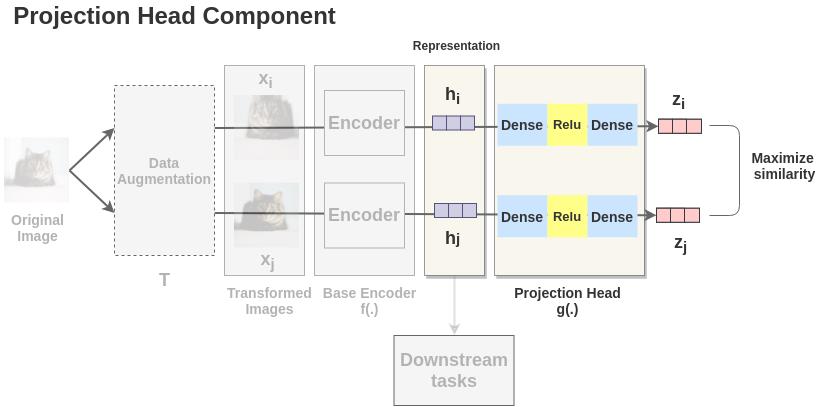
Step4:使用对比损失函数进行模型调优。
对于 $batch$ 中的每个增强过的图像通过基础编码器 $f(\\cdot )$,得到嵌入向量 $z$。

使用嵌入向量$z_i$,计算损失的步骤如下:
a. 计算余弦相似性
用余弦相似度计算图像的两个增强的图像之间的相似度。对于两个增强的图像 $x_i$ 和 $x_j$,在其投影表示 $z_i$ 和 $z_j$ 上计算余弦相似度。
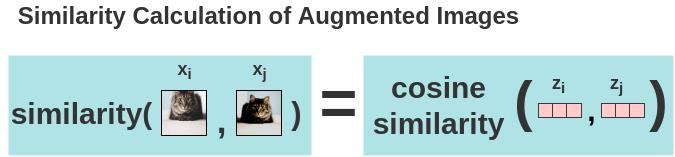
$s_{i,j} = \\frac{ \\color{#ff7070}{z_{i}^{T}z_{j}} }{( ||\\color{#ff7070}{z_{i}}|| ||\\color{#ff7070}{z_{j}}||)}$
其中
- $\\lVert z_{i} \\rVert$是矢量的模。
使用上述公式计算 $batch$ 中每个增强图像之间的两两余弦相似度。如图所示,在理想情况下,增强后的猫的图像之间的相似度会很高,而猫和大象图像之间的相似度会较低。

b. 损失的计算
$SimCLR$使用了一种对比损失,称为“$NT-Xent$损失”(归一化温度-尺度交叉熵损失)。工作步骤如下:
首先,将 $batch$ 的增强对逐个取出。

接下来,我们使用和 $softmax$ 函数原理相似的函数来得到这两个图像相似的概率。
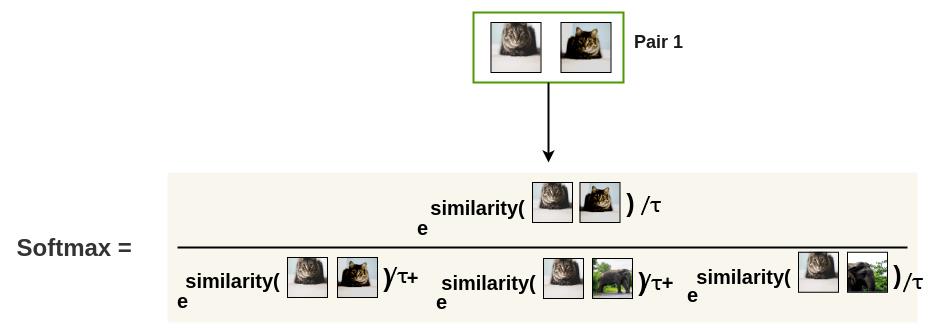
这种 $softmax$ 计算等效于获得第二张增强猫图像与该对中的第一张猫图像最相似的概率。批次中的所有剩余图像都被采样为不同的图像(负对)。 因此,我们不需要像 $InstDisc$、$MoCo$ 或 $PIRL$ 等以前的方法那样需要专门的架构、存储库或队列。

然后,取上述计算的负对数来计算这一对图像的损失。
$l_{i,j}=-log( \\frac{exp(sim(z_i,z_j)/\\tau )}{ {\\textstyle \\sum_{k=1}^{2N}}1_{[k\\ne i]} \\ exp(sim(z_i,z_j)/\\tau) } )$

图像位置互换,再次计算同一对图像的损失。

计算 $Batch size N=2$ 的所有配对的损失并取平均值。
$L = \\frac{1}{ 2N } \\sum \\limits _{k=1}^{N} [l(2k-1, 2k) + l(2k, 2k-1)]$
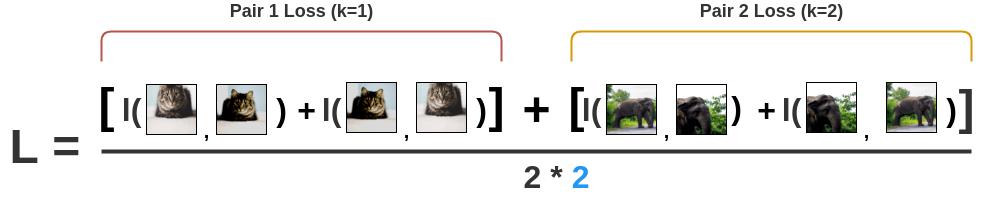
最后,更新网络 $f(\\cdot )$ 和 $g$ 以及最小化 $L$。
3.2.大批量训练
本文将训练批次大小 $N$ 从 $256$ 改变到 $8192$。$8192$ 的批次大小提供了来自两个增强视图的 $2$ 个正示例 $16382$ 个负示例。大批量训练可能不稳定,为了稳定训练,我们对所有批次大小使用 $LARS$优化器。我们使用 $Cloud \\ TPU$ 训练我们的模型,根据批量大小使用 $32$ 到 $128$ 个内核,$2 $ 全局 $BN$。
4 对比表示学习的数据增强
数据增强定义了预测任务。虽然数据增强已广泛用于有监督和无监督的表示学习,但它并未被视为定义对比预测任务的系统方法,许多现有方法通过改变架构来定义对比预测任务。Bachman 等人通过约束网络架构中的感受野来实现全局到局部的视图预测,而 Oord 等人则通过约束网络架构中的感受野来实现全局到局部的视图预测。赫纳夫等人通过固定的图像分割过程和上下文聚合网络实现相邻视图预测。我们表明,可以通过对目标图像执行简单的随机裁剪(调整大小)来避免这种复杂性,这创建了一系列包含上述两个的预测任务。这种简单的设计选择方便地将预测任务与其他组件(如神经网络架构)分离,可以通过扩展增强系列并随机组合它们来定义更广泛的对比预测任务。
4.1 数据增强操作的组合对于学习良好的表示至关重要
为了系统地研究数据增强的影响,本文考虑了几种常见的增强。 一种类型的增强涉及数据的空间/几何变换,如裁剪和调整大小、旋转和剪切。 另一种类型的增强涉及外观变换,例如颜色失真(包括颜色下降、亮度、对比度、饱和度、色调)、高斯模糊和 Sobel 过滤。 下图可视化了我们在这项工作中研究的增强。

为了解单个数据增强的影响和增强组合的重要性,本文研究了我们的框架在单独或成对应用增强时的性能。 由于 ImageNet 图像大小不同,本文总是应用裁剪和调整图像大小,这使得在没有裁剪的情况下很难研究其他增强。 为了消除这种混淆,我们考虑了这种消融的非对称数据转换设置。 具体来说,我们总是首先随机裁剪图像并将它们调整为相同的分辨率,然后只将目标转换应用于图 2 中框架的一个分支,而将另一个分支作为身份(即 $t (x_i ) = x_i )$。
如下图显示了数据增强操作单独和组合变换下的线性评估结果(linear evaluation result)。观察到,即使模型几乎可以完美地识别对比任务中的正对,也没有单一的转换足以学习好的表示。对组合进行增强时,对比预测任务变得更加困难,但表示质量显着提高。
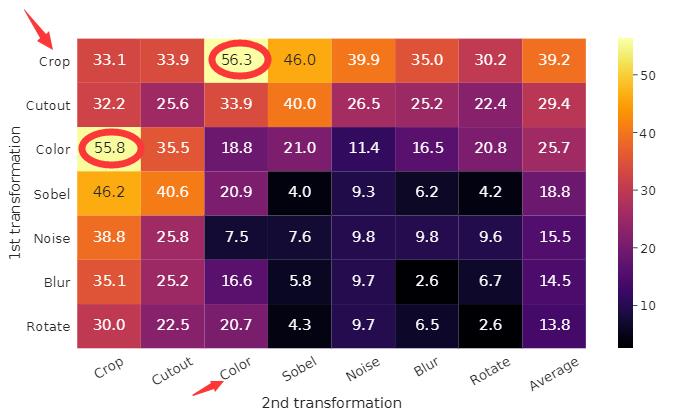
一种增强组合脱颖而出:随机裁剪和随机颜色失真 (random cropping and random color distortion)。推测仅使用随机裁剪作为数据增强时的一个严重问题是图像中的大多数 $patch$ 共享相似的颜色分布。下图显示单独的颜色直方图就足以区分图像。神经网络可以利用这个捷径来解决预测任务。因此,为了学习可概括的特征,将裁剪与颜色失真组合起来至关重要。
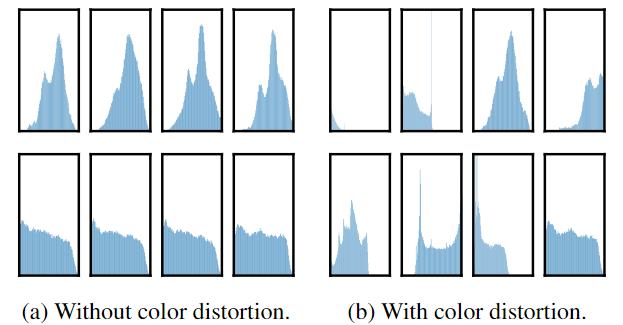
PS:颜色直方图
4.2 对比学习需要比监督学习更强的数据增强
为了进一步证明颜色增强的重要性,本文调整了颜色增强的强度,如下表所示。更强的颜色增强显着改善了学习的无监督模型的线性评估。 在这种情况下,$AutoAugment$ 是一种使用监督学习发现的复杂增强策略,其效果并不比简单裁剪+(更强)颜色失真( simple cropping+ (stronger) color distortion) 更好。 当使用相同的增强集训练监督模型时,观察到更强的颜色增强不会改善甚至损害它们的性能。 因此,我们的实验表明,与监督学习相比,无监督的对比学习受益于更强的(颜色)数据增强。
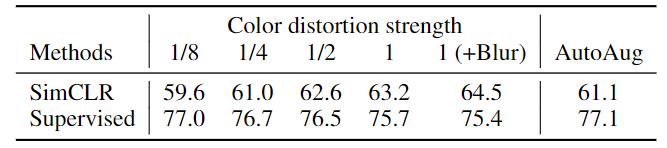
PS:SimCLR中的无监督ResNet-50与监督ResNet-50。
5 编码器和投影头的架构
5.1 无监督的对比学习从更大的模型中获益更多
如图所示,增加深度和宽度都可以提高性能。 虽然类似的发现适用于监督学习,但我们发现监督模型和在无监督模型上训练的线性分类器之间的差距随着模型大小的增加而缩小,表明无监督学习从更大的模型中受益比其监督对应物更多。
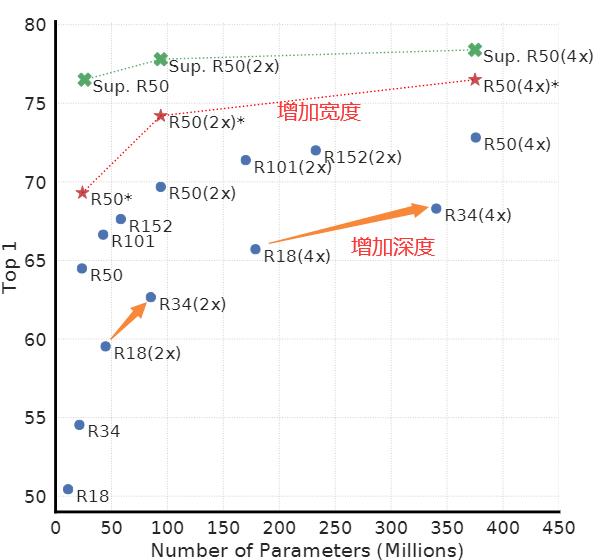
PS:在线性分类器中比较监督学习和无监督学习。
5.2 非线性投影头提高了之前图层的表示质量
研究投影头的重要性,即 $g(h)$。 下图显示了使用三种不同的头部架构的线性评估结果:(1)身份映射(identity mapping);(2)线性投影(Linear projection);(3)非线性投影(Non-linear projection)。观察到非线性投影比线性投影(+3%)好,比没有投影(>10%)好得多。 当使用投影头时,无论输出尺寸如何,都会观察到类似的结果。 此外,即使使用非线性投影,投影头之前的层 $h$ 仍然比之后的层 $z = g(h)$ 好得多(> 10%),表明投影头之前的隐藏层是 比之后的层更好的表示。
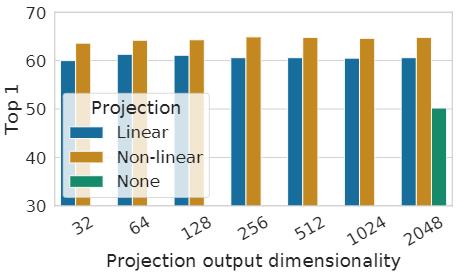
PS:横坐标表示 $z$ 的维度。
本文推测在非线性投影之前使用表示的重要性是由于对比损失引起的信息损失。 特别是,$z=g(h)$ 被训练为对数据变换保持不变。 因此,$g$ 可能删除对下游任务有用的信息,例如对象的颜色或方向。 通过利用非线性变换 $g(·)$,可以形成和保持更多的信息。 为了验证这个假设,使用 $h$ 和 $g(h)$ 来学习预测在预训练期间应用的变换。 这里我们设置 $g(h)=W^{(2)}\\sigma (W^{(1)}H)$,具有相同的输入和输出维度 (即 2048)。

PS:在不同的表示上训练额外的 MLP来预测转换的准确性。
本文验证了一个猜想:$h$ 中含有更多的信息,远多于 $g(h)$ 。用 $h$ 和$g(h)$ 来衡量一个图像做了什么工作,图中通过分类任务使用表示 $h$ 或 $g(h)$比较 ,得出两者的准确性。准确性越高说明含有原始数据信息越多,通过对比可以发现使用表示 $h$ 的准确性远高于使用表示 $g(h)$。说明较表示 $g(h)$, 表示$h$含有更多的信息。
6 损失函数和批量大小
6.1 具有可调温度的归一化交叉熵损失比替代方案效果更好
本文将 $NT-Xent$ 损失与其他常用的对比损失函数进行比较,例如逻辑损失和边际损失。
为了使比较公平,对所有损失函数使用相同的 $l_2$ 标准化$(l_2 \\ normalization)$方法,并调整超参数,并报告它们的最佳结果。下表显示,虽然 $(semi-hard negative mining)$ 有帮助,但最佳结果是仍然比我们默认的 $NT-Xent$ 损失更糟糕。

PS:使用不同损失函数训练的模型的线性评估(top-1)。 “sh”表示使用半硬负挖掘。
接下来测试 $l_2$ 标准化$(l_2 \\ \\ normalization)$(即余弦相似度与点积)和温度 $\\tau $ 在我们默认的 NT-Xent 损失中的重要性。 下表显示,如果没有标准化和适当的温度缩放,性能会明显变差。 如果没有 $l_2$ 标准化,对比任务的准确性更高,但在线性评估下得到的表示更差。
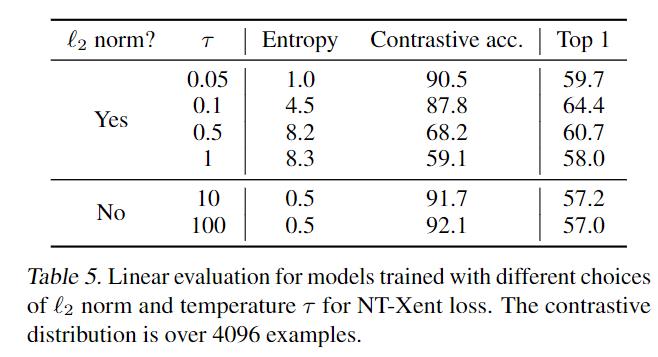
6.2 对比学习受益于更大的批量和更长的训练时间
下图显示针对不同时期 (epoch) 数训练模型时批量大小的影响。发现当训练时期 (epoch)的数量很少(例如 100 个时期 (epoch))时,较大的批次大小 (batch sizes) 比较小的批次具有显着的优势。 随着更多的训练步骤/时期,不同批次大小之间的差距会减少或消失,前提是批次是随机重新采样的。与监督学习相反,在对比学习中,更大的批次大小提供更多的负样本,促进收敛(即,对于给定的准确度,采用更少的时期和步骤)。 训练时间越长,也会提供更多的负面例子,从而改善结果。
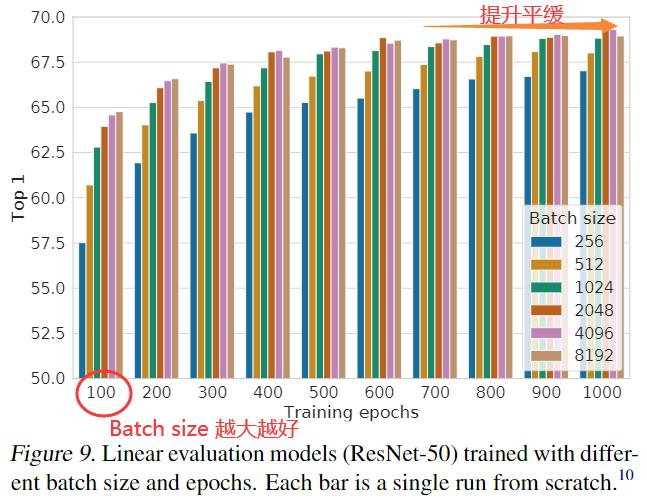
PS:线性评估模型(ResNet50)在不同batch size 和epoch下的准确性。
7 与最先进技术的比较
本文在 $3$ 个不同的隐藏层宽度(宽度乘数为 $1×$、$2×$ 和 $4×$)中使用 $ResNet-50$。 为了更好的收敛,模型训练了 $1000$ 个 $epoch$。
下表将我们的结果与之前的方法进行了比较在线性评估比较。 与以前需要专门设计的架构的方法相比,我们能够使用标准网络获得更好的结果。 使用我们的 $ResNet-50 (4x) $获得的最佳结果可以匹配监督预训练的 $ResNet-50$(前文所提)。
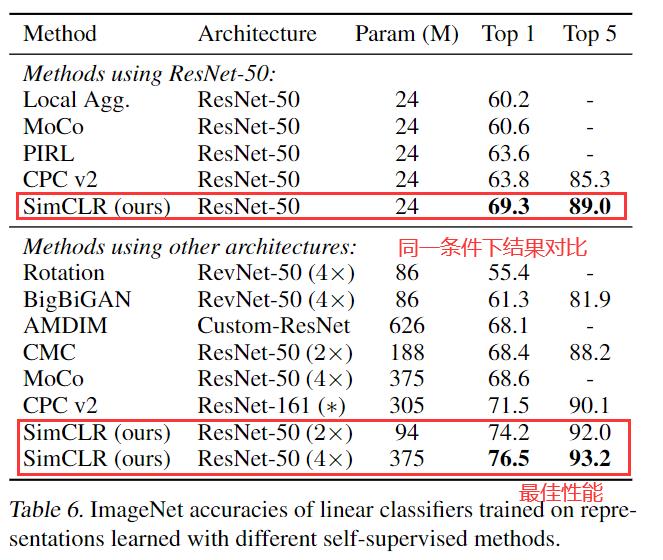
PS:线性分类任务中的比较结果
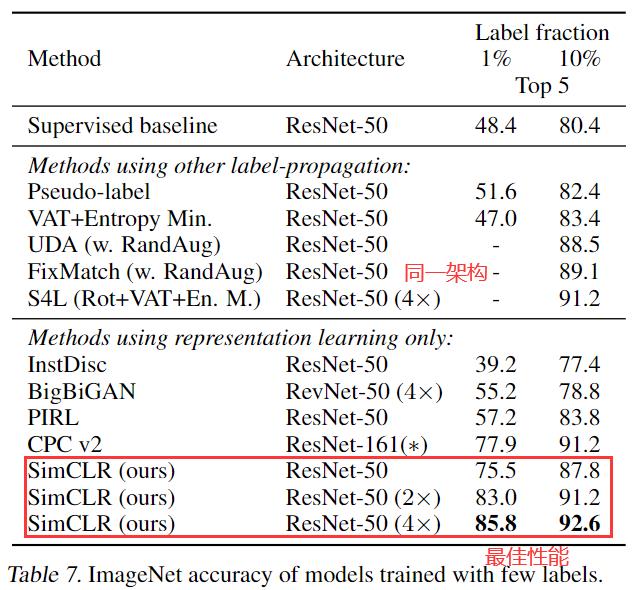
半监督学习。在没有正则化的情况下对标记数据的整个基础网络进行微调。 下表显示了我们的结果与最近的方法的比较。 同样,我们的方法显着改进了 1% 和 10% 的标签。
结论
因此,SimCLR 提供了一个强大的框架,可以在这个方向上进行进一步的研究,并改善计算机视觉的自监督学习状态。
参考文献
以上是关于论文解读——《A Simple Framework for Contrastive Learning of Visual Representations》的主要内容,如果未能解决你的问题,请参考以下文章