M-SQL:超强的多任务表示学习方法
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了M-SQL:超强的多任务表示学习方法相关的知识,希望对你有一定的参考价值。
摘要:本篇文章将硬核讲解M-SQL:一种将自然语言转换为SQL语句的多任务表示学习方法的相关论文。
本文分享自华为云社区《【云驻共创】M-SQL,一种超强的多任务表示学习方法,你值得拥有》,作者: 启明。
数据集整体介绍
定义介绍
国际惯例,先来一段定(bai)义(du)介(bai)绍(ke):Text to SQL,顾名思义,就是在给定数据库(或表)的前提下,根据用户的提问,产生SQL语句。其数学描述如下:
令X表示用户的自然语言提问,D表示与提问相关的数据库(或表),Y表示其对应的SQL语句。
SQL语句生成任务可以表述为:对于每一组独立的(X,D,Y),将(X,D)映射到对应的Y。
用一个大家熟悉的场景为例。假设我们有一张学生信息表,我们可以用自然语言提问:大于18岁的学生都有谁,模型需要返回一个与之相关的SQL语句,那么就是:
SELECT 姓名 FROM 学生信息 WHERE 年龄 > 18
场景分类
Text to SQL有很多种分类,其中一种是按问题分类:
一种是上下文无关的(提问之间不存在关联):Spider
一种是上下文相关的(两个提问之间存在一定关联):SparC
“上下文无关”是指提问之间没有任何的关联,而“上下文相关”是前后两个提问之间,存在一些指代关系或者说存在一定的关联。
同样,我们举一个简单的例子来说明:
提问1:有预约的医生ID是什么?
SELECT physician FROM appointment
提问2:他们的名字是什么?
SELECT T2.name FROM appointment AS T1 JOIN physician AS T2 ON T1.Physician = T2.EmpoyeeID
以上就是一个上下文相关的例子,第一句的确定医生ID,第二句根据医生ID确定医生名字。
另一种是按领域分类:单领域 or 多领域
如果所有的提问都是有关于航空方面的,这就是一个单领域的数据集。而跨领域数据集,则是在训练集当中可能有很多种领域,在测试集当中也有很多种领域,但是训练集中的领域和测试集中的领域不重合,这就要求我们的模型具有一定的泛化能力。
第三种是按照数据库进行分类:
单表数据库:WikiSQL,其提问只针对一个表,或者是它所针对数据库当中只有一个表
多表数据库:Spider,其提问针对的数据库当中有许多个表,它所产生的 SQL语句可能涉及到多个表之间的连接。
第四种种分类是按照标注类型进行分类:
最终结果:WikiTableQuestion
SQL语句:WikiSQL、Spider
有一些数据集没有给出相关的SQL语句,而是直接给出了一个结果。以前面的例子为例,“大于18岁的学生都有谁”,输出有可能是给出SQL语句,也有可能是最终结果:把这些人名都给列出来,而没有给出SQL语句,这其中涉及到的“弱监督学习”,本次不做具体讲解。
TableQA 数据集
本次要讲解的论文所采用的是一个TableQA数据集,它也是一个单表数据。也就是每一个提问都只针对一个表进行提问。TableQA和WikiSQL有有很多相似之处,但是也有一定的差异,如下图所示:

论文概述
介绍完数据集之后,我们来对论文中所提出的模型进行一个简单的介绍。
首先来思考这样一个问题:通过自然语言生成SQL语可以有什么方法?其实一个最简单的思路:输入端是自然语言句子,输出端是与之对应的SQL语句(按照SQL语句按照一个token一个token进行生成)。
比如说我们前面那个例子,Encoder是“大于18岁的学生都有谁“,输出端是SELECT name FROM XX表 Y条件。
这个方法很简单,但是也伴随着一些问题:SQL语句是结构化的查询语言,它是具备一定的结构的,这和一般的语言生成任务是有一定差别的。
对于一般的语言生成任务来说,如果变更其中的一两个词,可能它的语义不会发生太大变化。但是对于 SQL语句来说,如果某个词不一样了,那么其就可能就没有办法继续执行。所以我们需要利用好SQL语句内部的一些语法信息,也就是结构信息。按照它的结构来进行生成,这就是论文当中所提出来的,按照 SQL的框架来进行生成。
M-SQL
因为TableQA数据集只针对单表,相当于From字句可以省略。大体可以分成两个部分,一部分是 Select子句,一部分是 Where子句。
其中Select的子句当中有两个部分:一个是所选取的表的名称,另一个是聚合操作。比如说我们要求某一列的最大值、最小值或者是对某一列进行求和,就需要聚合操作来进行。
对于Where子句这一部分,我们详细介绍一下:
$WOP:where 条件连接符(and /or / Null)
$COLUMN:数据库中的列名
$AGG:对选取列的操作(Null, AVG, MAX, MIN, COUNT, SUM)
$OP:where子句中的列值
根据对TableQA数据集进行统计,限定select中最多出现2列、where中最多有3个条件:
SELECT ($AGG $COLUMN)*
WHERE $WOP ($COLUMN $OP $VALUE)*
M-SQL模型
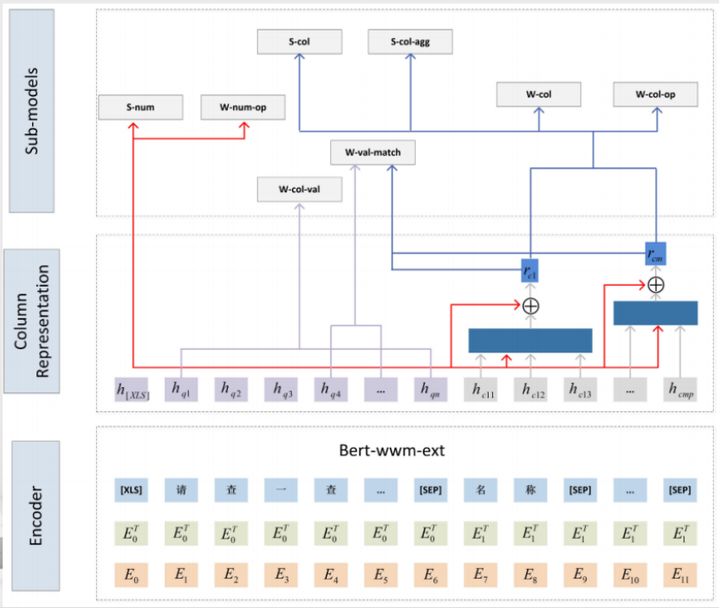
此模型大致可从下往上可以分成三块。
Encoder:对输入进行一个编码;采用了一个简单的bert模型,版本是wwwm-ext。wwm意味着其使用的是一个全词覆盖的方式,而ext则扩充了它的训练集并使它的训练部署有所增加。
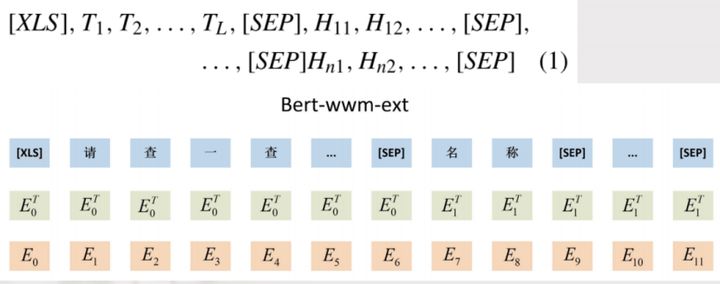
其输入部分包括:问题、列名。同样以前面“大于18岁的学生都有谁”为例,可以看到上图所示,T1至TL,后面跟着的是所提问的表当中所出现的每一列它的列名,比如说这个表当中可能有姓名、学号或者年龄。另外,与bert输入不同的是它用 [XLS]去替换了[CLS]。
列表示:对于列的表示进行增强;由于每一列当中它可能会由多个token构成,比如说,一列的名字叫“姓名”,其可能是两个字,这两个字分别有两个embeding,那么如何把这两个embeding给它合并成一个embeding作为列的表示呢?我们可以用前面的 XLS的表示来对列的表示进行增强,具体的做法如下:
先通过前面 XLS的表示,对这一列当中所有的token表示进行计算attention,attention计算出来之后再加上前面 XLS表示的 embeding,这两个之和就构成了这一列的增强的表示。
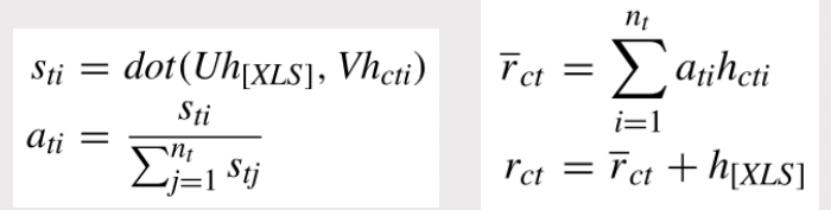
经过上述步骤之后,我们就得到了问题当中,每一个token的表示,以及表格当中每一列的表示。
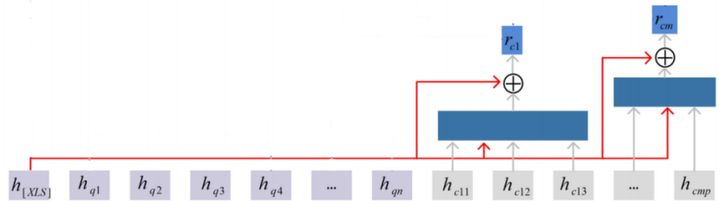
子模型:8个子模型及对这8个子模型进行1个多任务的学习。
前面提到,我们可以将SQL语句分割成不同的部分,然后每一部分分别进行生成,于是可以得出8个子任务,分别是:
- Select列数
- Where列数和连接符
- Select列
- Select列操作
- Where列
- Where每列的运算
- 值抽取
- 值匹配
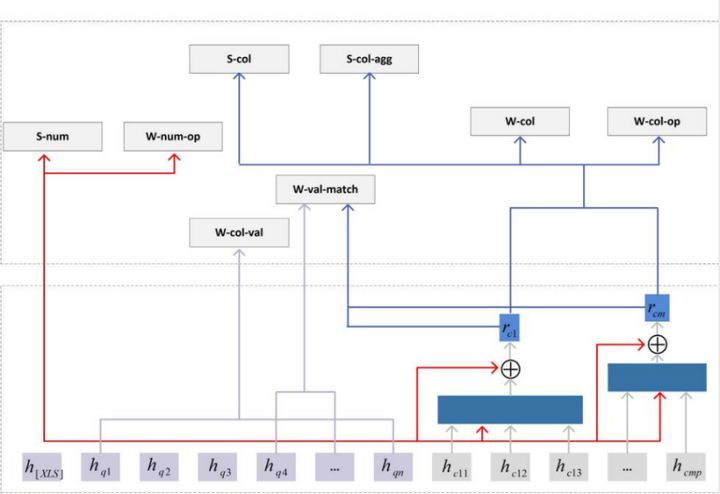
接下来,我们对这8个子任务分别介绍一下它们的做法。
任务一:S-num:Select中出现的列数。[1、2](2分类)
首先是Select当中出现的列数。对于TableQA数据集,Select当中出现列数只可能是一列或者是两列,因此我们可以当做是一个二分类的问题:利用 XLS的 embeding做线性变换,然后过sigmoid的得到它的概率。
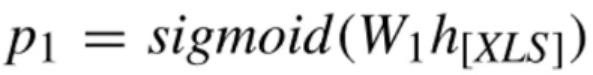
任务二:w-num-op:Where中的连接符和条件数。[null-1、and-1、or-1、and-2、or-2、and-3、or-3](7分类)
第二个任务是Where当中出现的连接符和条件数。所谓“连接符”,指的是“And”还是“or”等;条件的个数,指的是Where当中所出现的“>”、“<”、“=”等等条件的个数。我们可以将他们分成了7个类别,“-”前面的就是连接符,“-”后面的这些就是条件的个数。当然也可以把这两个任务进行分开,但是如果把这两个任务进行分开的话,效果与两个任务一起做相比,会大打折扣。
那么总共是有7个类型,就可以看成是7分类的问题,因此还是 XLS表示过一个线性变换,然后再经过softmax,就可以得到这7个类别上的概率分布。
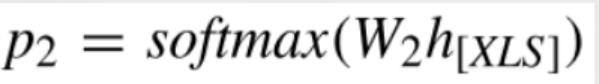
第三个和第四个子任务是Select字句和Where字句当中出现的列。我们前面已经预测了Select当中的例数,以及Where当中的例数,那么在这一部分我们分别预测每一例所出现的概率即可。
任务三:S-col:Select 中出现的列
Select中出现的列:利用我们之前每一列得到增强的表示,经过一个线性变换,再过一个softmax就可以得到这一列所出现的概率。
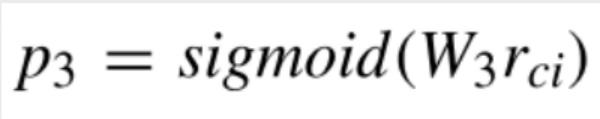
任务四:W-col:Where 条件中出现的列
对Where条件当中出现的列:同样,利用不同的线性变化来进行得到这一列它所出现的概率。
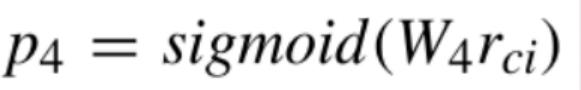
任务五:S-col-agg:Select 中出现的列的操作符
- [Null, AVG, MAX, MIN, COUNT, SUM](6分类)
第五个任务是Select当中出现的这些操作符,这些操作符也被称为是聚合操作。比如说,我们可以求这一列当中所有数据的最大值、最小值或者求平均、求和等等。
在TableQA当中,5种操作符加上NULL一共是6种,我们可以将其看到是一个6分类的问题。同样,我们对每一列的增强的表示做一个线性变换,然后再经过softmax就可以得到每一类的概率分布。
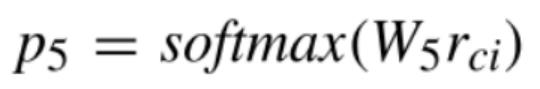
任务六:W-col-op:Where 条件中出现的列对应的条件运算符
- [> / < / == / !=](4分类)
对于Where条件当中出现的这些运算符也是一样。这些运算符,包括这一类大于一个数或者小于一个数,或者是等于某个值,或者不等于某个值,一共是4类,我们可以看作是一个4分类的问题。做法和之前的Select当中的运算符一致,也是给列的增强表示过一个线性映射再经过softmax得到4类的每一类的概率分布,从中的选取最大的作为这一列的运算符。
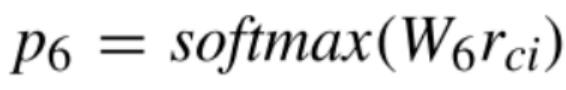
最后两个子任务就是服务于条件值预测。同样以我们前面的例子为例,“大于18岁的学生都有谁”。最后的结果应该是Where条件当中有一个age > 18,那么我们18应该怎样获得呢?作者就问题给它拆成了两个子任务:
任务七:从问题中抽取可能是值的短语
- 使用0/1对问题中的Token进行标记(1表示值,0表示非值),每一组连续的
1标记的token作为一个整体
第一步就是从问题当中抽取出有可能是值的短语。比如说“大于18岁的学生都有谁”这个问题,那么这个子任务就是把“18”从问题当中进行抽出来。我们可以采用的方法是使用0和1对问题当中所出现的token进行标记,比如说“大于18岁都有谁”中的“18”,我们就把它标记成1,然后其他所有的token就把它标注上0,并对于问题当中我们一个token的表述过一个线性变换,使用sigmoid的来预测它到底是1还是0。
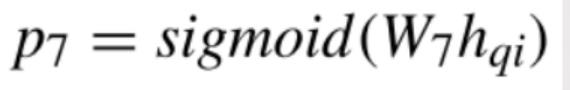
任务八:将抽取出的短语和Where中出现的列进行匹配
在任务七的基础上,我们需要将抽取出来的短语与where当中所出现的列进行匹配。
在前一个步骤,我们已经把“18”给它打上1的标签了,因此也就生成了“18”这个token序列。它是一个可能会出现在某一个条件当中的value,但是它会出现到哪一列之后,是这一步所要确定的事。
将取出来的短语与Where当中出现的列进行匹配,如果短语当中它是由多个token构成的,就把所有的token的text表示求一个平均。如下图,此公式相当于是对短语与where当中出现的列求一个相似度,然后再过一个sigmoid。前面这个u是一个可学习的参数,过一个sigmoid就可以得到短语与列是否匹配:如果匹配就把短语作为列的值,比如说18就跟age匹配了,然后我们就可以写age > 18。
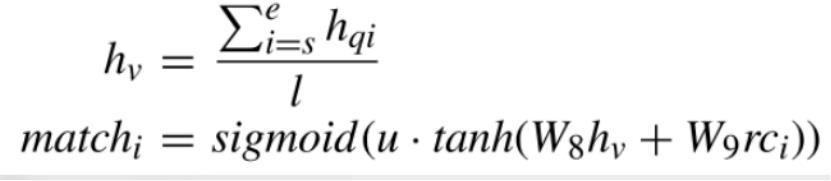
Execution-Guided Decoding
我们已经对上述8个子任务做了简单的介绍。通过这8个子任务,我们就可以得到一条SQL语句,并且保证它是符合了语法规则的。但是它所产生的SQL语句有可能还是不能被执行。
因为SQL语句的内部可能还存在一些限制条件:
- SELECT子句中如果出现string类型的列,则对应的操作不能是’sum’, ‘min’, ‘max’
- WHERE子句中如果出现string类型的列,则对应的操作不能是‘<’, ‘>’
- SELECT子句和WHERE子句中出现的列互不相同(分析数据集得知)
在这些限制下,我们可以采用Execution-Guided Decoding的方法:在decode的过程当中,去掉那些不能被执行的SQL语句,比如说SQL语句执行出来的结果是空,或者压根就不能被执行,从而被会报错,这些SQL语句我们就可以直接被抛弃,而选取符合上述条件的概率最大的SQL语句。
实验结果
接下来是实验结果。
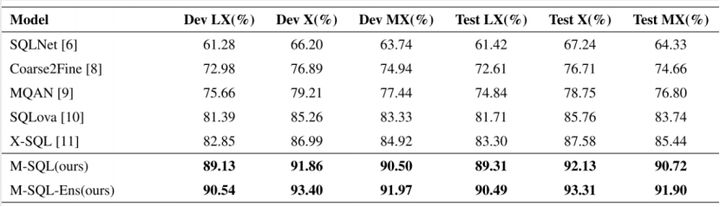
首先简单介绍一下其所采用的评价指标,分别是LX、X还有MX。
LX,就是它的逻辑形式的准确率。如果所生成的SQL语句和标准答案的SQL语句完全一致,那么上面这两个操作正确;如果有一点不一样,比如说“>”写错了,或者是这一列选错了,那么这个例子即错误。
X,就是它的执行结果的准确率。如果两条SQL语句,可能它的逻辑形式不一样(这两个SQL可能存在一些差别),但它的执行结果是一致的,那么也算预测正确。
MX,是前面LX和X的一个平均。它有两个模型,一个是单个模型,一个是集成模型(后面的Ens)。通过Ensemble对多次训练的结果进行集成,最终得到一个更好的结果。从图中我们可以看到它比之前几种模型的结果都要好。
因为之前的模型都是基于WikiSQL进行实现的。我们所采用的TableQA与WikiSQL有一些不同,并且比WikiSQL要更难一些,所以之前的这些模型在TableQA对数据集上的效果并不是很好。
子任务的性能
下图对8个不同的子模型的性能做了对比:
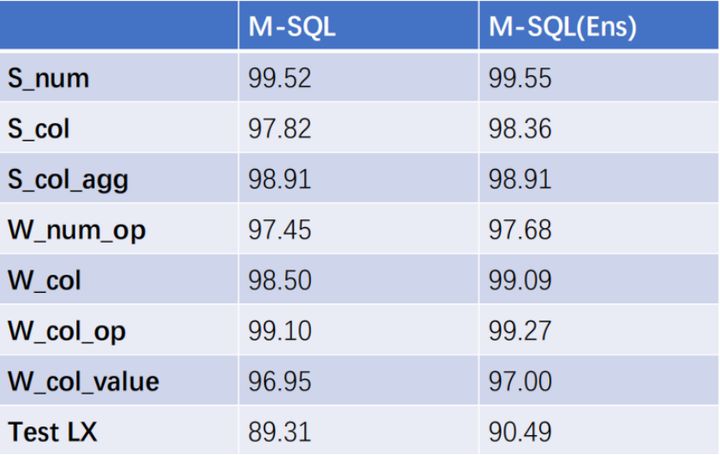
我们可以看到在每一个子模型上,它的效果都是非常不错的,现在经过Ensemble之后就可以达到更好的效果。
消融实验
在实验的最后一部分我们做了一系列的消融实验。
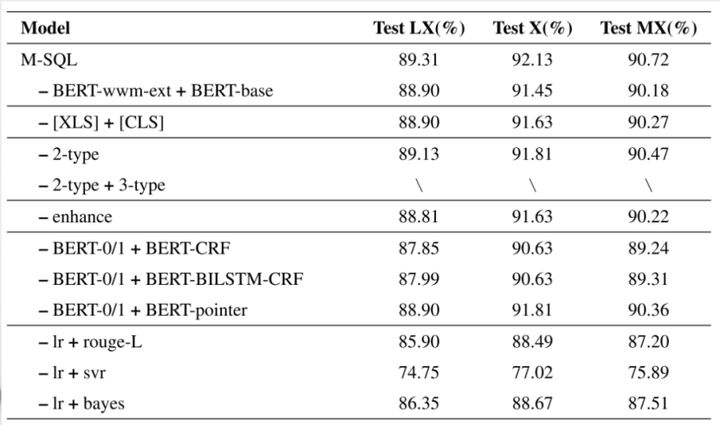
从实验结果我们可以看出,使用BERT-wwm-ext的版本比 BERT-base效果要好,使用XLS作为前置比CLS作为前置的效果要好。图中更下面部分是所使用的一些值的抽取的方法,以及一些值匹配的方法,我们在下面给大家作更详细的介绍。
复现中的细节处理
接下来,我们将介绍在复现过程当中的一些细节处理。
首先是数据预处理的部分。对于这个数据集来说,它的数据是不太规范的,有可能会出现以下情况(括号中表示歧义部分):
- 数字:哪些城市上一周成交一手房超十五万平? (十五,15)
- 年份:你知道10年的土地成交面积吗? (10年,2010)
- 单位:哪些城市最近一周新盘库存超过5万套? (5万,50000)
- 日期:哪个公司于18年12月28号成立? ( 18年12月28号,2018/12/28 )
- 同义:你能帮我算算芒果这些剧的播放量之和是多少吗?(芒果,芒果TV)
前面几个问题,可以直接按照一定的规则来进行转换;而后面这些可以通过到数据库当中去找相关的品类词做一个替换。
值的抽取
在“值抽取”这一部分的,我们尝试了很多种方法,比如说bert+crf的方法,bert+bilstm+crf,以及bert+半指针的方法。最终所采用的还是0/1标记的方法,因为它的效果是最好的。
- bert + crf,val_acc: 0.8785
- bert + bilstm + crf,val_acc: 0.8801
- bert + 半指针,val_acc: 0.8891
- bert + 0/1 标记,val_acc: 0.8922
0/1的方式是如何实现的呢?我们以问题是“青秀南城百货有限公司在哪?”为例来详细讲解一下。
query:青秀南城百货有限公司在哪?
bert_tokenizer:[‘[XLS]’, ‘青’, ‘秀’, ‘南’, ‘城’, ‘百’, ‘货’, ‘有’, ‘限’, ‘公’, ‘司’, ‘在’, ‘哪’, ‘?’, ‘[SEP]’]
value:青秀南城百货有限公司
tag:[0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
首先对此问题进行Tokenizer,然后得到token序列,如果值“青秀南城百货有限公司”出现在SQL语句中,就把这些token给标记成1;对于其他的没有在SQL语句当中出现的,就标记成0。
细节处理
Value检索
由于在value抽取的时候,抽取出来的value可能不太规范,或者是问题当中和数据库当中出现的不太一致。比如说下图中的“人人”与“人人网”:
Query1:人人周涨跌幅是多少?
Value:人人

在这种情况下,我们就需要将 value与 SQL这一列当中出现的所有的值做一个检索,选出与之最接近的一个词作为最终的 value。那么如果检索,我们可以选的方法也很多,比如说rouge-L的匹配方式,以及几种机器学习的方法:逻辑回归、SVR以及贝叶斯。通过效果对比,我们可以发现,逻辑回归是最好的方式,其准确度是97%。
Table-Column 信息增强:
最后一部分,使用表的内容来对列的表示进行增强。
如上图,比如说地区这一类,从中随机选取一个列值,比如说“广西”,我们这一列就表示成“地区, 广西”这一个整体就作为这一列的一个表示,并把它送到input端,然后再进一步的获得列的表示。通过这种方式对于列进行增强,最终可以获得0.4的效果提升。
复现中的问题及建议
1、数据集不规范,建议抽取选取部分规范的数据进行训练和预测;
2、不要从0开始复现,可以基于现有的模型,参考现有的代码。
M-SQL:一种将自然语言转换为SQL语句的多任务表示学习方法
查看本期论文解读视频、算法链接,请点击:
以上是关于M-SQL:超强的多任务表示学习方法的主要内容,如果未能解决你的问题,请参考以下文章