推荐系统中的多任务学习
Posted 爱好上班摸鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统中的多任务学习相关的知识,希望对你有一定的参考价值。
本文纯属乱说,如有雷同,纯属巧合。
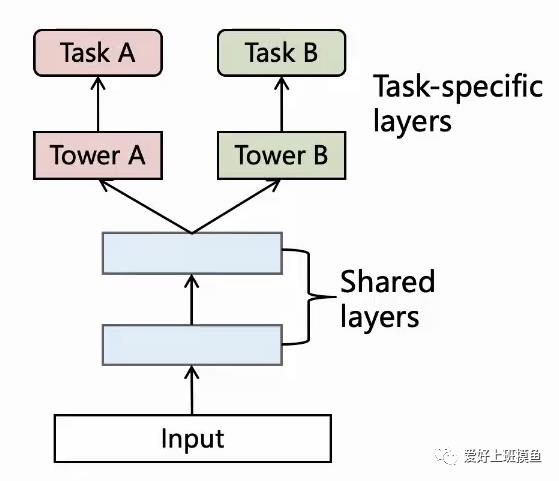
多任务学习最早起源于cv和nlp,我们直接进入正题,下图是最简单的多任务学习模型框架。
对于任务A和任务B,底层网络参数共享,上层各自任务做各自的loss,各loss以某种计算方式加总在一起形成最终loss,再实现梯度回传,更新网络参数。
从以上结构和描述不难看出多任务学习优点:
知识共享:鼓励模型学习任务之间通用共享的东西
正则:利于学到使用新任务上的泛化表征
互助表征学习:有更立体的监督
多任务学习在推荐系统的兴起
推荐系统的一个很大的挑战是——对用户满意度很难直接学习。刻画推荐系统效果的好坏就是通过用户的满意度,但这是一个非常复杂的深度语义变量,没有直接的量化监督,在内容领域我们一般通过总时长,点赞分享,用户留存这几个维度来刻画。
但是这里面也存在偏差。对于用户1,他会用点赞的方式来表达他对内容的满意;但对用户2,用评论的方式来表达他的满意;对于用户小3,又用在视频页面长时间浏览来表达他的满意。即存在用户偏差和目标偏差。另外对于一个视频,可能标题是 “不点赞不是中国人”,这样的视频可能存在大量点赞,但他并不是用户满意的视频,所以也存在物品的偏差。
正因为有以上的种种偏差,所以我们没办法只做一个点赞模型,或者只做一个时长模型,因为单一的这些维度都会带来大量的偏差,所以我们需要一个多任务的学习,目标既考虑时长,也考虑视频的完成率,也考虑点赞分享等等。我们希望这样的模型能高效协同各个具体任务,利用所有的信息进行充分学习。
那么为什么近两年多任务学习才流行呢,主要由于以下几点。
产品形态化的改变:传统的产品(无论是电商还是信息流)都相对串行。比如从曝光到点击,从点击到转化,是一个很强的衰减漏斗,我们做一个单独的点击ctr模型和一个单独的转化cvr模型就能解决问题。现在很多内容产品都是全屏沉浸式的,每一个视频都是自动播放,没有点击的概念,每一个视频用户都会看到,没有一个很强的衰减漏斗,只能通过用户的各种隐式反馈进行监督信号的度量。
模型结构的不断迭代:早期的推荐系统模型大多是LR,GBDT,随着深度学习的发展,后来不断演化为DNN,Wide and Deep,DeepFM等等,显然深度模型和多任务学习更适配。
多任务学习和强化学习自身的进展。
考虑抖音,快手,微视等沉浸式视频场景。我们可以有以下目标:
为了描述的方便,我们这里只考虑稠密的目标(互动行为是相对稀疏的),以1,2为例。
为了最大化播放时长和播放完成率,我们如何刻画正负样本呢。可以对视频的物理时长分段(比如0-10秒为一段,10-20秒为一段),在不同物理时长段的样本中,统计该分段的播放完成率分布,把头部的样本作为正样本,尾部的样本作为负样本。之后根据播放时长对正样本加权,播放时长越长,样本的权重则越大。这是最简单粗糙的一种多目标的表达。
版本一的划分正负样本需要依靠人工对分布的统计,这既不精确,也不灵活,每一次迭代都需要人工的统计。我们考虑不对样本进行正负的划分,直接以回归的方式预估播放完成率和播放时长。做一个完成率回归模型和时长回归模型,线上预估时,两个模型各自完成打分,以某种融合方式融合成为最终的得分。
版本二依赖于多个模型,每个模型就需要一套训练的机器资源和预测的机器资源,且多一套模型就多一套人工维护成本,不利于成本的节省。我们希望一个模型能解决多个目标,于是引入了本文开头的最简单额多任务学习的模型框架。后续业界的大多数进展也基于多任务学习的模型框架的优化。从基础的hard sharing,到2018年阿里巴巴引入ESMM,到2018年google引入的MMOE,到今年腾讯引入的PLE。
在版本二中我们提到“以某种融合方式融合成为最终的得分”,版本三的一个模型多头输出自然也需要把这些多个输出得分进行融合。具体如何融合对于目前的业界中是一个还没有成熟范式的问题。可以的做法有:
a * 完成率打分 + b * 时长打分 + c * 是否完播的概率打分 + .....
(完成率打分 ** a) * (时长打分 ** b) * (是否完播的概率打分 ** c) ....
其中a,b,c,d的设定可以是根据开启上帝视角+业务经验+业务主要目标的倾向。线上的打分融合还可以根据一些算法,比如贝叶斯,比如粒子群算法,比如强化学习。
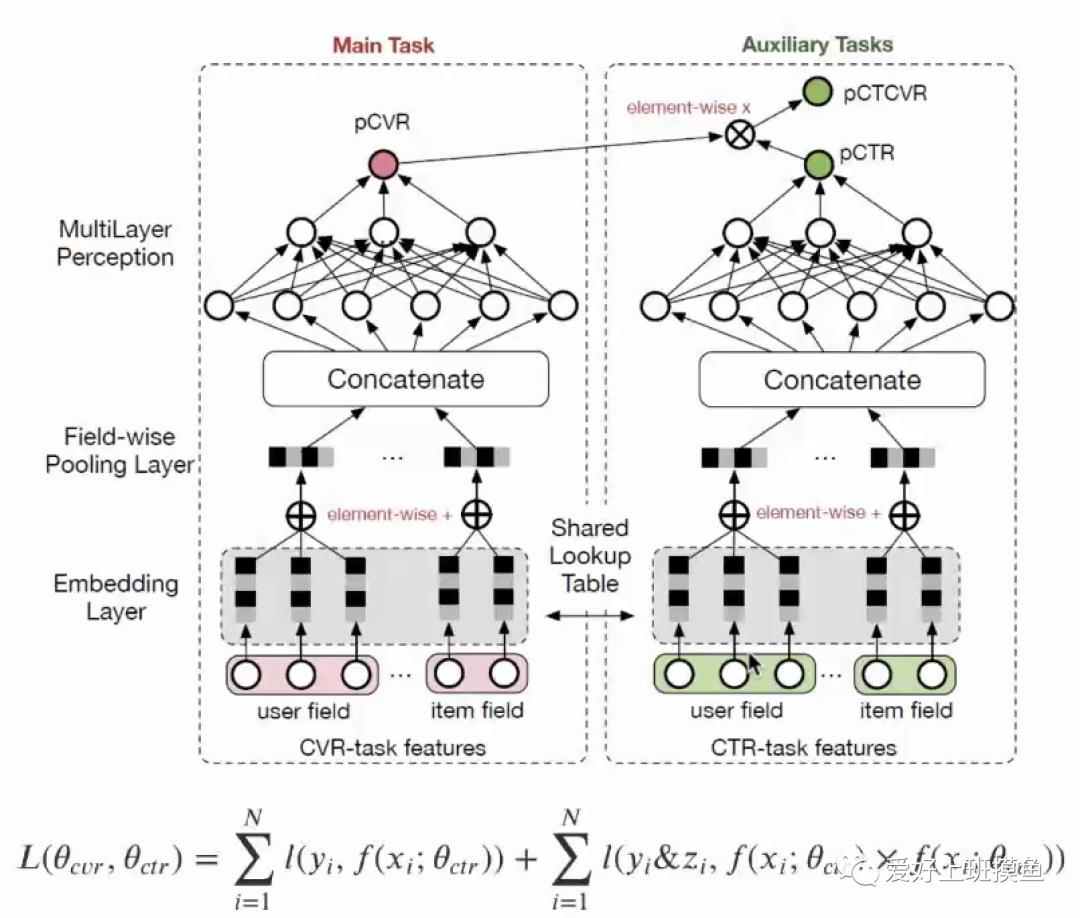
电商购物我们的目标一般是ctr(点击某商品的概率)和cvr(点击商品之后购买商品商品的概率)。那么训练ctr的模型正样本是点击的商品,负样本是曝光不点击的商品,样本空间是所有曝光的商品。cvr模型正样本是购买的商品,负样本是点击不购买的商品,样本空间是所有点击的商品。假设两个模型已经训练完毕。在线上预估的时候,我们对候选商品进入这两个模型获得打分。这里的问题在于线上预估时,进入cvr模型的样本的空间是所有样本(这个样本可能用户根本不会点击),但训练时该模型的样本空间却是所有点击样本,导致训练和预测时样本空间不一致。于是ESMM产生了。
本质上这是一个多任务学习的模型,底层共享Lookup embedding,上层一个目标是cvr,一个目标是ctr,但是该模型的创新点在于做loss的时候它考虑的不是cvr和ctr,而是ctcvr和ctr(ctcvr即cvr * ctr)。这里pCVR没有显式的监督信号。这样训练的时候,对ctr,正样本和负样本仍然是点击和不点击,ctcvr的正负样本分别是购买和不购买。这样样本空间在训练和预估时都是所有曝光的商品。所以该模型ESMM解决了Sample Selection Bias,同时也解决Data Sparsity。
我们再次拿出下图,将下图的结构称为hard-sharing:
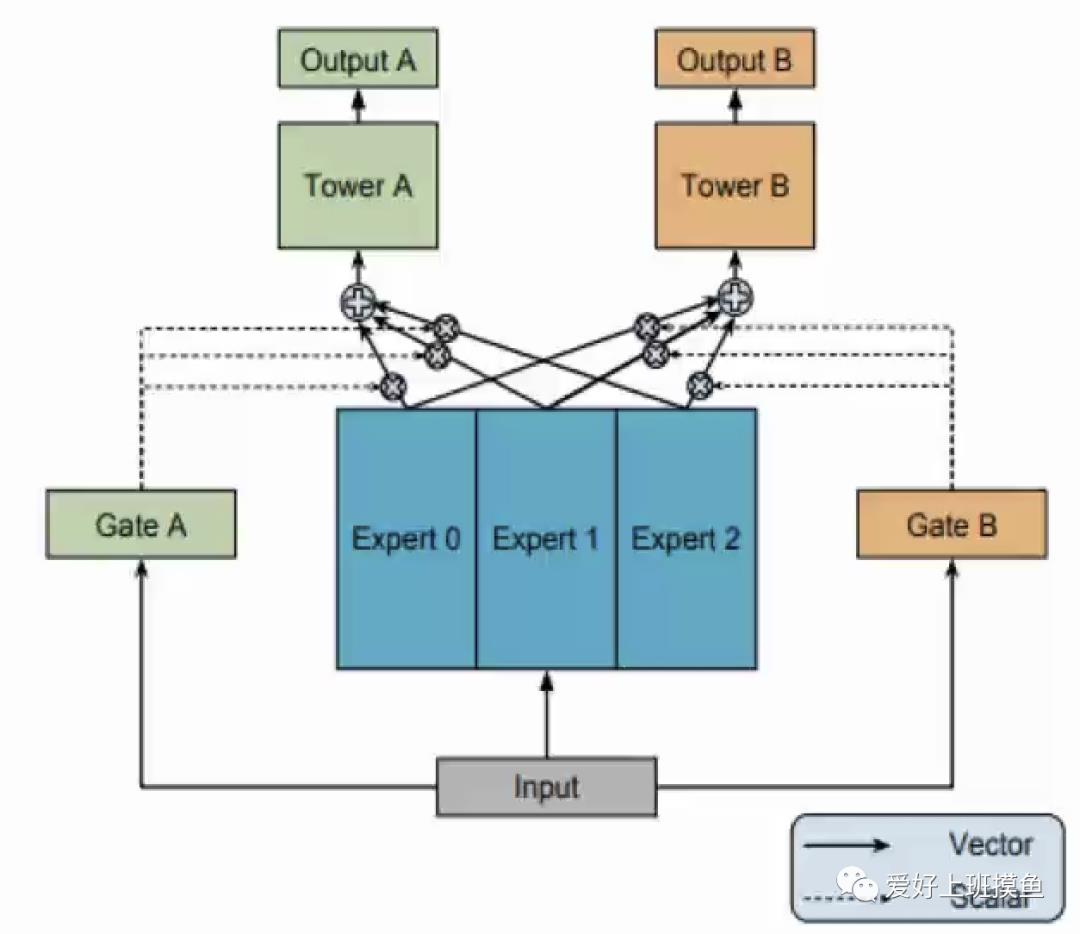
两个任务是各自独立但又有些相关性的,A是一个分类任务,B是一个回归任务,这是二者的不同。但当A是正样本时(即完播),就意味着B的完成率至少为1.0(考虑重复播放为一条样本,完成率可能大于1),从这个角度两个任务是相关的。那么hard-sharing真正能刻画好这种独立性和相关性吗,甚至会不会两个任务直接还会有相互负面的影响呢。事实上,实验证明,当两个任务如果相关性很弱,hard-sharing的效果不佳,任务之间相互影响冲突,导致效果可能不如单目标模型。于是,MMOE产生了。
底层输入进入k个专家网络,专家网络结构随意设定,最简单的便是几层全连接,每个专家独立输出各自的最后一层向量,通过门控(Gate产生一个k维的权重)的结构进行加权求和,再前向传播,不同的任务有各自的门控。门控可以是一个对input进行softmax的算子。
从该结构不难看出,MMOE能够清晰地从数据中学习任务之间的关系,在所有任务共享expert的同时,通过训练gating network来优化每一个任务。expert是共享的,gate是轻量的,整个模型在上层不会显得很笨重。实验证明,在任务之间的相关性比较弱时,效果会很好。
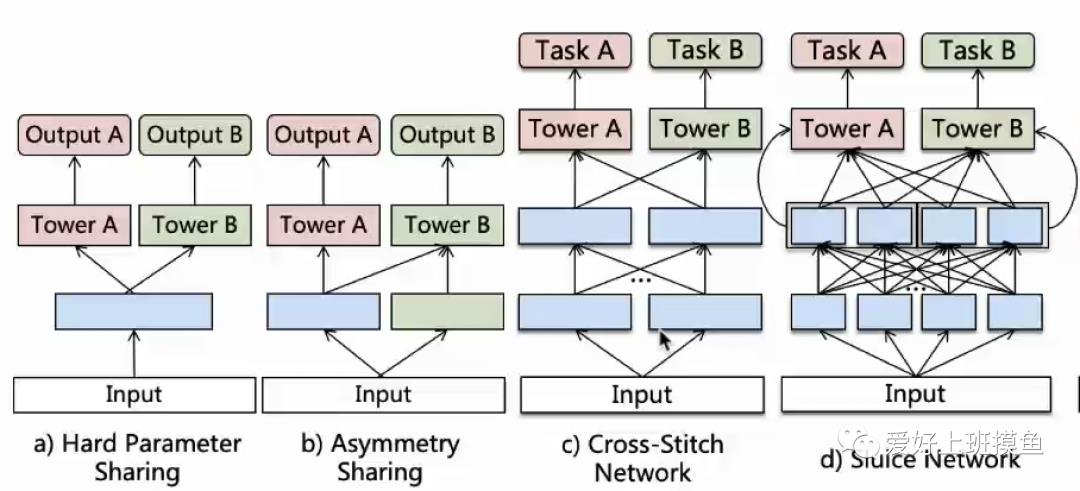
在做沉浸式视频推荐的模型研究时,同样考虑任务A为是否完播,任务B为播放完成率。我们会发现有所谓的“跷跷板”现象,使用hard-sharing主体结构时,如果我们稍微对A进行优化,可能会提高A的auc,但是会发现B的效果会变差,反之亦然。对hard-sharing变体了下图的种种结构,都发现无法同时优化A和B。
当我们使用MMOE时,发现A和B都能得到优化,但是提升比较有限。于是产生了PLE。
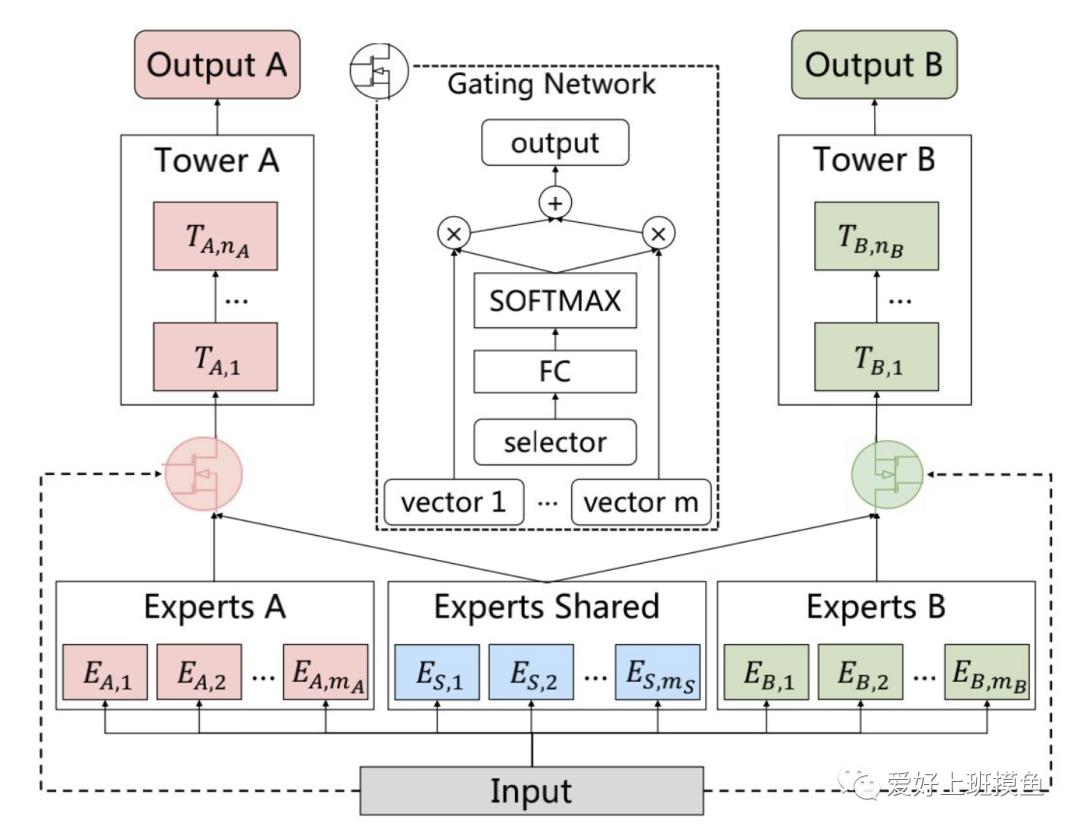
话不多说,直接上图,先上一个PLE的简化版CGC结构。
从网络结构可以看出,底层网络主要包括shared experts和task-specific expert构成,每一个expert module都由多个子网络构成,子网络的个数和网络结构都是超参数;上层由多任务网络构成,每一个多任务网络(towerA和towerB)的输入都是由gating门控进行加权控制。
蓝色部分为共享专家层,红色和绿色分别为各自任务的专家层。本质上该网络是通过共享专家层和两边的独立专家层通过门控结构进行加权求和传输到上层。和MMOE的显著区别在于区分共享隐层和独立隐层,独立隐层为特定目标专属,不收到其他目标影响;而MMOE则将所有隐层平等看待,不进行区分,即每个隐层的参数均会收到所有目标的影响。这里设计上下两层专家层也是考虑到不同深度语义的输出也许仍有互助借鉴学习作用。该模型是在分层共享+分层专属+门控的基础上设计了渐分式路由。实验证明该网络实现了两个任务的离线效果都显著增长。
1、播放时长 2、播放完成率 3、是否完播 4、是否滑过视频 5、是否互动
对时长做(非)线性变换;
在做多个loss融合时,给时长loss一个很小的权重(与对时长做线性变换等价)
多个目标的loss(相同scale)融合时,不同loss的权重怎么设定呢?
阿里巴巴提出了方差不确定性,做过尝试,离线效果不明显
播放完成率是个回归任务,若值域在0,1之间,此时用mse loss更好还是cross entropy loss更好?
线上实验尝试,cross entropy效果更好以及更稳定
以上是关于推荐系统中的多任务学习的主要内容,如果未能解决你的问题,请参考以下文章
19推荐系统19SNR:多任务学习
「回顾」自然语言处理中的多任务学习
19推荐系统18MMoE-PosBias:多任务学习
推荐系统(十四)多任务学习:阿里ESMM(完整空间多任务模型)
推荐系统(十四)多任务学习:阿里ESMM(完整空间多任务模型)
深度学习在推荐系统的应用