19推荐系统18MMoE-PosBias:多任务学习
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了19推荐系统18MMoE-PosBias:多任务学习相关的知识,希望对你有一定的参考价值。
文章目录
1、前言
文章主要聚焦于大规模视频推荐中的排序阶段,介绍一些比较实在的经验和教训,解决Multitask Learning, Selection Bias这两个排序系统的关键点。
为了解决这样的挑战,作者提出了MMoE-PosBias 架构,利⽤ MMoE 框架解决多⽬标问题,并利⽤ Wide&Deep 框架来缓解选择偏差的问题。
MMoE 上⼀篇论⽂有过介绍,选择偏差问题我们在之前介绍的阿⾥妈妈团队的多任务学习算法 ESMM 中也提到过,不过这⾥主要是位置上的选择偏差。
本文描述了一个用户视频推荐的大规模排序服务。具体场景是:给定一个用户播放的视频,生成下一个他可能会播放和喜欢的视频。 典型的推荐系统包含两个阶段:召回(recall),排序(rank)。本文的重点聚焦在排序阶段:对召回阶段输出的数百个内容,应用复杂的模型进行排序,选出其中最有可能被用户喜欢的。
设计与实现一个大规模的线上推荐系统会面临一下挑战:
- 多⽬标问题:视频推荐的⽬标⼤体可以分为参与度(指用户转发、评论、下载文档、观看视频、咨询等交互行为)和满意度(点赞、收藏、评分),这两类⽬标可能有冲突,⽐如说,⽤户喜欢观看的视频和喜欢收藏的视频可能是两种类型的视频;
- 多种用户反馈信号的建模问题。在现实的推荐系统中,除了点击之外,通常会有比较多的 “隐式” 的反馈信号。比如知乎的答案排序中,除了有点击阅读,还有点赞,点踩,用户阅读时长等信号,这些信号其实都可以表征,用户对内容的喜欢程度。
- 经常碰到隐式偏见,例如用户倾向于点击排序靠前的视频,而不是因为他喜欢。如果训练数据处理的时候不考虑到这些因素,会陷入feedback loop effect,进⼀步强化样本偏差。
为了解决这个问题,作者提出了⼀个⾼效的多任务神经⽹络学习架构,如下图所示:
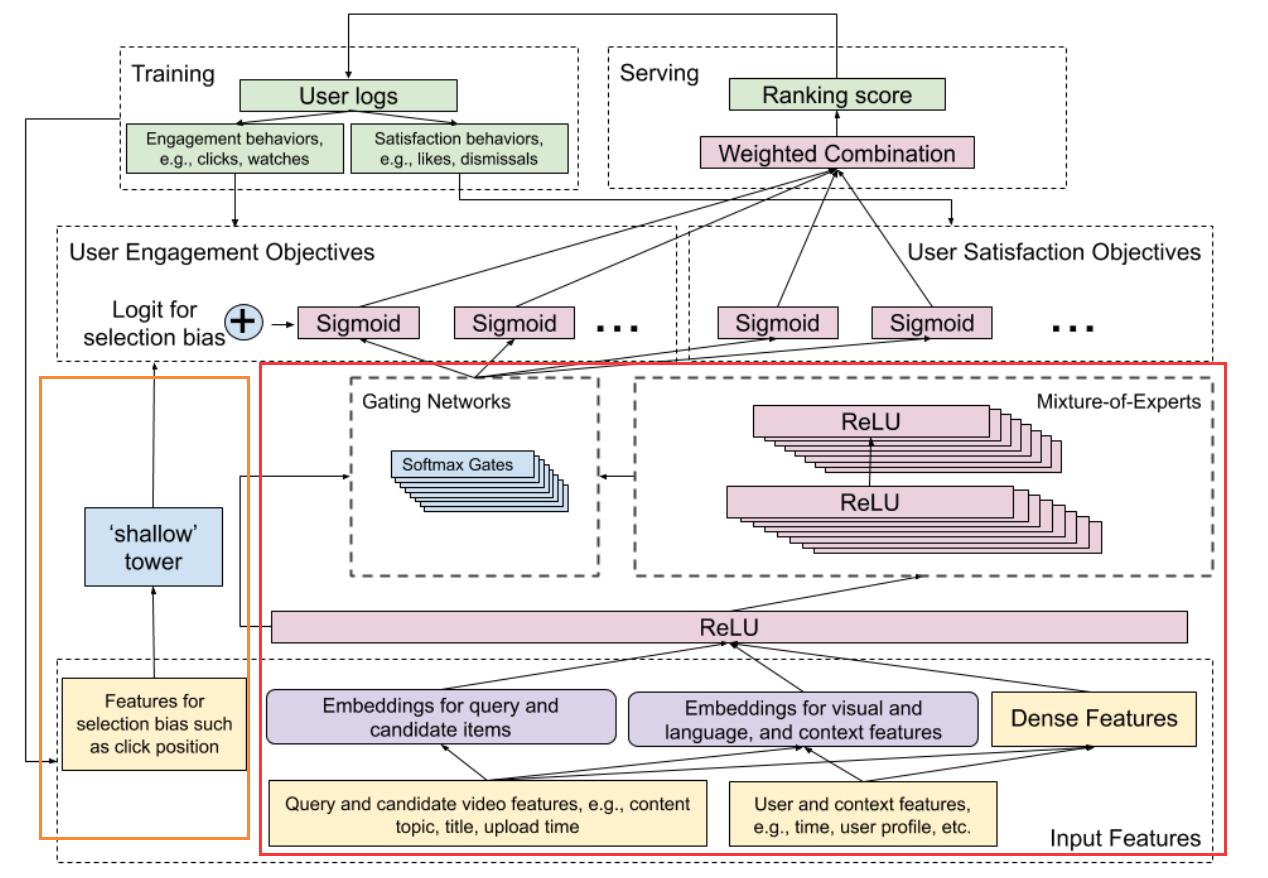
排 序 系 统 的 模 型 架 构 。 它 使 用 用 户 日 志 作 为 训 练 数 据 , 构 建 多 G a t e 和 M i x t u r e − o f − E x p e r t s 层 来 预 测 两 类 用 户 行 为 , 即 用 参 与 度 和 满 意 度 。 它 用 s i d e − t o w e r 纠 正 了 排 序 选 择 偏 差 。 最 重 要 的 是 , 多 个 预 测 组 合 成 最 终 排 名 得 分 。 排序系统的模型架构。它使用用户日志作为训练数据,构建多 Gate 和Mixture-of-Experts层\\\\来预测两类用户行为,即用参与度和满意度。它用side-tower纠正了\\\\排序选择偏差。最重要的是,多个预测组合成最终排名得分。 排序系统的模型架构。它使用用户日志作为训练数据,构建多Gate和Mixture−of−Experts层来预测两类用户行为,即用参与度和满意度。它用side−tower纠正了排序选择偏差。最重要的是,多个预测组合成最终排名得分。
第⼀眼看起来会⽐较乱,⾸先我们可以将其分为上下两部分,上⾯是系统,下⾯是 Wide&Deep 模型。
-
Deep 部分⽤ MMoE 来进⾏多任务学习,利⽤多个Mixture-of-Experts和多个 Gate 进⾏多⽬标预测,并对多个⽬标进⾏线形加权得到最终的⽬标函数;
-
Wide 部分⽤浅层模型代替(shallow tower),接收与选择偏差相关的输⼊,并输出⼀个标量最终预测的偏差项,并与上层的 user engagement 进⾏相加,从⽽减少位置偏差带来的影响。
2、相关知识
推荐问题可以表示为,给定一个query、context和一些items,返回一些高实用 items。例如,一个个性化化的电影推荐系统接受将一个用户的观看历史看作为query,context如周五晚上在家的餐桌上,一些电影,然后返回用户可能观看和享受的电影子集。在这部分,我们讨论一下三方面的相关工作:工业界中推荐系统的研究,多目标推荐系统和理解训练数据中的偏置。
工业界的推荐系统
直接询问用户对item实用的明确反馈的数量很难扩大,因此,排序系统通常使用潜藏反馈,如点击和推荐项的参与度。
大多数推荐系统包括两个阶段:候选生成和排序。
- 对于候选生成阶段,采用了多源信号和模型。例如,用共生items生成候选集,采用基于协同过滤的方法,使用了在(共生)图中随机游走,学习内容表示来过滤items获得候选,描述了一个用特征混合的混合特征。
- 针对排序,使用learning-to-rank框架的机器学习算法广泛使用。例如, 使用线性模型和基于树的模型开发了point-wise和pair-wise学习的排序系统。 用一个现形排序函数和一个pair-wise排序目标。 针对point-wise排序目标使用梯度级联决策树GBDT。 使用了point-wise排序目标的神经网络来预测加权点击。
这些工业推荐系统的主要挑战是容量。因此,它们通常采用基础改进和高效的机器学习算法的组合。为了在模型质量和有效性间平衡,一种流行的选择是用基于深度神经网络的point-wise排序模型 。
一个重要的问题:用户潜在反馈和用户在推荐项上的真实反馈之间的不一致。使用多任务学习技术来支持多个排序目标,每个都和用户反馈中的一种类型相对应。
多目标学习推荐系统
从训练数据中学习和预测用户行为是很具有挑战性的。这里存在不同类型的用户行为,如点击、评分和评论等。但是,每一个都不能单独反应用户的真实意图。例如,一个用户点击了一个item,但是最后却不喜欢它;用户只对点击和参与的项目评分。我们的排序系统需要能够学习和评估多种用户行为和效用,然后组合这些评估来为排序计算出最后的有效分数。
现有的行为感知和多目标推荐工作要么只适用于生成候选集阶段,要么不适用于大规模在线排序。
例如,一些推荐系统扩展协同过滤或基于内容的系统来从多个用户信号学习user-item之间的相似性。 它们在提供最终的推荐时无效。
另一方面,很多存在的多目标排序模型时针对特定类型的特征和应用而设计的,如来自视频标题的文本和来自缩略图的视觉特征, 模型支持来自多通道的特征是极具挑战性的。同时,其他的多目标排序系统,考虑多通道的输入特征不能扩展,由于在多目标中模型参数有效共享的限制。
除了推荐系统研究领域,基于深度神经网络的多目标学习,在针对表示学习的很多传统机器学习应用中也被广泛研究和探索,如自然语言处理和计算机视觉。尽管很多针对表示学习被提出的多任务学习技术,对于构建排序系统不适用,但是一些它们的构建模型激发了我们的设计。在本文中,我们描述了一个基于DNN的针对真实世界推荐的排序模型设计,并且使用了MoE层的扩展来支持多任务学习。
理解和建模训练数据中的bias
用户日志,用作我们的训练数据,从当前品产系统中捕获用户行为和推荐响应。用户和当前系统之间的相互作用创造了反馈中的选择偏置。例如,用户可能点击了一个item,是因为它被当前系统选择了,尽管它不是最整个语料库中最有用的。因此,在当前系统产生的数据上训练的新模型将会偏向当前系统,导致反馈回路效应。如何有效的学习减少这样的偏差对于排序系统仍是一个待解决的问题。
Joachims et al. [22] 首先分析了用来训练学习排序模型的隐式反馈数据中的position bias和presentation bias。通过对比点击数据和相关的显式反馈,他们发现position bias存在于点击数据中,并且严重影响在评估请求和文档之间的相关性中学习的排序模型。基于这个发现,提出了很多方法来去除这样的选择偏差,尤其是position bias。一种常用的做法是将位置作为输入特征注入到模型训练中,然后在serving时通过消融来消除bias。在概率点击模型中,位置用来学习P(relevance |pos)。消除position bias的一种方法是受【8】的启发,Chapelle et al. 用P来评估CTR模型,并假设在位置1没有位置偏差影响。对后,为了消除position bias,我们可以用position作为输入特征来训练一个模型,然后在服务时,将position特征设为1(或者其他固定值如默认值)。
其他的方法尝试从position学习一个bias项,然后将它用作归一化或者正则化。通常,为了学习bias项,需要在不考虑相关性的前提下用一些随机数据来推断bias项(参考’global bias’,’propensity’等)。在【23】中,反倾向分数inverse propensity score (IPS) 是用一个反事实模型学习的,不需要随机数据。在训练SVM的排序时该方法用作正则化。
在真实世界推荐系统中,尤其社交媒体平台,如Twitter和YouTube,用户行为和item受欢迎度每天都有很大的变化。因此,当我们训练主排序模型的同时建模选择偏置时,代替基于IPS的方法,我们需要更有效的方式来适应训练数据分布变化。
3、模型结构
接下来,我们看⼀下具体内容。
排序目标
在多任务排序模型中,作者将⽬标函数分为两类:engagement objectives 和 satisfaction objectives。前者⽤于捕获⽤户的点击观看⾏为、后者⽤户通过点赞收藏评分等来捕捉⽤户的满意程度。
诸多不同的⽬标中,例如点击、点赞作为分类任务,观看时常、视频评分作为回归任务。
最终作者会利⽤线形加权的⽅法来整合多个⽬标函数,并通过微调权重来获得最好的性能。
基于多 Gate 和Mixture-of-Experts层的任务关系和冲突建模
下图展示了两种多任务模型框架:
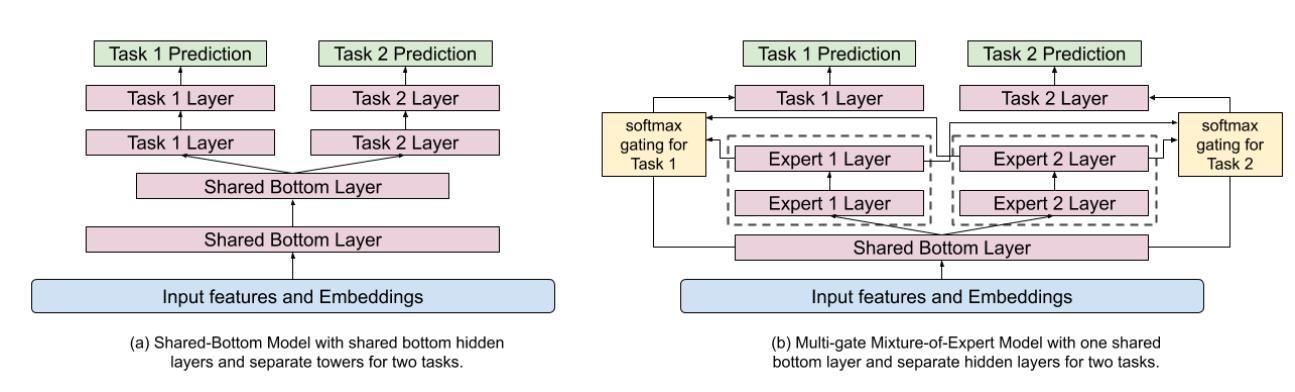
左边为⼀般的基于 hard-parameter sharing 的 MTL 架构,右边是基于 soft-parameter sharing 架构的 MMoE 框架。前者在低相关性的多任务学习中表现⽋佳,⽽后者可以很好的克服这⼀点。
所以作者使⽤ MMoE 作为多任务模型的框架,有助于从输⼊中学习到模块化的信息,从⽽更好的对多模态特征空间进⾏建模。
但是直接⽤ MoE 层的话会显著增⼤训练和预测的计算量(输⼊层维度⽐隐藏层维度⼤)。
所以利⽤ MLP 来实现专家⽹络:
y k = h k ( f k ( x ) ) where f k ( x ) = ∑ i = 1 n g ( i ) k ( x ) f i ( x ) \\begin{array}{c}{y_{k}=h^{k}\\left(f^{k}(x)\\right)} \\\\ {\\text { where } f^{k}(x)=\\sum_{i=1}^{n} g_{(i)}^{k}(x) f_{i}(x)}\\end{array}\\\\ yk=hk(fk(x)) where fk(x)=∑i=1ng(i)k(x)fi(x)
g k ( x ) = softmax ( W g k x ) g^{k}(x)=\\operatorname{softmax}\\left(W_{g^{k}} x\\right) gk(x)=softmax(Wgkx)
其中, n \\mathrm{n} n 为主任务数, k \\mathrm{k} k 某个任务, x \\mathrm{x} x 为输入的 Embedding , f i ( x ) f_{i}(x) fi(x) 为第 i \\mathrm{i} i 个专家网络, g ( x ) g(x) g(x) 为 gate 层。
建模和消除位置和选择bias
通常情况下,用户倾向于点击和观看展示在列表顶部附近的视频,而忽略了他们在观看视频的相关性和用户喜好上的真实的用户效用.
目标是从排序模型中移除这样的位置偏置,减少训练数据中的选择偏差.
有两种⽅法来处理学习到的位置特征:
- 直接作为输⼊;
- 或者利⽤ Adversarial learning 将位置作为⼀个辅助的学习⽬标来预测,并在反向传播阶段把提督取负,这样主模型便不会依赖位置特征了。
作者的实验表明,直接作为特征进⾏输⼊在深层⽹络中的效果不太好,所以采⽤了第⼆种⽅式来处理位置特征。
位置偏差是选择偏差中⾮常常⻅的⼀种,作者通过增加⼀个浅层⽹络来减少由于推荐产⽣的⽤户选择偏差,并打破有选择偏差导致导致的反馈循环,其结构如下图所示:
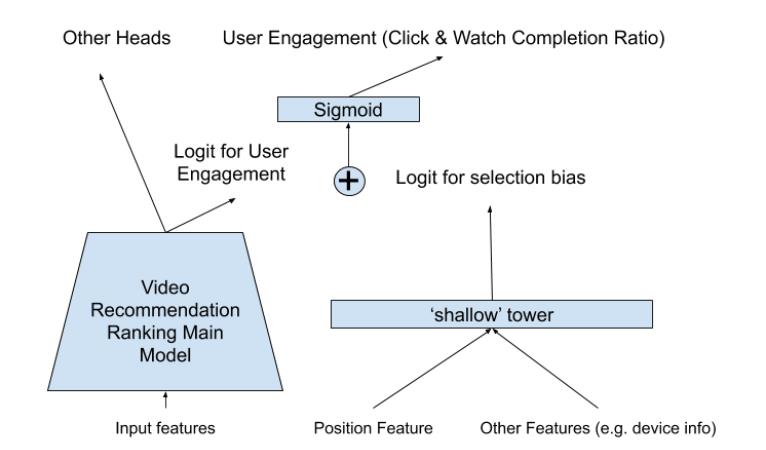
图
3
图3
图3
我们提出的模型结构类似于Wide&Deep框架。我们将模型预测分解为两部分:来自主塔(左边的)的用户效用部分,和来自shallow塔的bias部分。作者利⽤ shallow tower 去建模偏差,其输⼊的是与偏差相关的特征(如物品展示位置、⽤户设备信息等),输出的是⼀个偏置项标量,然后将它和主塔的最后logit相加,并经过 Sigmoid 函数得到最终的输出。如图3所示。
此外,在学习的时候,为了减少对位置的过分依赖,作者还会对模型所有偏差特征进⾏ 10% 的 dropout。
参考
Recommending What Video to Watch Next: A Multitask Ranking System
阅读笔记——Recommending What Video to Watch Next: A Multitask Ranking System_zhangw
阅读笔记——Recommending What Video to Watch Next: A Multitask Ranking System_zhangw
以上是关于19推荐系统18MMoE-PosBias:多任务学习的主要内容,如果未能解决你的问题,请参考以下文章