「回顾」自然语言处理中的多任务学习
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「回顾」自然语言处理中的多任务学习相关的知识,希望对你有一定的参考价值。
分享嘉宾:邱锡鹏 复旦大学计算机科学技术学院 副教授,博士生导师
编辑整理:靳韡赟
内容来源:DataFun AI Talk《自然语言处理中的多任务学习》
出品社区:DataFun

本次报告内容的题目是自然语言处理中的多任务学习,报告主要分为四个部分:
1、基于深度学习的自然语言处理;
2、深度学习在自然语言处理中的困境;
3、自然语言处理中的多任务学习;
4、新的多任务基准平台。
首先简单介绍一下实验室情况,课题组主要聚焦于深度学习与自然语言处理领域,包括语言表示学习、词法/句法分析、文本推理、问答系统等方面。开源自然语言处理系统FudanNLP,并将在12月中旬推出全新的NLP系统:fastNLP。

一、自然语言处理简介
自然语言处理就像人类语言一样,与人工语言的区别在于它是程序语言,自然语言处理包括语音识别、自然语言理解、自然语言生成、人机交互以及所涉及的中间阶段。下面列举出了自然语言处理的基础技术、核心技术和一些应用:
基础技术:词法分析、句法分析、实体识别、语义分析、篇章分析、语言模型;
核心技术:机器翻译、自动问答、情感分析、信息抽取、文本摘要、文本蕴含;
应用:智能客服、搜索引擎、个人助理、推荐系统、舆情分析、知识图谱。
自然语言处理最初由规则驱动,逐步发展为数据驱动。
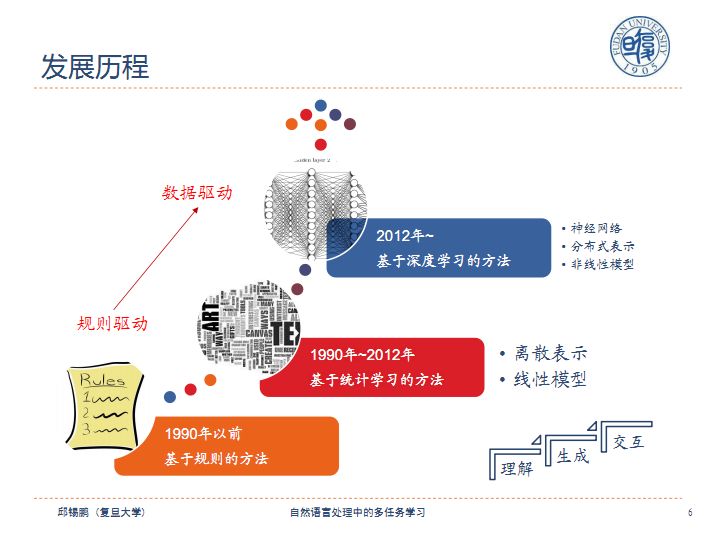
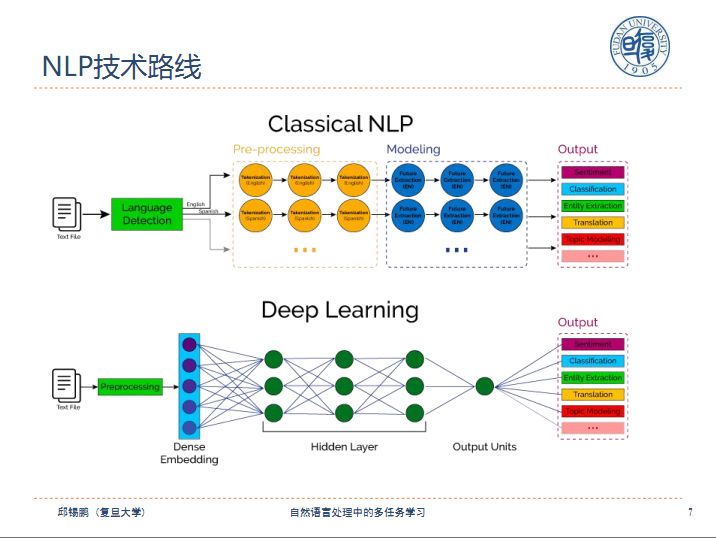
二、深度学习在自然语言处理中的困境
由于缺少大规模的标注数据或者标注代价太高,目前大部分用在NLP上的神经网络都不是很深,一般情况下,一层LSTM+Attention就足够完成大部分NLP任务。解决问题的方法包括有无监督预训练、多任务学习和迁移学习。今天我们主要介绍多任务学习。
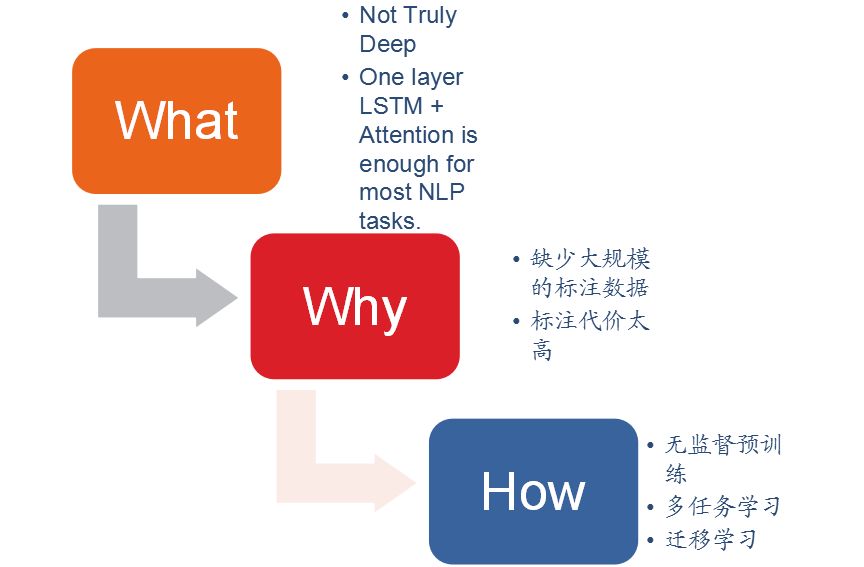
1、无监督预训练
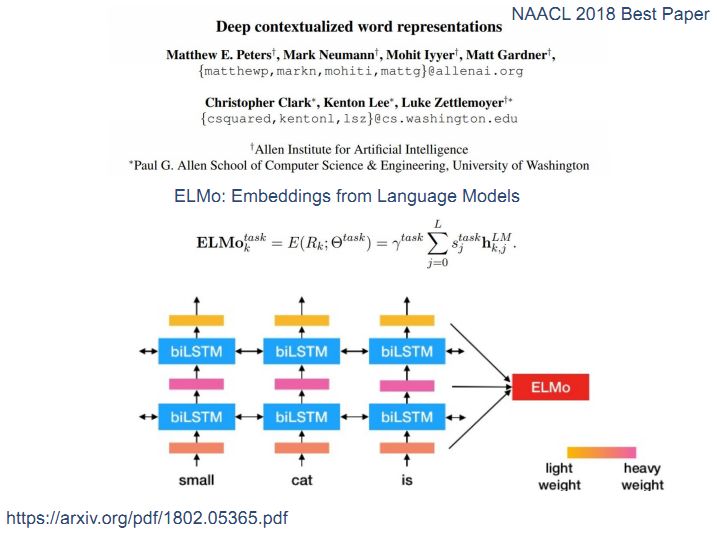
首先我们来介绍一下NLP中非常重要的无监督预训练,早期有很多研究者使用词向量等词级别的模型,后来发展为使用句子级别的模型,例如最近出现的ELMo、OpenAI GPT、BERT等,人们从最初学习更好的词的表示转变为学习更好的句子的表示。

论文Deep Contextualized Word Representations主要描述的是ELMo问题,通过建立两个双向的LSTM来预测一个前向、正向的语言模型,然后将它们拼起来,这个模型是一个非常好的迁移模型。
谷歌新推出的BERT是将机器翻译中的常用模型transformer的双向训练用于建模,它在很多任务中取得了较好的效果。
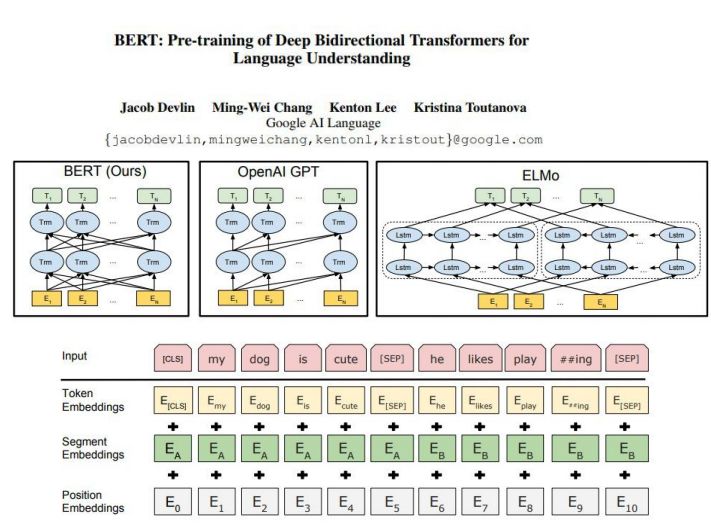
这些模型证明在NLP中表示学习依然十分重要,表示学习是从文本输入到计算机内部的一种表示,对于NLP任务,表示学习是指将语义信息表示成稠密、低维的实值向量。表示好之后送到分类器中,好的表示是一个非常主观的概念,没有一个明确的标准。一般而言,好的表示具有以下几个优点:
1)应该具有很强的表示能力,模型需要一定的深度;
2)应该使后续的学习任务变得简单;
3)应该具有一般性,是任务或领域独立的。

2、多任务学习
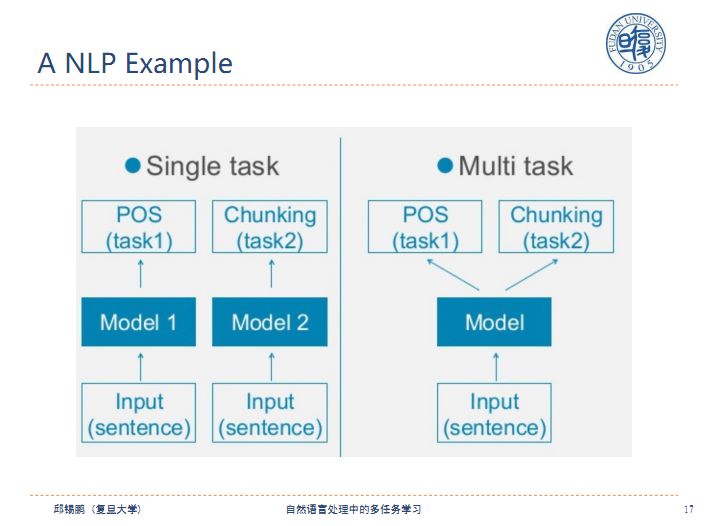
下面给出一个多任务学习的例子,对于两个单独的任务训练两个模型,对于任务1训练一个模型1,对于任务2训练一个模型2,多任务就是将两个任务放在一起用一个模型来处理。
多任务学习最早在97年被提出,多任务学习隐含着从其他任务中学习一种共享的表示,共享表示可以作为一种归纳偏置,归纳偏置可以看做是对问题相关的经验数据进行分析,从中归纳出反映问题本质的模型的过程,不同的学习算法(决策树、神经网络、支持向量机)具有不同的归纳偏置,在学习不同的任务过程中使用共享表示,可以使在某个任务中学习到的内容可以帮助其他任务学习的更好。

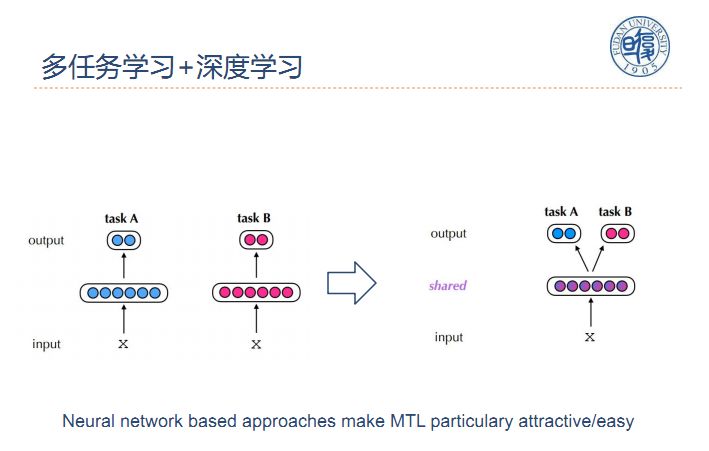
由于传统NLP的表示空间是离散的,MTL+NLP在传统的NLP模型是非常难实现的,随着深度学习的应用,整个NLP的表示空间变为连续的,使得任务实现更加容易。例如下图中taskA和taskB两个任务可以共享同一个模型。
不同学习范式之间的关系:多任务学习之上有迁移学习,之下有多标签学习和多类学习。

损失函数:假设有m个任务,多任务学习的损失函数是将各个任务的损失函数相加求得联合损失函数joint loss。
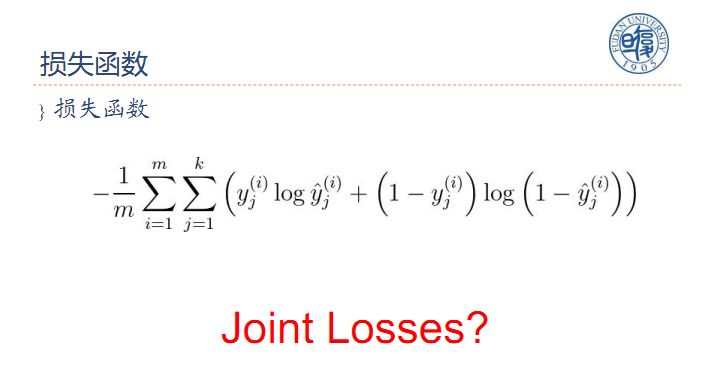
训练方式:首先进行Joint Ttaining,Training之后进行Fine Tunning。

多任务学习工作的优点:
1)隐式的数据增强:一个任务的数据量相对较少,而实现多个任务时数据量就得到了扩充,隐含的做了一个数据共享。
2)更好的表示学习:一个好的表示需要能够提高多个任务的性能。
3)正则化:共享参数在一定程度上弱化了网络能力,防止过拟合。
4)窃听:某个特征很容易被任务A学习,但是难以被另一个任务B学习,这可能是因为B以更复杂的方式与特征进行交互或者因为其它特征阻碍了模型学习该特征的能力。通过MTL,我们可以允许模型窃听,即通过任务A来学习该特征。
目前NLP中每个任务只做其中的一块,如果我们把这些任务拼起来会取得更好的效果。
三、自然语言处理中的多任务学习
下面介绍几种多任务学习的方式,传统的自然语言处理在输入端输入文本,之后进行词法分析和句法分析最后完成任务,这种方式很难实现,在有了多任务学习之后,不同的任务可以共享词法分析和句法分析模块,自然语言处理的方式得到了简化。
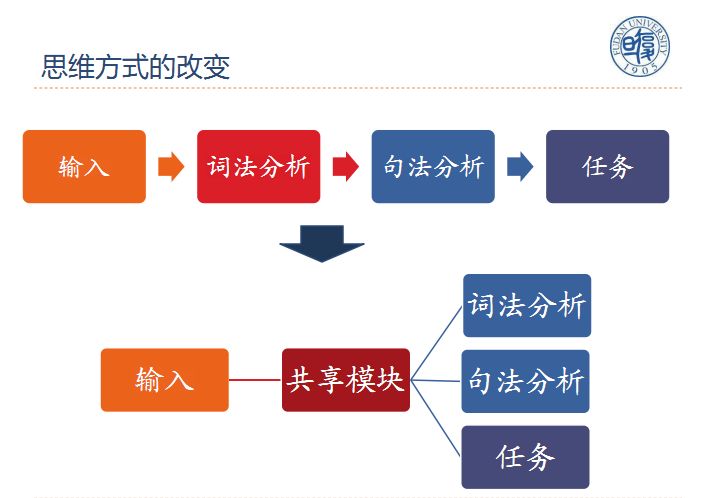
自然语言中的多任务学习包括有:多领域任务、多级任务、多语言任务、多模态任务等。
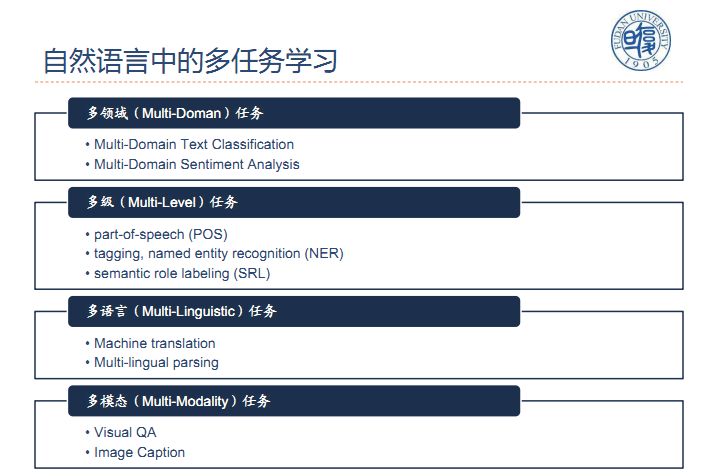
深度学习+多任务学习有硬共享、软共享、共享-私有等多种模式。
硬共享模式:在下面层共享,上层根据自己不同的任务做不同的设计;
软共享模式:每个任务都有自己的流程,从信息流来看就是从输入到A有自己的体系流程,还可以从其他任务的表示方法中拿一些东西过来;
共享-私有模式:一部分共享,一部分私有的信息传递机制。
此外还有多级共享、函数共享、主辅共享等多种共享模式,下面将一一介绍。

1、硬共享模式
硬共享在下面层共享,上面根据自己的不同的任务来做不同的设计,这种方法最早在2008年由Ronan Collobert在论文A Unified Architecture for Natural Language Processing:Deep Neural Networks with Multitask Learning中提出,应用到了很多与语义相关和语法相关的方面,例如机器翻译、文本分类等。

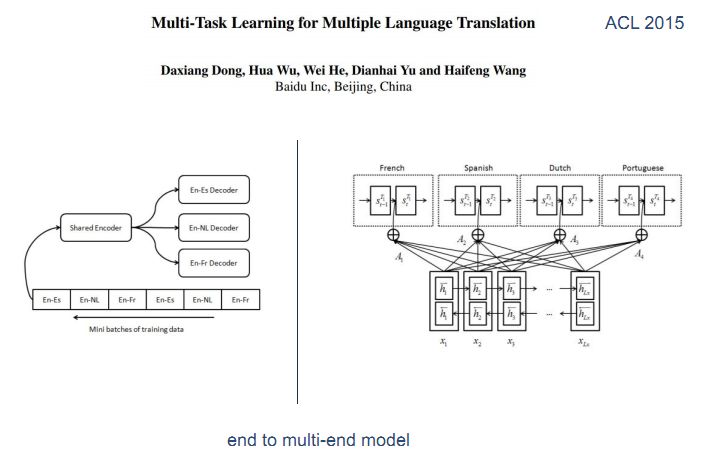
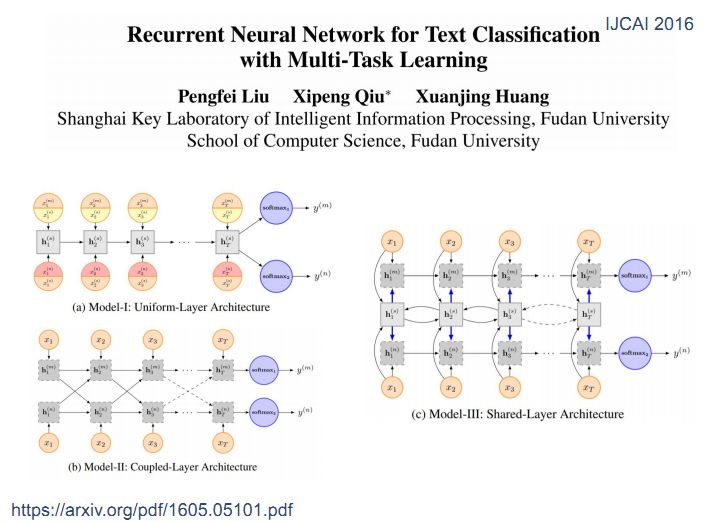
后来人们将注意力机制模型用于共享模式,注意力机制不需要使用所有的信息,只需要将其中部分信息选择出来,人们基于注意力机制做了共享模式。
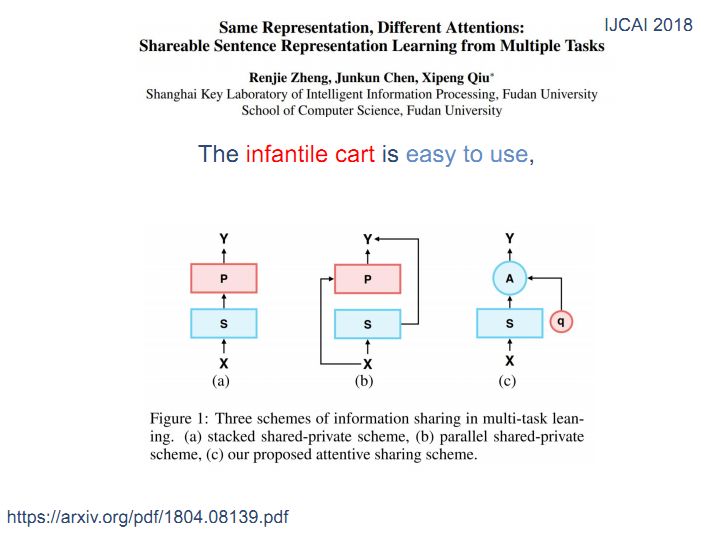
原来的多任务学习如图a所示,下面的s是共享层,p是不同任务自己的设计。现在我们将原有的算法转换大图c的形式,所有的表示函数共享,在输入到具体任务的时候使用一个和任务相关的查询Q去s中选择任务相关的信息。虽然表示方式是一样的,但是针对不同的具体任务,会根据每个任务关注点的不同来选择相应的信息。
2、软共享模式
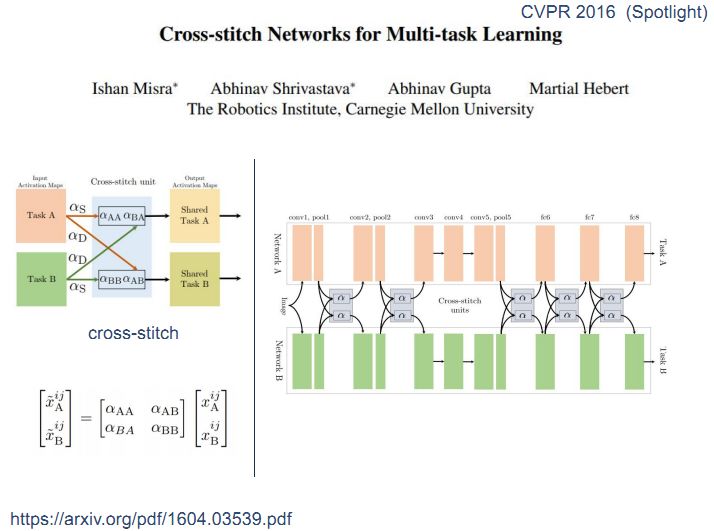
在软共享模式中没有严格规定共享层。经典网络cross-stitch结构中,上面是taskA,下面是taskB,在中间部分两个任务有交互,α是权重系数,表示taskA中有多少信息从自身流过来,有多少信息从taskB中流过来,这样两个任务就由两路,四个系数构成一个矩阵做权重组合,如果用到神经网络就类似于下图中右边的这种形式,这种网络最初应用于机器视觉领域,后来被人们用于NLP。
3、共享-私有模式
在共享-私有模式中部分网络模块在所有的任务中是共享的,通过设置外部记忆共享机制来实现信息共享,神经图灵机就是在神经网络中引入一个memory模块,整个框架就是用神经网络实现的一个控制器,加读写头和外部输入。图灵机全部由神经网络搭建而成。
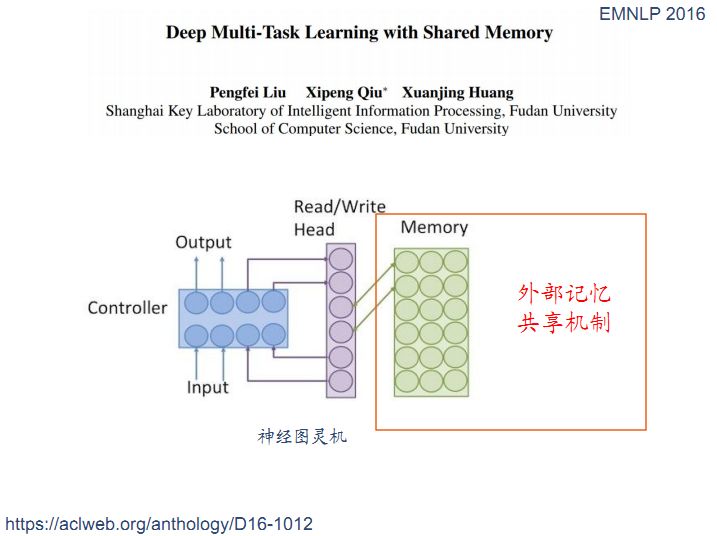
基于神经图灵机的想法我们可以做一个多任务学习,每个任务我们都可以看做是一个单独的图灵机,外部的memory在所有的任务中共享。在下图中M是外部记忆,外部记忆由两个任务共享,每个任务都会把共享信息写到外部记忆中,这是一种非常简单的共享方式。
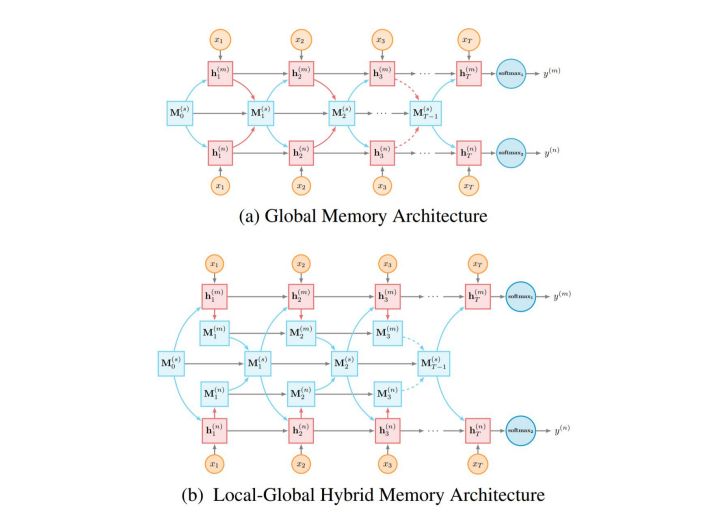

为了避免上图中的负迁移negative transfer,就需要判断哪些内容是和任务相关的,这就引入了近两年流行的对抗学习,在对抗学习中,中间的LSTM共享层有一个判决器来区分共享特征从哪个任务传递过来,在送入LSTM之前会包含有特征的来源信息。因此我们希望训练一个和判决器对抗的网络,在共享的LSTM层中尽可能让判决器不能区分任务来源。这样就去掉了特征的源信息,保证了共享LSTM学到的是与源无关的共享价值信息,这些叫做对抗信息。
下面我们将介绍几种未来研究的方向:
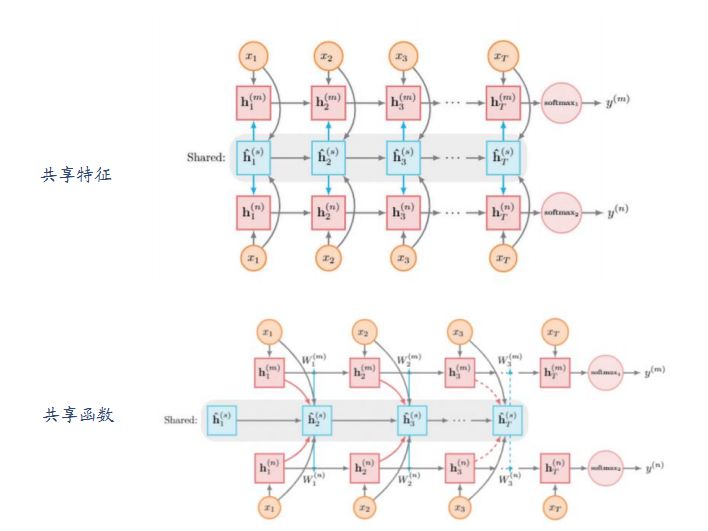
1、函数共享模式
之前我们了解的多任务学习都是特征共享,在函数共享中我们学的不再是共享特征而是共享函数,来生成一些参数或模型,这里我们将feature级的共享迁移到函数级的共享,下图中第一幅图图是特征共享,中间蓝色的是共享层,它将学到的特征送到上下两个任务中,第二幅图是函数共享,函数共享中共享层的输出不是直接送到上下两个分类器中,而是决定了上下两个分类器的参数。通过修改分类器来有效利用这些信息。
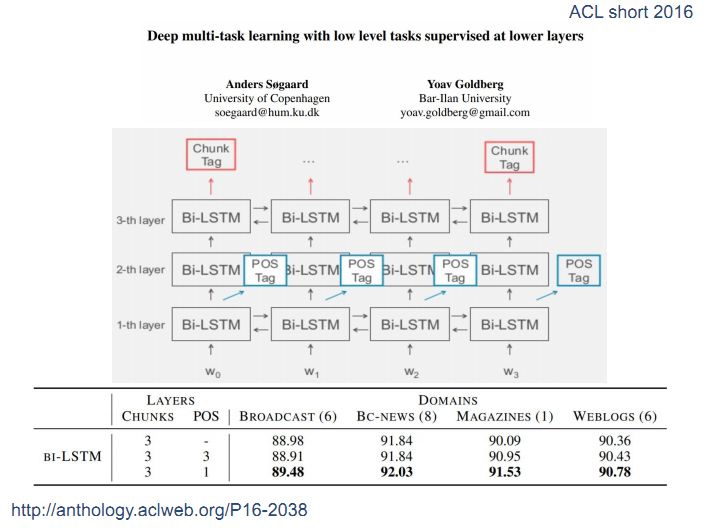
2、多级共享模式
2016年Anders Sфgaard等人在论文Deep Multi-task Learning with Low Levels Tasks Supervised at Lower Layers中提出在低级的网络层次输出低级的任务,在高级的网络层次输出高级的任务。例如在第一层输出词性标签POS tag,在第三层输出chunk tag,将NLP任务按照不同的级别来设计共享模式。
3、主辅任务模式
在做任何一个主要任务的同时都可以引入一个辅助任务。如下图,我们对每个任务引入一个辅助的语言模型,每个任务都使用左右两个语言模型,对所有任务进行这种拓展就形成了主辅任务模式。
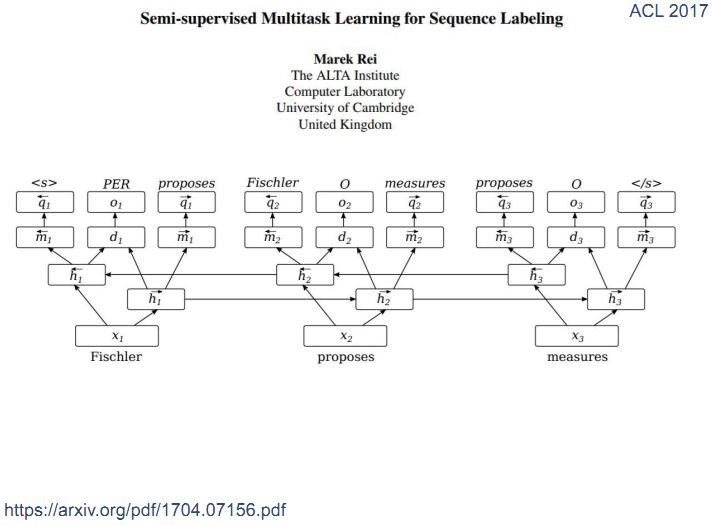
4、共享模式搜索
共享模式搜索是让计算机自动搜索这些共享模式,具体做法如图d所示,我们希望设计一种灵活的框架,在共享池中放入很多不同的模块,每个任务在完成过程中可以从共享池中挑选一些模块来组装自己的guideline。示例中任务A挑选了4、3、1,任务B挑选了3、2、1,这就隐含了A从M4出来,而B从M3出来,C从M2出来,这样一种层次化的共享模式设计。它本身也可以实现hard和soft的两种表示方式,因此是一种非常灵活的表示方式。
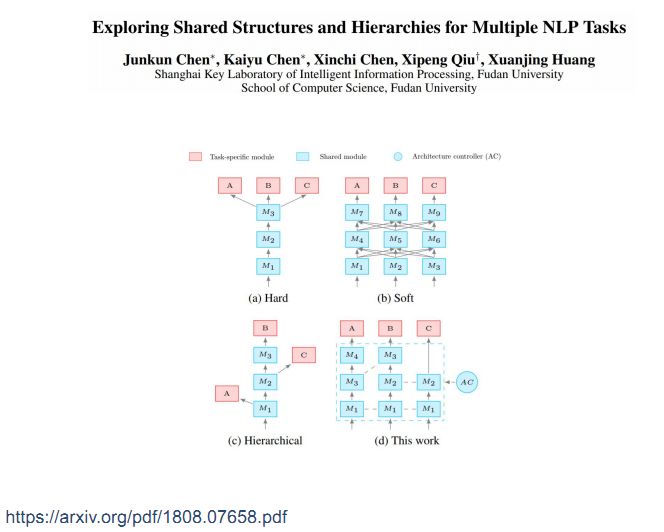
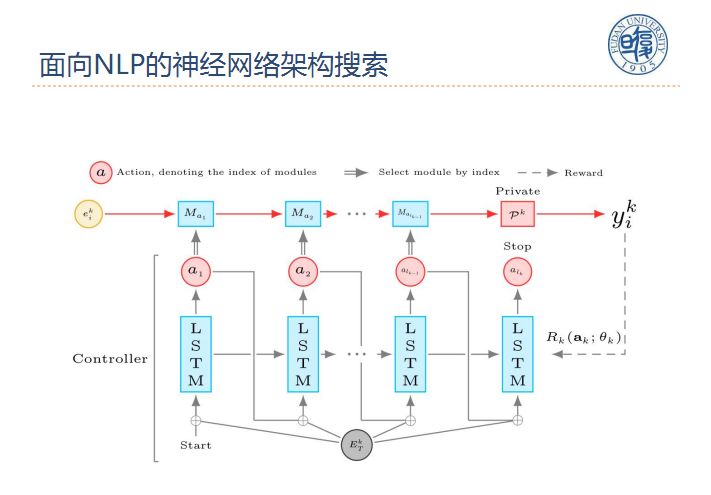
在面向NLP的神经网络架构搜索中,从共享池中挑选Ma1,Ma2等模块来组成不同的模型,将模型带入任务中去训练,得到正确率作为reward反馈给分类器从而选择更合适的组合方式来完成任务。
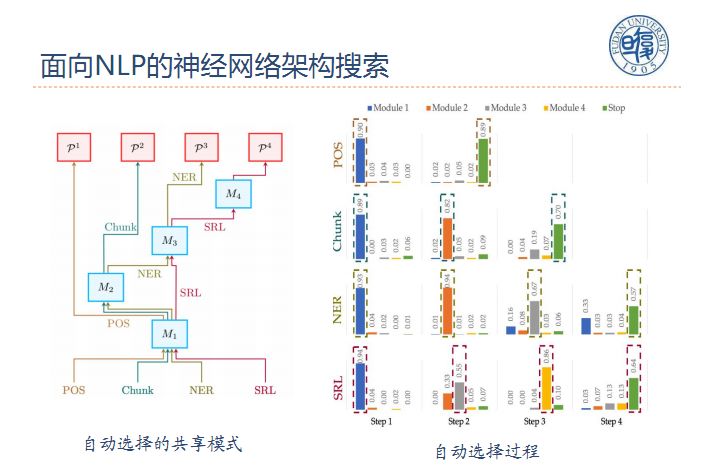
下面给出的例子就是对不同的任务挑选的不同的组合方式,其中有些组合方式非常类似。
四、新的多任务基准平台
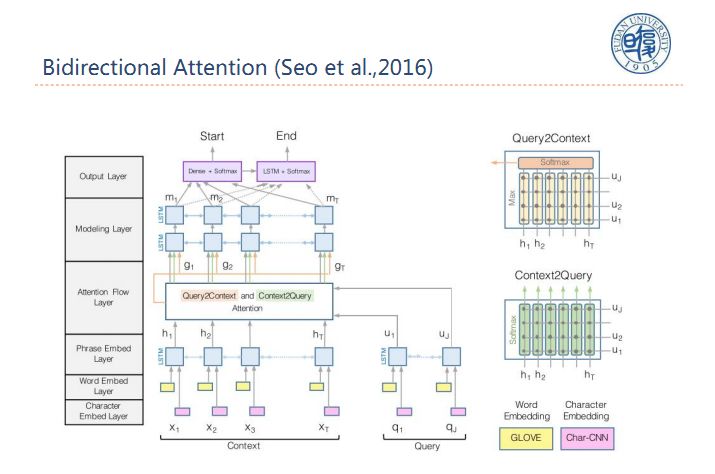
首先介绍一下机器阅读理解,机器阅读理解是在阅读一篇或多篇文档后,回答一些相关问题。由机器来生成答案,答案可能在原文中出现也可能不在原文中出现,目前机器阅读理解大部分都假设答案在原文中出现,我们用的一个主要框架是Biderectional Attention,同时给你context和query,做一个双向的注意力交互,最终确定两个位置,一个是答案开始的位置,一个是答案结束的位置,大部分的问题都可以通过这个框架来解决,这个框架具有通用性。几乎NLP所有任务都可以转化成阅读理解任务通过该框架解决和完成。

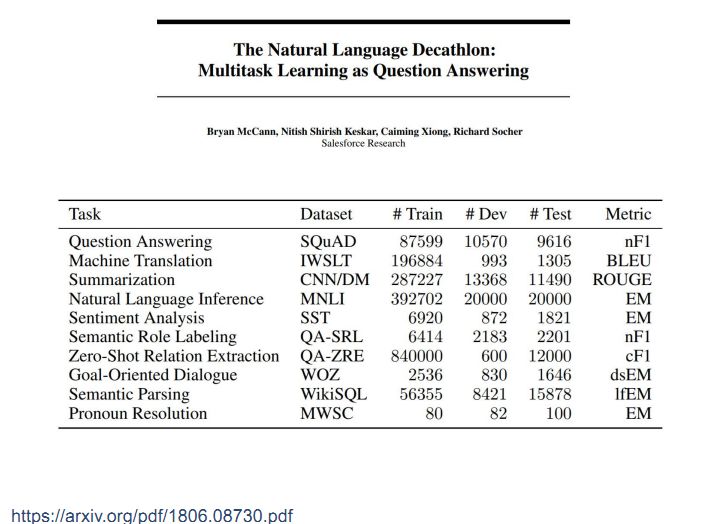
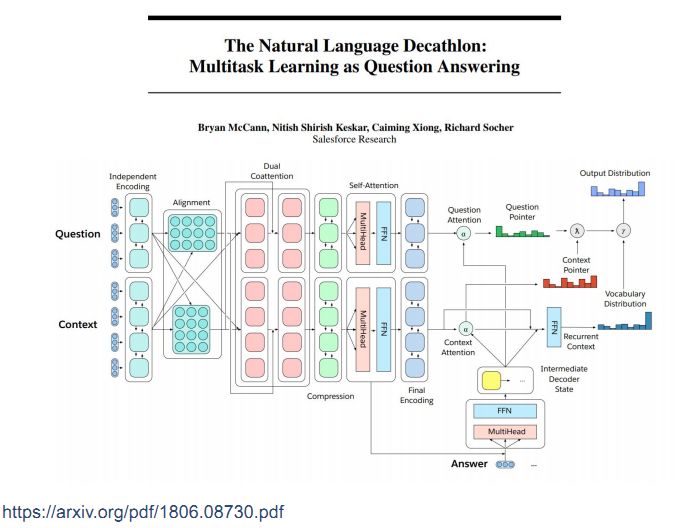
今年新发布的一个NLP通用的多任务学习系统叫做十项全能,选取了十个典型的NLP任务转化成阅读理解的形式,例如左下角的情感分类问题,将这些任务转换到阅读理解问题后采用Biderectional Attention框架去处理。由于这些问题的答案不一定出现在背景文档中,因此需要对Biderectional Attention框架进行改进。
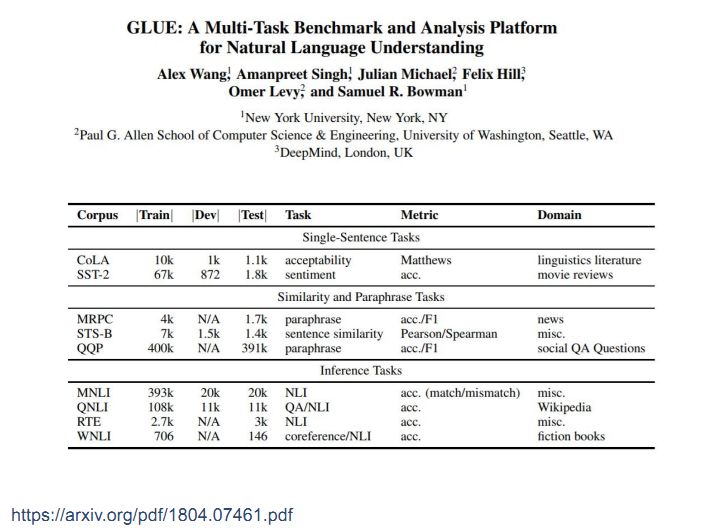
还有一个较大的框架是GLUE,也是将很多NLP任务转化成一个统一的形式。下图中是三个任务:单个句子任务、计算两个句子相似度、表示两个句子之间的蕴含关系。这些任务都可以做成encoder和decoder模式。
五、总结
最后,我们对今天介绍的内容做一个总结。今天主要介绍了自然语言处理简介、基于深度学习的自然语言处理、深度学习在自然语言处理中的困境、多任务学习和新的多任务基准平台。总的来说多任务学习的难度会比迁移训练低而效果比预训练要高一些。

另外,在今年12月中旬,我们将发布一个模块化的开源自然语言工具fastNLP。

这个工具包括Spacy高级接口、AllenNLP自定义模块、AutoML自动调参。将训练好的模型开放出来供大家直接调用。
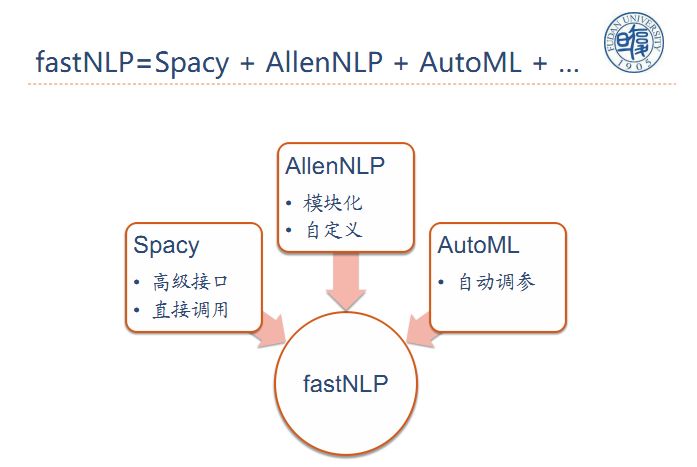
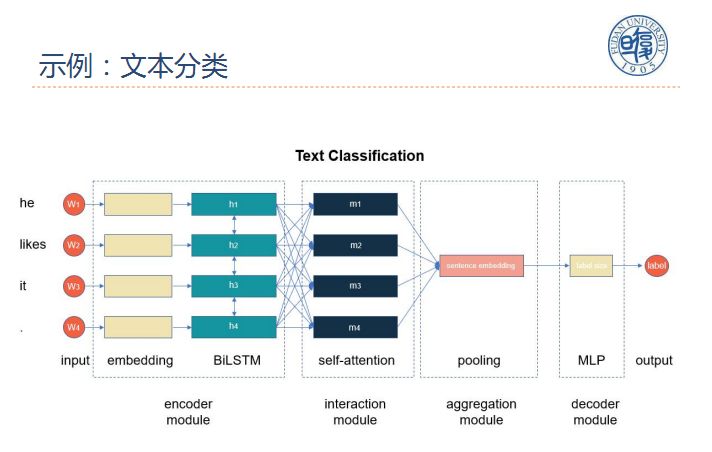
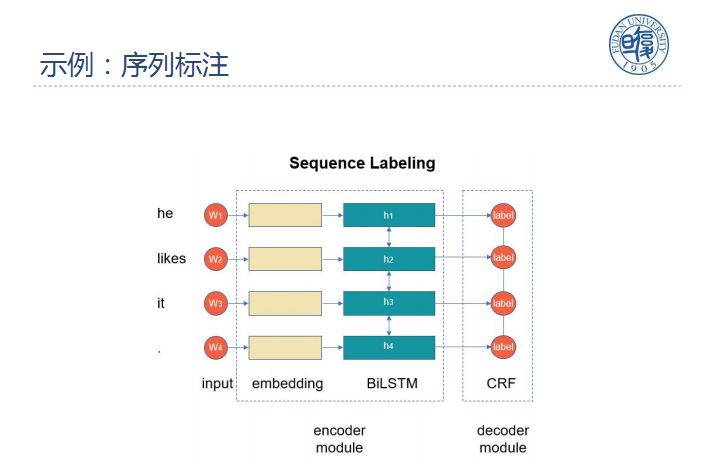
为实现模块化,我们将NLP分为四个构成组件:
1、编码器:将输入编码为一些抽象表示,输入的是单词序列,输出是向量序列;
2、交互器:使表示中的信息相互交互,输入的是向量序列,输出的也是向量序列;
3、聚合器:聚合信息,输入向量序列,输出一个向量;
4、解码器:将表示解码为输出,输出一个标签或者输出标签序列。

这里我们给出了两个示例,分别是文本分类和序列标注。
可以应用的场景主要包括:
1、直接调用;
2、模型开发;
3、自动化学习。

作者介绍:
邱锡鹏,复旦大学计算机科学技术学院 副教授,博士生导师,于复旦大学获得理学学士和博士学位。中国中文信息学会青年工作委员会执委、计算语言学专委会委员、中国人工智能学会青年工作委员会常务委员、自然语言理解专委会委员。主要研究领域包括人工智能、机器学习、深度学习、自然语言处理等,并且在上述领域的顶级期刊、会议(ACL/EMNLP/IJCAI/AAAI等)上发表过50余篇论文。自然语言处理开源工具FudanNLP作者,2015年入选首届中国科协青年人才托举工程,2017年ACL杰出论文奖。
——END——
DataFun算法交流群欢迎您的加入,感兴趣的小伙伴欢迎加管理员微信:
文章推荐:
社区介绍:
DataFun定位于最“实用”的数据科学社区,主要形式为线下的深度沙龙、线上的内容整理。希望将工业界专家在各自场景下的实践经验,通过DataFun的平台传播和扩散,对即将或已经开始相关尝试的同学有启发和借鉴。DataFun的愿景是:为大数据、人工智能从业者和爱好者打造一个分享、交流、学习、成长的平台,让数据科学领域的知识和经验更好的传播和落地产生价值。
DataFun社区成立至今,已经成功在全国范围内举办数十场线下技术沙龙,有超过一百五十位的业内专家参与分享,聚集了万余大数据、算法相关领域从业者。
以上是关于「回顾」自然语言处理中的多任务学习的主要内容,如果未能解决你的问题,请参考以下文章
总结 | 复旦大学陈俊坤:自然语言处理中的多任务学习 | AI 研习社职播间第 6 期