用于自然语言理解的多任务学习的深度神经网络
Posted 数据挖掘与开源生态
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用于自然语言理解的多任务学习的深度神经网络相关的知识,希望对你有一定的参考价值。
摘要
在本文中,我们提出了一种用于学习表示的多任务深度神经网络(MT-DNN),可以跨多种自然语言理解(NLU)任务。MT-DNN不仅利用了大量的跨任务数据,而且还受益于正则化效果,这种正则化效果使用了更通用的表示形式,有助于适应新的任务和领域。MT-DNN扩展了Liu等人提出的模型(2015年),通过并入BERT的预训练双向transformer语言模型(Devlin等人,2018)。MT-DNN在10个NLU任务(包括SNLI,SciTail和9个GLUE任务中的8个)上获得了最新的最新结果,将GLUE基准提高到82.7%(绝对改善2.2%)1.我们还演示了使用SNLI和SciTail数据集表明,MT-DNN所学习的表示与预训练的BERT表示相比,使用更少的域内标签实现了域自适应。代码和经过预训练的模型可从https://github.com/namisan/mt-dnn公开获得。
1 介绍
学习文本(例如单词和句子)的向量空间表示形式是许多自然语言理解(NLU)任务的基础。两种流行的方法是多任务学习和语言模型预训练。在本文中,我们通过提出一种新的多任务深度神经网络(MT-DNN)来结合两种方法的优势。多任务学习(MTL)受到人类学习活动的启发,人们经常运用从先前任务中学到的知识来帮助学习新任务(Caruana,1997; Zhang and Yang,2017)。例如,一个会滑雪的人比不会滑雪的人更容易学习滑冰。同样,联合学习多个(相关)任务也很有用,这样一个任务中学习的知识可以使其他任务受益。最近,人们越来越有兴趣将多任务学习应用到使用深度神经网络(DNN)的表示学习中(Collobert等,2011; Liu等,2015; Luong等,2015; Xu等,2018; Guo等人,2018; Ruder12等人,2019)有两个原因。首先,DNN的监督学习需要大量特定于任务的标记数据,而这些数据并非总是可用。 多任务学习提供了一种有效的方法,可以利用许多相关任务中的监督数据。其次,多任务学习的使用通过减轻对特定任务的过度拟合而从正则化效果中获利,从而使学习的表示形式能跨任务通用。
与多任务学习相比,语言模型预训练通过利用大量未标记数据已显示出有效学习通用语言表示的能力。最近的调查包括在Gao等人中(2018)。一些最突出的例子是ELMo(Peters等,2018),GPT(Radford等,2018)和BERT(Devlin等,2018)。这些是使用无监督目标对文本数据进行训练的神经网络语言模型。例如,BERT基于多层双向transformer,并在纯文本上进行训练,以进行掩盖词预测和下一个句子预测任务。要将预训练的模型应用于特定的NLU任务,我们经常需要使用特定于任务的训练数据为每个任务微调带有其他特定于任务的层的模型。例如,Devlin等人(2018)显示BERT可以通过这种方式进行微调,从而为一系列NLU任务(例如问题回答和自然语言推理)创建当前最好模型。
我们认为多任务学习和语言模型预训练是互补的技术,可以结合起来改进学习文本的表示提高各种NLU任务的性能。为此,我们扩展了Liu等人最初提出的MT-DNN模型(2015),将BERT用作共享文本编码层。如图1所示,较低的层(即文本编码层)在所有任务之间共享,而顶层则是特定于任务的,结合了不同类型的NLU任务,例如单句分类,成对文本分类,文本相似性,以及相关性排名。与BERT模型类似,MT-DNN可通过微调适应特定任务。与BERT不同,MT-DNN除了使用语言模型预训练之外,还使用多任务学习来学习文本表示。
MT-DNN在通用语言理解评估(GLUE)基准测试中使用的9个NLU任务中有8个获得了最新的最新结果(Wang等人,2018),将GLUE基准得分提高到82.7%,总计比BERT绝对值提高2.2%。我们进一步将MT-DNN的优势扩展到SNLI(Bowman等人,2015a)和SciTail(Khot等人,2018)任务中。与预训练的BERT表示相比,MT-DNN所学习的表示允许使用更少的域内标签进行域自适应。例如,我们修改的模型在SNLI上的准确度达到91.6%,在SciTail上的准确度达到95.0%,分别比以前的最新性能高1.5%和6.7%。即使只有原始训练数据的0.1%或1.0%,MT-DNN在SNLI和SciTail数据集上的性能也比许多现有模型要好。所有这些都清楚地证明了MT-DNN通过多任务学习的卓越综合能力。
2 任务
MT-DNN模型结合了四种NLU任务:单句分类,成对文本分类,文本相似性评分和相关性排名。为了具体起见,我们以GLUE基准中定义的NLU任务为例来描述它们。
单句分类:给定一个句子,模型使用预定义的类标签之一对其进行标签。例如,CoLA的任务是预测英语句子在语法上是否合理。SST-2任务是确定从电影评论中提取的句子的情绪是正面还是负面。
文本相似度:这是一项回归任务。给定一对句子,该模型将预测一个实际值得分,该得分指示两个句子的语义相似性。STS-B是GLUE中任务的唯一示例。
成对文本分类:给定一对句子,该模型基于一组预定义标签确定两个句子的关系。例如,RTE和MNLI都是语言推断任务,其目的是预测一个句子相对于另一个句子是否是蕴含的,矛盾的或中立的。QQP和MRPC是由句子对组成的释义数据集。任务是预测该对中的句子在语义上是否等效。
相关性排名:给定查询和候选答案列表,该模型按与查询的相关性顺序对所有候选进行排名。QNLI是Stanford问题回答数据集的一个版本(Rajpurkar等,2016)。该任务涉及评估句子是否包含对给定查询的正确答案。尽管QNLI在GLUE中被定义为二分类的分类任务,但在本研究中,我们将其表述为成对排名任务,其中该模型预计将包含正确答案的候选者的排名高于不包含该候选词的候选者。我们将证明,这种表示法比二分类分类法的准确性显着提高。
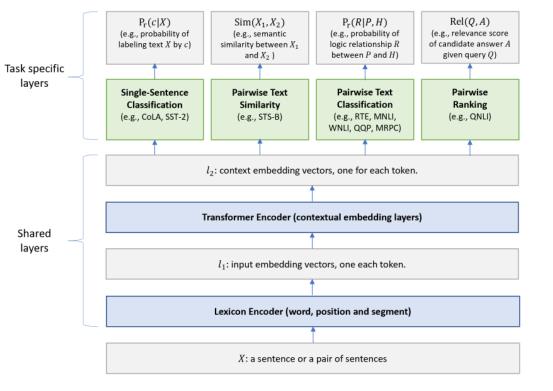
图一:用于表示学习的MT-DNN模型的体系结构。较低的层在所有任务之间共享,而顶层则特定于任务。首先,将输入X(一个句子或一对句子)表示为一系列嵌入向量(在l1中)。然后,Transformer编码器捕获每个单词的上下文信息,并在l2中生成共享的上下文嵌入向量。最后,对于每个任务,其他特定于任务的层会生成特定于任务的表示形式,然后进行分类,相似性评分或相关性排名所需的操作。
3 提出的MT-DNN模型
MT-DNN模型的体系结构如图1所示。较低的层在所有任务之间共享,而较高的层代表特定于任务的输出。输入X是单词序列(一个句子或成对的句子包装在一起),首先表示为嵌入向量序列 。然后,transformer编码器通过自注意机制捕获每个单词的上下文信息,并生成序列的上下文嵌入 ,这是由我们的多任务目标训练的共享语义表示。接下来,我们将详细介绍该模型。
词典编码器( ):输入X = { ,..., }是长度为m的嵌入序列。参照Devlin等人(2018),第一个嵌入(token) 始终是[CLS]token。如果X由一个句子对( , )组成,我们将使用特殊标记[SEP]分隔两个句子。词典编码器将X映射为一系列输入嵌入向量,每个token对应一个标记,通过将相应的单词,片段和位置嵌入相加而构成。
Transformer编码器( ):我们使用多层双向Transformer编码器(V aswani et al。,2017)将输入表示向量( )映射到上下文嵌入向量C∈ 的序列中。这是跨不同任务的共享表示。与通过预训练学习表示的BERT模型(Devlin et al。,2018)不同,MT-DNN除了预训练之外,还使用多任务目标学习表示。
下面,我们将以GLUE中的NLU任务为例来描述特定于任务的层,尽管在实践中我们可以合并任意自然语言任务,例如文本生成,其中将输出层设为神经解码器。
单句分类输出:假设x是标记[CLS]的上下文嵌入( ),可以将其视为输入句子X的语义表示。以SST-2任务为例。X被标记为c类(即情感)的可能性是通过使用softmax的逻辑回归来预测的:
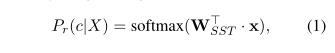
是特定任务的参数矩阵。
文本相似度输出:以STS-B任务为例。假设x是[CLS]的上下文嵌入( ),可以将其视为输入句子对( , )的语义表示。我们引入特定于任务的参数向量 来计算相似性得分为:
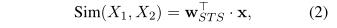
成对文本分类输出:以自然语言推断(NLI)为例。这里定义的NLI任务涉及m个单词的前提P =( ,..., )和n个单词的假设H =( ,..., ),目的是找到P和H之间的逻辑关系R,输出模块的设计遵循随机应答网络(SAN)的应答模块(Liu等人,2018a),这是最新的神经NLI模型。SAN的答案模块使用多步推理。与其直接预测给定输入的需求量,不如保持状态并迭代地完善其预测。
SAN应答模块的工作原理如下。我们首先通过连接P中的单词的上下文嵌入来构造前提P的工作记忆,这些词是互感器编码器的输出,表示为 ∈ ,类似地,假设H的工作记忆,表示为 ∈ 。然后,我们在内存上执行K步推理以输出关系标签,其中K是超参数。首先,初始状态 是 的摘要: = ,其中 = exp( · )/ exp( · )。在{1,2,,K-1}范围内的时间步长k,状态由 = GRU( , )定义。在这, 从先前状态 和存储器 计算出的: = , = softmax( )。一层分类器用于确定每个步骤k的关系:
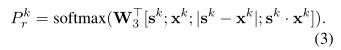
最后,我们通过平均分数来利用所有K个输出:
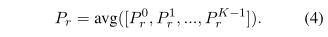
每个 是在所有关系R∈ 上的概率分布。在训练期间,我们在上述平均操作之前应用随机预测落差(Liu等人,2018b)。在解码期间,我们对所有输出求平均以提高鲁棒性。
相关性排名输出:以QNLI为例。假设x是[CLS]的上下文嵌入向量,它是一对问题及其候选答案(Q,A)的语义表示。我们将相关性分数计算为:
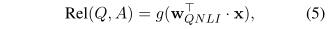
对于给定的Q,我们根据所有候选答案的相关性得分对它们进行排名,这些相关性得分是使用公式5计算得出的。
3.1 训练程序
MT-DNN的训练过程包括两个阶段:预训练和多任务学习。预训练阶段遵循BERT模型的预训练阶段(Devlin et al。,2018)。使用两个无监督的预测任务来学习词典编码器和Transformer编码器的参数分别是:屏蔽语言建模和下一句预测。
在多任务学习阶段,我们使用基于小批量的随机梯度下降(SGD)来学习模型的参数(即所有共享层和特定于任务的层的参数),如算法1所示。在每个时期,选择小批量处理(例如,在所有9个GLUE任务中),并根据任务t的特定于任务的目标更新模型。这大约优化了所有多任务目标的总和。
对于分类任务(即单句或成对文本分类),我们以交叉熵损失为目标
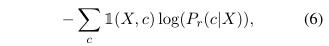
如果类别标签c是X的正确分类,则1(X,c)是二进制指示符(0或1),而Pr(.)由例如公式1或4定义。
对于文本相似性任务(例如STS-B),其中每个句子对都用实数值y进行注释,我们将均方误差作为目标,其中Sim(.)由公式2定义:
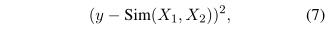
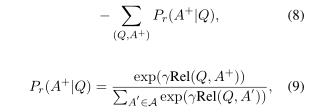
相关性排名任务的目标遵循成对学习排名范例(Burges等,2005;Huang等,2013)。以QNLI为例。给定查询Q,我们获得候选答案列表A,其中包含一个包含正确答案的正例
,和| A | -1个否定的例子。然后,根据训练数据中的查询,我们将正面示例的负面对数可能性降至最低,其中Rel(.)由公式5定义,而γ是根据保留数据确定的调整因子,在我们的实验中,我们仅将γ设置为1。

4 实验
我们在三种流行的NLU基准上评估了提出的MT-DNN:GLUE(Wang等人,2018),SNLI(Bowman等人,2015b)和SciTail(Khot等人,2018)。我们将MT-DNN与现有的包括BERT在内的最新模型进行了比较,并演示了使用和不使用GLUE进行模型微调以及使用SNLI和SciTail进行域自适应的多任务学习的有效性。
4.1 数据集
本节简要描述了GLUE,SNLI和SciTail数据集,如表1所示。
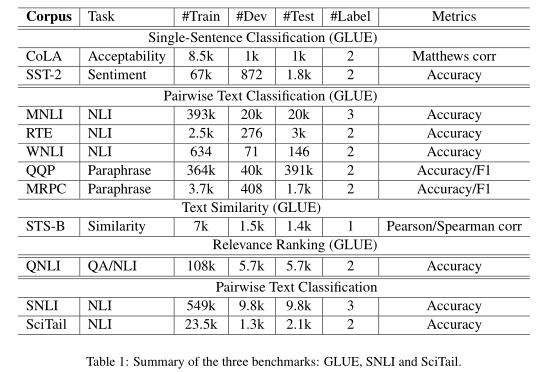
GLUE通用语言理解评估(GLUE)基准是表1中9个NLU任务的集合,包括问题回答,情感分析,文本相似性和文本含义;它被认为是设计良好的,用于评估NLU模型的泛化性和鲁棒性。
SNLI斯坦福自然语言推理(SNLI)数据集包含570k带有人类注释的句子对,其中前提是从Flickr30语料库的标题中提取的,并且对假设进行了手动注释(Bowman等人,2015b)。这是NLI使用最广泛的蕴含数据集。该数据集仅用于本研究中的域适应。
SciTail这是源自科学问答(SciQ)数据集的文本蕴含数据集(Khot等人,2018)。该任务涉及评估给定前提是否包含给定假设。与前面提到的其他蕴含数据集相反,SciTail中的假设是根据科学问题创建的,而相应的答案候选者和前提则来自从大型语料库中检索到的相关网络句子。结果,这些句子在语言上具有挑战性,前提和假设的词汇相似性通常很高,因此使SciTail特别困难。该数据集仅用于本研究中的域适应。
4.2 实施细节
我们的MT-DNN实现基于BERT的PyTorch实现。我们使用Adamax(Kingma and Ba,2014)作为优化器,遵循Devlin等人(2018)的方法,其学习率为5e-5,批处理大小(batch size)为32。epochs设置为5。除非另有说明,否则使用预热超过0.1的线性学习速率衰减计划。我们还将所有任务特定层的dropout设置为0.1,MNLI为0.3,CoLa为0.05。为避免梯度爆炸问题,我们将梯度范数剪裁为1。所有文本均使用词片标记,并切成不超过512个tokens。
4.3 GLUE主要结果
我们将MT-DNN及其变体与已提交到GLUE排行榜的最新模型进行了比较,结果示于表2和3。
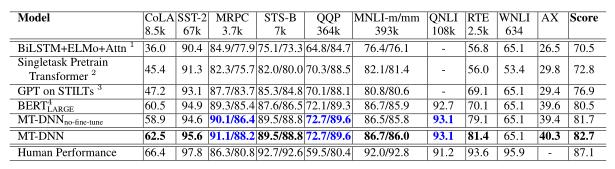
表二:使用GLUE评估服务对GLUE测试集结果评分。每个任务下方的数字表示训练集的数量。最新的结果以粗体显示,与人类表现相当或超过人类表现的结果以粗体显示。MT-DNN使用 初始化其共享层。所有结果均于2019年2月25日从https://gluebenchmark.com/leaderboard获得

表三:GLUE验证集的结果。每个任务的最佳结果以粗体显示。单任务DNN(ST-DNN)使用与MT-DNN相同的模型架构。但是它的共享层是未经训练的BERT模型,无需通过MTL进行完善。我们使用特定于任务的数据针对每个GLUE任务微调了ST-DNN。QNLI数据集有两个版本。V1于2019年1月30日到期。当前版本为v2。MT-DNN使用 作为其初始共享层。
这是作者发布的大型BERT模型,我们将其用作基准。我们根据任务特定的数据微调了每个GLUE任务的模型。
MT-DNN这是在第3节中提出的模型。我们使用了预先训练的 初始化其共享层,在所有GLUE任务上通过MTL完善了模型,并使用特定于任务的方法为每个GLUE任务微调了模型数据。表2中的测试结果表明,在所有任务上,MT-DNN的性能均优于所有现有系统,但WNLI除外,它在8个GLUE任务上创造了最新的技术成果,并将基准提高到82.7%,比 提升2.2%。由于MT-DNN使用 初始化其共享层,因此收益主要归因于MTL在完善共享层时的使用。MTL对于域内训练数据很少的任务特别有用。正如我们在表中所观察到的,在相同类型的任务上,与具有较多域内标签的任务相比,具有较少域内训练数据的任务对BERT的改进要大得多,即使它们属于同一任务类型,例如,两个NLI任务:RTE与MNLI,以及两个释义任务:MRPC与QQP。
MT- 由于MT-DNN的MTL使用了所有GLUE任务,因此可以将MT-DNN直接应用于每个GLUE任务而无需进行微调。表2中的结果表明,除CoLA之外,MT- 在所有任务中的性能均优于 。我们的分析表明,CoLA是具有挑战性的任务,其域内数据比其他任务要少得多,并且其任务定义和数据集在所有GLUE任务中都是唯一的,因此很难从其他任务中学到的知识中受益。结果,MTL倾向于不适合CoLA数据集。在这种情况下,必须进行微调以提高性能。如表2所示,即使只有非常少量的域内数据可用于自适应,精调后的精度也从58.9%提高到62.5%。这与经过精调的MT-DNN明显优于经精调的 在 CoLA(62.5%对60.5%)的事实相吻合,这表明学习的MT-DNN表示比预训练的域适应性更有效。BERT表示。我们将在4.4节中通过更多实验来重新讨论该主题。
ST-DNN ST-DNN表示单任务DNN。它使用与MT-DNN相同的模型架构。但是它的共享层是未经训练的BERT模型,无需通过MTL进行完善。然后,我们使用特定于任务的数据针对每个GLUE任务微调ST-DNN。因此,对于成对的文本分类任务,其ST-DNN和BERT模型之间的唯一区别是特定于任务的输出模块的设计。表3中的结果表明,在所有四个任务(MNLI,QQP,RTE和MRPC)上,ST-DNN均优于BERT,证明了SAN应答模块的有效性。我们还比较了QNLI上ST-DNN和BERT的结果。使用成对排名损失对ST-DNN进行微调,而BERT将QNLI视为二分类,并使用交叉熵损失进行微调。ST-DNN的性能明显优于BERT,这清楚地表明了问题制定的重要性。
4.4 SNLI和SciTail上的域适应结果
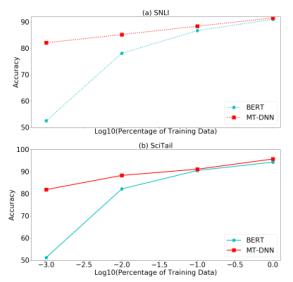
图2:分别使用MT-DNN和BERT生成的共享嵌入对SNLI和SciTail开发数据集进行域适应的结果。MT-DNN和BERT均基于预训练的BERT_BASE进行了微调。X轴指示用于适应的域特异性标记的样品的量。
构建实系统的最重要标准之一是快速适应新任务和新领域。这是因为为新的域或用任务收集标记的训练数据非常昂贵。通常,我们只有很少的训练数据,甚至没有训练数据。
为了使用上述标准评估模型,我们使用以下过程对两个NLI任务SNLI和SciTail进行了域自适应实验:
1.使用MT-DNN模型或BERT作为初始模型,包括BASE和LARGE模型设置;
2.通过使用特定于任务的训练数据适应训练有素的MT-DNN,为每个新任务(SNLI或SciTail)创建特定于任务的模型;
3.使用任务特定的测试数据评估模型。
我们从这些任务的默认训练/验证/测试集开始。我们随机抽取了其训练数据的0.1%,1%,10%和100%。结果,我们获得了SciTail的四组训练数据,分别包括23、235、2.3k和23.5k训练样本。同样,我们获得了SNLI的四组训练数据,分别包括549、5.5k,54.9k和549.3k训练样本。
我们执行五次随机抽样,并报告所有运行中的平均值。图2中报告了来自SNLI和SciTail的不同数量训练数据的结果。我们观察到,MT-DNN始终优于BERT基线,并且在表4中提供了更多详细信息。使用的训练示例越少,MT-DNN相比Bert的改进就越大。例如,只有SNLI训练数据的0.1%(23个样本),MT-DNN的准确度达到82.1%,而BERT的准确度为52.5%;使用1%的训练数据,MT-DNN的准确性为85.2%,BERT的准确性为78.1%。我们在SciTail上观察到类似的结果。结果表明,与BERT相比,MT-DNN所学习的表示对于域自适应更有效。
表5中,我们将使用所有域内训练样本的调整后的模型与几个强有力的基准进行比较,其中包括排行榜中报告的最佳结果。我们看到MT- 在两个数据集上都产生了当前最好的结果,将SNLI的基准分别提高到91.6%(绝对改进1.5%)和SciTail的标准达到95.0%(绝对改进6.7%)。这为SNLI和SciTail带来了当前新的最好结果。所有这些都证明了MT-DNN在域自适应方面的出色表现。
在这项工作中,我们提出了一个称为MT-DNN的模型,该模型将多任务学习和语言模型预训练相结合以进行语言表示学习。MT-DNN在SNLI,SciTail和GLUE这三个受欢迎的基准测试中,通过十项NLU任务获得了最新的最新结果。MT-DNN还在领域自适应实验中展示了出色的泛化能力。
在改善MT-DNN方面有很多未来的探索领域,包括更深入的了解多任务学习中的模型结构的共享层,在微调和预训练中都可以利用多个任务之间的相关性的一种有效的训练方法(Dong等。2019),以及以更明确和可控制的方式来合并文本的语言结构的方法。
以上是关于用于自然语言理解的多任务学习的深度神经网络的主要内容,如果未能解决你的问题,请参考以下文章