总结 | 复旦大学陈俊坤:自然语言处理中的多任务学习 | AI 研习社职播间第 6 期
Posted AI科技评论
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了总结 | 复旦大学陈俊坤:自然语言处理中的多任务学习 | AI 研习社职播间第 6 期相关的知识,希望对你有一定的参考价值。
AI 科技评论编者按:过去几年,深度学习在自然语言处理中取得了很大的进展,但进展的幅度并不像其在计算机视觉中那么显著。其中一个重要的原因是数据规模问题。多任务学习是将多个任务一起学习,充分挖掘多个任务之间的相关性,来提高每个任务的模型准确率,从而可以减少每个任务对训练数据量的需求。
近日,在雷锋网 AI 研习社公开课上,复旦大学计算机系在读硕士陈俊坤分享了其所在研究组关于多任务学习在自然语言处理领域的最新工作。公开课回放视频可点击文末阅读原文观看
分享嘉宾:
陈俊坤,复旦大学计算机系在读硕士,导师是邱锡鹏副教授,主要研究方向为自然语言处理,多任务学习等。其研究工作曾在 AAAI, IJCAI 上发表。
分享主题:自然语言处理中的多任务学习 & 复旦大学 NLP 实验室介绍
分享提纲:
1、复旦大学 NLP 实验室介绍
2、基于深度学习的自然语言处理
3、深度学习在自然语言处理中的困境
4、自然语言中的多任务学习
5、多任务基准平台
雷锋网 AI 研习社将其分享内容整理如下:
本次的分享主要有两个目的:一是介绍一下复旦大学 NLP 实验室的相关工作;二是让愿意攻读研究生的同学对国内实验室有更多的了解,从而在选择攻读研究生上更有目标性。
复旦大学 NLP 实验室介绍
分享之前,先进行一下自我介绍,我目前在复旦大学 NLP 实验室攻读研三,师从邱锡鹏副教授,现在也是字节跳动 AI Lab 的实习生,研究方向主要是自然语言处理、多任务学习和迁移学习。今天的分享,我会重点讲一下多任务学习。
另外介绍一下复旦大学 NLP 实验室,它致力于利用机器技术,理解和处理人类语言,拥有国内领先的团队,实验室的老师都有非常丰富的经验。我所在的研究组主要聚焦于深度学习和自然语言处理领域,包括语言表示学习、词法/句法分析、文本推理、问答系统等方面,指导老师是邱锡鹏副教授,近几年来,我们发表国际顶级会议/期刊 50 余篇,还获得了 ACL 2017 杰出论文;在 SQUAD 2.0 上获得第二的成绩,并在 SQUAD 1.1 上多次获得第一;另外我们也开发开源自然语言处理系统,希望能帮助大众解决更多问题,其中包括 FudanNLP(国内最早的开源 NLP 系统之一)、fastNLP(一个模块化、自动化、可扩展的 NLP 系统)。
本次自然语言处理的报告纲要包括:
自然语言处理简介
基于深度学习的自然语言处理
深度学习在自然语言处理中的困境
自然语言处理中的多任务学习
新的多任务基准平台
自然语言处理简介
首先简单介绍一下自然语言语言处理这个概念。
我们知道图灵测试是指,当一个人与机器对话时,他无法判断对方是机器还是人,那机器就通过了图灵测试。这就引出了自然语言处理的核心:让机器去理解和生成自然语言。
那什么是自然语言处理?我们可以大致将其理解为人类语言,区别于程序语言等人工语言。自然语言处理任务包括语音识别、自然语言理解、自然语言生成、人机交互以及所涉及的中间阶段,目前可以归为是人工智能和计算机科学的交叉子学科。
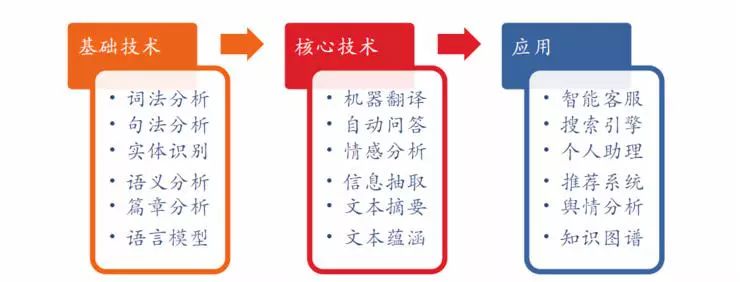
从技术上进行总结,可以分为三个层面:基础技术、核心技术和应用:
自然语言处理的难点在于歧义性,以下我以中文分词为例进行说明:
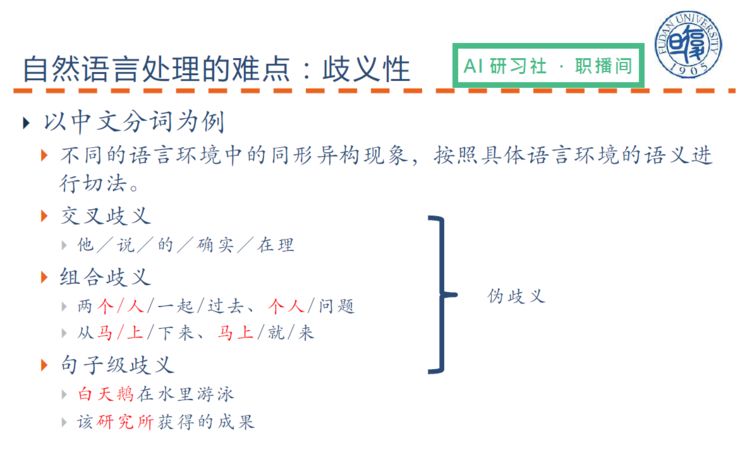
(关于自然语言处理的难点的具体讲解,请回看视频 00:05:35 处)
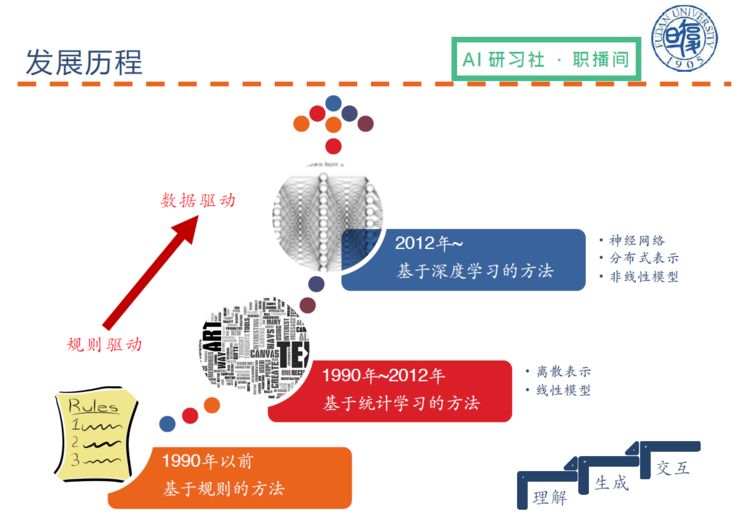
自然语言处理的发展历程可以这样总结: 在 1990 年以前,多基于规则的方法进行自然语言处理;90 年代以后,逐渐引入一些统计学习的方法;目前,自 2012 年开始,随着的深度学习的热潮,开始基于深度学习神经网络端到端的训练进行自然语言处理。总之,自然语言处理就是一个理解语言(文本到机器)、生成(机器到文本)再到交互的过程。
那对于人来说,理想中的自然语言处理流程是怎样的呢?
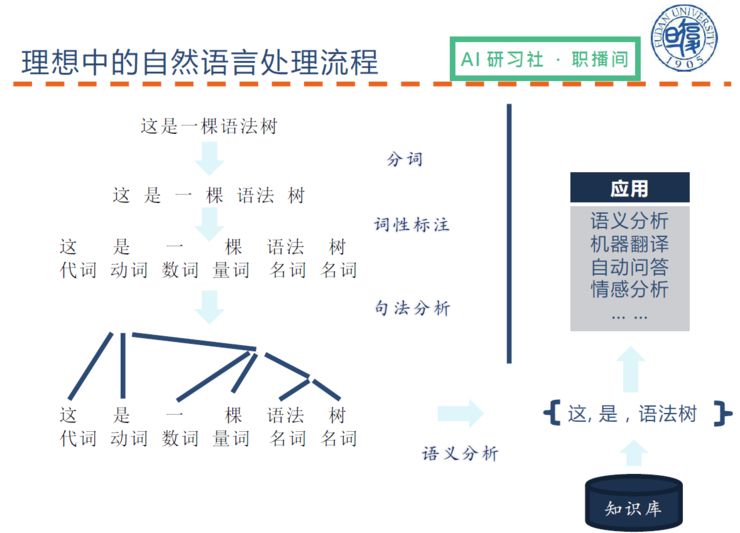
(关于理想中的自然语言处理流程的具体讲解,请回看视频 00:08:10 处)
基于深度学习的自然语言处理
下面讲一下基于深度学习的自然语言处理是怎样的。首先讲一下如何在计算机中表示语言的语义?
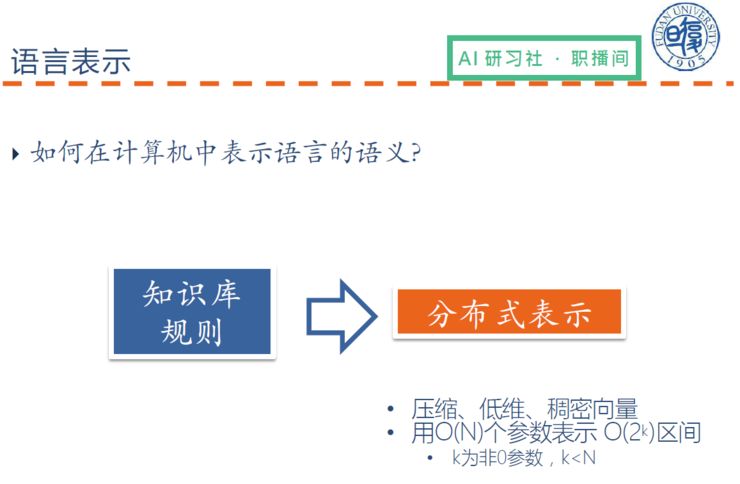
计算机中语言语义的表示之前是采用一些知识库的规则;到了深度学习中,则采用分布式的表示方法。下面可以看一个图像的案例:

(关于语言语义表示及其案例的具体讲解,请回看视频 00:09:00 处)
这里就要引出在自然语言处理中非常重要的概念——词嵌入(Word Embeddings),这个概念从 2013 年开始逐渐火热起来。
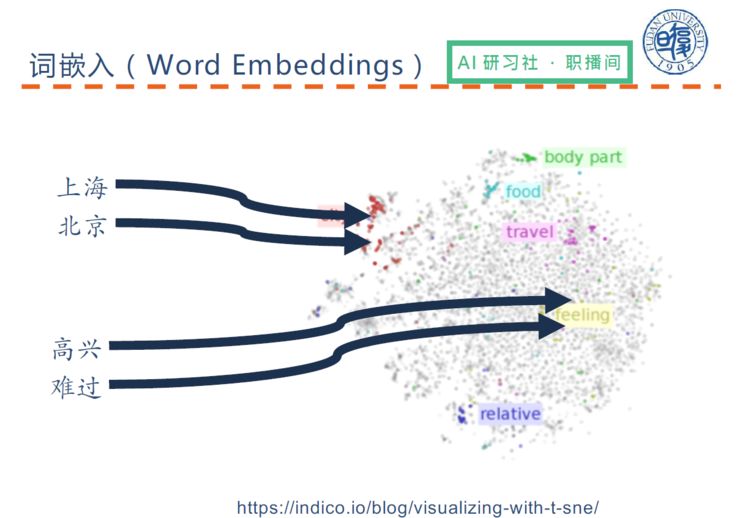
(关于词嵌入的具体讲解,请回看视频 00:10:40 处)
词表示之后,就要考虑句子表示,不过句子表示的难度远大于词表示,这里主要讲一下在神经网络中怎样表示句子。
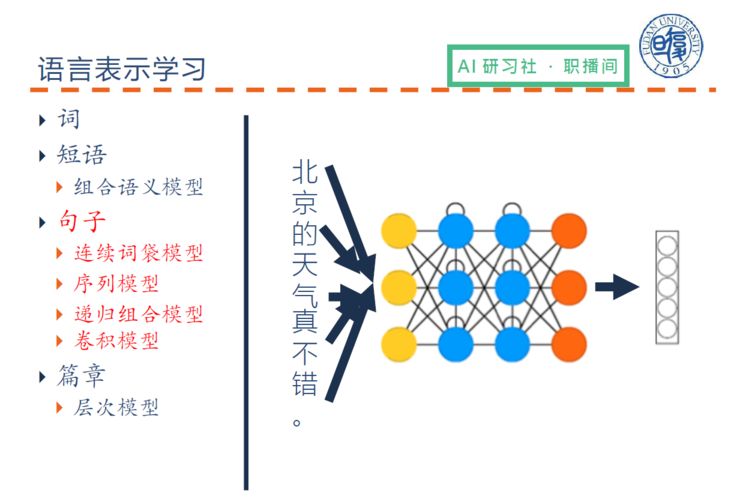
(关于神经网络中的句子表示的具体讲解,请回看视频 00:12:42)
在得到字、句子表示之后,如果要对自然语言处理任务的类型进行总结,可以划分为以下几个类别:
第一,类型(对象)到序列,包括文本生成、图像描述生成任务;
第二,序列到类别,包括文本分类、情感分析任务;
第三,同步的序列到序列,包括中文分析、词性标注、语义角色标注任务;
第四,异步的序列到序列,包括机器翻译、自动摘要、对话系统任务。
深度学习在自然语言处理中的困境
相比计算机视觉,深度学习在自然语言处理中存在较大的困境。
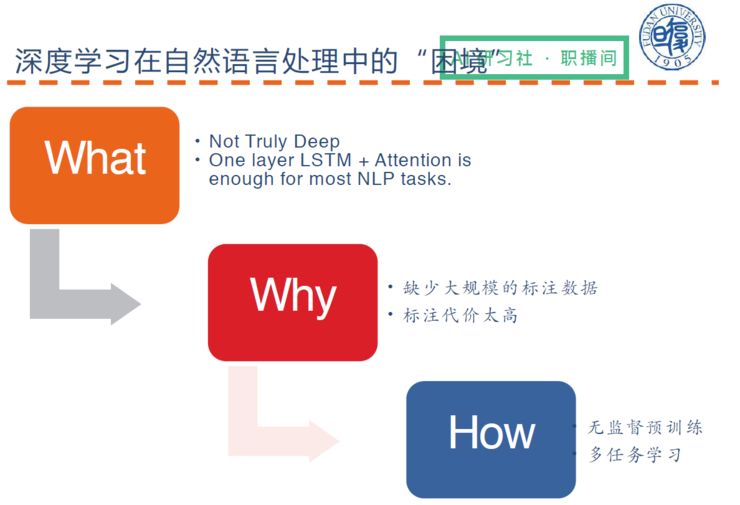
针对这些困境,目前有两套相对有效的解决思路:
一是无监督预训练;

二是多任务学习。
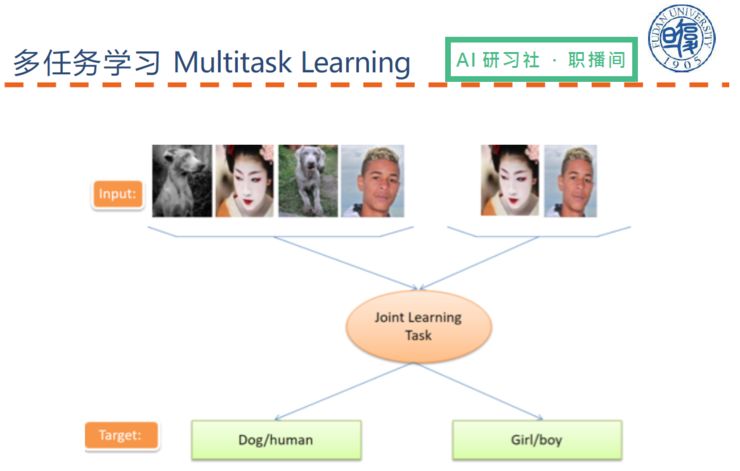
那么为什么多任务学习在自然语言处理中的表现这么好?原因包括:
隐式的数据增强;
更自然的表示学习;
更好地表示学习,一个好的表示需要能够提高多个任务的性能;
正则化:共享参数在一定程度上弱化了网络能力,可以防止过拟合;
Eavesdropping(窃听)。
(对于深度学习在自然语言处理中所存在困境及其原因和解决方法——无监督学习和多任务学习的具体讲解,请回看视频 00:13:51 处)
自然语言处理中的多任务学习
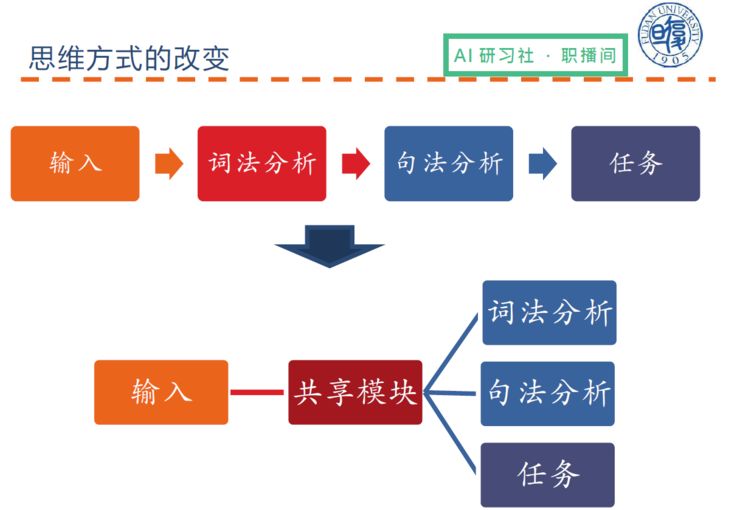
下面讲一下自然语言下的多任务学习。理想状态下,自然语言处理是按照输入到词法分析到句法分析再到多任务的过程,而多任务的自然语言处理,可以使用一个共享模块,同时进行词法分析、句法分析以及任务这几项任务。
自然语言中的多任务学习可以归纳为以下几个种类:
第一个是跨领域(Multi-Doman)任务
第二个是多级(Multi-Level)任务
第三个是多语言(Multi-Linguistic)任务
第四个是多模态(Multi-Modality)任务

深度学习下的多任务学习,一般是共享一些多层次的神经网络,可以总结为以下三种方式:
第一,硬共享模式
第二,软共享模式
第三,共享-私有模式
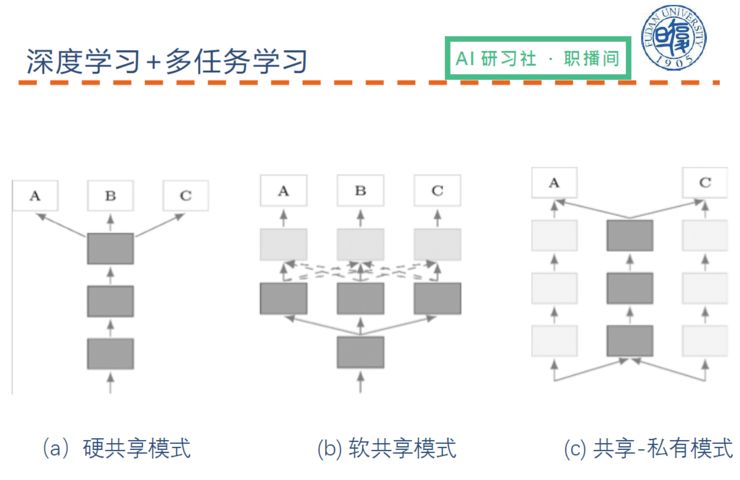
(关于自然语言处理中的多任务学习种类以及深度学习下的多任务学习方式的具体讲解,请回看视频 00:23:15 处)
共享模式主要可以分为以下类别:

接下来我将以实验室的论文为主,外加一些相关论文,介绍一下这些共享模式:
硬共享模式

软共享模式
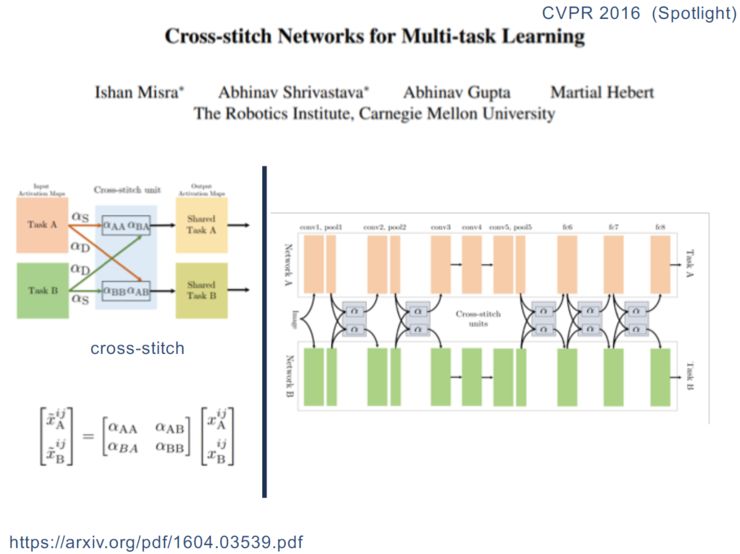
共享-私有模式
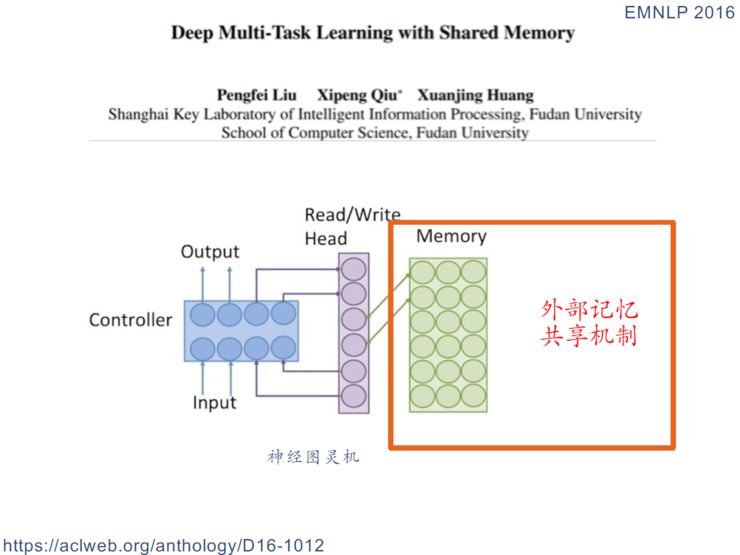
函数共享模式
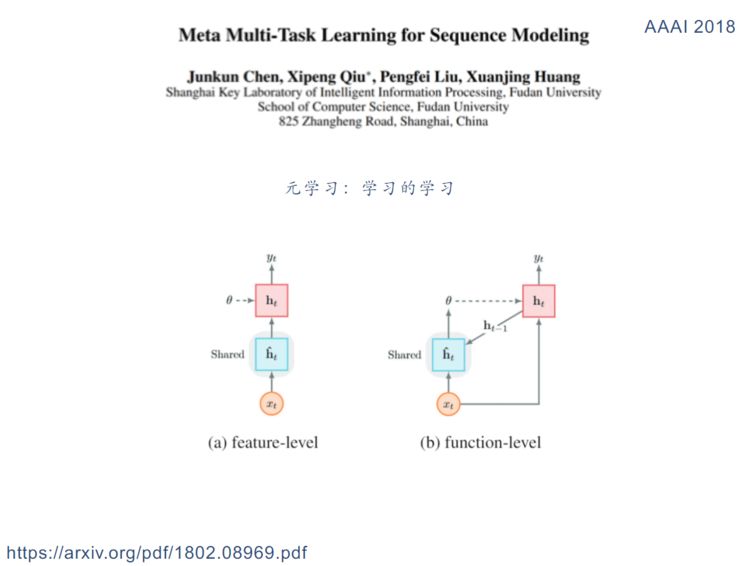
多级共享模式

主辅任务模式
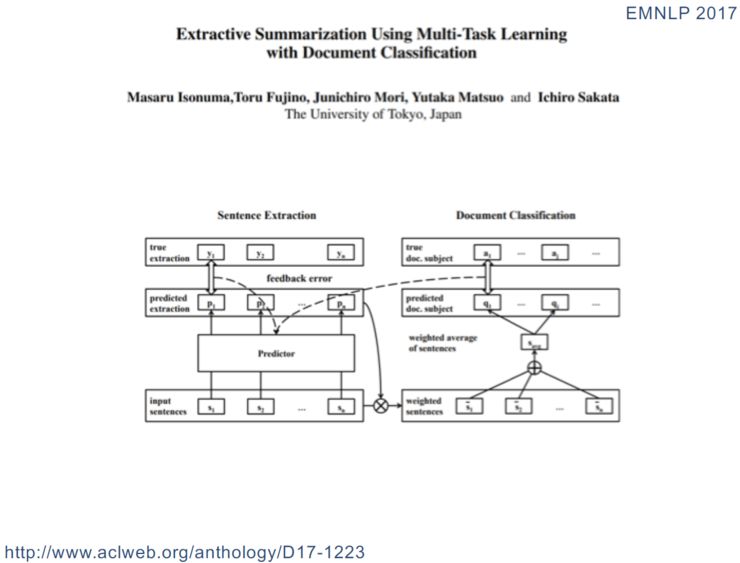
接着讲一下共享模式探索:
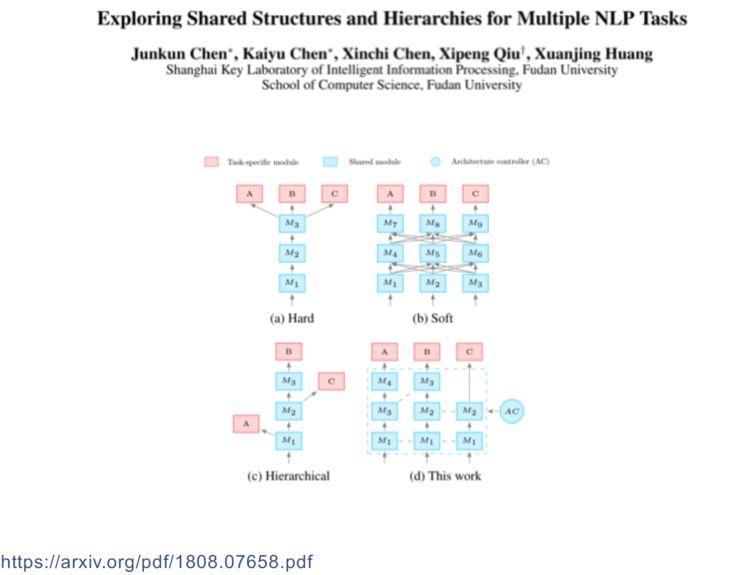
(关于对这几类共享模式的案例介绍以及共享模式探索的具体讲解,请回看视频 00:26:35 处)
新的多任务基准平台
接下来介绍一下多任务学习的两个比较主流的 benchmark。
先讲一下从去年开始比较火的阅读理解,即机器阅读一篇或多篇文档,并回答一些相关问题。它对于自然语言处理来说,是比较难的任务类型,这就引出了两个 benchmark。
第一个是 decanlp,它将很多 Q1 任务合并在一起作为多任务学习的联合训练集,每个任务有不同评价指标,每个任务的类型差异也很大,有的是翻译,有的是摘要。
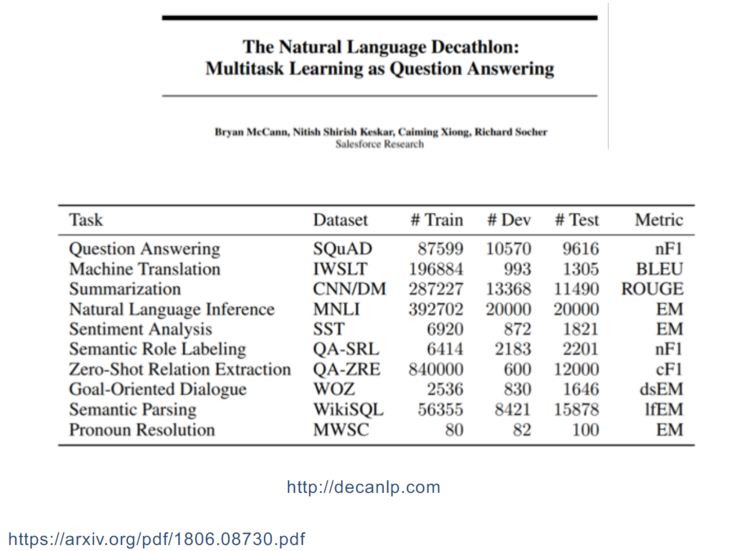
第二个是最近被大家刷爆的数据集 GLUE,它是 NYU 做的,跟 decanlp 理念差不多,也是跟 Q&A、情感分类类似的数据集。
这两个数据集还有很多发展的空间,但是我个人感觉最近大家刷榜的方式有点走偏了。
(关于这两个 benchmark 的具体讲解以及讲者的一些思考分享,请回看视频 00:46:50 处)
以上就是本期嘉宾的全部分享内容。本期公开课回放视频可点击文末阅读原文观看。
以上是关于总结 | 复旦大学陈俊坤:自然语言处理中的多任务学习 | AI 研习社职播间第 6 期的主要内容,如果未能解决你的问题,请参考以下文章