文献学习An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献学习An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale相关的知识,希望对你有一定的参考价值。
1 引言
所有版本的论文实现https://paperswithcode.com/paper/an-image-is-worth-16x16-words-transformers-1
提出用纯transformer去做图像识别,图像分类,在ImageNet, CIFAR-100, VTAB数据集上表现良好,最佳模型在ImageNet上达到88:55%,在ImageNet ReaL上达到90:72%,在CIFAR-100上达到94:55%,在VTAB套件19个任务上达到77:63%。
2 介绍
2.1 简介
2017年提出基于Self-attention的Transformer,由于Transformers的计算效率和可扩展性,它已经能够训练具有超过100B参数的空前规模的模型。
在计算机视觉中,CNN自从1989年以来一直占据主导地位,在2018年《Non-local neural networks》将CNN与Self-attention结合,2019年《Stand-alone self-attention in vision models.》直接用self-attention替代了卷积。但是在大规模的图片识别中,ResNet仍然是最好的。
作者思路是将图像分割成块,并提供这些块的线性嵌入序列作为Transformer的输入。在NLP应用程序中,图像块的处理方式与标记(单词)相同。以有监督的方式训练图像分类模型。
Transformer在中等规模的数据集(如ImageNet)上进行训练时,如果没有很强的正则化,这些模型的精确度会比同等规模的resnet低几个百分点。因为此时的Transformer缺乏一些归纳偏置,如翻译等效性和局部性,因此在数据量不足的情况下不能很好地概括。
然而,如果在更大的数据集(14M-300M图像)上训练模型,情况就会改变。我们发现,大规模的训练胜过归纳偏置。作者的模型(ViT)在足够规模的预训练和转移到数据点较少的任务中时,可以获得很好的效果。当在公共ImageNet-21k数据集或内部JFT-300M数据集上进行预训练时,ViT在多个图像识别基准上接近或超过了最新水平。特别是,最佳模型在ImageNet上达到88:55%,在ImageNet ReaL上达到90:72%,在CIFAR-100上达到94:55%,在VTAB套件19个任务上达到77:63%。
2.2 综述
- 2017年《Attention is all you need》提出Transformer应用到NLP
- 2019年《BERT: Pre-training of deep bidirectional transformers for language understanding》Bert,用于训练大量语料库,然后对特定的任务进行微调
- 2018年《Improving language under standing with unsupervised learning. 》使用去噪自监督预训练任务,而GPT工作线使用语言建模作为其预训练任务
- 2018年《Acceleration of stochastic approximation by averaging》只在每个查询像素的局部邻域应用self-attention,而不是全局应用。
- 2019年《Local relation networks for image recognition》局部多头点积自self-attention块完全可以代替卷积
- 2019年《Generating long sequences with sparse transformers》 Sparse Transformers 为了适用于图像,采用可伸缩的全局self-attention近似。
- 2019年《Scaling autoregressive video models》衡量注意力的另一种方法是将注意力应用到大小不同的块中
- 2020年《On the relationship between self attention and convolutional layers.》与VIta论文的工作相似,该模型提取大小为(2× 2) 从输入图像开始,并在顶部应用完全的self-attention。这个模型与ViT非常相似,但是VIt的工作进一步证明了大规模的预训练使vanilla transformers能够与最先进的CNNs竞争(甚至优于CNNs)。此外,该论文使用了2× 2像素,这使得模型只适用于小分辨率图像。而VIt可以处理中分辨率图像。
- 2019年《Attention augmented convolutional networks》结合了CNN与self-attention增强特征映射做图像分类
- 2018年《 Relation networks for object detection.》结合CNN与self-attention做目标检测
- 2018年《 Non-local neural networks》结合CNN与self-attention视频处理
- 2020年《Visual transformers: Token-based image representation and processing for computer vision》结合CNN与self-attention做图像分类
- 2020年《Object-centric learning with slot attention》结合CNN与self-attention做非监督目标发现
- 2020年《UNITER: UNiversal Image-TExt Representation Learning》结合CNN与self-attention做统一文本视觉任务
- 2020年《Generative pretraining from pixels.》与VIt论文相似的论文,图像GPT(IGPT)图像分类,在降低图像分辨率和颜色空间后,对图像像素应用Transformer。该模型以无监督的方式作为生成模型进行训练,然后可以对结果表示进行微调或线性探测以提高分类性能,在ImageNet上达到72%的最大准确率。
3 系统模型
3.1 模型简介
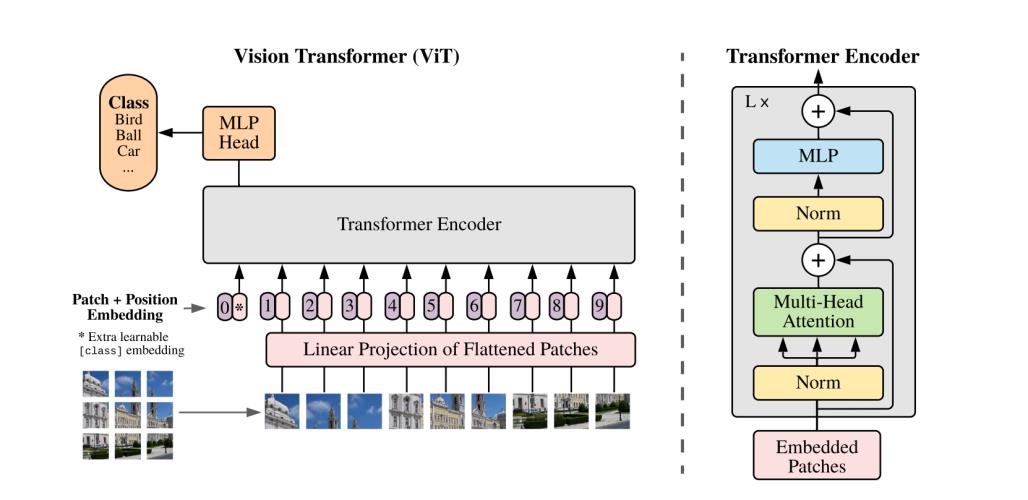
3.2 对高分辨率的图像进行微调模型
通常,在大型数据集上预先训练ViT,并对(较小的)下游任务进行微调。为此,我们移除预先训练好的预测头,并附加一个初始化为零D× K的预测头前馈层,其中K是下游类的数量。与训练前相比,在更高分辨率下进行微调通常是有益的。在输入高分辨率图像时,我们保持块大小不变,从而获得更大的有效序列长度。VIT可以处理任意的序列长度(直到内存限制),但是,预先训练的位置嵌入可能不再有意义。因此,作者根据预训练位置嵌入在原始图像中的位置对其进行二维插值。注意,该分辨率调整和块提取是关于图像的2D结构的归纳偏置被手动注入到VIT中的唯一点。
4 实验分析
评估了ResNet, Vision Transformer (ViT)和混合的表示学习能力。为了理解每个模型的数据需求,对不同规模的数据集进行预处理,并评估许多基准任务。考虑到预训练模型的计算成本,ViT的表现非常好,以较低的预训练成本在大多数识别基准上达到了最新水平。最后,用自我监督的方法做了一个小实验,证明了自我监督的ViT具有未来的发展前景。
5 反思和疑问
- 在此之前其实已经有两个相似的工作,一篇是《On the relationship between self attention and convolutional layers.》仅适用于小分辨率图像。第二篇,《Generative pretraining from pixels.》准确率相比VIT较低。
- VIT可以处理任意长度序列,并且对高低分辨率图像都可以处理。
- 论文中描述的模型结构和代码中的结构,似乎不一样,对应不上。还需要对代码进一步调试详细解读。
以上是关于文献学习An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale的主要内容,如果未能解决你的问题,请参考以下文章
机器学习笔记:ViT (论文 An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale)
An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
论文解读 - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(阅读笔记)
[Paper]AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
[Paper]AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE