机器学习笔记:ViT (论文 An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale)
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记:ViT (论文 An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale)相关的知识,希望对你有一定的参考价值。
ICLR 2021
0 前言
说到图像处理,一般想到的就是CNN/CNN的变体
机器学习笔记:CNN卷积神经网络_UQI-LIUWJ的博客-CSDN博客
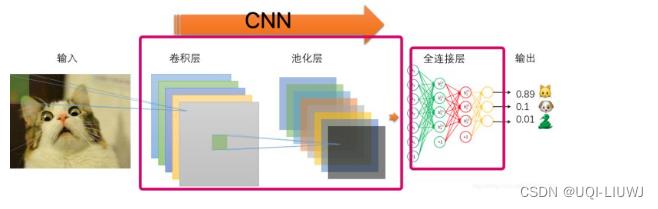
。ViT的想法是利用Transformer机制来替换CNN机制,将Transformer运用到图像分类中。
机器学习笔记:Transformer_UQI-LIUWJ的博客-CSDN博客
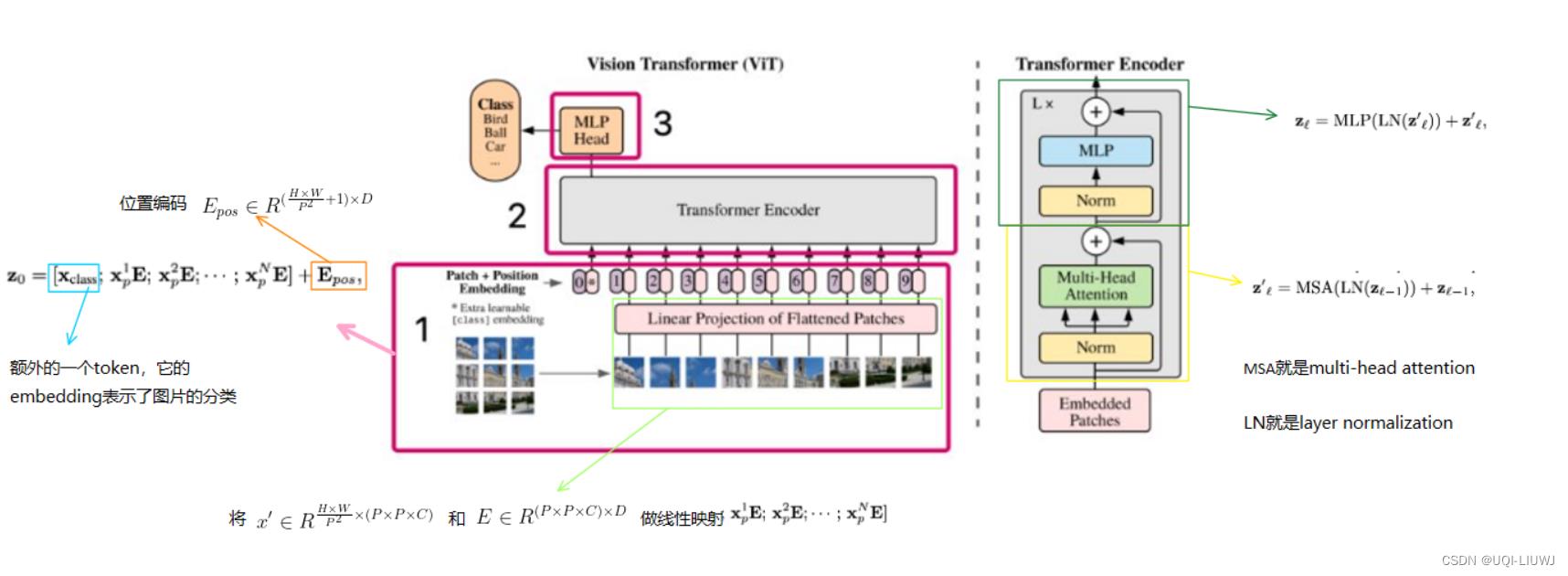
1 图像转成句子(图片 token化)

将图像分割成小块(image patch),并将这些块转化为序列,作为Transformer的输入。
图像块(image patches)相当于NLP任务中的单词(token)来做处理。以有监督的方式训练图像分类模型。
- 比如一张原始图像
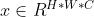 ,分辨率是H×W,通道数是C
,分辨率是H×W,通道数是C - 我们将其分割成P×P的patch组成的序列

2 整体流程
和Transformer的encoder流程差不多
以上是关于机器学习笔记:ViT (论文 An Image Is Worth 16X16 Words: Transformers for Image Recognition at Scale)的主要内容,如果未能解决你的问题,请参考以下文章
从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程
论文/机器学习笔记:SENet (Squeeze-and-Excitation Networks)
论文/机器学习笔记:SENet (Squeeze-and-Excitation Networks)
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(阅读笔记)