从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程
Posted fareise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程相关的知识,希望对你有一定的参考价值。
如果觉得我的算法分享对你有帮助,欢迎关注我的微信公众号“圆圆的算法笔记”,更多算法笔记和世间万物的学习记录~后台回复“VT”获取Vision Transformer论文整理
1. CV中的Transformer介绍
随着Transformer在NLP领域主流地位的确立,越来越多的工作开始尝试将Transformer应用到CV领域中。CV Transformer的发展主要经历了以下3个阶段;首先是在CNN中引入Attention机制解决CNN模型结构只能提取local信息缺乏考虑全局信息能力的问题;接下来,相关研究逐渐开始朝着使用完全的Transformer模型替代CNN,解决图像领域问题;目前Transformer解决CV问题已经初见成效,更多的工作开始研究对CV Transformer细节的优化,包括对于高分辨率图像如何提升运行效率、如何更好的将图像转换成序列以保持图像的结构信息、如何进行运行效率和效果的平衡等。本文梳理了近期10篇Transformer、Attention机制在计算机视觉领域的应用,从ViT到Swin Transformer,完整了解CV Transformer的发展过程。
2. Attention机制增强CNN阶段
CNN的模型结构特点是对局部信息汇聚建模,其劣势在于难以对长周期进行建模。而Attention模型有较强的的长周期建模能力,因此Attention Augmented Convolutional Networks(2020)提出使用Attention来弥补CNN在超长周期建模的不足。该方法将输入的图像[H, W, F]转换成二维度[H*W, F]作为Attention部分输入,Attention模型采用了multi-head attention的形式。为了弥补Transformer对于空间位置信息提取能力的缺失,本文借助了Self-Attention with Relative Position Representations(2018)的思路,在宽度和高度两个维度分别使用了相对位置编码增强Attention能力。最后,作者用Attention部分得到的信息和CNN部分得到的信息拼接到一起,共同进行后续任务,形成了二者的优势互补。这里简单介绍一下相对位置编码,它是一种替代Transformer中position embedding的方式,对于任意两个位置的元素i和,会将二者的相对位置embedding加入到计算attention的过程中。如果i和j距离为n,就用距离为n对应的一个可学习的embedding表示,同时设定某个阈值,如果i和j的距离超过k,就都用距离k对应的embedding表示。下面的公式左侧代表i和j的相对位置embedding aij怎么用在多头attention中,右侧表明了两个元素相对位置embedding的计算方法。通过引入relative position embedding,在attention模型中也可以实现平移不变性(因为平移后相对位置不变)
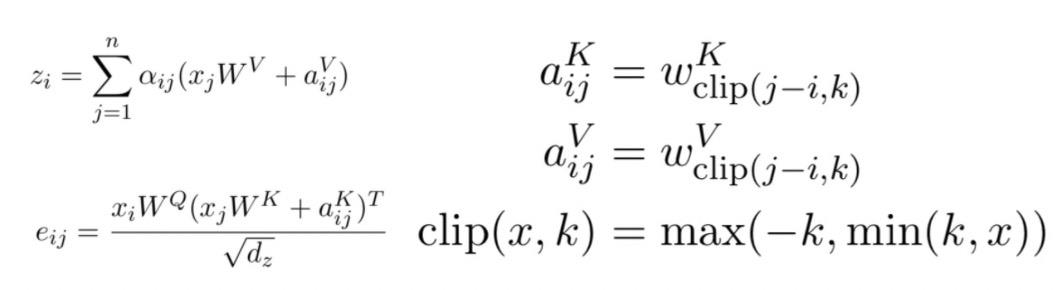
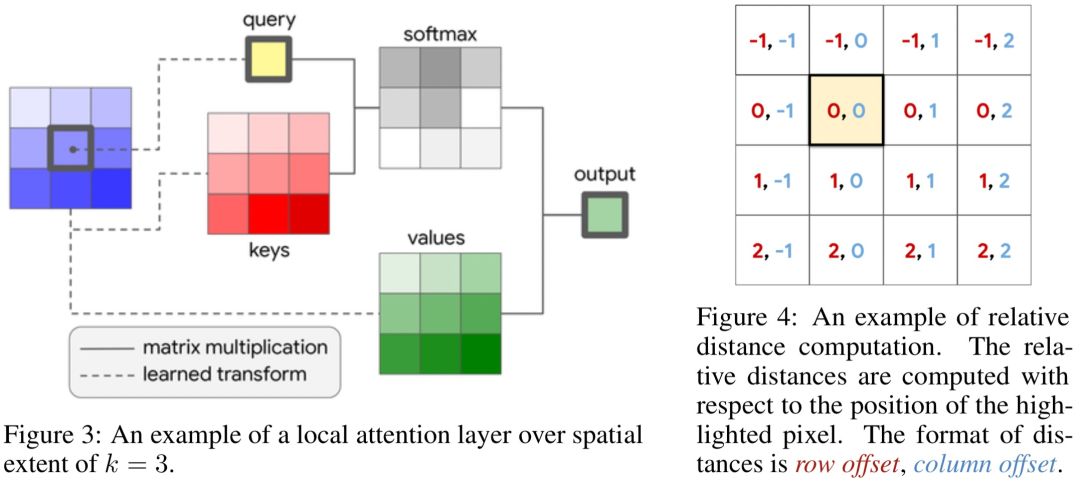
Stand-Alone Self-Attention in Vision Models(NIPS 2019)进一步提出完全使用Attention+相对位置embedding代替ResNet中的卷积模块,实现了全Attention的图像模型。与之前工作的差异是,本文提出使用local attention的方式,即类似于卷积,每个像素只和其周围几个像素点进行attention运算,降低了计算开销。图像中实现local attention的模型结构如下图所示。
3. Transformer完全替代CNN阶段
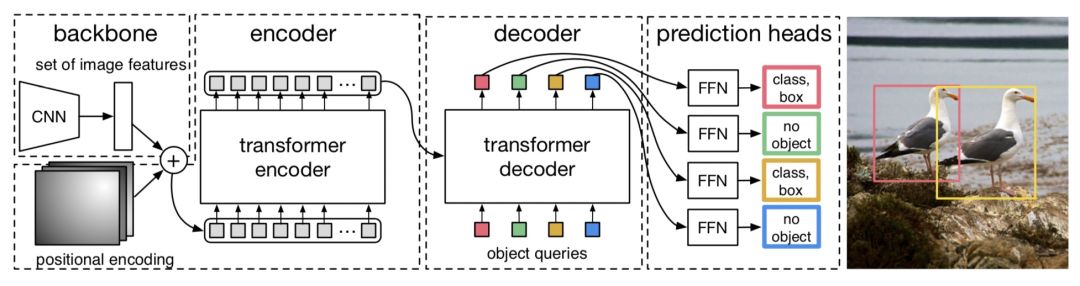
End-to-End Object Detection with Transformers(ECCV 2020,DERT)提出DERT模型,引入Transformer做目标检测任务。本文提出set prediction的方法解决目标检测任务,通过让模型预测N个元素(每个元素表示是否有目标,有目标的话预测目标的类别和位置),其中N大于图像中真正包含的目标,让这预测出来的N个结果和ground truth做一个匹配计算loss。这部分的细节感兴趣的同学可以阅读原文,我们下面主要介绍DERT的模型结构。DERT的目标是输入N个预测结果来和ground truth做匹配,采用了CNN+Transformer Encoder+Transformer Decoder的模型架构。输入图像维度为[3, W, H],首先利用CNN提取feature map,得到[C, W', H']的高阶表示。然后利用1*1的卷积将第一维进行压缩后,组成可以输入到Transformer模型中的2维序列数据,同时引入每个区块的position embedding和feature map对应进行拼接后输入到Encoder中,输入到Transformer Encoder中的维度为[d, W'*H']。Transformer Encoder的输出会进入到Decoder中,Decoder的输入也为可训练的N个position embedding,对应预测N个目标检测结果。最终N的输出分别进行FFN进行最终结果预测。DERT的模型结构如下图。
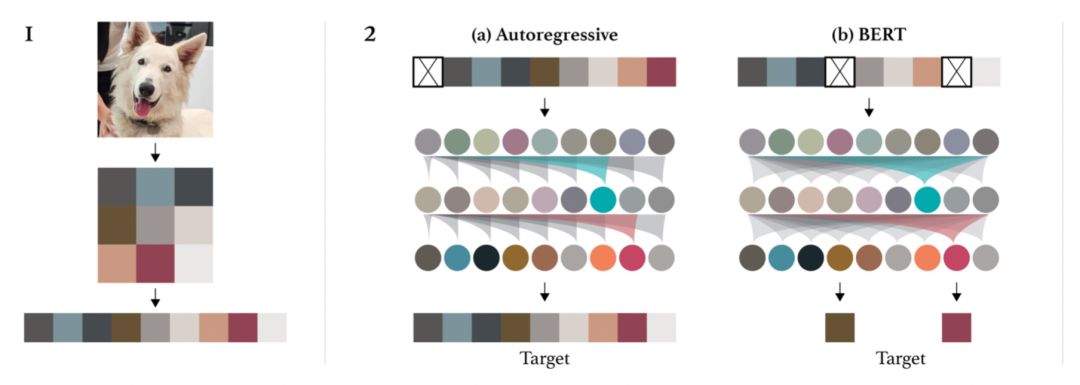
Generative Pretraining from Pixels(2020)提出使用GPT在大规模图像样本上进行无监督预训练,生成图像表示用于下游任务。这篇工作采用的方法和GPT在NLP中的应用相似,对图像进行预处理,转换成生成分辨率较低的,然后转换成一维序列,输入到GPT模型中。文中尝试了Autoregressive(单向预测下一个像素点)以及Bert(mask掉部分像素点用上下文信息预测)两种预训练优化目标。使用这种方法预训练得到的图像表示,经过finetune后,在ImageNet上取得了72%的准确率。
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(ICLR 2021,VIT)提出了VIT模型,完全复用了NLP中Transformer的模型结构解决图像问题。VIT的具体做法是将图像处理成类似NLP中输入token序列的形式,输入到基础的Transformer中,实现图像领域的Transformer使用。具体做法为,将图像划分成多个patch,假设原来图像的维度是[W, H, C](宽度*高度*channel),那么经过转换后的图像维度为[N, P*P*C],其中P代表将图像的分成了多少个块,P对应的就是图像转换成的序列的长度。接下来每个patch会使用一个NN网络映射成一个固定维度,输入到后续的Transformer Encoder中。此外,position embedding也使用的是一维的。为了进行图像分类,类似于Bert,在序列起始位置添加了一个用于分类的标识token。文中也提到,使用Transfomer解决图像问题的主要问题在于缺少图像相关的inductive bias,CNN中的平移不变性、二维空间的临近关系等,在Transformer中都无法引入。但是文中通过实验验证,如果在大量充足的数据上进行预训练,VIT仍然能取得不错的效果。同时文中也提到,如果训练数据不充足,VIT的效果会大打折扣
4. CV Transformer的效率和效果优化阶段
在VIT的基础上,出现了一系列从效率、效果等角度的改进方法。Transformer in Transformer(NIPS 2021)提出了TNT模型。该方法的核心思路是,将原来VIT中的patch再进一步细分成sub-patch,将每个patch看成是一个sentence,而patch的进一步细分得到的元素看成是word。首先使用一个Inner Transformer对一个patch内的sub-patch进行表示生成。然后融合patch和sub-patch的信息,使用Outer Transformer在patch粒度进行表示生成。这种方式比较类似于NLP中的word-level和char-level信息的组合,它的本质思路是,将图像分成patch粒度太粗了,由于一个数据集中图像的多样性,如果将patch分解成粒度更细的sub-patch,就能在数据中发现更多相似的sub-patch组,提升模型在数据上的学习能力和泛化性。
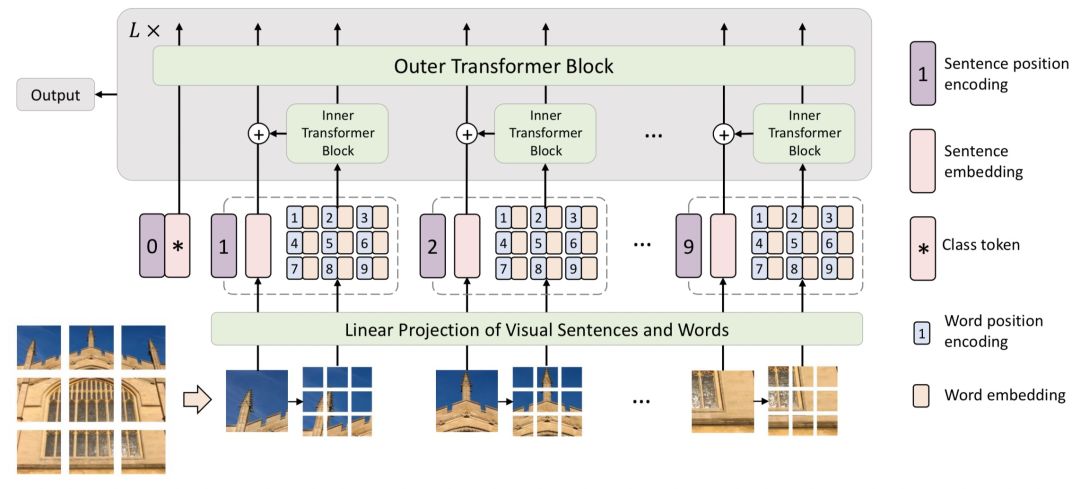
添加图片注释,不超过 140 字(可选)
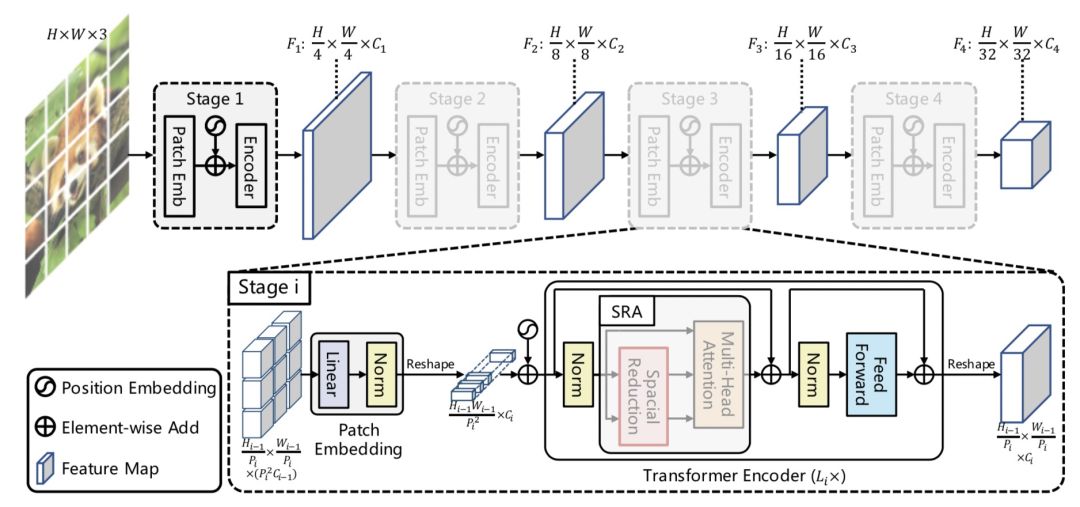
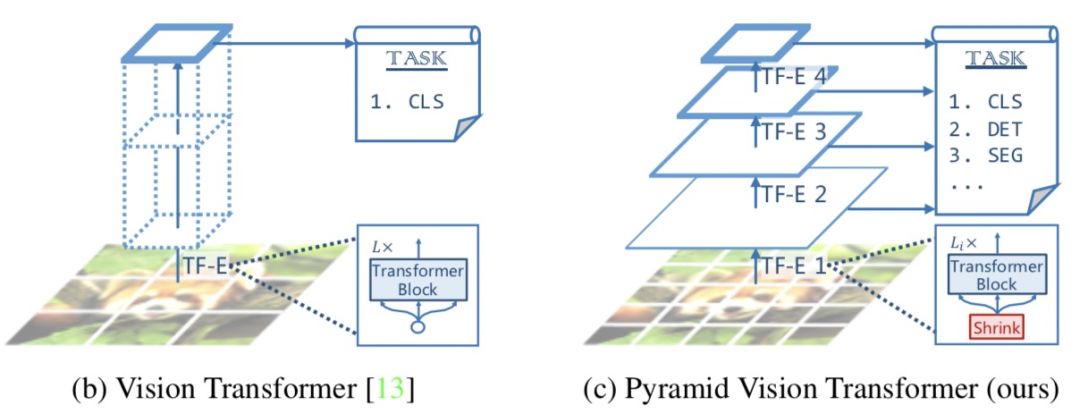
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions(ICCV 2021,PVT)提出了适用于像素级图像任务的Transformer模型(需要对每个像素点预测一个label)。之前的VIT将图像分成了patch,导致输出的结果分辨率较低,并且Transformer模型的计算开销随着序列长度增长而变大,直接应用像素级别的预测任务会导致计算和内存消耗暴涨。因此VIT还只适用于图像分类任务。为了解决上述问题,本文提出了将Pyramid CNN的思路引入Transformer,通过将初始分辨率调高,并逐层降低分辨率的方式,捕捉更细粒度信息,同时降低运行开销。PVT将模型分成4个阶段,每个阶段模型都会由patch embedding+Transformer组成,区别在于每层输出的分辨率是逐层降低的,从4*4的高分辨率逐渐变成32*32的低分辨率,适用于各种任务。模型结构图以及与VIT的对比如下:
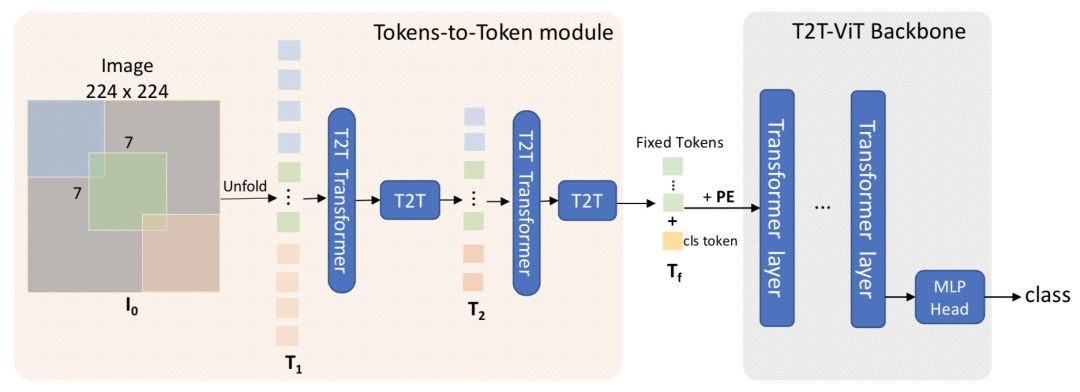
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet(ICCV 2021)提出了T2T-ViT模型。本文认为ViT之所以无法直接用中等数量数据集训练取得较好效果,是因为ViT对图像进行分patch拼接成序列的处理方法太简单了,模型无法学习到图像的结构信息,并且文中通过比较ViT和CNN中间每层输出的表示也印证了这一点。因此本文提出了新的Tokenize方法,将每一层的输出再还原成一个图像,然后在图像上进行soft split。Soft split指的是有重叠的进行patch划分,这样就建立起了上一层不同patch之间的关系。通过这种方法也使得网络输入序列的长度逐层减小。网络的具体结构如下图:
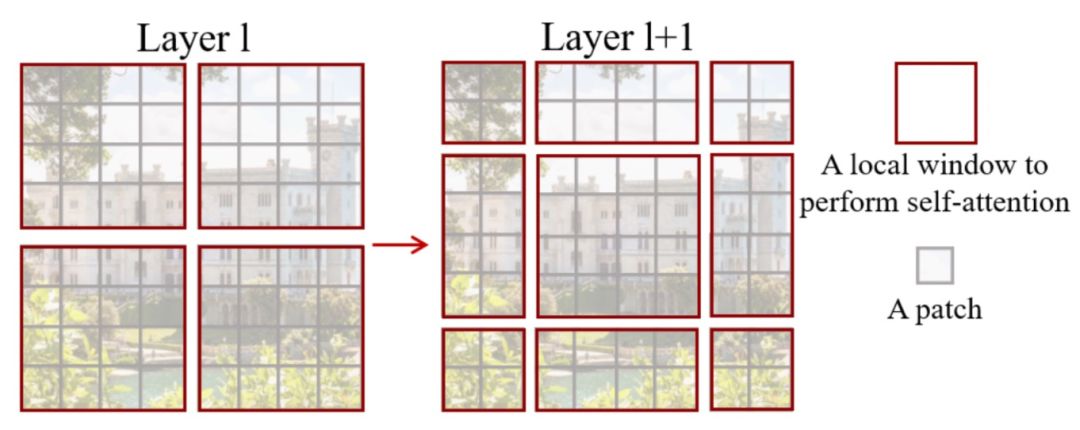
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(2021)的思路类似于PVT,也是将图像分成更细的batch,并且逐层合并降低分辨率。Swin Transformer中采用local attention的方式,将patch划分成window,patch间的attention只在window内进行,以提升运行效率。但是这样的问题在于不同window之间的patch无法进行信息交互了。为了解决这个问题,Swin Transformer又提出Shifted Window方法,在不同层采用不同的window配置,如下面这张图,在下一层中会将window位置进行2个patch的横向和纵向偏移,以使得上一层不同window内的patch进行信息交互。
5. 总结
本文通过近2年10篇计算机视觉顶会论文,梳理了Transformer在CN领域的发展历程。我们可以看到,Transformer在CV领域中的应用已经逐渐成熟,后续会有更多相关研究工作,这对计算机视觉、多模态领域都带来了极大的贡献。
后台回复“VT”获取Vision Transformer论文资料~
如果觉得我的算法分享对你有帮助,欢迎关注我的微信公众号“圆圆的算法笔记”,更多算法笔记和世间万物的学习记录~更多干货都在“圆圆的算法笔记”~
【历史干货算法笔记,更多干货公众号后台查看】
以上是关于从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程的主要内容,如果未能解决你的问题,请参考以下文章