论文解读 - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Posted XianxinMao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读 - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale相关的知识,希望对你有一定的参考价值。
目前我认为在分类领域上,最有研究价值的是 ResNet、Transformer。一个是从 Papers with code 的 benchmark 判断,另外一个是对以往 DenseNet、Inception 等网络的实验。深度学习从 2012 年的 AlexNet 开始,然后是 VGG,网络是往更深的方向发展,直到遇到一个问题,网络越深,模型性能开始下降。在排除了梯度消失/爆炸以及过拟合问题之后,发现是网络的优化困难问题。这时候提出的 Residual Learning,也就是 ResNet 解决了该问题。此后的 DenseNet 等网络也都包含 Skip connection,从设计上来看并未脱离这个框架范畴。再者 BiT Transfer 论文也证明 ResNet 在 ImageNet 上可达到 88% 左右的准确率,与最高的基于 Transformer 架构的 90% 也相差无几。
Transformer 目前在 NLP 占据主流地位,CNN 目前在 CV 占据主流地位,那么我们就会思考 Transformer 是否可以迁移应用到 CV 上,这里提一下 Transformer 的两个点,self-attention、序列化处理,其中 attention 机制在 CNN 里有引入,但是效果一般般,而 Transformer 更加彻底,直接应用到图像上。
Self-attention-based architectures, in particular Transformers, have become the model of choice in natural language processing(NLP).
Transformer 架构目前在 NLP 领域占据统治地位,那么这个架构是否可以迁移到 CV 领域呢,在 CNN 架构中,我们会引入注意力模块,然而注意力模块在 Transformer 上很自然(它的本质是一个序列处理,注意力只是其中一个重要模块,特点是 global self-attention),所以是否可以把 Transformer 应用在图像上呢,这个思考很有价值。
We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks(ImageNet, CIFAR-100, VTAB). Vision Transformer(ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
解读: 这里的出发点呢,是以前的 CNNs 网络里有添加注意力机制模块,这里更加彻底,把整个网络用 Transformer 来替代。这里呢,对于 Vision Transformer 来说 ImageNet-1k 也只是中等规模的数据集,所以归根结底,还是要大数据集来做预训练,以提高泛化性,但是这里也要注意不同架构的网络,指 CNNs 和 Transformer,两者之间的性能可能随数据集规模的变化趋势也会不一样?下面的一句话,算是可以回答这个问题吧,我的理解是 Transformer 的上限更高吧。
With the models and datasets growing, there is still no sign of saturating performance.
Inspired by the Transformer scaling successes in NLP, we experiment with applying a standard Transformer directly to images, with the fewest possible modifications. To do so, we split an image into patches and provide the sequence of linear embeddings of these pathces as an input to a Transformer. Image patches are treated the same way as tokens(words) in an NLP application. We train the model on image classification in supervised fashion.
When trained on mid-sized datasets such as ImageNet without strong regularization, these models yield modest accuracies of a few percentage points below ResNets of comparable size. This seemingly discouraging outcome may be expected: Transformers lack some of the inductive biases inherent to CNNs, such as translation equivariance and locality, and therefore do not generalize well when trained on insufficient amout of data.
However, the picture changes if the models are trained on larger datasets(14M-300M images). We find that large scale training trumps inductive bias. Our Vision Transformer(ViT) attains excellent results when pre-trained at sufficient scale and transferred to tasks with fewer datapoints. When pre-trained on the pubilc ImageNet-21k dataset or the in-house JFT-300M dataset, ViT approaches or beats state of the art on multiple image recognition benchmarks.
解读: 对于 CNNs 来说,我认为只需要研究到 ResNet 就够了,这个是因为看了 papers with code 的 benckmark 以及 BiT transfer 这篇论文之后的思考。Transformer 对于数据的要求更高,因为缺失 inductive biases,对比 ViT 和 BiT,其实两者的准确率是差不多的,所以貌似也看不太出来 Transformer 比 CNNs 更有优势吧。
When feeding images of higher resolution, we keep the patch size the same, which results in a larger effective sequence length. The Vision Transformer can handle arbitrary sequence lengths(up to memory constraints), however, the pre-trained position embeddings may no longer be meaningful. We therefore perform 2D interpolation of the pre-trained position embeddings, according to their location in the original image. Note that this resolution adjustment and patch extraction are the only points at which an inductive bias about the 2D structure of the images is manually injected into the Vision Transformer.
Navie application of self-attention to images would require that each pixel attends to every other pixel. With quadratic cost in the number of pixels, this does not scale to realistic input sizes.
Note that the Transformer’s sequence length is inversely proportional to the square of the patch size, thus models with smaller patch size are computationally more expensive.

解读: 从上图来看,ViT 的准确率优势并不是特别大,但是训练时间成本上确实很有优势,达到相同精度对比情况下。
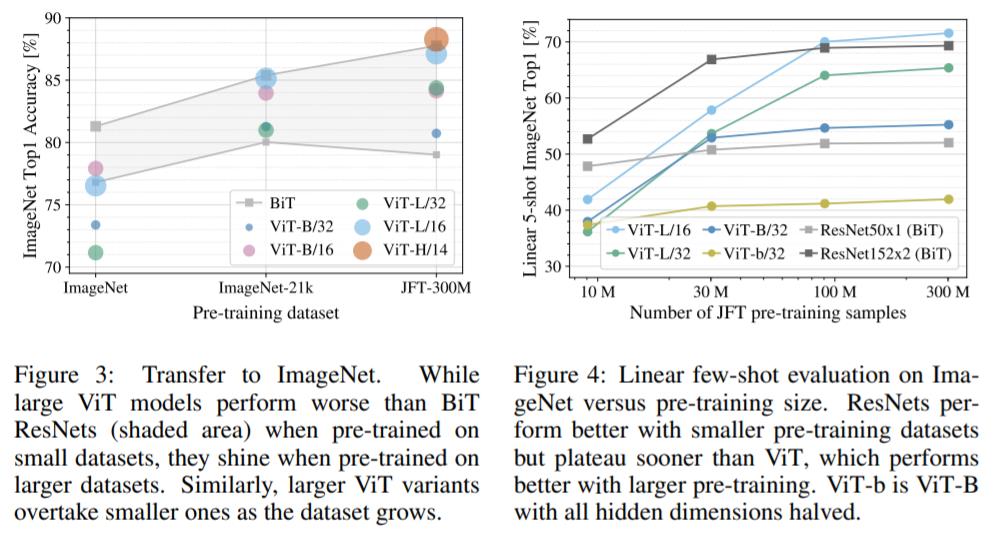
This result reinforces the intuition that the convolutional inductive bias is useful for smaller datasets, but for larger ones, learning the relevant patterns directly from data is sufficient, even beneficial.
解读: 从上图可以看出来,对于在 ImageNet-1k 上预训练 ViT,其结果比 BiT 差,对于在 ImageNet-21k 上预训练 ViT,其结果和 BiT 相当,对于在 JFT-300M 上预训练,结果比 BiT 略微好一些。我的想法,目前来看,分类上我觉得用 CNNs 就行,毕竟模型训练出来之后,我们还需要经过压缩等手段,然后再部署上线。卷积网络具有归纳偏置,这个对于小数据集来说是有用的,但是对于更大型的数据集,我们可以直接学习其中的相关模式,这个本质上有点类似于上帝视角了,只要我们囊括了该场景下的所有情况,那么模型的效果就会很好。
Transformers show impressive performance on NLP tasks. However, much of their success stems not only from their excellent scalability but also from large scale self-supervised pre-training.
Transformers are networks that operate on sequences of data, for example, a set of words. These sets of works are first tokenized and then fed into the transformer. Transformers add Attention (a quadratic operation – calculates pairwise inner product between each pair of the tokenized words. As the number of words increases, so does the number of operations).
The authors of ViT solve this problem by using global attention, but not on the entire image, rather on multiple image patches. So first a large image is separated into multiple small patches (for example 16 x 16 pixels).
解读: ViT 使用全局注意力机制,不同点在于把原始图像切分成多个 patches
However, if entire image data is fed into a model, rather than just the parts that the filters can extract (or it considers important), the chances of the model performing better are higher. This is exactly what is happening inside a Visual Transformer.
解读: CNN 存在 inductive biases, Transformer 存在 global self-attention, 对于数据量越大的情况,数据的 relevant patterns 越全,这时候 Transformer 更有优势,也可以说明它的全局掌控能力更强。
This example implements the Vision Transformer (ViT) model for image classification, and demonstrates it on the CIFAR-100 dataset. The ViT model applies the Transformer architecture with self-attention to sequences of image patches, without using convolution layers.
The PatchEncoder layer will linearly transform a patch by projecting it into a vector of size projection_dim. In addition, it adds a learnable position embedding to the projected vector.
class PatchEncoder(layers.Layer):
def __init__(self, num_patches, projection_dim):
super(PatchEncoder, self).__init__()
self.num_patches = num_patches
self.projection = layers.Dense(units=projection_dim)
self.position_embedding = layers.Embedding(
input_dim=num_patches, output_dim=projection_dim
)
def call(self, patch):
positions = tf.range(start=0, limit=self.num_patches, delta=1)
encoded = self.projection(patch) + self.position_embedding(positions)
return encoded
The ViT model consists of multiple Transformer blocks, which use the layers.MultiHeadAttention layer as a self-attention mechanism applied to the sequence of patches. The Transformer blocks produce a [batch_size, num_patches, projection_dim] tensor, which is processed via an classifier head with softmax to produce the final class probabilities output.
Unlike the technique described in the paper, which prepends a learnable embedding to the sequence of encoded patches to serve as the image representation, all the outputs of the final Transformer block are reshaped with layers.Flatten() and used as the image representation input to the classifier head. Note that the layers.GlobalAveragePooling1D layer could also be used instead to aggregate the outputs of the Transformer block, especially when the number of patches and the projection dimensions are large.
def create_vit_classifier():
inputs = layers.Input(shape=input_shape)
# Augment data.
augmented = data_augmentation(inputs)
# Create patches.
patches = Patches(patch_size)(augmented)
# Encode patches.
encoded_patches = PatchEncoder(num_patches, projection_dim)(patches)
# Create multiple layers of the Transformer block.
for _ in range(transformer_layers):
# Layer normalization 1.
x1 = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
# Create a multi-head attention layer.
attention_output = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=projection_dim, dropout=0.1
)(x1, x1)
# Skip connection 1.
x2 = layers.Add()([attention_output, encoded_patches])
# Layer normalization 2.
x3 = layers.LayerNormalization(epsilon=1e-6)(x2)
# MLP.
x3 = mlp(x3, hidden_units=transformer_units, dropout_rate=0.1)
# Skip connection 2.
encoded_patches = layers.Add()([x3, x2])
# Create a [batch_size, projection_dim] tensor.
representation = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
representation = layers.Flatten()(representation)
representation = layers.Dropout(0.5)(representation)
# Add MLP.
features = mlp(representation, hidden_units=mlp_head_units, dropout_rate=0.5)
# Classify outputs.
logits = layers.Dense(num_classes)(features)
# Create the Keras model.
model = keras.Model(inputs=inputs, outputs=logits)
return model
下图是一个 Vision Transformer 的训练结果,此处不加载预训练模型,只是用于作为 Demo。

以上是关于论文解读 - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale的主要内容,如果未能解决你的问题,请参考以下文章
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
文献学习An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
文献学习An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[Paper]AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
[Paper]AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE(阅读笔记)