An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
Posted 代码空间
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale相关的知识,希望对你有一定的参考价值。
模型如下图所示:
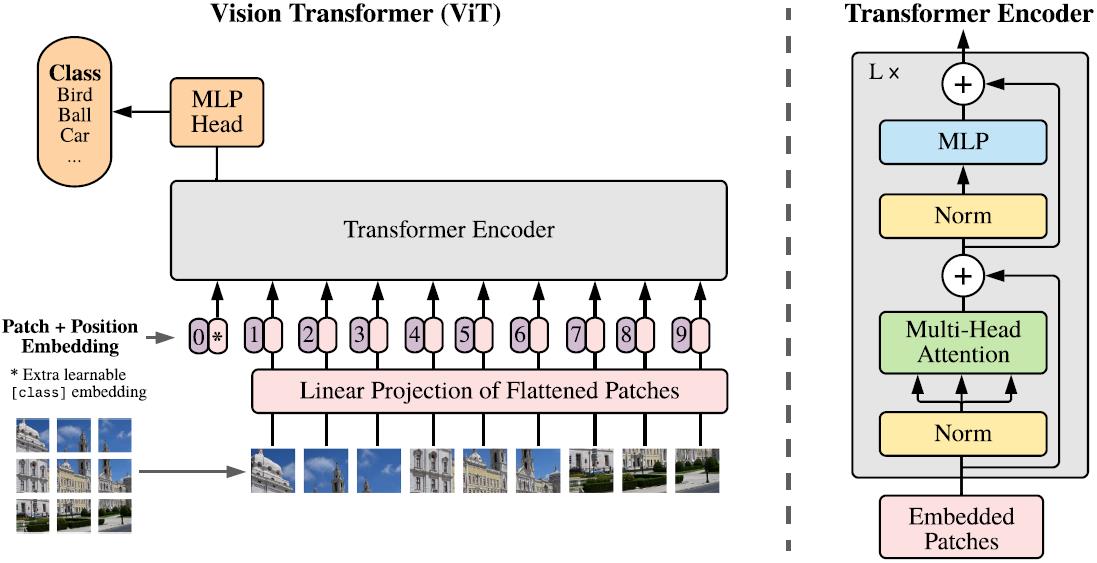
将H×W×C的图像reshape成了N×(P2×C),其中(H,W)是图像的原始分辨率,C是通道数,(P,P)是每个图像块的分辨率,N=H×W/P2为图像块的数量,将一个图像块使用可学习的线性层映射到维度为D的隐藏向量,如式(1)所示,线性映射的输出称为patch embeddings.在patch embeddings之前增加了一个可学习的embedding:xclass.patch embeddings后面的是position embeddings,用于保留位置信息,再加上多头自注意力(MSA),MLP,Layernorm(LN),最后输出Encoder.

AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
哈喽,大家好!欢迎大家点进这个链接,为什么要选择读这篇论文呢,一个原因,这是一篇非常经典的论文,提出一种将Transformer应用在计算机视觉的方法,而且现如今很多很多的基于这篇文章的工作在不断创新发展,有一种奠基石的感觉,而且模型跑起来非常方便。当然这这是一个原因,还有另一个原因,就是关于这篇论文的讲解非常多,所以对我来说,可以参考着来阅读,这个吸引力真的太大了,嘿嘿一笑。

如果这篇文章讲的不好的话,还希望大家多多包涵。
那我们就开始吧!


首先让我们来了解一些背景。
在计算机视觉领域,注意力机制要么与卷积网络结合使用,要么用于替换卷积网络的某些组成部分,作者认为这种对卷积网络的依赖是不必须的,VIT可以基于图像patch序列,使用纯Transformer架构,并证明可以更好地执行图像分类任务。(哇哦,这似曾相识的开场白)
接下来,让我们来回顾一下关于Transformer的优点和缺点。
Transformer的优点
1、具有优秀的运算效率和扩展性
2、可以通过大量数据做预训练并微调在其他数据集来减少运算资源
3、Attention(注意力机制)
Transformer的缺点
1、需要大量训练数据
2、缺乏像CNN固有的归纳偏差(inductive bias)如平移不变性(translation equivariance)、局部性(locality)
3、训练数据量不足时会无法达到很好的泛化能力
接下来,让我们来看看VIT是如何解决把图片送入Transformer这个难题的呢。

输入图像大小HWC,将其分割成N个PPC的patch,基于一个可训练的线性投影将每个patch投影到D维,最终输入大小为ND。
与Bert的【class】token类似,VIT在迁入的patch序列放一个可学习的嵌入作为类别的token,在该位置的输出后接MLP head来做分类。
位置嵌入仍然使用一维位置嵌入。
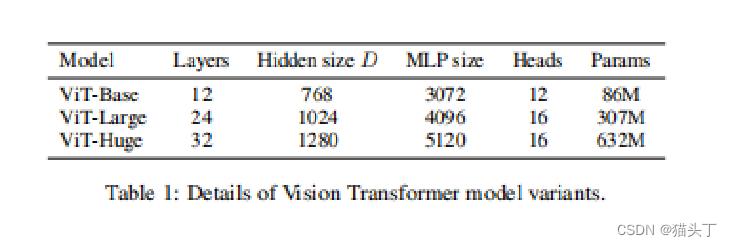
基于模型大小VIT模型有三个变体
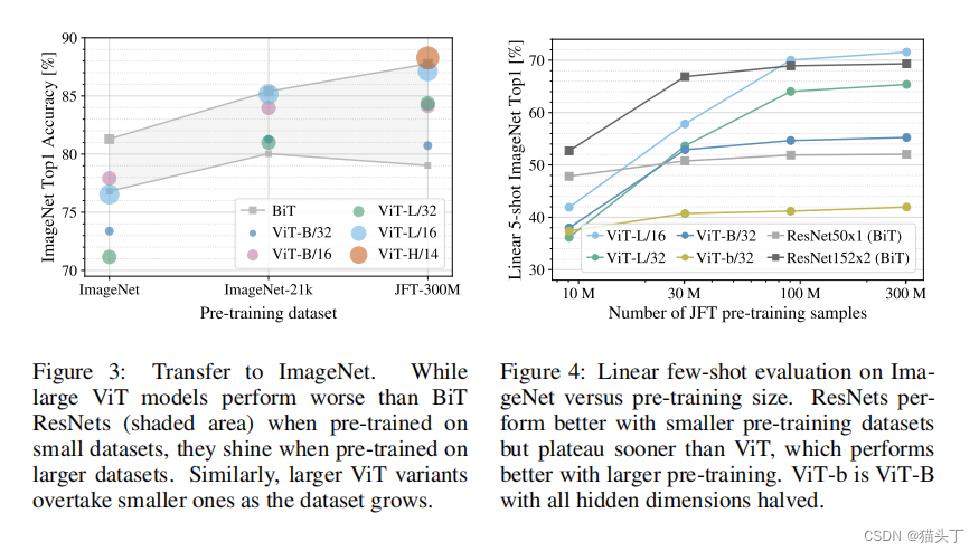
将模型在ImageNet、ImageNet-21k和JFT-300M数据集上进行预训练
接下来是一些VIT与SOTA的实验对比

以上是关于An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale的主要内容,如果未能解决你的问题,请参考以下文章