NLP讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert 方案
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert 方案相关的知识,希望对你有一定的参考价值。
1 相关信息
2 引言
(1)Baseline的选择
我选择的是Datawhale闫强“致Great Bert方案”进行的迭代优化,其中是使用加载预训练模型,进行微调。用到了差分学习率和AdamW 优化器。这些点这对于Bert的微调有巨大的作用。还有更多Bert微调技巧来自于论文《How to Fine-Tune BERT for Text Classification?》论文中提到的微调策略有
- 处理长文本 我们知道BERT 的最大序列长度为 512,BERT 应用于文本分类的第一个问题是如何处理长度大于 512 的文本。本文尝试了以下方式处理长文章。
- 截断法 文章的关键信息位于开头和结尾。 我们可以使用三种不同的截断文本方法来执行 BERT 微调。
- 只截断头部
- 只截断尾部
- 头尾截断
- 层级法 输入的文本首先被分成k = L/510个片段,喂入 BERT 以获得 k 个文本片段的表示向量。 每个分数的表示是最后一层的 [CLS] 标记的隐藏状态,然后我们使用均值池化、最大池化和自注意力来组合所有分数的表示。
- 不同层的特征 BERT 的每一层都捕获输入文本的不同特征。 改论文研究了来自不同层的特征的有效性,可以看到:最后一层表征效果最好;最后4层进行max-pooling效果最好
- 灾难性遗忘 Catastrophic forgetting (灾难性遗忘)通常是迁移学习中的常见诟病,这意味着在学习新知识的过程中预先训练的知识会被遗忘。 因此,本文还研究了 BERT 是否存在灾难性遗忘问题。 我们用不同的学习率对 BERT 进行了微调,发现需要较低的学习率,例如 2e-5,才能使 BERT 克服灾难性遗忘问题。 在 4e-4 的较大学习率下,训练集无法收敛。所以当预训练模型失效不能够收敛的时候多检查下超参数是否设置有问题。
- Layer-wise Decreasing Layer Rate 逐层降低学习率 下表 显示了不同基础学习率和衰减因子在 IMDb 数据集上的性能。 我们发现为下层分配较低的学习率对微调 BERT 是有效的,比较合适的设置是 ξ=0.95 和 lr=2.0e-5
(2)方案的改进

通过以下方案,将单模型Bert从0.79逐步提升到0.8246,最终通过模型融合得到最高得分0.8304
- 数据预处理
Bert的数据预处理,只做了所有字母转换为小写和词性还原,词性还原比如working还原为work,采用nltk.stem.WordNetLemmatizer.lemmatize(word)工具包。其他的预处理,则是适得其反,过多的预处理,会降低模型精度,因为通过查阅资料,Bert预训练的模型,在训练当初就是使用原生数据训练的,为了达到更好的fine tune微调效果,在使用预训练模型的数据尽量与训练模型时候的数据形式保持统一。
- K折交叉验证
选择的是5折2epoch训练,3090的显卡,5W的数据,batch—size为10,bert_base都得训练7个小时左右,bert_large 10个小时左右,Roberta_large 14个小时左右。更别说后期通过数据增强和加入伪标签总训练数据近16W的时候,训练时间加倍。一训练就是一整天。所以选择5折2epoch是迫不得已,通过观察发现,训练完模型都没有过拟合,完全可以加大训练深度,设4epoch模型精度会更高。
- Bert+Bi-LSTM
- bert_base
- Bert_large
- Roberta_large
Bert_ base模型最小,有444M,8G的显存的勉强能跑起来,模型精度在bert中最低,历史最高得分0.8162。bert_large模型规模中等,1G以上的,11G的显存都无法跑起来。模型精度中等,历史最高得分0.8171。Roberta_large规模比Bert_large还要大,需要的显存更大。模型精度最高历史最高得分0.8246,通过其他Baseline的启发,在bert后加一层Bi-LSTM能提高千分点。也有方案加一层Attention的,但是我们没有取得成功。
- 数据增强:具体实现见英文文本数据增强
- 第一种:随机删除、随机替换、同义词替换
- 第二种:互译(回译):翻译成其他语言再翻译会英文
第一种方式,将原始训练集5W的数据全部增强,第二种方式也将原始5W数据进行了增强。在传统 深度学习模型TextCNN、FastText方案中,这两种增强并没有带来增益,但是在Bert中,两种数据增强方式,都带来了增益。
这两种方式我们尝试了三种组合。带来的增益幅度也是不一样的
(1)原始数据5W+第一种数据增强5W:提升0.05+
(2)原始数据5W+第二种数据增强5W:提升0.05+
(3)原始数据5W+第一种数据增强5W+第二种数据增强5W:提升0.1+
- 伪标签:具体实现见【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–6 提分方案
- 根据多模型结果投票的原理
将测试集放入各个模型中预测,得到多个模型的预测结果,选择各个模型都投票的数据,给测试集做伪标签,即获得Top K 的高质量标签,再将这些伪标签和对应的文本数据加入训练集中重新从零训练模型。直接将线上提升0.1+个点,反复重复以上操作,还能得到更高准确率,直到不再提升。该方式在传统DL 方案中能提升0.3个点,绝对的大杀器。
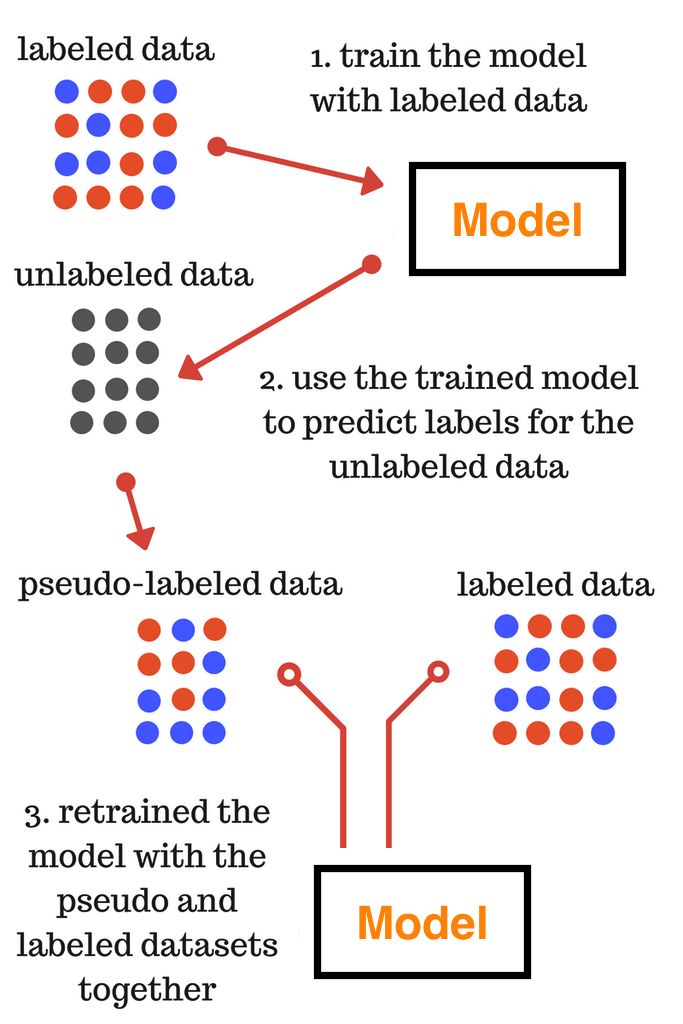
注意图片中的第二个Model和第一个Model不是同一个,第二个Model,是重新训练出来的
- 调参
- Batch_size
- 学习率
- 文本截断长度MAX_LEN
注意本次任务中通过对比实验,Batch_size选择的是10 ,对应模型初始学习率2e-5,全连接层的初始学习率是1e-4。如果显存够大,可以加倍,但是学习率也需要加倍。实验过程中,batch-size为4时,模型精度更高,但是太费时,我们只能舍弃精度,加快训练。
文本的最大长度,通过实验对比,选择过100、200、300,发现300的时候模型精度最高
- 混合精度训练,具体实现见【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–6 提分方案
混合精度训练是在尽可能减少精度损失的情况下利用半精度浮点数加速训练。它使用FP16即半精度浮点数存储权重和梯度。在减少占用内存的同时起到了加速训练的效果。
- 模型融合:具体实现见【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–6 提分方案
- Stacking
- Voting投票融合
Stacking 是将验证集和测试集同时放入多个模型中预测,各自得到预测矩阵,再将每个模型的预测矩阵水平合并得到新的矩阵,则将验证集合并的预测矩阵作为基模型的训练集,去训练基模型,基模型此任务中选择的LogisticRegression 。用测试集合并的预测矩阵放入基模型预测作为最终的预测值。
Voting 在分类任务中是常用的融合技巧,以下一张图,一目了然,每一列表示一个模型的预测结果,每行去计数,每行出现次数最高的数即是该行的最终值。

但是我们的最终融合方式并不是简单的等权融合,而是变形的加权融合。是把个模型的历史的高分结果,进行了按比例融合,选择了3个bert_base、4个roberta_large、3个bert_large、一个robert_base、1个机器学习LGB、1个textcnn、1个fasttext。如下图所示
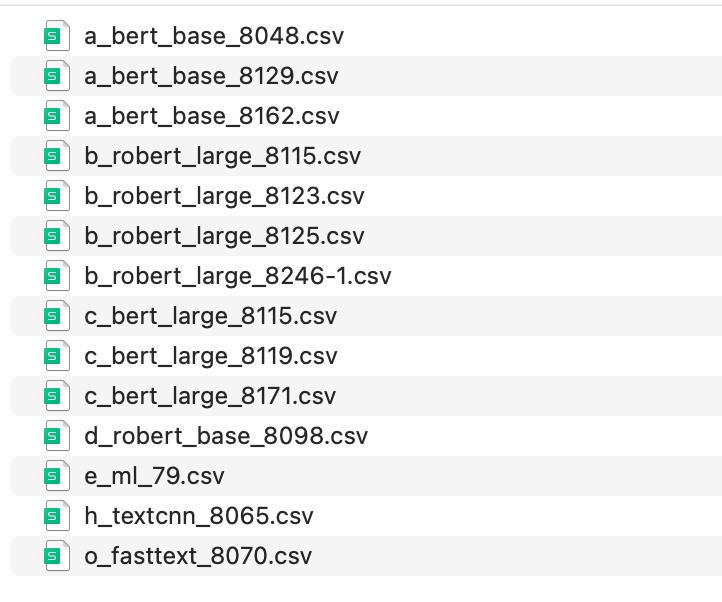
3 实现
3.1 数据预处理
(1)加载包
import pandas as pd
from nltk.stem import WordNetLemmatizer
from tqdm import tqdm
import re
import nltk
tqdm.pandas()
import re
import os
import pickle
train = pd.read_csv('./data/train_data.csv',sep="\\t")
test = pd.read_csv('./data/test.csv', sep='\\t')
def preprocess_text(document):
stemmer = WordNetLemmatizer()
text = str(document)
# 替换换行符
text = text.replace("\\n", ' ')
# 用单个空格替换多个空格
text = re.sub(r'\\s+', ' ', text, flags=re.I)
# 转换为小写
text = text.lower()
# 词形还原
tokens = text.split()
tokens = [stemmer.lemmatize(word) for word in tokens]
preprocessed_text = ' '.join(tokens)
return preprocessed_text
train["title"] = train["title"].progress_apply(lambda x: preprocess_text(x))
train["abstract"] = train["abstract"].progress_apply(lambda x: preprocess_text(x))
test["title"] = test["title"].progress_apply(lambda x: preprocess_text(x))
test["abstract"] = test["abstract"].progress_apply(lambda x: preprocess_text(x))
(2)训练集预处理
train_text_list = []
for index, row in train.iterrows():
title = row["title"]
abstract = row["abstract"]
text = "[CLS] " + title + " [SEP] " + abstract + " [SEP]"
train_text_list.append(text)
train['text'] = train_text_list
label_path = "data/pseudo_data/label_id2cate.pkl"
#将标签进行转换
label_id2cate = dict(enumerate(train.categories.unique()))
label_cate2id = {value: key for key, value in label_id2cate.items()}
with open(label_path, 'wb') as f:
pickle.dump(label_id2cate, f, pickle.HIGHEST_PROTOCOL)
train['label'] = train['categories'].map(label_cate2id)
train_data = pd.DataFrame(columns=['text','label'])
train_data['text'] = train['text']
train_data['label'] = train['label']
train_data.to_csv('data/train_clean_data.csv', sep='\\t',index=False)
(3)测试集预处理
test_text_list = []
for index, row in test.iterrows():
title = row["title"]
abstract = row["abstract"]
text = "[CLS] " + title + " [SEP] " + abstract + " [SEP]"
test_text_list.append(text)
test['text'] = test_text_list
pseudo_label = pd.read_csv("./submit_voting-8-9-2.csv")
test['label'] = pseudo_label['categories'].map(label_cate2id)
# 去除换行符
test_data = test.drop(['paperid', 'title', 'abstract'], axis=1, inplace=False)
test_data.to_csv('data/test_clean_data.csv', sep='\\t', index=False)
3.2 Bert
bert_base、bert_large、roberta_large代码都是一样的,唯一的不同在于使用预训练模型和对应分词器的选择不同。在以下代码会注释说明
(1)加载包
# 导入transformers
import transformers
from transformers import AutoConfig,AutoModel,AutoTokenizer,logging
from torch.utils.data import RandomSampler,Dataset, DataLoader
from transformers import BertModel, BertTokenizer, BertConfig, AdamW, get_linear_schedule_with_warmup
from transformers import RobertaTokenizer, RobertaModel
# 导入torch
import torch
import torch.nn as nn
import torch.nn.functional as F
# 常用包
import re
import os
import numpy as np
import pandas as pd
from tqdm import tqdm
import pickle
import os
import torch
import torch.nn as nn
from torch.utils import data
from sklearn.utils import resample
from sklearn.metrics import accuracy_score
# 全局变量
os.environ["TOKENIZERS_PARALLELISM"] = "false"
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
(2)模型结构
cache_dir = '/media/mgege007/winType/cache'
class PaperClassifier(nn.Module):
def __init__(self):
n_classes = 39
super(PaperClassifier, self).__init__()
# 如果是Bert_large,此处是
# PRE_TRAINED_MODEL_NAME = "bert-large-uncased"
# self.robert = BertModel.from_pretrained(PRE_TRAINED_MODEL_NAME)
# 如果是bert_base,此处是
PRE_TRAINED_MODEL_NAME = "bert-base-uncased"
self.robert = BertModel.from_pretrained(PRE_TRAINED_MODEL_NAME)
# 如果是roberta_large,此处是
# PRE_TRAINED_MODEL_NAME = 'roberta-large'
# self.robert = RobertaModel.from_pretrained(PRE_TRAINED_MODEL_NAME)
self.bilstm = nn.LSTM(input_size=self.robert.config.hidden_size,
hidden_size=self.robert.config.hidden_size, batch_first=True, bidirectional=True)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.robert.config.hidden_size * 2, n_classes)
def forward(self, input_ids, attention_mask):
last_hidden_out, pooled_output = self.robert( # 只要了句子级表示? _:[10, 300, 768] [16, 768]
input_ids=input_ids,
attention_mask=attention_mask) # [16, 300]300是句子长度
last_hidden_out = self.drop(last_hidden_out)
output_hidden, _ = self.bilstm(last_hidden_out) # [10, 300, 768]
output = self.drop(output_hidden) # dropout
output = output.mean(dim=1)
return self.out(output)
(3)读取数据
def data_process():
train = pd.read_csv('data/train_clean_data.csv', sep='\\t')
test = pd.read_csv('data/test_clean_data.csv', sep='\\t')
label_path = "data/label_id2cate.pkl"# label编码所需要的字典
if os.path.exists(label_path):
with open(label_path, 'rb') as f:
label_id2cate = pickle.load(f)
return train, test, label_id2cate
(4)封装数据集
class PaperDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, item):
"""
item 为数据索引,迭代取第item条数据
"""
text = str(self.texts[item])
label = self.labels[item]
encoding = self.tokenizer.encode_plus( # 等价于tokenizer.tokenize() + tokenizer.convert_tokens_to_ids()
text,
add_special_tokens=True,
max_length=self.max_len,
truncation=True,
return_token_type_ids=True,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
return {
'texts': text,
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label, dtype=torch.long)
}
def create_data_loader(df, tokenizer, max_len, batch_size,sampler):
ds = PaperDataset( # dataset
texts=df['text'].values,
labels=df['label'].values,
tokenizer=tokenizer,
max_len=max_len
)
return DataLoader(
ds,
batch_size=batch_size,
sampler = sampler,
num_workers=4, # 多线程
pin_memory=True # 页锁定内存
)
def create_test_loader(df, tokenizer, max_len, batch_size):
ds = PaperDataset( # dataset
texts=df['text'].values,
labels=df['label'].values,
tokenizer=tokenizer,
max_len=max_len
)
return DataLoader(
ds,
batch_size=batch_size,
num_workers=4,#多线程
pin_memory=True # 页锁定内存
)
(5)定义1个epoch训练
def train_epoch(model, data_loader, loss_fn, optimizer, device, scheduler):
print("start training!")
model = model.train()
losses = []
pred_ls = []
label_ls = []
accumulate_step = 10
i = 0
for d in tqdm(data_loader):
input_ids = d["input_ids"].to(device)
attention_mask = d["attention_mask"].to(device)
targets = d["labels"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = loss_fn(outputs, targets)
losses.append(loss.item())
loss = loss/accumulate_step
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
if (i+1)%accumulate_step ==0:
optimizer.step()
scheduler.step()
optimizer.zero_grad()
i+=1
label_ls.extend(d["labels"])
pred_ls.extend(preds.tolist())
correct_predictions = accuracy_score(label_ls, pred_ls)
return correct_predictions, np.mean(losses)
# 验证
def eval_model(model, data_loader, loss_fn, device):
model = model.eval() # 验证预测模式
losses = []
pred_ls = []
label_ls = []
with torch.no_grad():
for d in data_loader:
input_ids = d["input_ids"].to(device)
attention_mask = d["attention_mask"].to(device)
targets = d["labels"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = loss_fn(outputs, targets)
y_pred_arr = outputs.data.cpu().numpy()
losses.append(loss.item())
pred_ls.extend(preds.tolist())
label_ls.extend(d["labels"])
correct_predictions = accuracy_score(label_ls, pred_ls)
return correct_predictions, np.mean(losses)
(6)预测结果
def model_predictions(model, data_loader, device):
model = model.eval()
result = []
with torch.no_grad():
for d in data_loader:
input_ids = d["input_ids"].to(device)
attention_mask = d["attention_mask"].to(device)
outputs = model(
input_ids=input_ids,
attention_mask=attention_mask
)
y_pred = outputs.data.cpu().numpy()
result.extend(y_pred)
return result
(7)K折划分数据
# K折数据划分
def load_data_kfold(dataset,BATCH_SIZE,MAX_LEN, k, n):
print("Cross validation第{}折正在划分数据集".format(n+1)以上是关于NLP讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert 方案的主要内容,如果未能解决你的问题,请参考以下文章
NLP讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert 方案
NLP讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert 方案
NLP讯飞英文学术论文分类挑战赛Top10开源多方案--2 数据分析
NLP讯飞英文学术论文分类挑战赛Top10开源多方案--2 数据分析