NLP讯飞英文学术论文分类挑战赛Top10开源多方案--1 赛后总结与分析
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP讯飞英文学术论文分类挑战赛Top10开源多方案--1 赛后总结与分析相关的知识,希望对你有一定的参考价值。
1 相关信息
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–1 赛后总结与分析
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–2 数据分析
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–3 TextCNN Fasttext 方案
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–4 机器学习LGB 方案
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert 方案
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–6 提分方案
2 总结
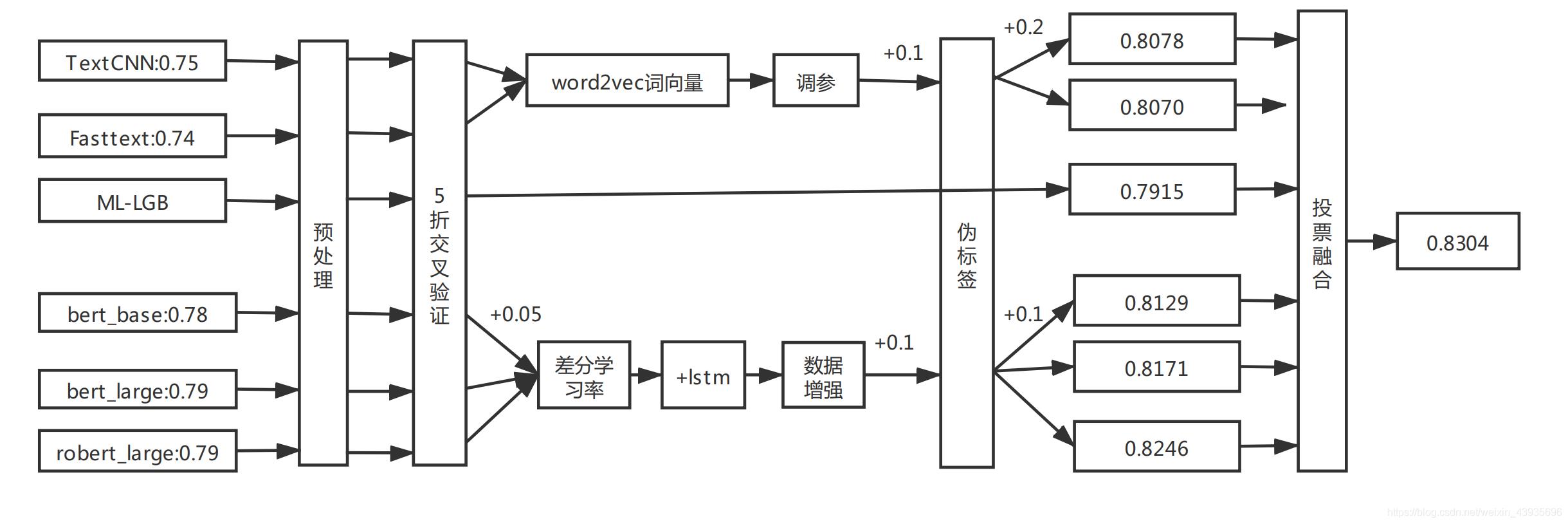
感谢2021年7月的暑假遇到三个志同道合的队友:博远、禹飞、沛恒,互相鼓励,一直出谋划策一个月,最终以0.8304的成绩获得rank 10/389的成绩。
2.1 TextCNN、Fasttext等DL方案
(1)方案
拿到赛题,第一件事,就是做数据分析。可以参考【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–2 数据分析分析
了解到数据量比较小,只有5W,首先选择了TextCNN、FastText算法模型。首先选择非词向量的即词嵌入的模型去跑通baseline,然后再选择word2vec、fasttext、glove等预训练词向量去提分。这些方案最初,都只能拿到最高0.77+的分数,通过后期的数据预处理方式改变、K折交叉验证、预训练词向量调参,伪标签等提分技巧,最终达到0.807+。具体方案参考
【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–3 TextCNN Fasttext方案
(2)提分点
- 数据预处理:词性替换、去除特殊字符、数字泛化、去除多余空格、去除换行等方式,均有提升,具体查看代码实现
- 预训练word2vec、fasttext、glove词向量,通过对比单个word2vec选择128维度,能获得最高的准确率,尝试合并三种向量的矩阵,得到3×128的词向量矩阵,但是效果并没有单个词向量的好。
(3)注意点 - 同样的数据,用DPCNN、TextRNN模型,效果并不佳
- 还有HAN、LSTMwithAttention等模型都还没有尝试
- 尝试了GCN图卷积神经网络,由于该方案中需要使用邻接矩阵,矩阵太大,显存装不下,只使用了部分的训练数据,线上就能到达0.78+的分数,实现没有这么大的显存设备,放弃了该方案。
- 数据增强:随机替换、随机删除做的5W数据以及互译的5W数据,加上原本的5W的数据,分别测试了两种增强方式,都没有得到提升。但是在Bert上提升了一个点。
2.2 机器学习LGB方案
队友尝试了用LGB方案,实现非常简单,交叉5折交叉验证,就能达到0.79的分数,但是我们没有在该方案上进一步改进,仅作为一个基本方案,在比赛的最后的投票融合部分,使用了该模型的预测结果。具体方案可参考
【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–2 机器学习LGB方案
2.3 Bert方案
(1)使用Bert的辛酸
选择Bert是最后的大杀器,我们的最高得分模型就是Bert,有一个致命的缺点就是太吃显卡,费时费钱,不像TextCNN等其他DL模型,十几分钟,半个小时就能跑完。跑通“致great -闫强”大佬开源的bert Baseline方案科大讯飞学术论文分类挑战赛 0.79+ baseline
就花了三个小时,后期我们自己的模型,少则6个小时,多则20个小时,才能出结果。多次出现跑到最后,在生成提交文件的时候出bug或者中途出Bug ,前功尽弃。因为选择的K折交叉验证取每折的平均作为预测值,一旦中断,交叉验证取平均的结果将得不到。
虽然我和其中一名队友有本地服务器,但是我的显存太小,只有8G,吃显存的Bert_large 、roberta_large根本跑不动,我和其他两名队友,就选择了恒源云的云服务器3090的GPU,虽然有活动送了100块钱的代金券,但是三天就用完了,剩下的全是自己烧钱充值,5块钱一个小时的费用,打比赛没赢到钱,反而每个人砸了不少钱。
(2)Bert真香
我尝试自己去github和kaggle上选择高分Bert baseline去跑通模型,但是准确率极低,只有0.65+。一直在分析原因,直到强哥又在直播课上开源了其他方案Bert的baseline,科大讯飞NLP文本分类赛事上分利器:Bert微调技巧大全_闫强,该方案中强哥提到了很多提分技巧,包括使用差分学习率,使用bert_base、bert_large、roberta_large预训练模型、对一篇Bert微调的论文中点进行了解析。特别是包括学习率的设置,如果设置不好,会导致灾难性遗忘,这对我是一个巨大的启发。
灾难性遗忘 Catastrophic forgetting (灾难性遗忘)通常是迁移学习中的常见诟病,这意味着在学习新知识的过程中预先训练的知识会被遗忘。 因此,论文中还研究了 BERT 是否存在灾难性遗忘问题。 我们用不同的学习率对 BERT 进行了微调,发现需要较低的学习率,例如 2e-5,才能使 BERT 克服灾难性遗忘问题。 在 4e-4 的较大学习率下,训练集无法收敛。
尝试修改学习率后,模型直接提升几个点,上了0.70+,但是还是低。最终选择在强哥的第二个bert的baseline上进行迭代。
首先跑通bert_base,使用差分学习率,5折交叉2epoch,训练参数调参就能达到0.795+。
(3)继续提分
- 队友尝试修改模型结构,在bert后面使用一层LSTM,能够提升千分点。
- 用相同的代码,使用不同的预训练模型bert_large,roberta_large,相继获得0.7991,0.80+的结果。
- 选择TextCNN、Fasttext、ML -LGB 、bert_base、bert_large、roberta_large的投票模型融合提高一个点。0.81+
- 数据增强:两种方式,第一种是随机删除、随机替换方式增强5W的训练集、第二种是互译的方式,再做5W的数据。总共15W的数据,再去训练模型。单个模型能提升一个点,bert突破0.81+。
- 利用投票的原理,选择多个模型都投票的数据去做伪标签,得到top 6000的高质量伪标签,加入训练集,重新训练所有模型,所有模型都得到了一个点的提升,又继续投票融合,线上突破0.82
- 此时已经黔驴技穷了,只能继续反复迭代伪标签,用最高的模型又重新做伪标签得到top8000的伪标签数据,再重新训练模型,TextCNN、Fasttext单个模型都突破0.80+,bert_base、bert_large方案都突破0.81+,roberta_large模型最佳达到0.8246,再去投票融合,最终达到最高成绩,0.8304。
(4)Bert 注意点
- Bert的数据预处理,通过对比实验,只选择小写处理和词性替换,更多更细的预处理将会是适得其反的,反而会降低模型的准确率,因为预训练的模型,当初训练时就是预训练的没有经过太细致预处理的数据。可参考【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert方案
- Bert训练太慢了,最后选择了混合精度训练,加快近两倍的训练速度。但是在比赛最后几天才使用的。模型精度没有太大影响。省了不少时间。可参考【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–6 提分方案
- 差分学习率搭配AdamW优化器使用很有必要,能够提高模型精度
- 伪标签的加入,不是随便加入的,越高质量的伪标签,越能得到更好的效果。伪标签加入到训练数据后,不是继续训练,而是从零训练,这样伪标签才能发挥作用。可参考【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–6 提分方案
- 尝试自己使用ITPT方式预训练自己的数据集,最大设置了60epoch,效果并不佳,有两方面的原因,数据集太小,训练集加上测试集只有6W的样本文本,二可能是我们做的方式不对。最终该方案放弃。
- 尝试过将bert_base、bert_large、roberta_large三个模型使用Stacking集成,非正规的Stacking效果有0.8228,并没有投票融合效果好,为什么说非正规,是因为我将三个模型验证集的数据是vstack,而不是hstack。说都了都是泪,因为三个模型训练的时候,把验证集顺序shuffle了,不能去hstack每个样本。如果正确使用,估计能提高更多分数。
3 继续提分点
(1)TextCNN、Fasttext等模型
- 理论上合并word2vec+fasttext+glove三个词向量的矩阵,能提高模型精度,但是本人只尝试过各128维度,并没有提升,就没有过多时间去调参。可以各取100维度,合并成300维的词向量嵌入矩阵。
- 对抗训练:队友使用PGD对抗训练的方法得到提升,但是我测试的时候未得到提升,这是不应该的。还有FGM对抗训练,在我的实验测试并没有得到提升。我也没有进一步去分析原因。
(2)Bert模型
- 调参:bert模型没有经过太多的调参
- 加深训练:选择的5折,2epoch,训练完模型,都没有过拟合,但是训练时间都是十几个小时。如果有更多的时间会选择去加大epoch
- 其他集成方法,Stacking、Bagging等方案,由于我的代码有误,在准备三个Bert模型stacking数据的时候,被shuffle了,只能去vstack三个模型的数据去做非正规的stacking,的确有提升,但是并不如投票融合的话。
- 改进Bert结构:在其他比赛中,有些大佬,使用拼接Bert输出层的bert模型,效果显著。CCF BDCI 2019 互联网新闻情感分析 复赛top1
以上是关于NLP讯飞英文学术论文分类挑战赛Top10开源多方案--1 赛后总结与分析的主要内容,如果未能解决你的问题,请参考以下文章
NLP讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert 方案
NLP讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert 方案
NLP讯飞英文学术论文分类挑战赛Top10开源多方案--2 数据分析
NLP讯飞英文学术论文分类挑战赛Top10开源多方案--2 数据分析