NLP讯飞英文学术论文分类挑战赛Top10开源多方案--2 数据分析
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP讯飞英文学术论文分类挑战赛Top10开源多方案--2 数据分析相关的知识,希望对你有一定的参考价值。
相关信息
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–1 赛后总结与分析
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–2 数据分析
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–3 TextCNN Fasttext 方案
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–4 机器学习LGB 方案
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert 方案
- 【NLP】讯飞英文学术论文分类挑战赛Top10开源多方案–6 提分方案
1 赛题
- 本次赛题希望参赛选手利用论文信息:论文id、标题、摘要,划分论文具体类别。
赛题样例(使用\\t分隔):
paperid:9821
title:Calculation of prompt diphoton production cross sections at Tevatron and LHC energies
abstract:A fully differential calculation in perturbative quantum chromodynamics is presented for the production of massive photon pairs at hadron colliders. All next-to-leading order perturbative contributions from quark-antiquark, gluon-(anti)quark, and gluon-gluon subprocesses are included, as well as all-orders resummation of initial-state gluon radiation valid at next-to-next-to-leading logarithmic accuracy.
categories:hep-ph - 评估指标
本次竞赛的评价标准采用准确率指标,最高分为1。计算方法参考https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html, 评估代码参考
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
accuracy_score(y_true, y_pred)
2 数据分析
2.1 加载数据
import re
import numpy as np
import pandas as pd
train = pd.read_csv('./data/train.csv', sep='\\t')
test = pd.read_csv('./data/test.csv', sep='\\t')
sub = pd.read_csv('./data/sample_submit.csv')
# 查看前5行数据
train.head(5)

分别有四个属性,paperid、titile、abstract、categories
# 数据大小
train.shape,test.shape,sub.shape
#((50000, 4), (10000, 3), (10000, 2))
2.2 查看缺失值
# 查看训练集缺失值
train.isnull().sum()
# 查看测试集缺失值
test.isnull().sum()
# 查看训练集数据信息
train.info()
# 查看测试集数据信息
test.info()
paperid 0
title 0
abstract 0
categories 0
dtype: int64
paperid 0
title 0
abstract 0
dtype: int64
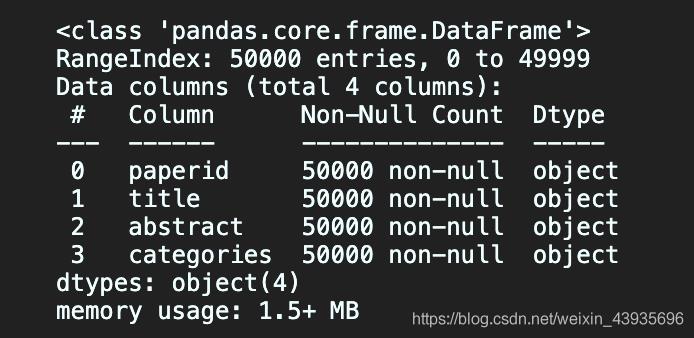
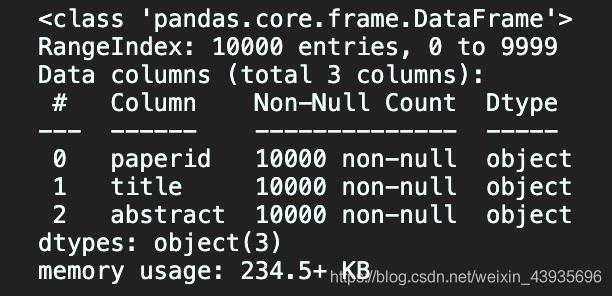
# 查看数据集中间有无空行
print("train null nums")
print(train.shape[0]-train.count())
print("test null nums")
print(test.shape[0]-test.count())
无缺失值,无空行,训练集有5W行,测试集有1W行
2.3 标签分布
train['categories'].value_counts()
# # 标签类别数 39
len(train['categories'].value_counts())
# 绘制直方图
sns.countplot(train.categories)
plt.xlabel('categories count')
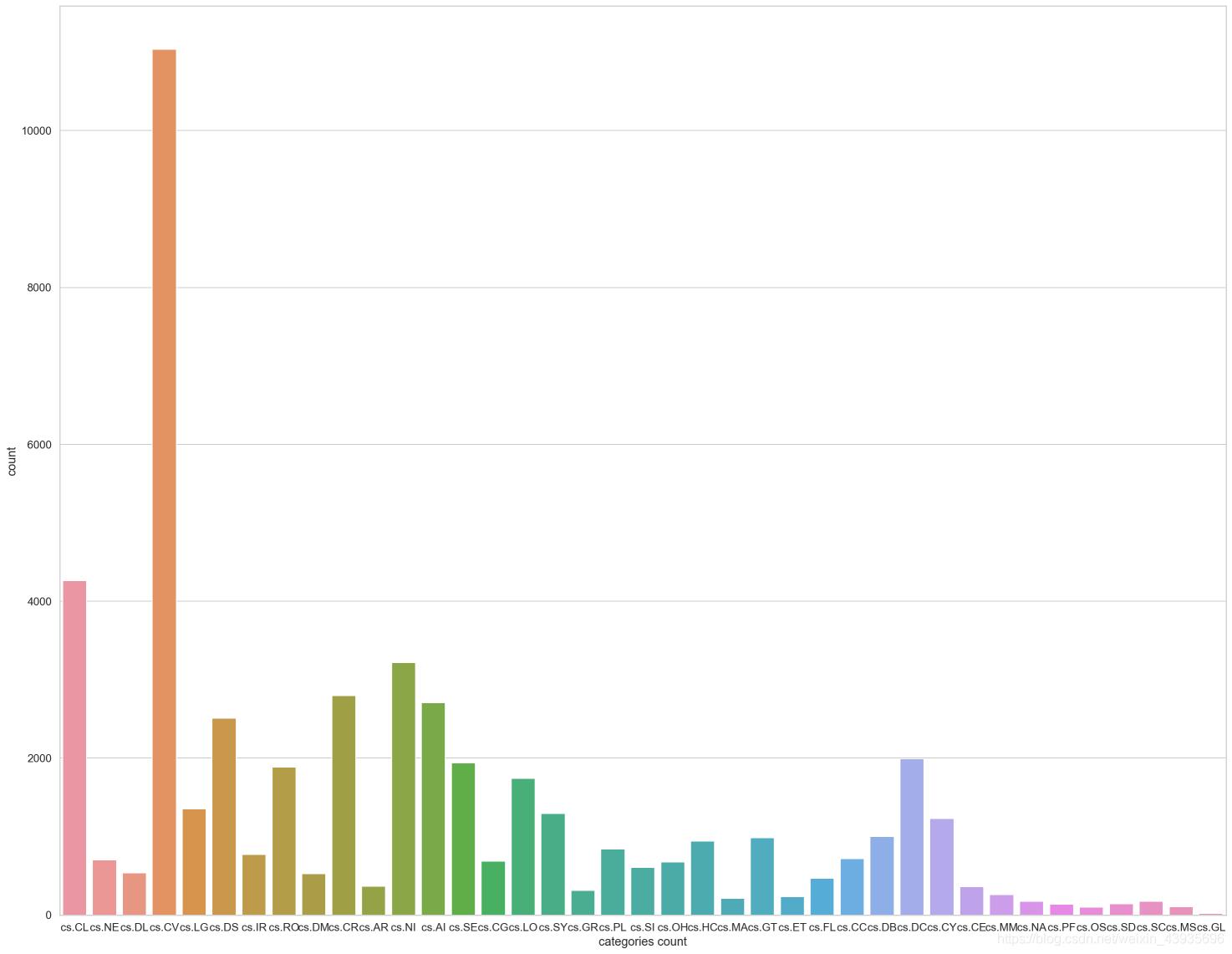
大类别只有CS一种,子类别有39类。数据分布不均衡
2.4 文本长度
# 训练集
titlelen1 = []
abstractlen1 = []
for i in range(len(train)):
titletext = train['title'][i]
abstracttext = train['abstract'][i]
titlelen1.append(len(tokenizer.tokenize(titletext)))
abstractlen1.append(len(tokenizer.tokenize(abstracttext)))
train['titlelen'] = titlelen1
train['abstractlen'] = abstractlen1
x1 = train['titlelen'].describe()
x2 = train['abstractlen'].describe()
# 测试集
titlelen2 = []
abstractlen2 = []
for i in range(len(test)):
titletext = test['title'][i]
abstracttext = test['abstract'][i]
titlelen2.append(len(tokenizer.tokenize(titletext)))
abstractlen2.append(len(tokenizer.tokenize(abstracttext)))
test['titlelen'] = titlelen2
test['abstractlen'] = abstractlen2
x3 = test['titlelen'].describe()
x4 = test['abstractlen'].describe()
训练集
count 50000.00000
mean 10.60276
std 4.06394
min 1.00000
25% 8.00000
50% 10.00000
75% 13.00000
max 44.00000
Name: titlelen, dtype: float64
测试集
count 50000.00000
mean 186.88670
std 71.31268
min 5.00000
25% 137.00000
50% 182.00000
75% 231.00000
max 629.00000
Name: abstractlen, dtype: float64
训练集标题平均10个单词,摘要平均186个单词
测试集标题平均10个单词,测试集摘要平均186个单词
2.5 标题摘要合并后字符长度
train['text_len']=train['text'].map(len)
test['text_len']=test['text'].map(len)
train['text'].map(len).describe()
test['text'].map(len).describe()
# 绘制句子长度分布图
train['text_len'].plot(kind='kde')
test['text_len'].plot(kind='kde')
count 50000.00000
mean 1131.28478
std 387.14365
min 69.00000
25% 860.00000
50% 1117.00000
75% 1393.00000
max 3713.00000
Name: text, dtype: float64
count 10000.000000
mean 1127.097700
std 388.662603
min 74.000000
25% 855.750000
50% 1111.000000
75% 1385.250000
max 3501.000000
Name: text, dtype: float64

每个样本文本单词长度200左右,字符平均长度1000左右。理论上单词数小于200的成为短文本,这里可以当成短文本去处理,高于200的进行截断。
对比两张图,训练集和测试集长度分布一致。
3 总结
(1)数据可视为短文本数据
(2)赛题属于多分类单标签问题,39类,类别分布不均衡,数据为英文文本
(3)文本有title和abstract两部分,平均长度为10和185
(4)数据量较小,只有5W
(5)训练集测试集数据分布一致
(6)赛题奖金太少,但学习作用很大
以上是关于NLP讯飞英文学术论文分类挑战赛Top10开源多方案--2 数据分析的主要内容,如果未能解决你的问题,请参考以下文章
NLP讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert 方案
NLP讯飞英文学术论文分类挑战赛Top10开源多方案–5 Bert 方案
NLP讯飞英文学术论文分类挑战赛Top10开源多方案--2 数据分析
NLP讯飞英文学术论文分类挑战赛Top10开源多方案--2 数据分析