翻译:生产中的机器学习:为什么你应该关心数据和概念漂移
Posted 架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了翻译:生产中的机器学习:为什么你应该关心数据和概念漂移相关的知识,希望对你有一定的参考价值。
没有模型可以永远持续下去。即使数据质量很好,模型本身也会开始退化。这在实践中意味着什么?
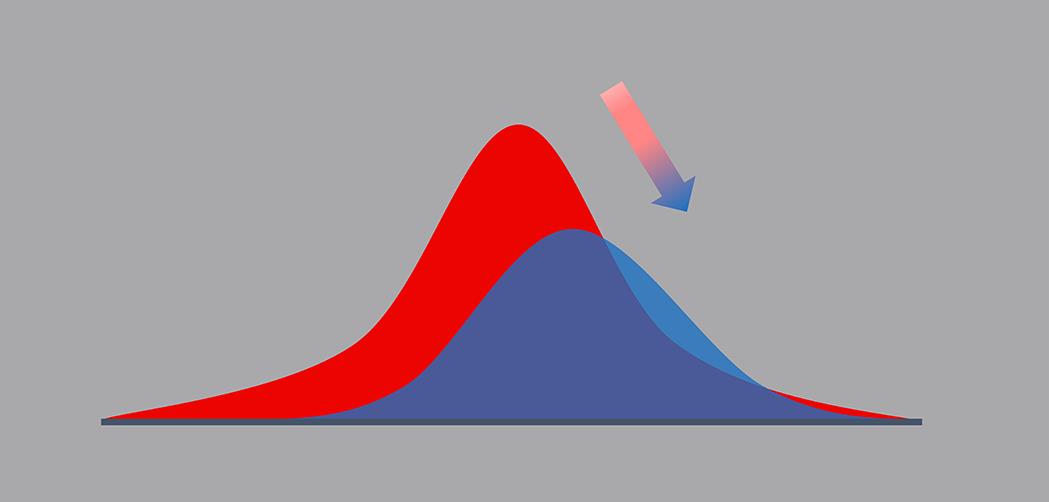
1. 会出什么问题?
机器学习模型经常处理损坏、延迟或不完整的数据。数据质量问题占生产故障的主要部分。
但假设它被覆盖了。数据工程团队做得很好,数据所有者和生产者没有受到伤害,也没有系统崩溃。这是否意味着我们的模型是安全的?
可悲的是,这从来都不是给定的。虽然数据可能是正确的,但模型本身可能会开始退化。
在此上下文中使用了一些术语。让我们潜入。
2. 模型衰减
过去的表现并不能保证将来的结果。— 大多数金融产品的小字体。
人们称之为模型漂移、衰退或陈旧。
事情Ç ^ h安格,并随着时间的推移模型性能下降。最终的衡量标准是模型质量指标。可以是准确率、平均错误率,也可以是一些下游业务KPI,比如点击率。
没有模型永远存在,但衰减的速度各不相同。
某些型号可以持续数年而无需更新。例如,某些计算机视觉或语言模型。或者在孤立、稳定的环境中的任何决策系统。
其他人可能需要每天对新数据进行再培训。
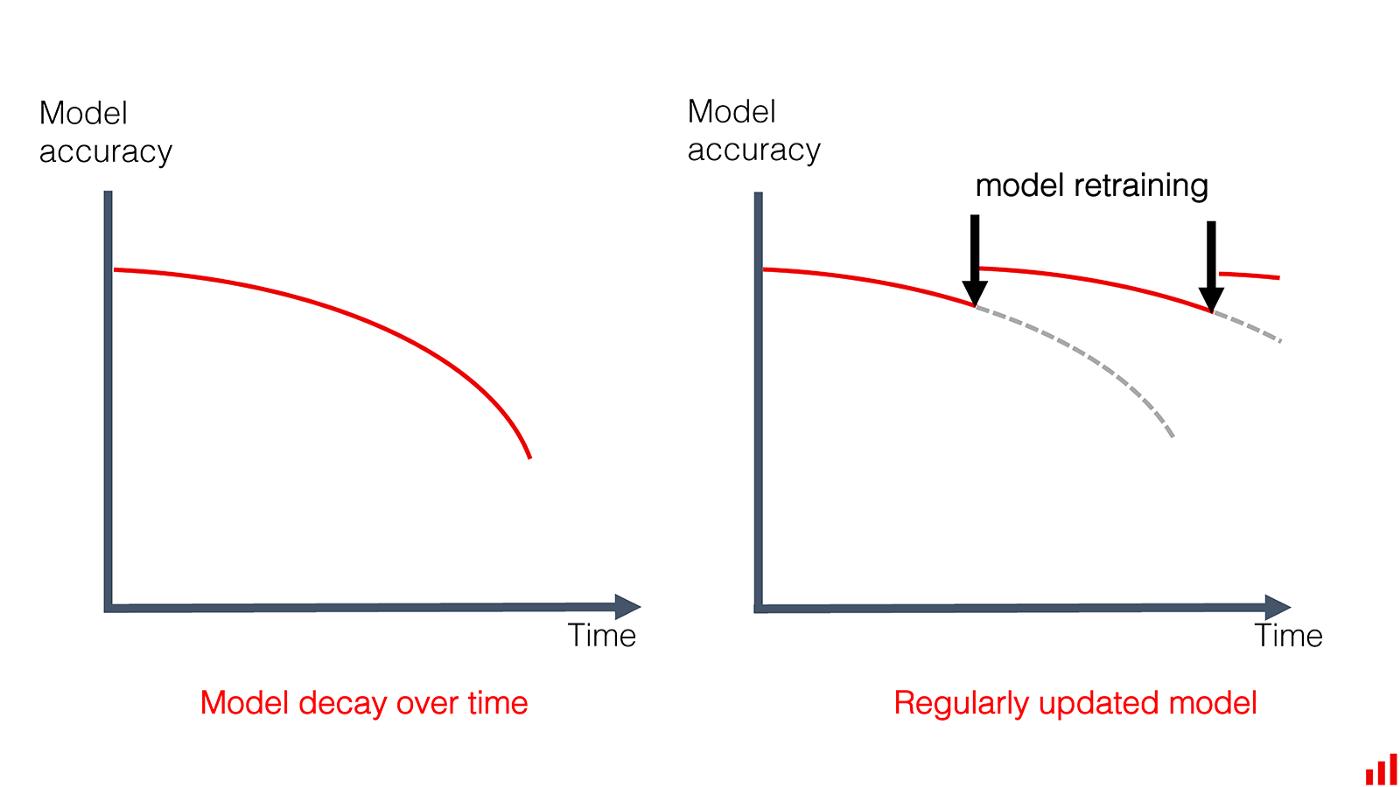
模型衰减是一个术语,字面意思是模型变得更糟。但当然,这是有原因的。
当数据质量良好时,通常有两个疑点:数据漂移或概念漂移data drift or concept drift。或者两者同时进行。
和我们一起承担。我们现在解释一下。
3. 数据漂移data drift
数据漂移、特征漂移、总体或协变量漂移。相当多的名称来描述本质上相同的事物。
即:输入数据已更改。变量的分布是有意义的不同。因此,经过训练的模型与这些新数据无关。
它仍然会在与“旧”数据相似的数据上表现良好!模型很好,就像“真空中”的模型一样。但实际上,由于我们正在处理一个新的特征空间,它变得非常有用。
这是一个倾向建模的例子。
在线市场通过广告吸引用户。新人注册后不久,我们希望预测他们购买的可能性,以便向他们发送个性化优惠。
以前,大多数用户获取都是通过付费搜索进行的。在一个新的广告活动之后,很多用户都来自 Facebook。在训练中,我们的机器学习模型在这部分表现不佳。它只有有限的例子可供学习。
尽管如此,整体模型质量还是足够的,因为这个子群很小。现在它增长了,可以预见,性能下降了。
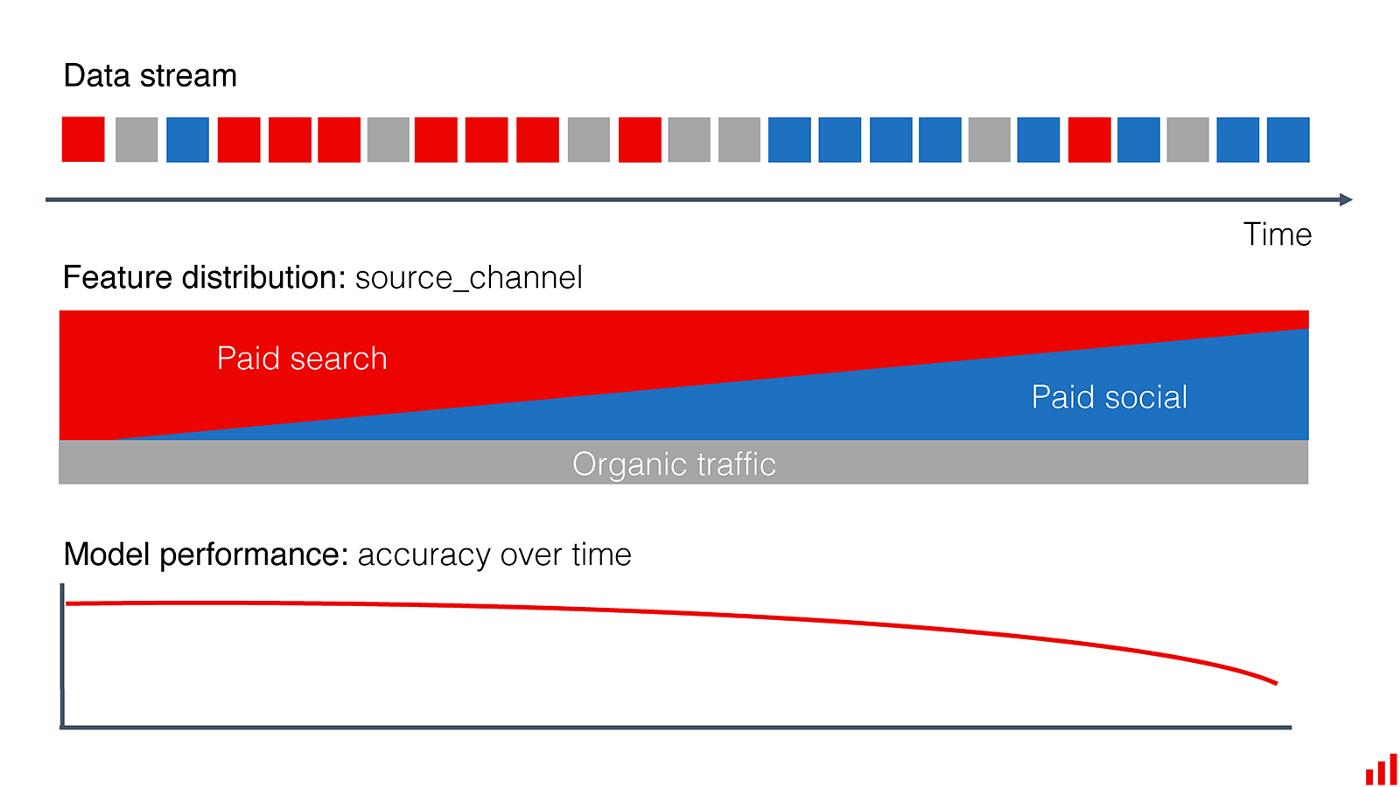
随着越来越多的用户来自社交渠道,模型性能下降。(作者图片)。
在调试时,我们会看到“source_channel”中类频率的变化以及其他相关变量的分布,例如“device”、“region”等。
在新的地理区域中应用模型时会发生类似的事情。或者,如果不断增长的受众开始包括新的人口统计细分,等等。
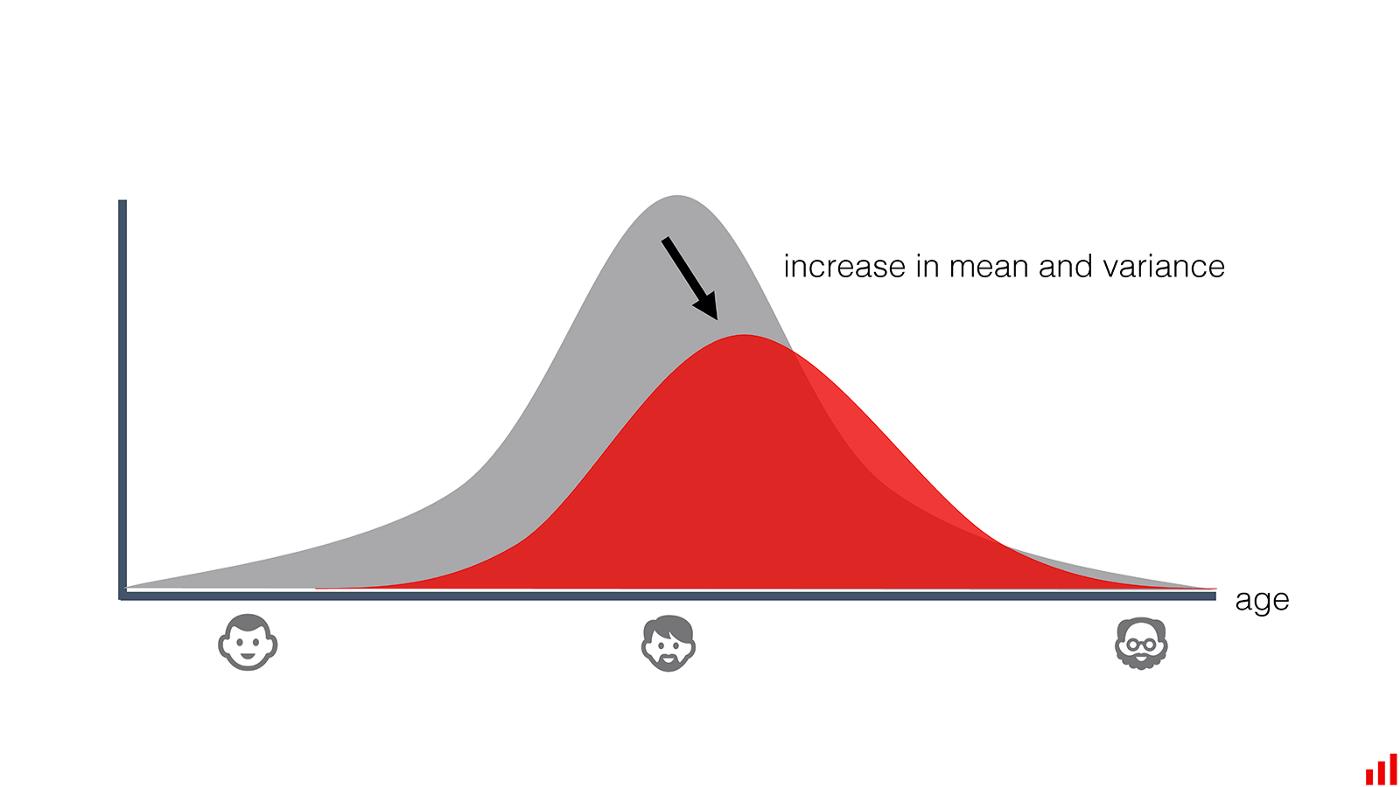
“年龄”特征分布的变化。(作者图片)。
在这些示例中,现实世界的模式可以保持不变。但是模型的性能会随着不同数据区域的质量而有所下降。
衰减的范围可以从轻微到剧烈——当漂移影响最重要的特征时。
为了解决这个问题,我们需要在新数据上训练模型或为新段重建模型。
4. 训练服务偏斜
这个值得一提。
它通常与数据漂移混合使用或互换使用。我们分析它们的方式可能确实相似,但产生偏差的根本原因并不相同。
在这种情况下,不存在“漂移”,它假设在模型的生产使用过程中发生了变化。训练服务偏斜更像是一种不匹配。它在第一次尝试将模型应用于真实数据时揭示了这一点。
当您在人工构建或清理的数据集上训练模型时,经常会发生这种情况。这些数据不一定代表真实世界,或者不完全代表真实世界。
例如,发票分类模型是在一组有限的众包图像上训练的。它在测试集上表现良好。但是一旦投入生产,人们对发票数据填写方式的多样性感到惊讶。或者与模型训练相比,扫描图像的质量较低。

训练服务偏斜。(作者图片)。
最近,Google Health 团队也遇到了类似的问题。他们开发了一种计算机视觉模型,用于从眼部扫描图像中检测视网膜病变的迹象。实际上,这些通常是在光线不足的情况下拍摄的。该模型在现实生活中的表现与在实验室中一样好。
在大多数训练服务倾斜的情况下,模型开发必须继续。如果幸运的话,不成功的试运行可能会生成足够的数据来训练新模型或调整现有模型。否则,您可能需要先收集并标记新数据集。
5. 概念漂移concept drift
当模型学习的模式不再成立时,就会发生概念漂移。
与数据漂移相反,分布(例如用户人口统计、词频等)甚至可能保持不变。相反,模型输入和输出之间的关系发生了变化。
从本质上讲,我们试图预测的东西的意义正在演变。根据比例,这将使模型不太准确甚至过时。
概念漂移有不同的风格。
5.1 渐进的概念漂移

渐进式或增量式漂移是我们所期望的。
世界在变,模型在变老。它的质量下降是随着外部因素的逐渐变化而发生的。
一些例子:
- 竞争对手推出新产品。消费者有了更多的选择,他们的行为也会发生变化。销售预测模型也应该如此。
- 宏观经济条件不断变化。由于一些借款人拖欠贷款,信用风险被重新定义。评分模型需要学习它。
- 设备的机械磨损。在相同的工艺参数下,图案现在略有不同。它影响制造中的质量预测模型。
没有任何个人变化是戏剧性的。每个可能只影响一小部分。但最终,它们加起来。
有时可以观察到单个特征水平的变化。
这就是它在二元分类任务中的样子,比如流失预测。特定特征的分布是稳定的。但目标类别在特定值范围内的份额会随着时间的推移而增长。出现新的预测模式。但这只是一个特性:对模型性能的初始影响是温和的。
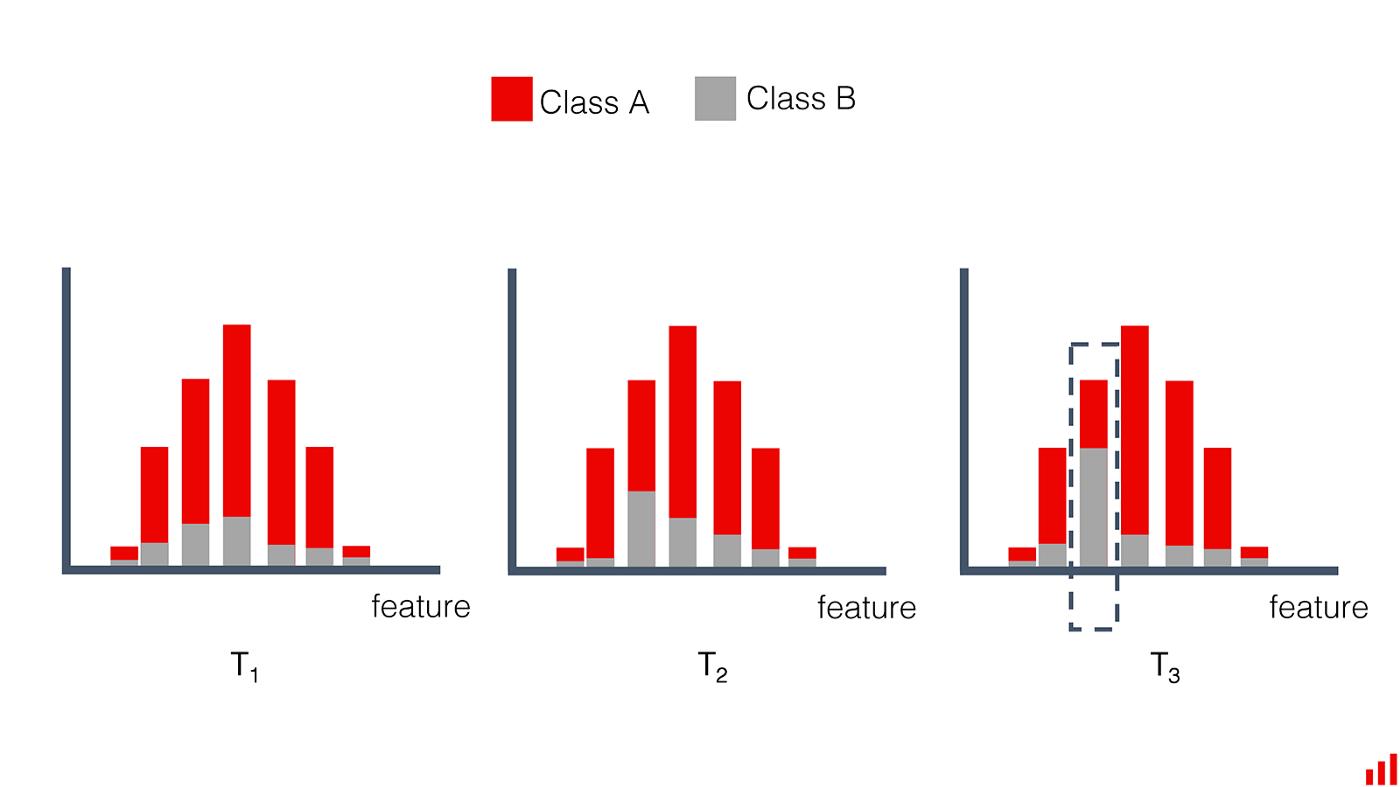
给定特征与预测目标之间关系的变化。(作者图片)。
模特的年龄有多快?
当然,这取决于。但通常可以提前获得估算值。
如果我们正在构建一个有监督的预测模型,我们就会知道过去的真实情况。我们可以在较旧的数据上训练模型并将其应用于后期。然后我们可以模拟不同频率的模型再训练,并测量它如何影响模型质量。
这样的测试为我们提供了常规模型再培训需求的良好代理。每个新周的数据是否会提高性能?或者一个 3 个月大的模型仍然表现得和新的一样好?
然后,我们可以在选定的时间间隔内对新积累的数据安排模型更新。
我们在单独的博客中描述了可以运行的更多检查来决定再培训计划。
5.2 突然的概念漂移
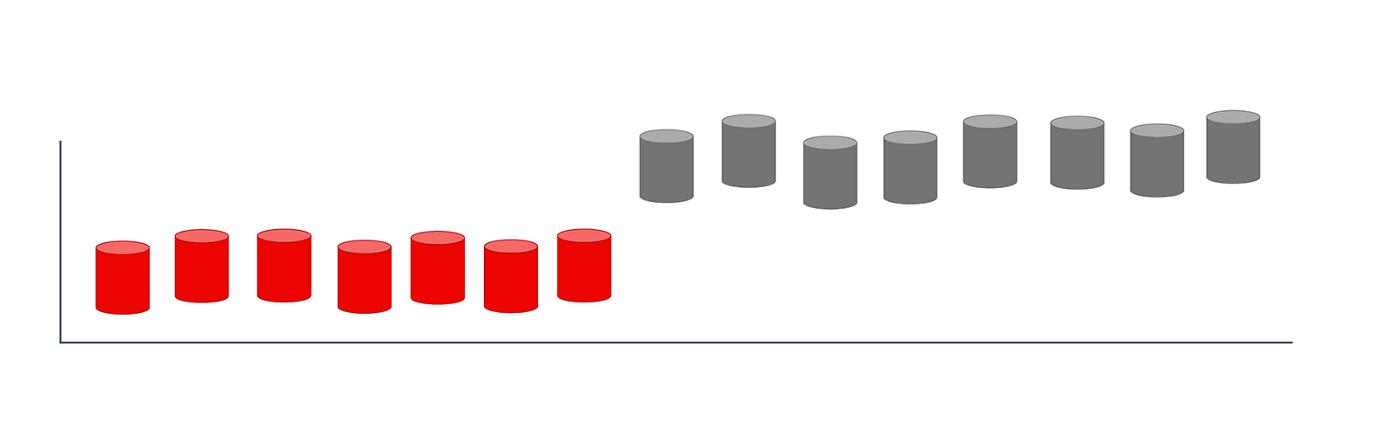
外部变化可能更突然或更剧烈。这些很难错过。正如我们在最近的帖子中分享的那样,COVID-19 大流行就是一个完美的例子。
几乎在一夜之间,流动性和购物模式发生了变化。它影响了各种模型,甚至“稳定”的模型。
需求预测模型不会猜测瑜伽裤的销量会猛增 350%(就像Stitch Fix 发生的那样)或者大多数航班会随着边境关闭而取消。
您是否正在努力识别 X 射线图像上的肺炎?您立即获得了一个新标签。

这种突然的变化并不总是需要大流行或股市崩盘。
在更普通的事件过程中,您可以体验到以下情况:
- 中央银行的利率变化。所有金融和投资行为都会受到影响,模型无法适应看不见的模式。
- 生产线技术改造。由于修改后的设备具有新的故障模式(或缺乏这些模式),预测性维护变得过时。
- 应用程序界面的重大更新。过去的点击和转化数据变得无关紧要,因为用户旅程是新的。
6. 处理漂移

在发生根本性转变的情况下,模型会崩溃。与此同时,不太相关的模型可能需要人工帮助。您可能希望暂停它,直到收集到更多数据。作为后备策略,您可以使用专家规则或启发式方法。
为了回到正轨,我们需要重新训练模型。方法各不相同:
- 使用更改前后的所有可用数据重新训练模型。
- 使用一切,但为新数据分配更高的权重,以便模型优先考虑最近的模式。
- 如果收集到足够多的新数据,我们可以简单地放弃过去。
“幼稚”的再培训并不总是足够的。如果问题发生了变化,我们可能需要调整模型,而不是将最新数据输入到现有数据中。
选项包括域适应策略、构建使用旧数据和新数据的模型组合、添加新数据源或尝试全新的架构。
有时最好修改模型范围或业务流程。它可以缩短预测范围或更频繁地运行模型。例如,面临购物习惯转变的零售商可能会从每周需求预测转换为每日需求预测。
沟通也很重要。与界面更新一样,更改可以来自业务内部。在这里,您需要使业务所有者和模型维护者保持一致。早期警告将帮助您为新的冷启动准备模型。
7. 反复出现的概念漂移
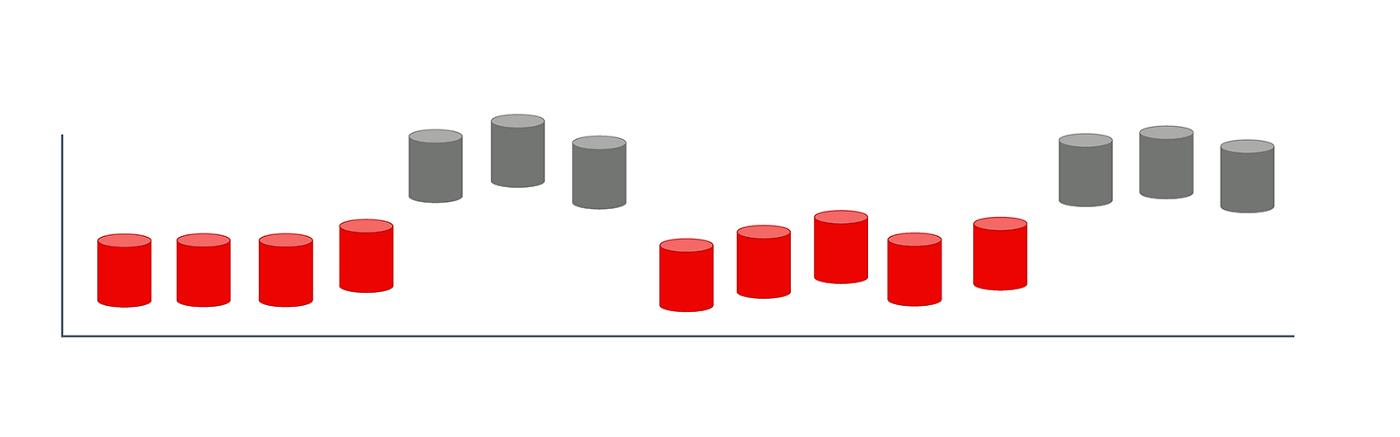
更值得一提的是。
一些研究人员使用术语“重复性漂移”来描述重复的变化。我们觉得这里的事情有点混乱。
季节性是已知的建模概念。它确实看起来(并且是)目标函数的临时更改。
那些在一年中适度购物的人在黑色星期五表现出不寻常的模式。银行假期影响一切,从零售销售到生产故障。周末的流动性与工作日不同。等等。
如果我们有一个声音模型,它应该对这些模式做出反应。每个黑色星期五都类似于一年前的那个。我们可以在系统设计或构建集成模型中考虑循环变化和特殊事件。“经常性漂移”是可以预料的,不会导致质量下降。
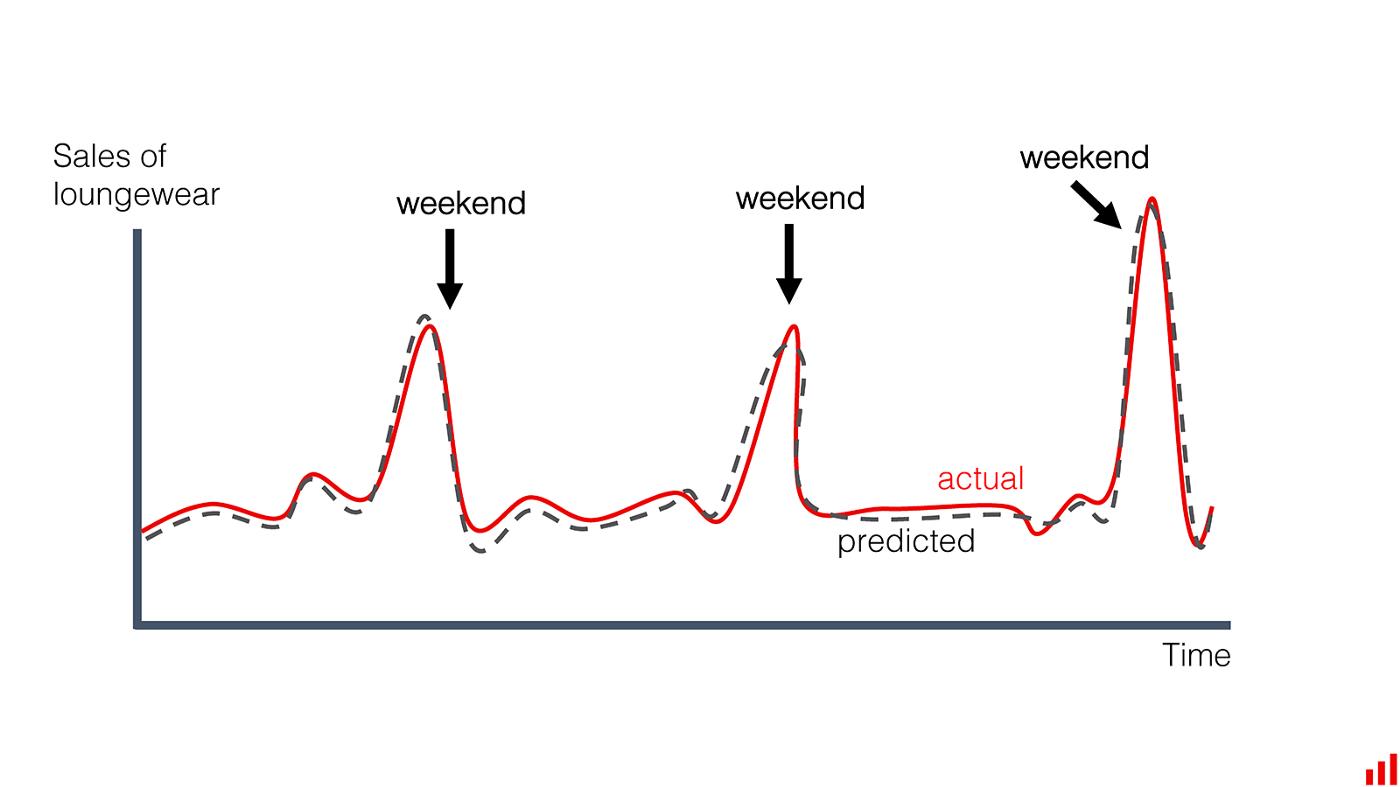
消费者在周末购物更多。模式是已知的,模型预测显示了它。(作者图片)。
从模型监控的角度来看,这种“漂移”并不重要。每周都有周末,我们不需要警报。当然,除非我们看到新的模式。
8. 如何在生产中处理这种不完全漂移?
教你的模型季节性。
如果它首先在制作中看到一些特殊事件或季节,您可以使用其他类似事件作为示例。例如,如果引入了一个新的银行假期,您可以假设与已知的相似。
如果需要,领域专家可以帮助在模型输出之上添加手动后处理规则或校正系数。
9. 漂移回顾
让我们总结一下。
所有模型都会降级。有时,性能下降是由于数据质量低、管道损坏或技术错误。
如果没有,您还有两个赌注:
- 数据漂移:数据分布的变化。
该模型在未知数据区域上表现更差。 - 概念漂移:关系的变化。
世界已经改变,模型需要更新。它可以是渐进的(预期的)、突然的(你明白的)和反复出现的(季节性的)。
在实践中,语义上的区别几乎没有区别。通常情况下,漂移会结合在一起并且很微妙。
重要的是它如何影响模型性能,如果重新训练是合理的,以及如何及时捕捉到这一点。
这个怎么分析?浏览教程“如何在 20 天内破坏模型”中的应用示例,并在 GitHub 上查看我们用于模型分析的开源工具。
参考
https://towardsdatascience.com/machine-learning-in-production-why-you-should-care-about-data-and-concept-drift-d96d0bc907fb
以上是关于翻译:生产中的机器学习:为什么你应该关心数据和概念漂移的主要内容,如果未能解决你的问题,请参考以下文章
独家 | 手把手教你如何使用Flask轻松部署机器学习模型(附代码&链接)