独家 | 手把手教你如何使用Flask轻松部署机器学习模型(附代码&链接)
Posted 数据派THU
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了独家 | 手把手教你如何使用Flask轻松部署机器学习模型(附代码&链接)相关的知识,希望对你有一定的参考价值。
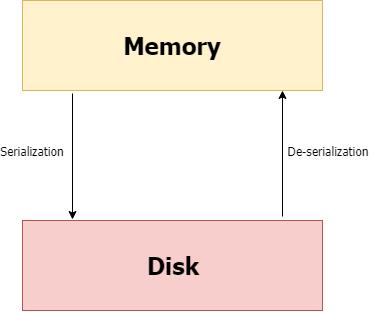
本文可以让你把训练好的机器学习模型使用Flask API 投入生产环境。
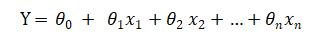

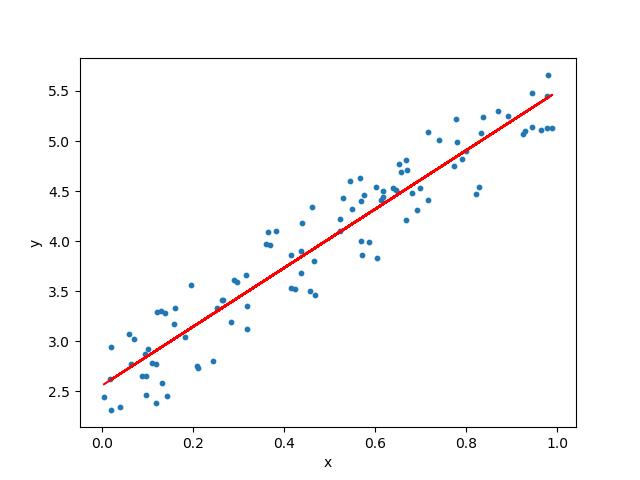
容易上手使用
内置开发工具和调试工具
集成单元测试功能
平稳的请求调度
详尽的文档
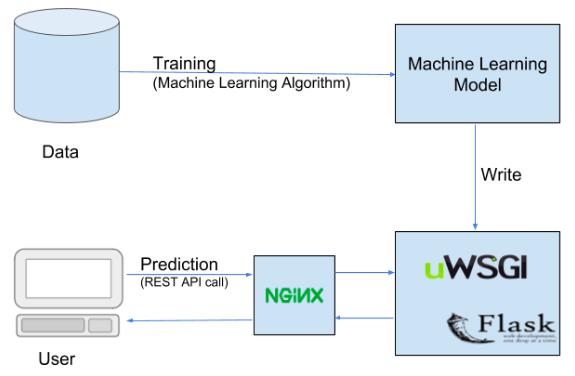
代码在哪里呢?
<!DOCTYPE html><html ><head><meta charset="UTF-8"><title>Deployment Tutorial 1</title><link href='https://fonts.googleapis.com/css?family=Pacifico' rel='stylesheet' type='text/css'><link href='https://fonts.googleapis.com/css?family=Arimo' rel='stylesheet' type='text/css'><link href='https://fonts.googleapis.com/css?family=Hind:300' rel='stylesheet' type='text/css'><link href='https://fonts.googleapis.com/css?family=Open+Sans+Condensed:300' rel='stylesheet' type='text/css'><link rel="stylesheet" href="{{ url_for('static', filename='css/style.css') }}"></head><body style="background: #000;"><div><h1>Sales Forecasting</h1><!-- Main Input For Receiving Query to our ML --><form action="{{ url_for('predict')}}"method="post"><input type="text" name="rate" placeholder="rate" required="required" /><input type="text" name="sales in first month" placeholder="sales in first month" required="required" /><input type="text" name="sales in second month" placeholder="sales in second month" required="required" /><button type="submit" class="btn btn-primary btn-block btn-large">Predict sales in third month</button></form><br><br> {{ prediction_text }}</div></body></html>
接下来,使用CSS对输入按钮、登录按钮和背景进行了一些样式设置。
@import url(https://fonts.googleapis.com/css?family=Open+Sans);html { width: 100%; height:100%; overflow:hidden;}body {width: 100%;height:100%;font-family: 'Helvetica';background: #000;color: #fff;font-size: 24px;text-align:center;letter-spacing:1.4px;}.login {position: absolute;top: 40%;left: 50%;margin: -150px 0 0 -150px;width:400px;height:400px;}
login h1 { color: #fff;text-shadow: 0 0 10px rgba(0,0,0,0.3);letter-spacing:1px;text-align:center;}input {width: 100%;margin-bottom: 10px;background: rgba(0,0,0,0.3);border: none;outline: none;padding: 10px;font-size: 13px;color: #fff;text-shadow: 1px 1px 1px rgba(0,0,0,0.3);border: 1px solid rgba(0,0,0,0.3);border-radius: 4px;box-shadow: inset 0 -5px 45px rgba(100,100,100,0.2), 0 1px 1px rgba(255,255,255,0.2);-webkit-transition: box-shadow .5s ease;-moz-transition: box-shadow .5s ease;-o-transition: box-shadow .5s ease;-ms-transition: box-shadow .5s ease;transition: box-shadow .5s ease;}
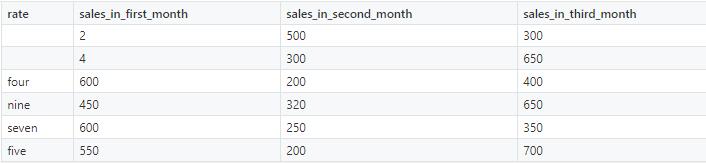
import numpy as npimport matplotlib.pyplot as pltimport pandas as pdimport pickledataset = pd.read_csv('sales.csv')dataset['rate'].fillna(0, inplace=True)dataset['sales_in_first_month'].fillna(dataset['sales_in_first_month'].mean(), inplace=True)X = dataset.iloc[:, :3]def convert_to_int(word):word_dict = {'one':1, 'two':2, 'three':3, 'four':4, 'five':5, 'six':6, 'seven':7, 'eight':8,'nine':9, 'ten':10, 'eleven':11, 'twelve':12, 'zero':0, 0: 0}return word_dict[word]X['rate'] = X['rate'].apply(lambda x : convert_to_int(x))y = dataset.iloc[:, -1]from sklearn.linear_model import LinearRegressionregressor = LinearRegression()regressor.fit(X, y)pickle.dump(regressor, open('model.pkl','wb'))model = pickle.load(open('model.pkl','rb'))print(model.predict([[4, 300, 500]]))
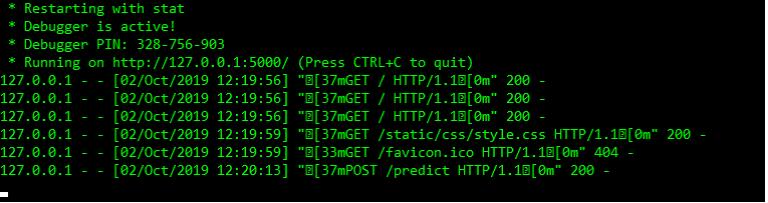
import numpy as npfrom flask import Flask, request, jsonify, render_templateimport pickleapp = Flask(__name__)model = pickle.load(open('model.pkl', 'rb'))@app.route('/')def home():return render_template('index.html')@app.route('/predict',methods=['POST'])def predict():int_features = [int(x) for x in request.form.values()]final_features = [np.array(int_features)]prediction = model.predict(final_features)output = round(prediction[0], 2)return render_template('index.html', prediction_text='Sales shouldbe $ {}'.format(output))@app.route('/results',methods=['POST'])def results():data = request.get_json(force=True)prediction = model.predict([np.array(list(data.values()))])output = prediction[0]return jsonify(output)if __name__ == "__main__":app.run(debug=True)
import requestsurl = 'http://localhost:5000/results'r = requests.post(url,json={'rate':5,'sales_in_first_month':200, 'sales_in_second_month':400})print(r.json()) Results
编辑:王菁
校对:王欣
译者简介

和中华,留德软件工程硕士。由于对机器学习感兴趣,硕士论文选择了利用遗传算法思想改进传统kmeans。目前在杭州进行大数据相关实践。加入数据派THU希望为IT同行们尽自己一份绵薄之力,也希望结交许多志趣相投的小伙伴。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织
以上是关于独家 | 手把手教你如何使用Flask轻松部署机器学习模型(附代码&链接)的主要内容,如果未能解决你的问题,请参考以下文章
手把手教你用 Flask,Docker 和 Kubernetes 部署Python机器学习模型(附代码)
手把手教你用 Python 和 Flask 创建REST API