分布式机器学习如何用于大模型?
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式机器学习如何用于大模型?相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :专知

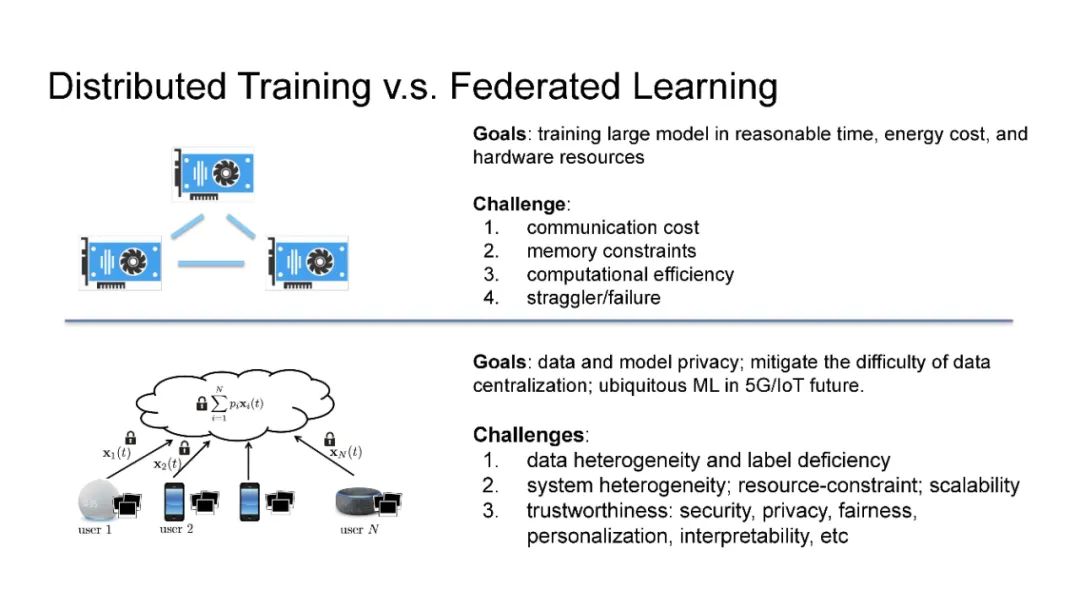
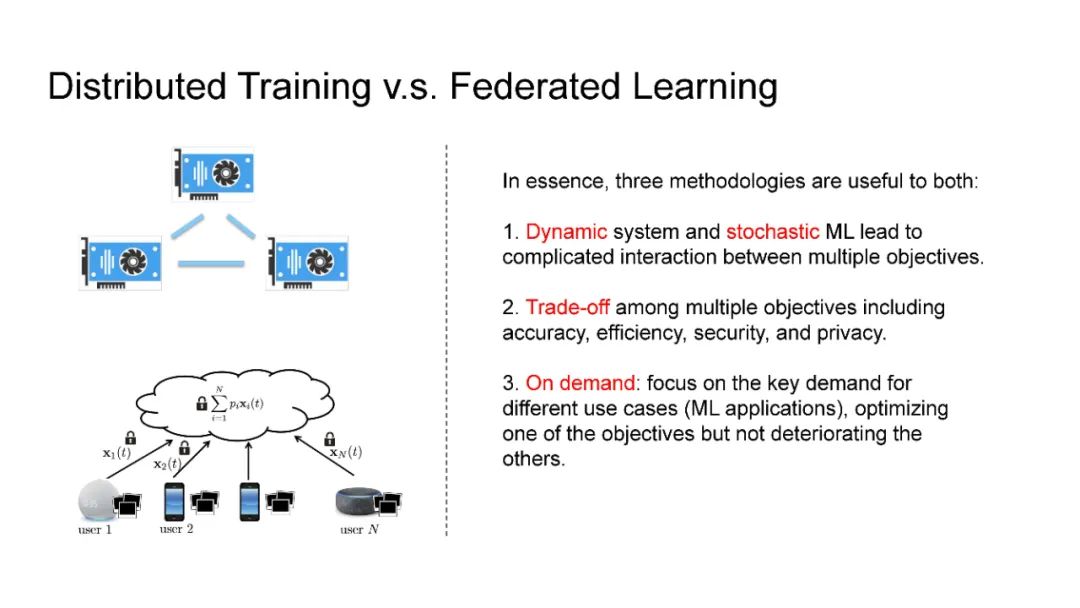
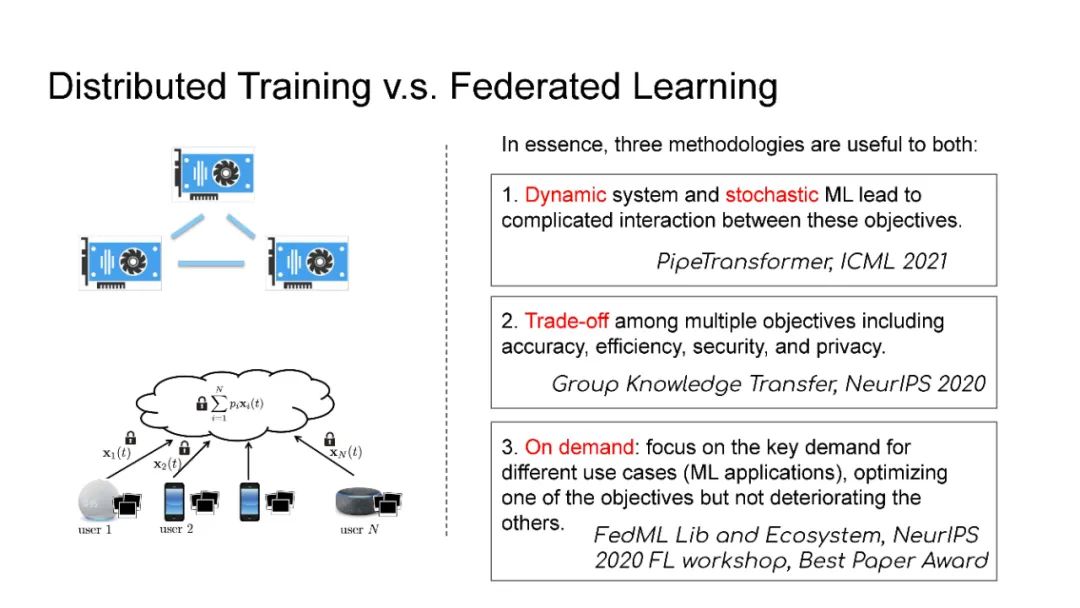
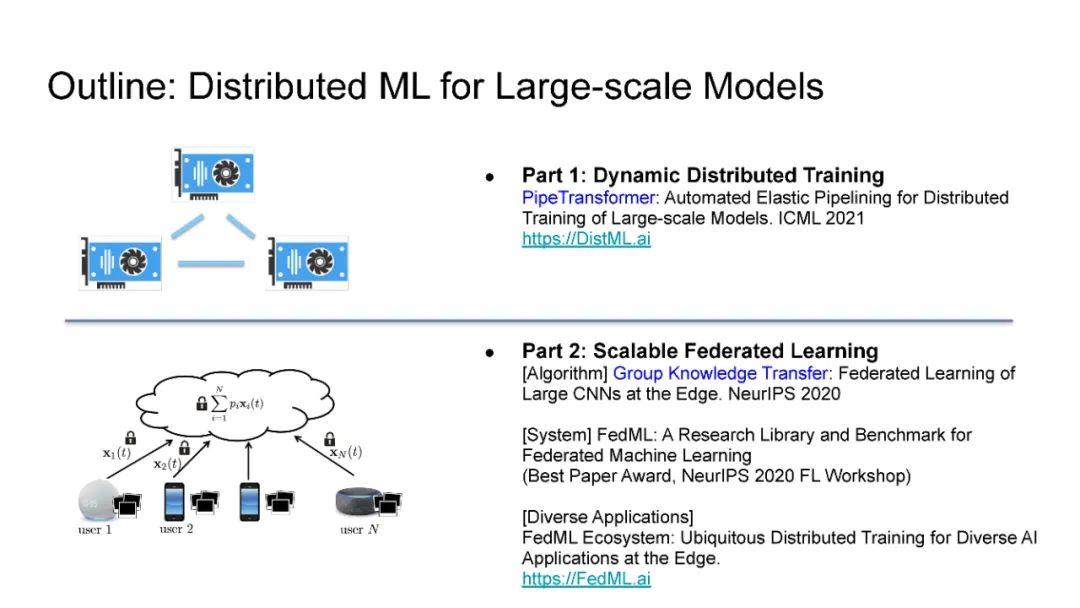
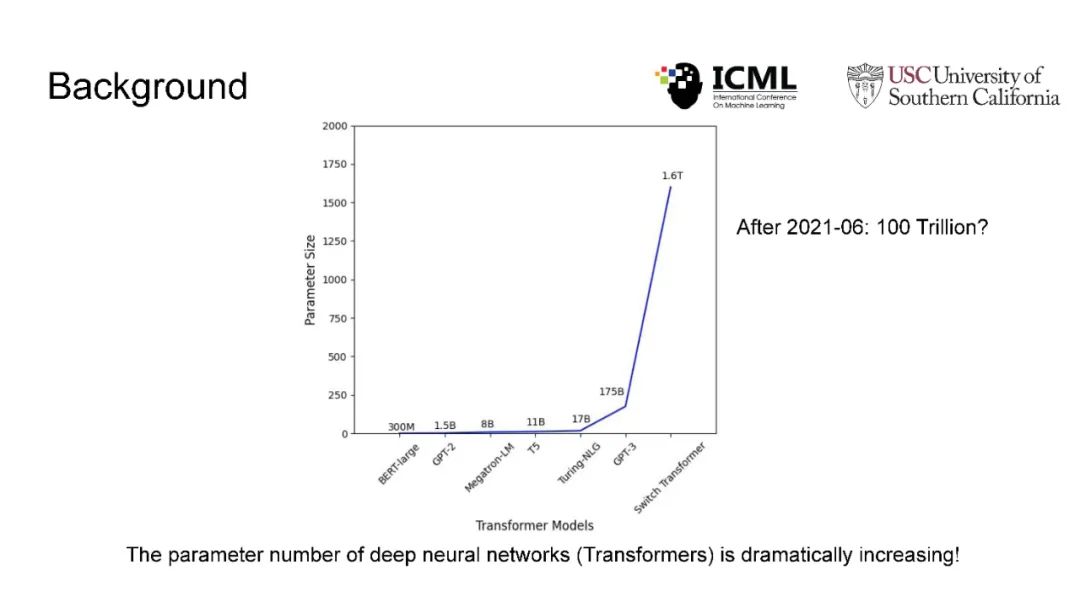
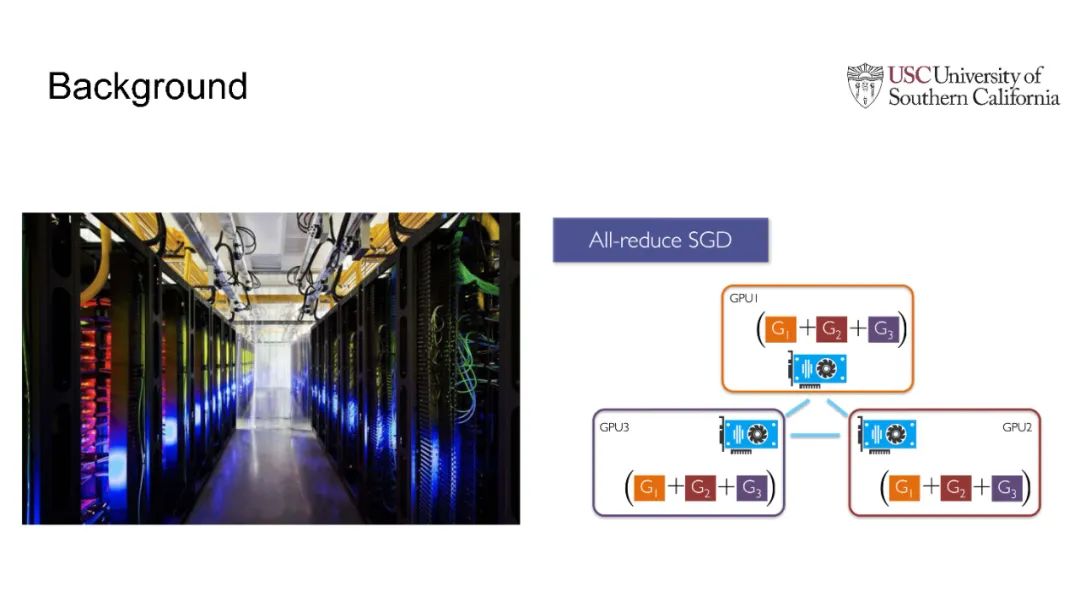
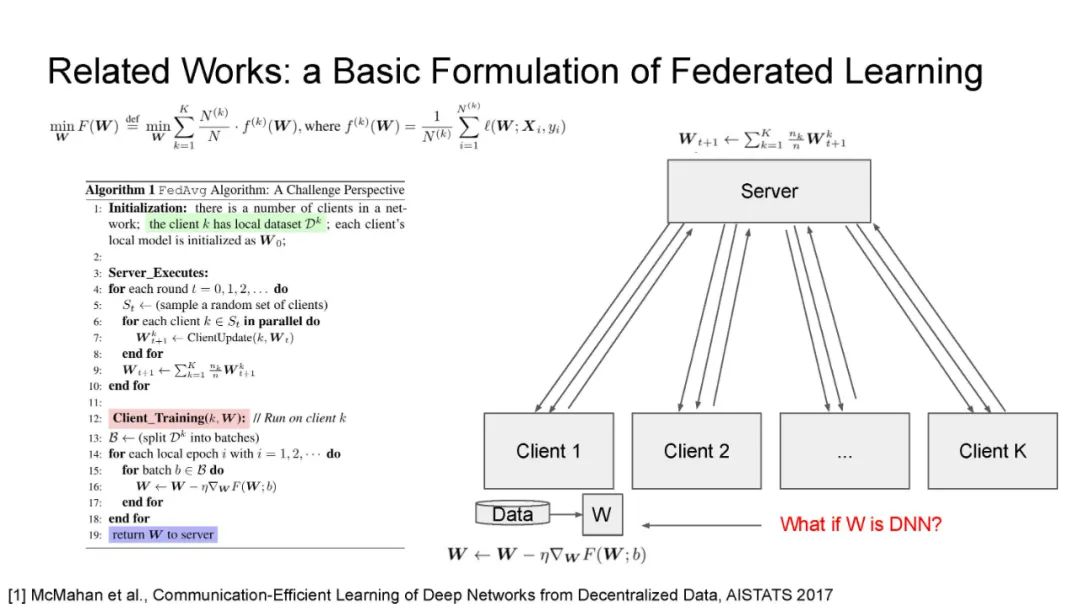
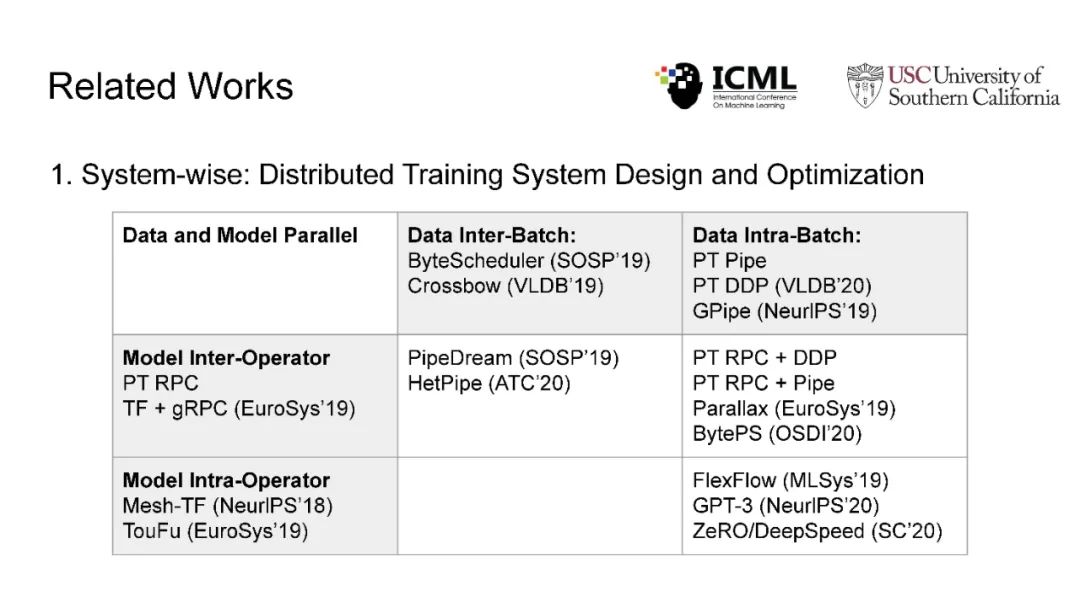
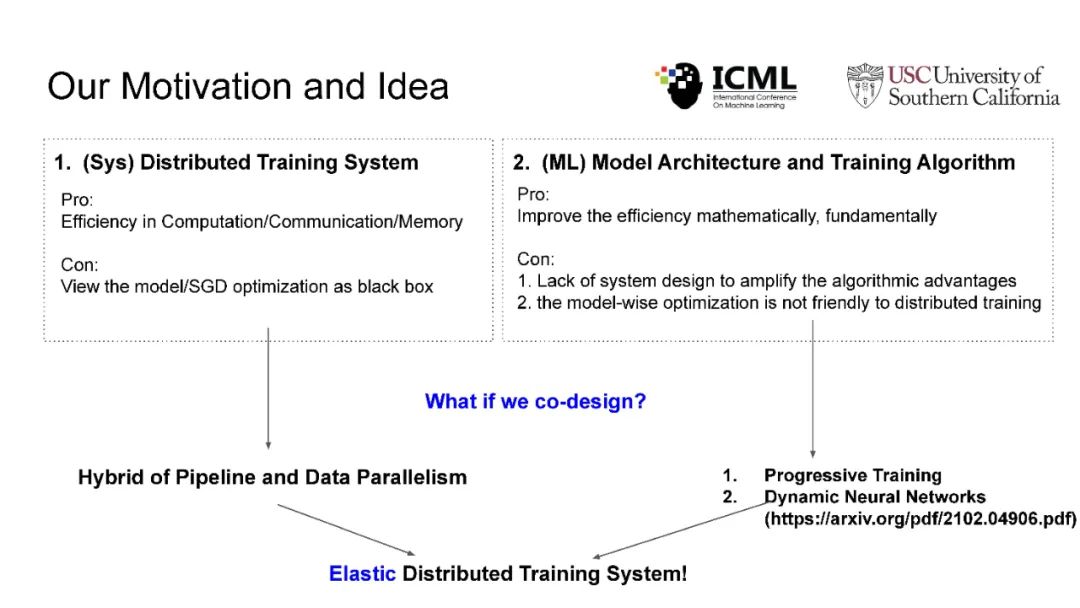
在现代人工智能中,大规模深度学习模型已经成为许多重要互联网业务背后的核心技术,如搜索/广告/推荐系统/CV/NLP。BERT、Vision Transformer、GPT-3和Switch Transformer模型将模型规模扩大到10亿甚至数万个参数,几乎所有学习任务的准确性都得到了显著提高。使用云集群的分布式训练是及时成功地训练此类大规模模型的关键。开发更先进的分布式训练系统和算法既可以降低能源成本,也可以让我们训练更大的模型。此外,开发像联邦学习这样的颠覆性学习模式也至关重要,它不仅可以保护用户的隐私,还可以分担处理前所未有的大数据和模型的负担。这次演讲将主要关注大规模模型的分布式ML系统: 云集群的动态分布式训练(https://DistML.ai)和边缘设备的大规模联合学习(https://FedML.ai)。在第一部分中,我将介绍PipeTransformer,这是一种用于分布式训练Transformer模型(BERT和ViT)的自动化弹性管道。在PipeTransformer中,我们设计了自适应的飞冻结算法,可以在训练过程中逐步识别和冻结部分层,并设计了弹性流水线系统,可以动态减少GPU资源来训练剩余的激活层,并在已释放的GPU资源上分叉更多的管道,以扩大数据并行度的宽度。第二部分,我将讨论可扩展的联邦学习,用于在资源受限的边缘设备和FedML生态系统上训练大型模型,其目标是针对CV NLP、GraphNN和IoT等多种AI应用在边缘进行无处不在的分布式训练。
地址:
https://www.youtube.com/watch?v=AY7pCYTC8pQ
作者:
Chaoyang He,美国洛杉矶南加州大学计算机科学系博士研究生









---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于分布式机器学习如何用于大模型?的主要内容,如果未能解决你的问题,请参考以下文章
干货!分享 10 个用于并行和分布式机器学习任务的Python框架
干货!分享 10 个用于并行和分布式机器学习任务的Python框架