Spark分布式机器学习源码分析:模型评估指标
Posted 雨云飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark分布式机器学习源码分析:模型评估指标相关的知识,希望对你有一定的参考价值。
Spark是一个极为优秀的大数据框架,在大数据批处理上基本无人能敌,流处理上也有一席之地,机器学习则是当前正火热AI人工智能的驱动引擎,在大数据场景下如何发挥AI技术成为优秀的大数据挖掘工程师必备技能。本文结合机器学习思想与Spark框架代码结构来实现分布式机器学习过程,希望与大家一起学习进步~
本文采用的组件版本为:Ubuntu 19.10、Jdk 1.8.0_241、Scala 2.11.12、Hadoop 3.2.1、Spark 2.4.5,老规矩先开启一系列Hadoop、Spark服务与Spark-shell窗口:
1
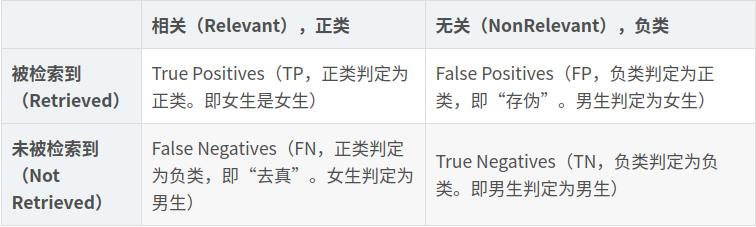
二分类
-
真阳性(TP)-标签为阳性,预测也为阳性 -
真阴性(TN)-标签为负,预测也为负 -
假阳性(FP)-标签为负,但预测为正 -
假阴性(FN)-标签为阳性,但预测为阴性
2
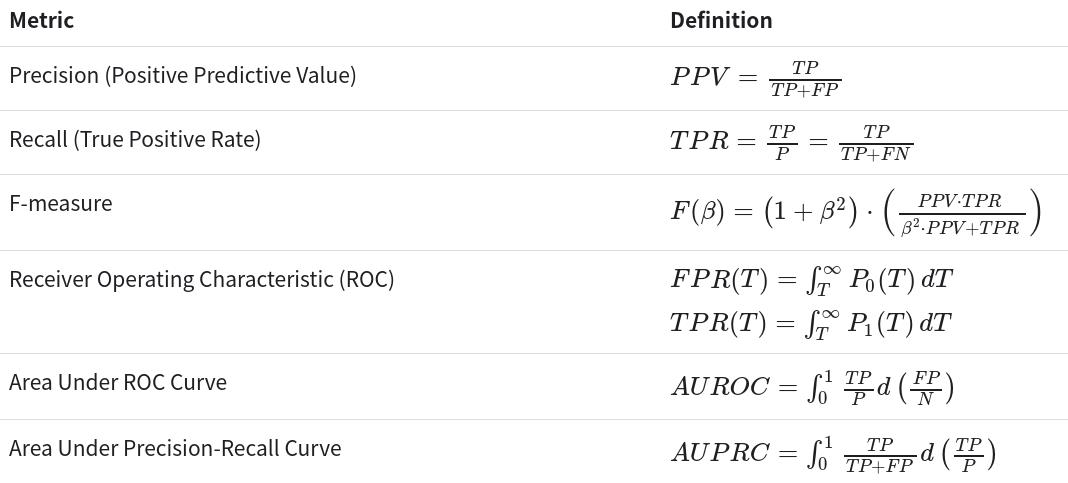
二分类
二分类器用于将给定数据集的元素分为两个可能的组(例如欺诈或非欺诈)之一,这是多类分类的一种特殊情况。大多数二元分类指标可以概括为多类分类指标。
3
多分类
import org.apache.spark.mllib.classification.LogisticRegressionWithLBFGSimport org.apache.spark.mllib.evaluation.BinaryClassificationMetricsimport org.apache.spark.mllib.regression.LabeledPointimport org.apache.spark.mllib.util.MLUtils// 加载libsvm格式的训练数据val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_binary_classification_data.txt")// 将数据分为训练(60%)和测试(40%)val Array(training, test) = data.randomSplit(Array(0.6, 0.4), seed = 11L)training.cache()// 运行训练算法以建立模型val model = new LogisticRegressionWithLBFGS().setNumClasses(2).run(training)// 清除预测阈值,以便模型返回概率model.clearThreshold// 计算测试集上的原始分数val predictionAndLabels = test.map { case LabeledPoint(label, features) =>val prediction = model.predict(features)(prediction, label)}// 实例化指标对象val metrics = new BinaryClassificationMetrics(predictionAndLabels)// 通过阈值预测精度val precision = metrics.precisionByThresholdprecision.foreach { case (t, p) =>println(s"Threshold: $t, Precision: $p")}// 通过阈值预测召回率val recall = metrics.recallByThresholdrecall.foreach { case (t, r) =>println(s"Threshold: $t, Recall: $r")}// PR曲线val PRC = metrics.pr// F值val f1Score = metrics.fMeasureByThresholdf1Score.foreach { case (t, f) =>println(s"Threshold: $t, F-score: $f, Beta = 1")}val beta = 0.5val fScore = metrics.fMeasureByThreshold(beta)f1Score.foreach { case (t, f) =>println(s"Threshold: $t, F-score: $f, Beta = 0.5")}// AUPRCval auPRC = metrics.areaUnderPRprintln(s"Area under precision-recall curve = $auPRC")// 计算在ROC和PR曲线中使用的阈值val thresholds = precision.map(_._1)// ROC曲线val roc = metrics.roc// AUROCval auROC = metrics.areaUnderROCprintln(s"Area under ROC = $auROC")
3
多分类
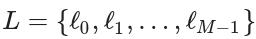 ,真实输出向量y由N个元素组成
,真实输出向量y由N个元素组成
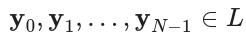 ,多类预测算法生成N个元素的预测向量
,多类预测算法生成N个元素的预测向量
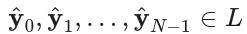 。对于本节,修改后的增量函数δ^(x)将被证明是有用的
。对于本节,修改后的增量函数δ^(x)将被证明是有用的
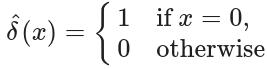

4
多分类实例
import org.apache.spark.mllib.classification.LogisticRegressionWithLBFGSimport org.apache.spark.mllib.evaluation.MulticlassMetricsimport org.apache.spark.mllib.regression.LabeledPointimport org.apache.spark.mllib.util.MLUtilsval data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_multiclass_classification_data.txt")val Array(training, test) = data.randomSplit(Array(0.6, 0.4), seed = 11L)training.cache()val model = new LogisticRegressionWithLBFGS().setNumClasses(3).run(training)val predictionAndLabels = test.map { case LabeledPoint(label, features) =>val prediction = model.predict(features)(prediction, label)}val metrics = new MulticlassMetrics(predictionAndLabels)// 混淆矩阵println("Confusion matrix:")println(metrics.confusionMatrix)// 总体统计val accuracy = metrics.accuracyprintln("Summary Statistics")println(s"Accuracy = $accuracy")// 通过标签预测val labels = metrics.labelslabels.foreach { l =>println(s"Precision($l) = " + metrics.precision(l))}// 通过标签计算召回率labels.foreach { l =>println(s"Recall($l) = " + metrics.recall(l))}// 通过标签计算假阳性率labels.foreach { l =>println(s"FPR($l) = " + metrics.falsePositiveRate(l))}// 通过标签计算F1labels.foreach { l =>println(s"F1-Score($l) = " + metrics.fMeasure(l))}// 加权统计println(s"Weighted precision: ${metrics.weightedPrecision}")println(s"Weighted recall: ${metrics.weightedRecall}")println(s"Weighted F1 score: ${metrics.weightedFMeasure}")println(s"Weighted false positive rate: ${metrics.weightedFalsePositiveRate}")
5
多标签分类
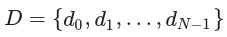 ,将L0,L1,...,LN-1定义为标签集的族,并将P0,P1,...,PN-1定义为预测集的族,其中Li和Pi分别是标签集和预测集记录di。所有唯一标签的集合由
,将L0,L1,...,LN-1定义为标签集的族,并将P0,P1,...,PN-1定义为预测集的族,其中Li和Pi分别是标签集和预测集记录di。所有唯一标签的集合由
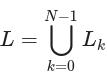
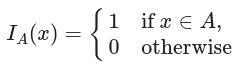

6
多标签分类实例
import org.apache.spark.mllib.evaluation.MultilabelMetricsimport org.apache.spark.rdd.RDDval scoreAndLabels: RDD[(Array[Double], Array[Double])] = sc.parallelize(Seq((Array(0.0, 1.0), Array(0.0, 2.0)),(Array(0.0, 2.0), Array(0.0, 1.0)),(Array.empty[Double], Array(0.0)),(Array(2.0), Array(2.0)),(Array(2.0, 0.0), Array(2.0, 0.0)),(Array(0.0, 1.0, 2.0), Array(0.0, 1.0)),(Array(1.0), Array(1.0, 2.0))), 2)val metrics = new MultilabelMetrics(scoreAndLabels)println(s"Recall = ${metrics.recall}")println(s"Precision = ${metrics.precision}")println(s"F1 measure = ${metrics.f1Measure}")println(s"Accuracy = ${metrics.accuracy}")metrics.labels.foreach(label =>println(s"Class $label precision = ${metrics.precision(label)}"))metrics.labels.foreach(label => println(s"Class $label recall = ${metrics.recall(label)}"))metrics.labels.foreach(label => println(s"Class $label F1-score = ${metrics.f1Measure(label)}"))println(s"Micro recall = ${metrics.microRecall}")println(s"Micro precision = ${metrics.microPrecision}")println(s"Micro F1 measure = ${metrics.microF1Measure}")println(s"Hamming loss = ${metrics.hammingLoss}")println(s"Subset accuracy = ${metrics.subsetAccuracy}")
7
排序算法
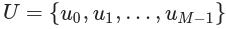
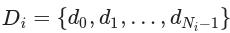
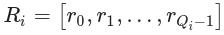
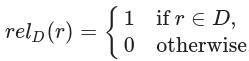

8
排序算法实例
import org.apache.spark.mllib.evaluation.{RankingMetrics, RegressionMetrics}import org.apache.spark.mllib.recommendation.{ALS, Rating}// 读取收视率数据val ratings = spark.read.textFile("data/mllib/sample_movielens_data.txt").rdd.map { line =>val fields = line.split("::")Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble - 2.5)}.cache()// 将等级映射为1或0,其中1表示应该推荐的电影val binarizedRatings = ratings.map(r => Rating(r.user, r.product,if (r.rating > 0) 1.0 else 0.0)).cache()// 汇总评分val numRatings = ratings.count()val numUsers = ratings.map(_.user).distinct().count()val numMovies = ratings.map(_.product).distinct().count()println(s"Got $numRatings ratings from $numUsers users on $numMovies movies.")// 建立模型val numIterations = 10val rank = 10val lambda = 0.01val model = ALS.train(ratings, rank, numIterations, lambda)// 定义一个函数以将等级从0缩放到1def scaledRating(r: Rating): Rating = {val scaledRating = math.max(math.min(r.rating, 1.0), 0.0)Rating(r.user, r.product, scaledRating)}// 获取每个用户的排名前十的预测,然后从[0,1]开始缩放val userRecommended = model.recommendProductsForUsers(10).map { case (user, recs) =>(user, recs.map(scaledRating))}// 假设用户评分3或更高(对应于1)的任何电影都是相关文档// 与最相关的十大文件进行比较val userMovies = binarizedRatings.groupBy(_.user)val relevantDocuments = userMovies.join(userRecommended).map { case (user, (actual,predictions)) =>(predictions.map(_.product), actual.filter(_.rating > 0.0).map(_.product).toArray)}// 实例化指标对象val metrics = new RankingMetrics(relevantDocuments)//精度Array(1, 3, 5).foreach { k =>println(s"Precision at $k = ${metrics.precisionAt(k)}")}// 平均平均精度println(s"Mean average precision = ${metrics.meanAveragePrecision}")// 归一化折现累计收益Array(1, 3, 5).foreach { k =>println(s"NDCG at $k = ${metrics.ndcgAt(k)}")}// 获取每个数据点的预测val allPredictions = model.predict(ratings.map(r => (r.user, r.product))).map(r => ((r.user,r.product), r.rating))val allRatings = ratings.map(r => ((r.user, r.product), r.rating))val predictionsAndLabels = allPredictions.join(allRatings).map { case ((user, product),(predicted, actual)) =>(predicted, actual)}// 使用回归指标获取RMSEval regressionMetrics = new RegressionMetrics(predictionsAndLabels)println(s"RMSE = ${regressionMetrics.rootMeanSquaredError}")// 计算R方println(s"R-squared = ${regressionMetrics.r2}")
9
回归算法评估

import org.apache.spark.mllib.evaluation.RegressionMetricsimport org.apache.spark.mllib.linalg.Vectorimport org.apache.spark.mllib.regression.{LabeledPoint, LinearRegressionWithSGD}// 加载数据val data = spark.read.format("libsvm").load("data/mllib/sample_linear_regression_data.txt").rdd.map(row => LabeledPoint(row.getDouble(0), row.get(1).asInstanceOf[Vector])).cache()// 建立模型val numIterations = 100val model = LinearRegressionWithSGD.train(data, numIterations)// 获取预测val valuesAndPreds = data.map{ point =>val prediction = model.predict(point.features)(prediction, point.label)}// 实例化指标对象val metrics = new RegressionMetrics(valuesAndPreds)// Squared errorprintln(s"MSE = ${metrics.meanSquaredError}")println(s"RMSE = ${metrics.rootMeanSquaredError}")// R-squaredprintln(s"R-squared = ${metrics.r2}")// Mean absolute errorprintln(s"MAE = ${metrics.meanAbsoluteError}")// Explained varianceprintln(s"Explained variance = ${metrics.explainedVariance}")
Spark模型评估指标以及源码分析的全部内容至此结束,有关Spark的基础文章可参考前文:
参考链接:
http://spark.apache.org/docs/latest/mllib-evaluation-metrics.html
历史推荐

一个赞,晚餐加鸡腿
以上是关于Spark分布式机器学习源码分析:模型评估指标的主要内容,如果未能解决你的问题,请参考以下文章
学习笔记Spark—— Spark MLlib应用—— 机器学习简介Spark MLlib简介