干货!分享 10 个用于并行和分布式机器学习任务的Python框架
Posted 机器学习社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货!分享 10 个用于并行和分布式机器学习任务的Python框架相关的知识,希望对你有一定的参考价值。
如今,神经网络模型已经非常深入和复杂,需要学习很多的权重。训练此类模型非常具有挑战性。数据科学家需要建立分布式训练,检查点等。即使如此,数据科学从业者也可能无法达到理想的性能和收敛速度。训练大型模型更具挑战性,因为模型很容易耗尽内存。
在本文中,我将分享 10 个 Python 框架列表,这些框架使我们能够对分布式和并行化深度学习模型有更深刻的认知。
1、Elephas
Elephas 是 Keras 的扩展,它可以使用 Spark 大规模运行分布式深度学习模型。Elephas 保持了 Keras 的简单性和高可用性,从而允许对分布式模型进行快速原型制作,该模型可以在海量数据集上运行。Elephas 当前支持许多应用程序,包括:深度学习模型的数据并行训练分布式超参数优化集成模型的分布式训练。
安装
pip install elephas
Github 链接
https://github.com/maxpumperla/elephas
2、FairScale

FairScale 是 PyTorch 扩展库,用于在一台或多台机器/节点上进行高性能和大规模培训。该库扩展了基本的PyTorch功能,同时添加了新的实验功能。FairScale支持:
-
并行 -
分片训练 -
大规模优化 -
GPU内存优化 -
GPU速度优化
安装
pip install fairscale
Github 链接
https://github.com/facebookresearch/fairscale
3、TensorFlowOnSpark
通过将TensorFlow深度学习框架中的突出功能与Apache Spark和Apache Hadoop相结合,TensorFlowOnSpark可以在GPU和CPU服务器集群上实现分布式深度学习。
它支持在Spark集群上进行分布式TensorFlow训练和推理,其目标是最大程度地减少在共享网格上运行现有TensorFlow程序所需的代码更改量。
TensorFlowOnSpark由Yahoo开发,用于在Yahoo私有云中的Hadoop集群上进行大规模分布式深度学习。
安装
# for tensorflow>=2.0.0
pip install tensorflowonspark
# for tensorflow<2.0.0
pip install tensorflowonspark==1.4.4
Github 链接
https://github.com/yahoo/TensorFlowOnSpark
4、DeepSpeed
DeepSpeed 是一个深度学习优化库,它使分布式训练变得容易、高效和有效。
DeepSpeed为所有人提供了极端规模的模型训练,从在大型超级计算机上进行训练到在低端群集甚至在单个GPU上进行训练的人员:
-
极端规模:将当前的GPU群集与数百种设备结合使用,实现3D并行 DeepSpeed 可以有效地训练具有数万亿参数的深度学习模型。 -
极高的内存效率:DeepSpeed 的ZeRO-Offload 仅需一个 GPU,即可训练超过10B参数的模型,比现有技术大10倍,使数十亿参数的模型训练民主化,从而使许多深度学习科学家可以探索更大更好的模型。
pip install deepspeed
Github 链接
https://github.com/microsoft/DeepSpeed
5、Horovod

Horovod 是一个针对TensorFlow,Keras,PyTorch和Apache MXNet的分布式深度学习训练框架。
Horovod的目标是使分布式深度学习快速且易于使用。一旦使用Horovod编写了可扩展的培训脚本,它就可以在单GPU,多GPU甚至是多个主机上运行,而无需进行任何其他代码更改。
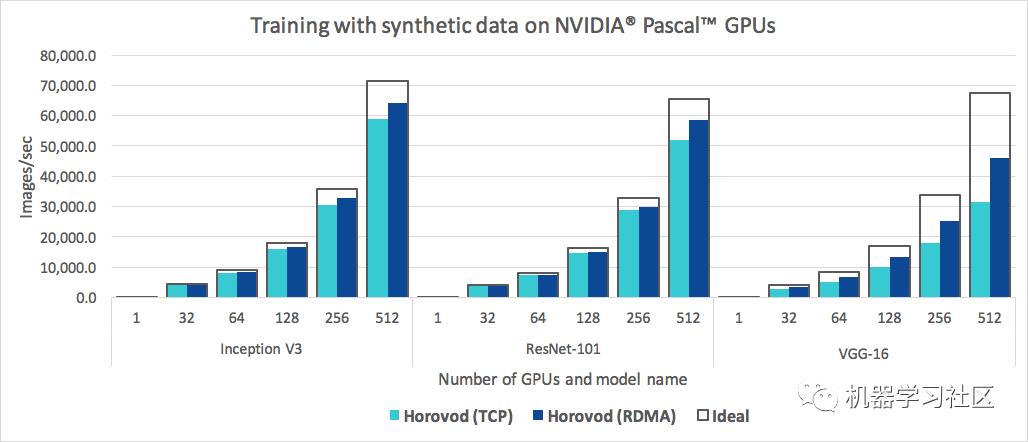
除了易于使用之外,Horovod速度也很快。下面的图表表示基准测试是在128个服务器上完成的,该服务器具有 4 个 Pascal GPU,每个GPU均通过支持RoCE的 25 Gbit/s网络连接:
安装
#To run on CPUs
pip install horovod
#To run on GPUs with NCCL
HOROVOD_GPU_OPERATIONS=NCCL pip install horovod
Github 链接
https://github.com/horovod/horovod
6、Mesh TensorFlow
Mesh TensorFlow(mtf)是一种用于分布式深度学习的语言,能够指定广泛的分布式张量计算类。Mesh TensorFlow的目的是为硬件/处理器上的计算图形式化并实施分配策略。
例如:将批处理拆分成多个处理器行,并将隐藏层中的各个单元拆分成多个处理器列。Mesh TensorFlow被实现为 TensorFlow 上的一层。
安装
pip install mesh-tensorflow
Github 链接
https://github.com/tensorflow/mesh
7、BigDL
BigDL 是 Apache Spark 的分布式深度学习库,使用 BigDL,用户可以将其深度学习应用程序编写为标准 Spark 程序,这些程序可以直接在现有Spark或Hadoop集群上运行。
为了简化构建Spark和BigDL应用程序的过程,提供了一个高级Analytics Zoo,用于端到端Analytics AI管道:
-
丰富的深度学习支持。 -
高性能 -
有效地横向扩展
安装
pip install BigDL
Github 链接
https://bigdl-project.github.io/master/#
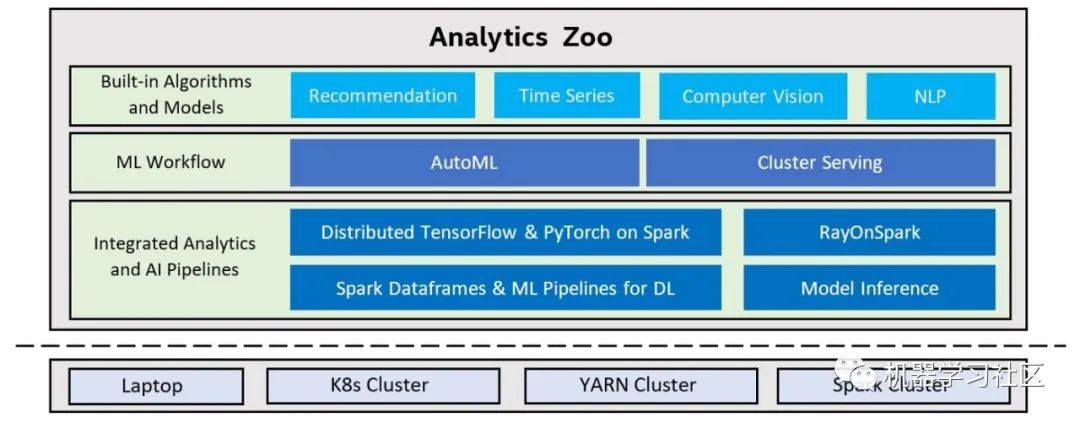
8、Analytics Zoo
 Analytics Zoo 无缝地将TensorFlow,Keras和PyTorch扩展为分布式大数据。
Analytics Zoo 无缝地将TensorFlow,Keras和PyTorch扩展为分布式大数据。
-
用于将AI模型应用于分布式大数据的端到端管道,使用Spark代码内联编写TensorFlow或PyTorch,以进行分布式训练和推理 -
Spark ML管道中的本机深度学习(TensorFlow / Keras / PyTorch / BigDL)支持 -
可扩展的AutoML用于时间序列预测
安装
pip install analytics-zoo
Github 链接
https://github.com/intel-analytics/analytics-zoo
9、Petastorm
Petastorm 是由 Uber ATG 开发的开源数据访问库。该库支持直接从Apache Parquet格式的数据集中进行单机或分布式培训以及对深度学习模型的评估。
Petastorm支持流行的基于Python的机器学习(ML)框架,例如Tensorflow,PyTorch和PySpark。也可以从纯Python代码中使用它。
安装
pip install petastorm
Github 链接
https://github.com/uber/petastorm
10、Apache SINGA

Apache SINGA 是一个 Apache 顶级项目,致力于深度学习和机器学习模型的分布式培训。
-
可扩展性:SINGA使培训并行化并优化通信成本,以提高培训的可扩展性。 -
效率:SINGA建立计算图以优化训练速度和内存占用。 -
可用性:SINGA具有简单的软件堆栈和Python界面以提高可用性。
安装
#CPU only
conda install -c nusdbsystem -c conda-forge singa-cpu=3.1.0
#GPU with CUDA and cuDNN (CUDA driver >=384.81 is required)
conda install -c nusdbsystem -c conda-forge singa-gpu=3.1.0
官方链接
http://singa.apache.org/
福利时间
336页《机器学习实战》PDF 免费下载了,全书通过精心编排的实例,切入日常工作任务,摒弃学术化语言,利用高效的可复用Python代码来阐释如何处理统计数据,进行数据分析及可视化。通过各种实例,读者可从中学会机器学习的核心算法,并能将其运用于一些策略性任务中,如分类、预测、推荐。另外,还可用它们来实现一些更高级的功能,如汇总和简化等。
1、长按关注下方公众号,点击右上角;
2、在下方后台回复关键词「机器学习实战」快速下载
以上是关于干货!分享 10 个用于并行和分布式机器学习任务的Python框架的主要内容,如果未能解决你的问题,请参考以下文章