2021年大数据Kafka:kafka生产者数据分发策略
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据Kafka:kafka生产者数据分发策略相关的知识,希望对你有一定的参考价值。
全网最详细的大数据Kafka文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
策略二:用户发生数据的时候指定了key没有指定partition ,采用hash算法
策略三: 当用户既没有指定partition也没有key。采用粘性的划分策略(Sticky Partitioning Strategy)方案(2.4以上版本新特性,老版本为轮询)
系列历史文章
2021年大数据Kafka(十):kafka生产者数据分发策略
2021年大数据Kafka(九):kafka消息存储及查询机制原理
2021年大数据Kafka(八):Kafka如何保证数据不丢失
2021年大数据Kafka(七):Kafka的分片和副本机制
2021年大数据Kafka(六):❤️安装Kafka-Eagle❤️
2021年大数据Kafka(五):❤️Kafka的java API编写❤️
2021年大数据Kafka(四):❤️kafka的shell命令使用❤️
2021年大数据Kafka(三):❤️Kafka的集群搭建以及shell启动命令脚本编写❤️
2021年大数据Kafka(二):❤️Kafka特点总结和架构❤️
2021年大数据Kafka(一):❤️消息队列和Kafka的基本介绍❤️
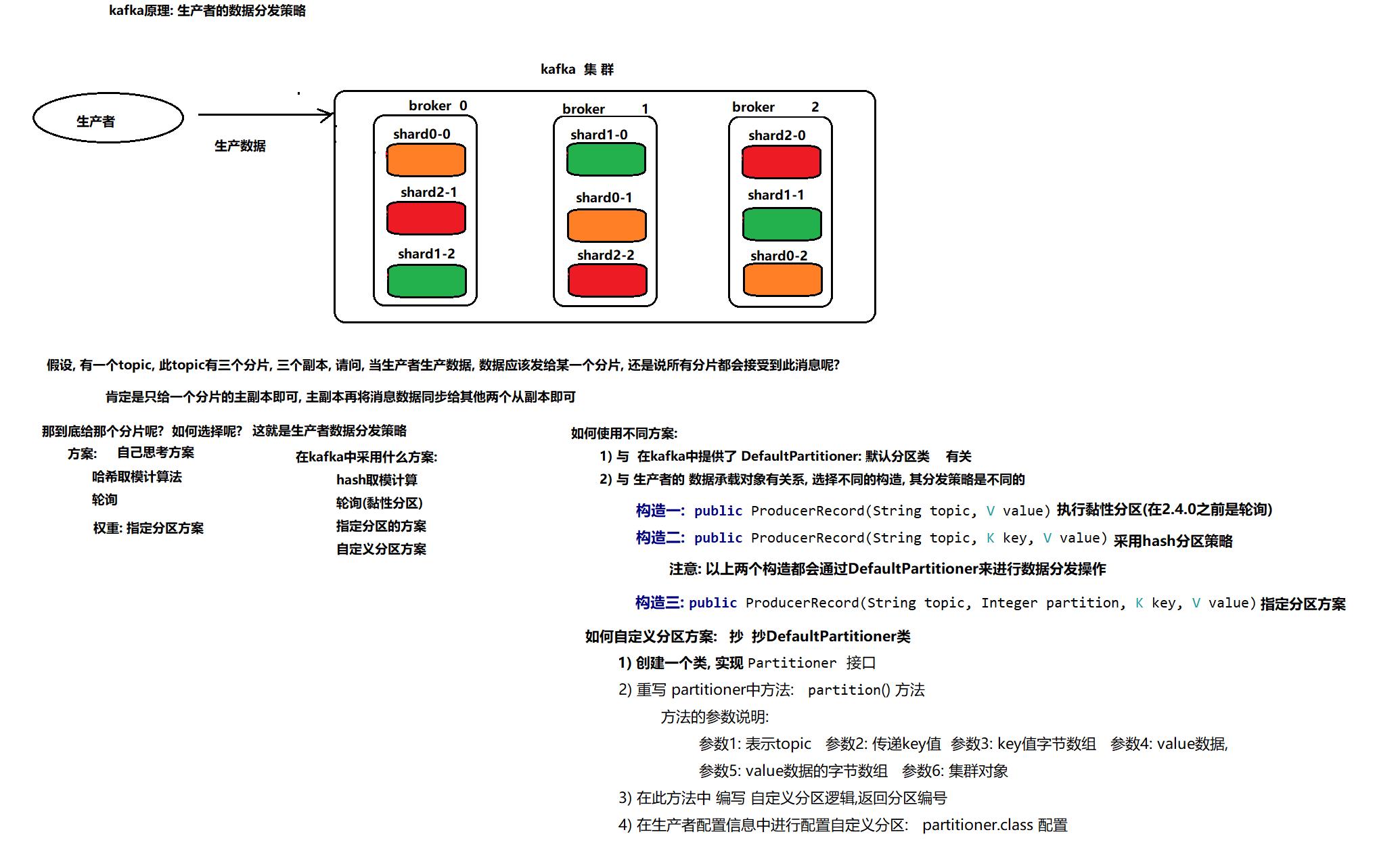
生产者数据分发策略

策略一:用户指定了partition

策略二:用户发生数据的时候指定了key没有指定partition ,采用hash算法

策略三: 当用户既没有指定partition也没有key。采用粘性的划分策略(Sticky Partitioning Strategy)方案(2.4以上版本新特性,老版本为轮询)
Sticky Partitioning Strategy会随机地选择一个分区并会尽可能地坚持使用该分区——即所谓的粘住这个分区。
原因:

总结:
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于2021年大数据Kafka:kafka生产者数据分发策略的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据Kafka:kafka消息存储及查询机制原理
2021年大数据Kafka:❤️Kafka的java API编写❤️