2021年大数据Kafka:❤️Kafka的java API编写❤️
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据Kafka:❤️Kafka的java API编写❤️相关的知识,希望对你有一定的参考价值。
全网最详细的大数据Kafka文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
系列历史文章
2021年大数据Kafka(五):❤️Kafka的java API编写❤️
2021年大数据Kafka(四):❤️kafka的shell命令使用❤️
2021年大数据Kafka(三):❤️Kafka的集群搭建以及shell启动命令脚本编写❤️
2021年大数据Kafka(二):❤️Kafka特点总结和架构❤️
2021年大数据Kafka(一):❤️消息队列和Kafka的基本介绍❤️
Kafka的java API编写
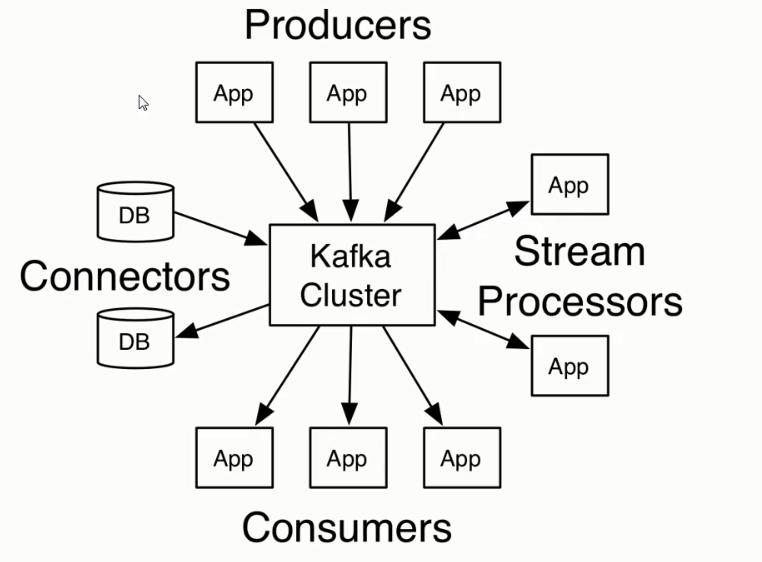
一、生产者代码
第一步: 需求
接下来,编写Java程序,将1-100的数字消息写入到Kafka中
第二步: 准备工作
1) 创建maven项目 导入相关的依赖
<repositories><!-- 代码库 -->
<repository> <id>central</id> <url>http://maven.aliyun.com/nexus/content/groups/public//</url>
<releases> <enabled>true</enabled></releases>
<snapshots> <enabled>true</enabled> <updatePolicy>always</updatePolicy> <checksumPolicy>fail</checksumPolicy></snapshots>
</repository>
</repositories>
<dependencies>
<!-- kafka客户端工具 --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.4.1</version>
</dependency>
<!-- 工具类 --> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-io</artifactId> <version>1.3.2</version>
</dependency>
<!-- SLF桥接LOG4J日志 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.6</version>
</dependency>
<!-- SLOG4J日志 --> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.16</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
2) 导入log4j.properties
将
log4j.properties
配置文件放入到
resources
文件夹中
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
3) 创建包和类
创建包cn.it.kafka,并创建KafkaProducerTest类
第三步: 代码开发
生产者代码1: 默认异步发生数据方式, 不含回调函数
package com.it.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
// kafka的生产者的代码:
public class KafkaProducerTest {
public static void main(String[] args) {
//1.1: 构建生产者的配置信息:
Properties props = new Properties();
props.put("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
props.put("acks", "all"); // 消息确认机制: all表示 必须等待kafka端所有的副本全部接受到数据 确保数据不丢失
// 说明: 在数据发送的时候, 可以发送键值对的, 此处是用来定义k v的序列化的类型
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//1. 创建 kafka的生产者对象: KafkaProducer
Producer<String, String> producer = new KafkaProducer<String, String>(props);
//2. 执行数据的发送
for (int i = 0; i < 100; i++) {
// producerRecord对象: 生产者的数据承载对象
ProducerRecord<String, String> producerRecord =
new ProducerRecord<String, String>("product-topic", Integer.toString(i));
producer.send(producerRecord);
}
//3. 释放资源
producer.close();
}
}生产者的代码2: 同步发送操作
package com.it.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
// kafka的生产者的代码:
public class KafkaProducerTest2 {
@SuppressWarnings("all")
public static void main(String[] args) {
//1.1: 构建生产者的配置信息:
Properties props = new Properties();
props.put("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
props.put("acks", "all"); // 消息确认机制: all表示 必须等待kafka端所有的副本全部接受到数据 确保数据不丢失
// 说明: 在数据发送的时候, 可以发送键值对的, 此处是用来定义k v的序列化的类型
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//1. 创建 kafka的生产者对象: KafkaProducer
Producer<String, String> producer = new KafkaProducer<String, String>(props);
//2. 执行数据的发送
for (int i = 0; i < 100; i++) {
// producerRecord对象: 生产者的数据承载对象
ProducerRecord<String, String> producerRecord =
new ProducerRecord<String, String>("product-topic", Integer.toString(i));
try {
producer.send(producerRecord).get(); // get方法, 表示是同步发送数据的方式
} catch (Exception e) {
// 如果发生操作, 出现了异常, 认为, 数据发生失败了 ....
e.printStackTrace();
}
}
//3. 释放资源
producer.close();
}
}
生产者代码3: 异步发生数据, 带有回调函数操作
package com.it.producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
// kafka的生产者的代码:
public class KafkaProducerTest {
public static void main(String[] args) {
//1.1: 构建生产者的配置信息:
Properties props = new Properties();
props.put("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
props.put("acks", "all"); // 消息确认机制: all表示 必须等待kafka端所有的副本全部接受到数据 确保数据不丢失
// 说明: 在数据发送的时候, 可以发送键值对的, 此处是用来定义k v的序列化的类型
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//1. 创建 kafka的生产者对象: KafkaProducer
Producer<String, String> producer = new KafkaProducer<String, String>(props);
//2. 执行数据的发送
for (int i = 0; i < 100; i++) {
// producerRecord对象: 生产者的数据承载对象
ProducerRecord<String, String> producerRecord =
new ProducerRecord<String, String>("product-topic", Integer.toString(i));
producer.send(producerRecord, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
// 在参数2中, 表示发生的状态异常, 如果 异常为null 表示数据以及发送成功, 如果不为null, 表示数据没有发送成功
if(exception != null){
// 执行数据发生失败的后措施...
}
}
}); // 异步发送方式
}
//3. 释放资源
producer.close();
}
}二、消费者代码
消费者代码1: 自动提交偏移量数据
package com.it.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
// kafka的消费者的代码
public class KafkaConsumerTest {
public static void main(String[] args) {
//1.1: 指定消费者的配置信息
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
props.setProperty("group.id", "test"); // 消费者组的名称
props.setProperty("enable.auto.commit", "true"); // 消费者自定提交消费偏移量信息给kafka
props.setProperty("auto.commit.interval.ms", "1000"); // 每次自动提交偏移量时间间隔 1s一次
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//1. 创建kafka的消费者核心类对象: KafkaConsumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
//2. 让当前这个消费, 去监听那个topic?
consumer.subscribe(Arrays.asList("product-topic")); // 一个消费者 可以同时监听多个topic的操作
while (true) { // 一致监听
//3. 从topic中 获取数据操作: 参数表示意思, 如果队列中没有数据, 最长等待多长时间
// 如果超时后, topic中依然没有数据, 此时返回空的 records(空对象)
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
//4. 遍历ConsumerRecords, 从中获取消息数据
for (ConsumerRecord<String, String> record : records) {
String value = record.value();
System.out.println("接收到消息为:"+value);
}
}
}
}消费者代码2: 手动提交偏移量数据
package com.it.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
// kafka的消费者的代码
public class KafkaConsumerTest2 {
public static void main(String[] args) {
//1.1 定义消费者的配置信息
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1:9092,node2:9092,node3:9092");
props.setProperty("group.id", "test01"); // 消费者组的名称
props.setProperty("enable.auto.commit", "false"); // 消费者自定提交消费偏移量信息给kafka
//props.setProperty("auto.commit.interval.ms", "1000"); // 每次自动提交偏移量时间间隔 1s一次
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//1. 创建消费者的核心类对象
KafkaConsumer<String,String> consumer = new KafkaConsumer<String,String>(props);
//2. 指定要监听的topic
consumer.subscribe(Arrays.asList("product-topic"));
//3. 获取数据
while(true) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
String value = consumerRecord.value();
// 执行消费数据操作
System.out.println("数据为:"+ value);
// 当执行完成后, 认为消息已经消费完成
consumer.commitAsync(); // 手动提交偏移量信息
}
}
}
}
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于2021年大数据Kafka:❤️Kafka的java API编写❤️的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据Kafka:❤️Kafka的java API编写❤️
2021年大数据Kafka:❤️Kafka的java API编写❤️