2021年大数据Kafka:Kafka如何保证数据不丢失
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据Kafka:Kafka如何保证数据不丢失相关的知识,希望对你有一定的参考价值。
全网最详细的大数据Kafka文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
系列历史文章
2021年大数据Kafka(八):Kafka如何保证数据不丢失
2021年大数据Kafka(七):Kafka的分片和副本机制
2021年大数据Kafka(六):❤️安装Kafka-Eagle❤️
2021年大数据Kafka(五):❤️Kafka的java API编写❤️
2021年大数据Kafka(四):❤️kafka的shell命令使用❤️
2021年大数据Kafka(三):❤️Kafka的集群搭建以及shell启动命令脚本编写❤️
2021年大数据Kafka(二):❤️Kafka特点总结和架构❤️
2021年大数据Kafka(一):❤️消息队列和Kafka的基本介绍❤️
Kafka如何保证数据不丢失
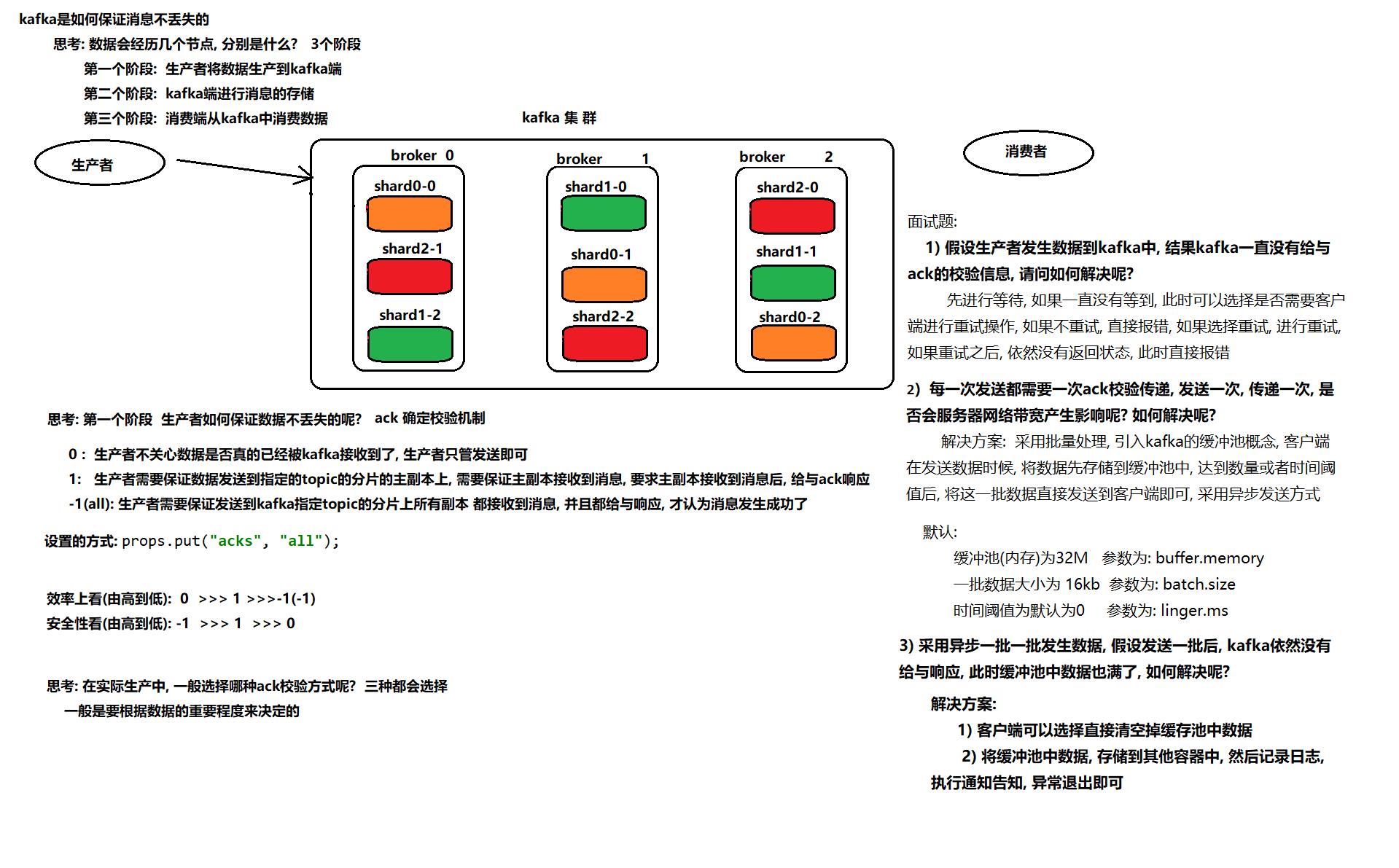
一、如何保证生产者数据不丢失

1) 消息生产分为同步模式和异步模式
2) 消息确认分为三个状态
- a) 0:生产者只负责发送数据
- b) 1:某个partition的leader收到数据给出响应
- c) -1:某个partition的所有副本都收到数据后给出响应
3) 在同步模式下
- a) 生产者等待10S,如果broker没有给出ack响应,就认为失败。
- b) 生产者重试3次,如果还没有响应,就报错。
4) 在异步模式下
- a) 先将数据保存在生产者端的Buffer中。Buffer大小是2万条。 32M
- b) 满足数据阈值或者时间阈值其中的一个条件就可以发送数据。
- c) 发送一批数据的大小是500条。16Kb
如果broker迟迟不给ack,而Buffer又满了。开发者可以设置是否直接清空Buffer中的数据。
二、如何保证broker端数据不丢失
broker端:
- broker端的消息不丢失,其实就是用partition副本机制来保证。
- Producer ack -1(all). 能够保证所有的副本都同步好了数据。其中一台机器挂了,并不影响数据的完整性。
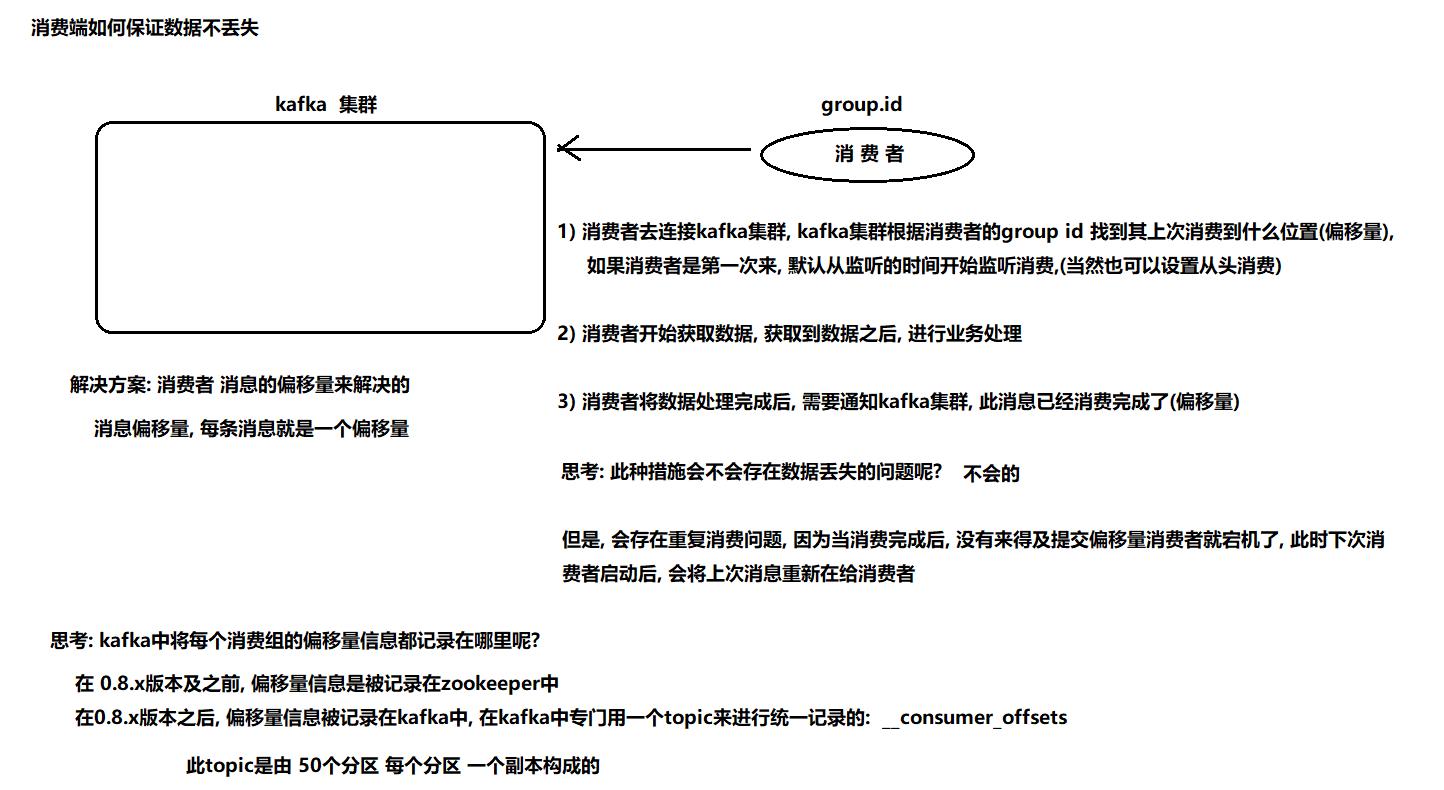
三、如何保证消费端数据不丢失
消费端:
通过offset commit 来保证数据的不丢失,kafka自己记录了每次消费的offset数值,下次继续消费的时候,会接着上次的offset进行消费。
而offset的信息在kafka0.8版本之前保存在zookeeper中,在0.8版本之后保存到topic中,即使消费者在运行过程中挂掉了,再次启动的时候会找到offset的值,找到之前消费消息的位置,接着消费,由于offset的信息写入的时候并不是每条消息消费完成后都写入的,所以这种情况有可能会造成重复消费,但是不会丢失消息。
四、总结
生产者端
broker端
broker端主要是通过数据的副本和 ack为-1 来保证数据不丢失操作
消费端
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于2021年大数据Kafka:Kafka如何保证数据不丢失的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据Kafka:kafka消息存储及查询机制原理
2021年大数据Kafka:kafka消息存储及查询机制原理