大数据问题排查系列 - SPARK STANDALONE HA 模式的一个缺陷点与应对方案
Posted michaelli916
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据问题排查系列 - SPARK STANDALONE HA 模式的一个缺陷点与应对方案相关的知识,希望对你有一定的参考价值。
大数据问题排查系列 - SPARK STANDALONE HA 模式的一个缺陷点与应对方案
前言
大家好,我是明哥!
作为当今离线批处理模式的扛把子,SPARK 在绝大多数公司的数据处理平台中都是不可或缺的。而在底层使用的具体资源管理器上,SPARK 支持四种模式:
- standalone
- yarn
- mesos
- kubernetes
四种模式的简单对比如下图:

以上四种模式中,mesos 在业界使用的最少,其次是 standalone 模式,再次是 yarn 模式。不过随着大数据与云计算日益融合的趋势,现在也有不少场景在使用 kubernetes 替代 yarn 和 standalone 模式。
关于大数据的发展趋势,尤其是大数据与云计算日益融合的趋势,大家可参考笔者以往两篇文章:
从技术视角看大数据行业的发展趋势
大数据与云计算深度融合的趋势体现在哪些方面?
本文讲述,spark standalone部署模式下,HA 高可用部署的一个缺陷点和对应的解决办法。
以下是正文。
SPARK STADNALONE HA 模式的确切含义是什么?
我们知道,spark 在 standalone 部署模式下,有多个 worker 节点负责具体任务的执行,spark 框架帮我们解决了作业底层各个 stage 以及各个 stage 中各个 task 任务执行失败时的容错,spark框架也帮我们解决了 各个 worker 节点宕机情况下的容错;但是整个 spark 集群是只有一个 master 节点负责接收用户提交的作业的,该 master 节点是有单点故障即 SPOF(single point of failure)的。
为了应对 master 节点的 spof, 我们可以做 master 节点的 HA 高可用:即部署多个 master 节点,并通过选举确保同一时间只有一个 active 的 master 对外提供服务,当该 active master 节点意外宕机时,原先 standby 的 master 节点会自动检测到这种异常情况并被选举成为新的 active master,从而对外提供服务(接受 worker 注册,接受作业提交);同时原先已经注册到集群中的 workers,以及原先已经提交的作业,会自动注册到该新的 master 上,即不丢失状态。
如何配置和使用 STANDALONE HA 模式下的 SPARK 集群?
有两种方法,配置都很简单:
-
一是配置 spark-defaults.conf,示例如下:
- spark.master spark://node1:7077,node2:7077
- spark.deploy.recoveryMode ZOOKEEPER
- spark.deploy.zookeeper.url node1:2181,node2:2181,node3:2181
- spark.deploy.zookeeper.dir /spark24-ha
-
二是配置spark-env.sh,示例如下:

当然,客户端在使用 HA 模式的 SPARK STANDALONE 集群时,需要将 spark.master 配置为以下方式,才会轮询检查可用的 spark master:
- spark.master spark://node1:7077,node2:7077
问题现象 - SPARK STANDALONE HA 模式的一个缺陷
笔者在线上使用过程中,发现了 SPARK STANDALONE HA 模式的一个缺陷点,或者说做的不完善的地方:
某客户环境的 spark standalone 部署模式,通过 zk 配置了ha 高可用后,发现 active spark master 经常挂掉,且 standby spark master 经过选举成为 active spark master 后也经常挂掉。
经过 google 搜索,发现有一个相关的 jira 是关于这个的:
Bouncing Zookeeper node causes Active spark master to exit
问题原因
-
Active 与 standby 的 spark master 在底层都会跟 zk 建立两个 session 链接, 一个是跟 zk leader node 的 session 链接,还有一个是跟任一 zk node 的 session 链接。
-
一旦 active spark master 底层跟 zk 的 session 链接断开,不管该 session 链接底层的 zk 是 leader 还是follower,原 active 状态的 spark master 的 leader 角色都会被剥夺,然后该 spark master 进程会自动退出。
-
同时原 standby 状态的 spark master 会成功切换为active状态,并自动接受已提交运行的application 的重新注册(当然,这些 application 需要配置多个 spark master 的轮询,如:spark://node1:7077,node2:7077)。
-
其实,以上现象说白了,是 active spark master 在因底层 zk 不稳定或其他原因造成 session 链接断开时,会被剥夺 leader 角色,这点没什么问题;但随后 spark 直接将被剥夺了 leader 角色的 master 进程直接退出了,这点就有点简单粗暴了。相关源码如下:
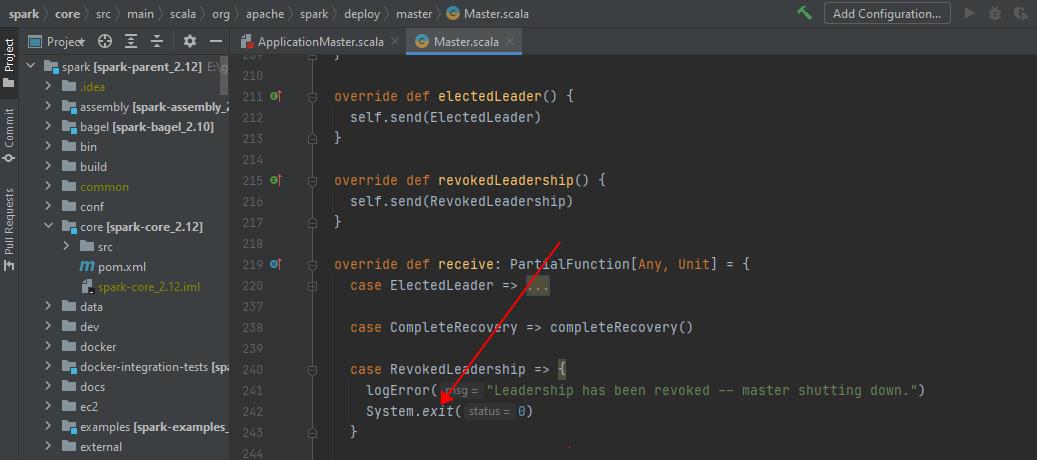
问题解决
可以从两个方面着手,解决该问题:
-
spark master 进程异常退出的根本原因是,底层的 zk 负载过大不稳定造成 spark 跟 zk 的 session 连接经常断开,(在 spark, kafka, 微服务等服务都使用同一个 zk 集群时,经常会出现该问题)。所以从根本上解决问题,需要从 zk 的稳定上做文章,可以配置 spark 单独使用一个独立的 zk 集群 (由于 spark 对 zk 的压力不大,对 zk 的性能要求也不是很高,所以该 zk 集群可以跟 spark 集群混部);
-
active spark master 在因底层 zk session 链接断掉失去 leader 角色后会自动退出,所以为确保 HA 效果,我们可以再次启动该 spark master 服务,以确保集群中有至少两个 spark master。具体实现方式上,可以通过监控脚本或 haproxy 等工具,自动检测 spark master 进程并在该进程异常推出后,自动再次启动该进程 (其实底层只需执行 sh $SPARK_HOME/sbin/start-master.sh即可)
相关日志
当 zk 的 leader 节点重启时,原先 active 状态的 spark master 节点日志如下:
21/08/18 18:43:15 INFO zookeeper.ClientCnxn: Unable to read additional data from server sessionid 0x27a687ab09da9f8, likely server has closed socket, closing socket connection and attempting reconnect
21/08/18 18:43:15 INFO state.ConnectionStateManager: State change: SUSPENDED
21/08/18 18:43:15 INFO state.ConnectionStateManager: State change: SUSPENDED
21/08/18 18:43:15 INFO master.ZooKeeperLeaderElectionAgent: We have lost leadership
21/08/18 18:43:15 ERROR master.Master: Leadership has been revoked -- master shutting down.
当 zk 的 follower 节点重启时,原先 active 状态的 spark master 节点日志如下:
21/08/18 22:51:46 WARN zookeeper.ClientCnxn: Session 0x17b58dbaaf60171 for server node1/10.20.39.41:2181, unexpected error, closing socket connection and attempting reconnect
java.io.IOException: Connection reset by peer
at sun.nio.ch.FileDispatcherImpl.read0(Native Method)
at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39)
at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223)
at sun.nio.ch.IOUtil.read(IOUtil.java:192)
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:380)
at org.apache.zookeeper.ClientCnxnSocketNIO.doIO(ClientCnxnSocketNIO.java:68)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:366)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1081)
21/08/18 22:51:46 INFO state.ConnectionStateManager: State change: SUSPENDED
21/08/18 22:51:46 INFO master.ZooKeeperLeaderElectionAgent: We have lost leadership
21/08/18 22:51:46 ERROR master.Master: Leadership has been revoked -- master shutting down.
当 zk 的 leader 节点重启时,原先 standby 状态的 spark master 节点日志如下:
21/08/18 18:43:18 INFO zookeeper.ClientCnxn: Socket connection established to node3/10.20.39.43:2181, initiating session
21/08/18 18:43:18 INFO zookeeper.ClientCnxn: Session establishment complete on server node3/10.20.39.43:2181, sessionid = 0x37a687ab25aa91d, negotiated timeout = 60000
21/08/18 18:43:18 INFO state.ConnectionStateManager: State change: RECONNECTED
21/08/18 18:44:18 INFO master.ZooKeeperLeaderElectionAgent: We have gained leadership
21/08/18 18:44:18 INFO master.Master: I have been elected leader! New state: RECOVERING
21/08/18 18:44:18 INFO master.Master: Trying to recover worker: worker-20210818182026-10.20.39.42-46483
21/08/18 18:44:18 INFO master.Master: Trying to recover worker: worker-20210818182026-10.20.39.43-37230
21/08/18 18:44:18 INFO client.TransportClientFactory: Successfully created connection to /10.20.39.42:46483 after 6 ms (0 ms spent in bootstraps)
21/08/18 18:44:18 INFO client.TransportClientFactory: Successfully created connection to /10.20.39.43:37230 after 6 ms (0 ms spent in bootstraps)
21/08/18 18:44:18 INFO master.Master: Worker has been re-registered: worker-20210818182026-10.20.39.42-46483
21/08/18 18:44:18 INFO master.Master: Worker has been re-registered: worker-20210818182026-10.20.39.43-37230
21/08/18 18:44:18 INFO master.Master: Recovery complete - resuming operations!
!关注不迷路~ 各种福利、资源定期分享!欢迎有想法、乐于分享的小伙伴们, 扫码关注公众号,后台留言,加群交流学习 (微信群:ABC技术交流 (AI+BigData+Cloud))。
以上是关于大数据问题排查系列 - SPARK STANDALONE HA 模式的一个缺陷点与应对方案的主要内容,如果未能解决你的问题,请参考以下文章
大数据问题排查系列-大数据集群开启 kerberos 认证后 HIVE 作业执行失败