:Spark 内核调度
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:Spark 内核调度相关的知识,希望对你有一定的参考价值。
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。下面就带大家来学习今天的内容!
往期内容:
- Spark基础入门-第一章:Spark 框架概述
- Spark基础入门-第二章:Spark环境搭建-Local
- Spark基础入门-第三章:Spark环境搭建-StandAlone
- Spark基础入门-第四章:Spark环境搭建-StandAlone-HA
- Spark基础入门-第五章:环境搭建-Spark on YARN
- Spark基础入门-第六章:PySpark库
- Spark基础入门-第七章:本机开发环境搭建
- Spark基础入门-第八章:分布式代码执行分析
- Spark Core-第一章: RDD详解
- Spark Core-第三章:RDD的持久化
- Spark Core-第四章:Spark案例练习
- Spark Core-第五章:共享变量
一、DAG
Spark的核心是根据RDD来实现的, Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。 Spark 的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage, 将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理, 可以合理规划资源利用,做到尽可能用最少的 资源高效地完成任务计算。
以词频统计WordCount程序为例, DAG图:
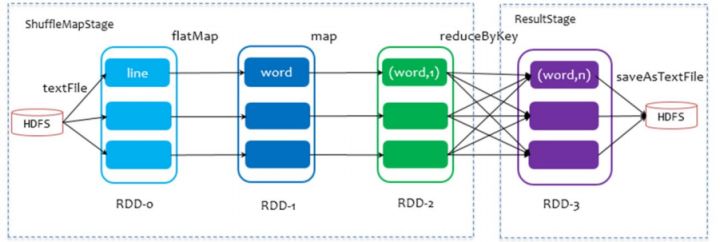

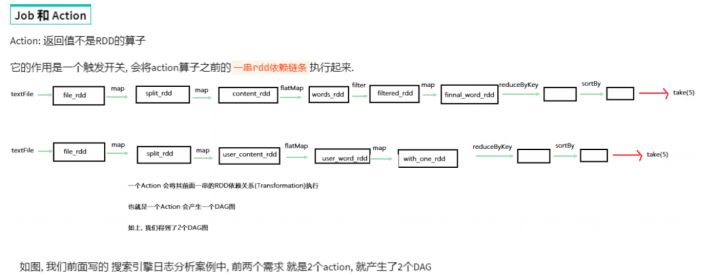


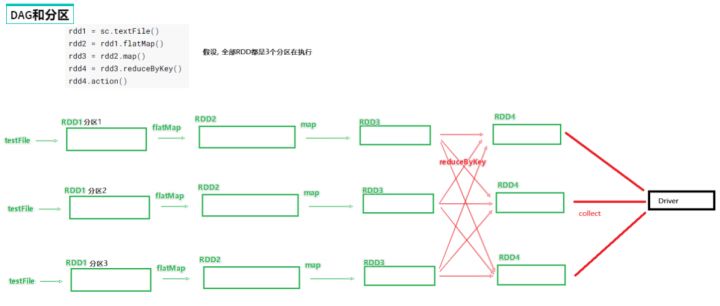
二、DAG的宽窄依赖和阶段划分

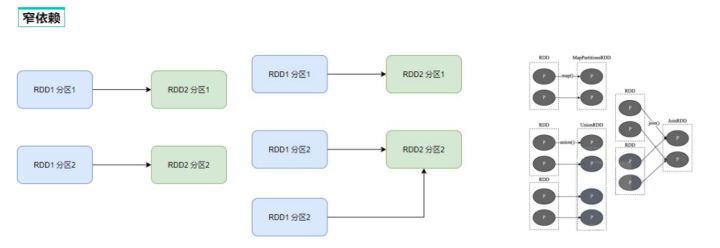

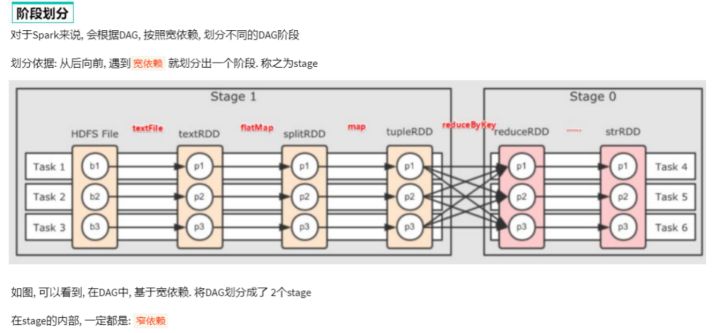
三、内存迭代计算



四、Spark 并行度





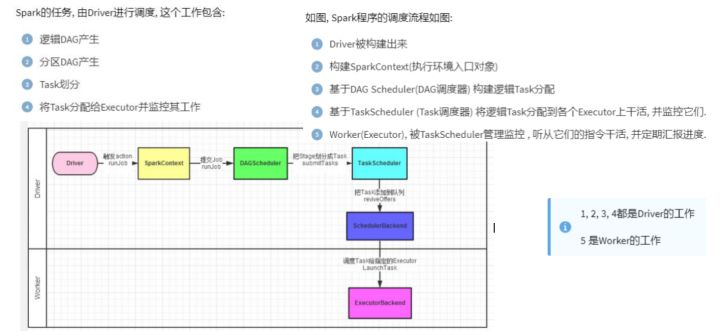
五、Spark的任务调度

六、 拓展 - Spark运行中的概念名词大全


七、 Spark Shuffle
MR Shuffle 回顾
首先回顾MapReduce框架中Shuffle过程,整体流程图如下:

简介
Spark在DAG调度阶段会将一个Job划分为多个Stage,上游Stage做map工作,下游Stage做reduce工作,其本质上 还是MapReduce计算框架。 Shuffle是连接map和reduce之间的桥梁,它将map的输出对应到reduce输入中,涉及到序列化反序列化、跨节点网络IO以及磁盘读写IO等。
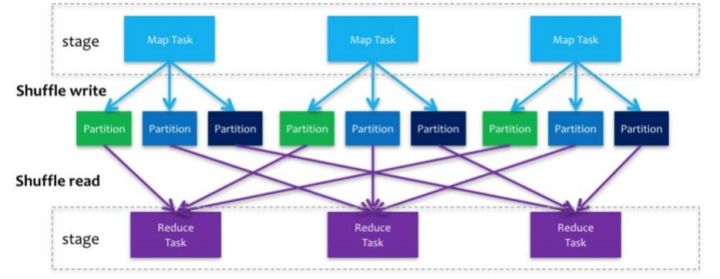
Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是
Child Stage的第一步。
执行Shuffle的主体是Stage中的并发任务,这些任务分ShuffleMapTask和ResultTask两种, ShuffleMapTask要进行 Shuffle, ResultTask负责返回计算结果,一个Job中只有最后的Stage采用ResultTask,其他的均为ShuffleMapTask 。如果要按照map端和reduce端来分析的话, ShuffleMapTask可以即是map端任务,又是reduce端任务,因为 Spark中的Shuffle是可以串行的; ResultTask则只能充当reduce端任务的角色。
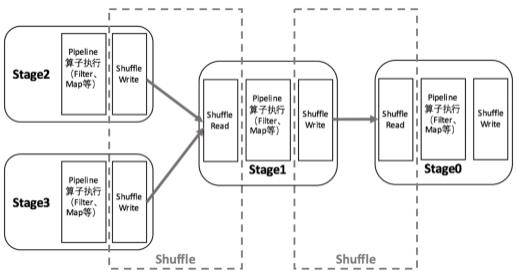
Spark在1.1以前的版本一直是采用Hash Shuffle的实现的方式,到1.1版本时参考Hadoop MapReduce的实现开始引 入Sort Shuffle,在1.5版本时开始Tungsten钨丝计划, 引入UnSafe Shuffle优化内存及CPU的使用, 在1.6中将 Tungsten统一到Sort Shuffle中,实现自我感知选择最佳Shuffle方式,到的2.0版本, Hash Shuffle已被删除,所有Shuffle方式全部统一到Sort Shuffle一个实现中。

在Spark的中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。 ShuffleManager随着 Spark的发展有两种实现的方式,分别为HashShuffleManager和SortShuffleManager,因此spark的Shuffle有Hash Shuffle和Sort Shuffle两种。
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager。该ShuffleManager而HashShuffleManager有着一个非常严重的弊端,就是会产生大量的中间磁盘文件, 进而由大量的磁盘IO操作影响了性能。
因此在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager。 SortShuffleManager相较于 HashShuffleManager来说,有了一定的改进。主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件, 但 是最后会将所有的临时文件合并(merge)成一个磁盘文件, 因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
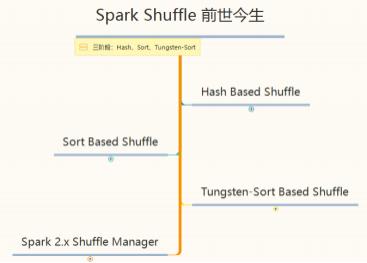
Hash Shuffle 了解
Shuffle阶段划分:
shuffle write: mapper阶段,上一个stage得到最后的结果写出
shuffle read: reduce阶段,下一个stage拉取上一个stage进行合并
1)未经优化的hashShuffleManager:
HashShuffle是根据task的计算结果的key值的hashcode%ReduceTask来决定放入哪一个区分,这样保证相同的数据一定放入一个分区, Hash Shuffle过程如下:
根据下游的task决定生成几个文件,先生成缓冲区文件在写入磁盘文件,再将block文件进行合并。
未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。提出如下解决方案
2)经过优化的hashShuffleManager:
在shuffle write过程中, task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概 念,每个shuffleFileGroup会对应一批磁盘文件,每一个Group磁盘文件的数量与下游stage的task数量是相同的。

未经优化:
- 上游的task数量: m
- 下游的task数量: n
- 上游的executor数量: k (m>=k)
- 总共的磁盘文件: m*n
优化之后的:
- 上游的task数量: m
- 下游的task数量: n
- 上游的executor数量: k (m>=k)
- 总共的磁盘文件: k*n
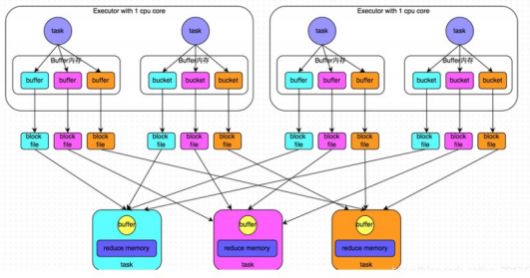
Sort Shuffle Manager 了解
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制, 另一种是bypass运行机制。当shuffle write task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用bypass机制。
( 1)该模式下,数据会先写入一个内存数据结构中(默认5M),此时根据不同的shuffle算子,可能选用不同的数据结 构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内 存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。 ( 2)接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话 ,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
( 3)排序
在溢写到磁盘文件之前, 会先根据key对内存数据结构中已有的数据进行排序。
(4)溢写
排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数 据的形式分批写入磁盘文件。
( 5) merge
一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之 前所有的临时磁盘文件都进行合并成1个磁盘文件,这就是merge过程。
由于一个task就只对应一个磁盘文件, 也就意味着该task为Reduce端的stage的task准备的数据都在这一个文件中, 因此还会单独写一份索引文件, 其中标识了下游各个task的数据在文件中的start offset与end offset。
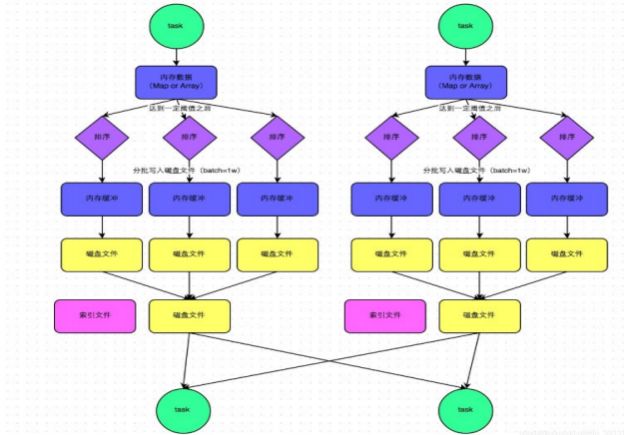
Sort Shuffle bypass机制
bypass运行机制的触发条件如下:
1)shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。
2)不是map combine聚合的shuffle算子(比如reduceByKey有map combie)。
bypass运行机制的触发条件如下:
1)shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。
2)不是map combine聚合的shuffle算子(比如reduceByKey有map combie)。
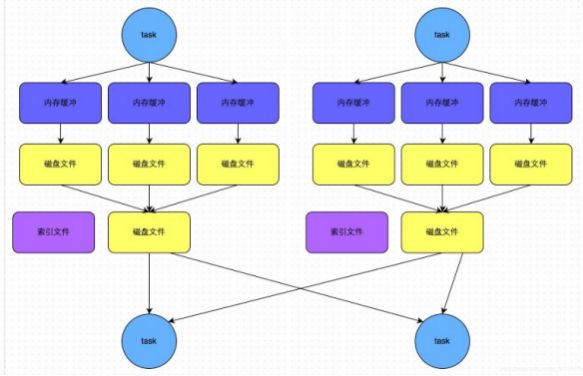
此时task会为每个reduce端的task都创建一个临时磁盘文件,并将数据按key进行hash,然后根据key的hash值,
将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager来说, shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:
- 第一,磁盘写机制不同;
- 第二,不会进行排序。也就是说,启用该机制的最大好处在于, shuffle write过程中,不需要进行数据的排序操作, 也就节省掉了这部分的性能开销。
总结:
SortShuffle也分为普通机制和bypass机制
普通机制在内存数据结构(默认为5M)完成排序,会产生2M个磁盘小文件。
而当shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。或者算子不是聚合类的
shuffle算子(比如reduceByKey)的时候会触发SortShuffle的bypass机制, SortShuffle的bypass机制不会进行排序 ,极大的提高了其性能。
Shuffle的配置选项
Shuffle阶段划分:
shuffle write: mapper阶段,上一个stage得到最后的结果写出
shuffle read: reduce阶段,下一个stage拉取上一个stage进行合并

以上是关于:Spark 内核调度的主要内容,如果未能解决你的问题,请参考以下文章