大数据问题排查系列 - TDH大数据平台中 HIVE作业长时间无法执行结束
Posted 明哥的IT随笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据问题排查系列 - TDH大数据平台中 HIVE作业长时间无法执行结束相关的知识,希望对你有一定的参考价值。
大数据问题排查系列 - TDH大数据平台中 HIVE作业长时间无法执行结束
前言
大家好,我是明哥!
本片博文是“大数据问题排查系列”之一,讲述某星环 TDH 大数据平台中,研发同学提交的 Hive 作业在成功提交后,客户端长时间收不到任何结果信息也收不到任何报错信息问题的排查。
以下是正文。
问题现象
研发同学反馈,提交的很多 Hive 作业在成功提交后,客户端长时间收不到任何结果信息也收不到任何报错信息,如下图所示,有的作业在提交 1.7h 后都没有执行结束,客户端没有收到任何结果信息,也没有收到任何报错信息。

问题初步分析
熟悉 CDH/HDP 大数据平台 或 apache 原生版 hive 的同学,有的可能遇到过上述 hive 作业长时间都没有执行结束且没有任何报错信息的情况,这通常是因为作业提交到的 yarn 队列没有足够的资源,hive 作业无法申请到足够的 yarn container 从而长时间无法执行结束。只要确保整个 yarn 集群和作业对应的 yarn 队列资源足够,且作业提交到了正确的 yarn 队列中,一般都可以修复问题。(当然,作业申请到了资源后,执行结果是成功还是失败是另外一回事)。
但是在 TDH 中,以上论断是不成立的。事实上,在 TDH 中,hive 作业跟本就不是运行在 YARN上的,跟本就不消耗任何 YARN 资源!
背景知识 - TDH 中,hive 作业的运行机制
星环的 TDH 大数据平台中的 HIVE,其正式名称是 Inceptor, 是基于早期的某个版本的开源的 Apache hive 改造得来的,其在底层做了大量魔改和优化,也 cherry pick 了开源 apache hive后续版本的很多先进功能,但其一致秉持的是闭源的路线,跟开源的 apache hive 的任何一个版本都没有严格的对应关系了!事实上,二者的很多参数都是不通用的,在底层的作业执行机制上也是不同的。
在 TDH 中,Inceptor 作业不是运行在 YARN 上,而是运行在 Inceptor 后台的一个 spark 集群中,且该 spark 集群是一个 standalone 模式的 spark 集群,本身也不占用任何 YARN资源!事实上,TDH 中在启动 Inceptor 服务时,就在背后将该 spark集群启动起来了,后续所有提交给 Inceptor 的作业都是运行在该 spark 集群中的!由于省去了提交作业后,申请资源,启动分布式多个JVM,执行作业,再销毁分布式多个JVM的时间开销,所以 Inceptor 中作业的执行速度会比 cdh/hdp/apache hive 中快很多,特别是在 SQL 底层对应大量小作业时更是如此。(当然了,双刃剑的另一面是,TDH中 inceptor 作业之间的资源隔离没有 cdh/hdp/apache hive中做的好)。
从原理上想想,这其实也是对空间换时间和预计算的一种实现吧。
如下图所示,Inceptor 底层有多个服务角色:
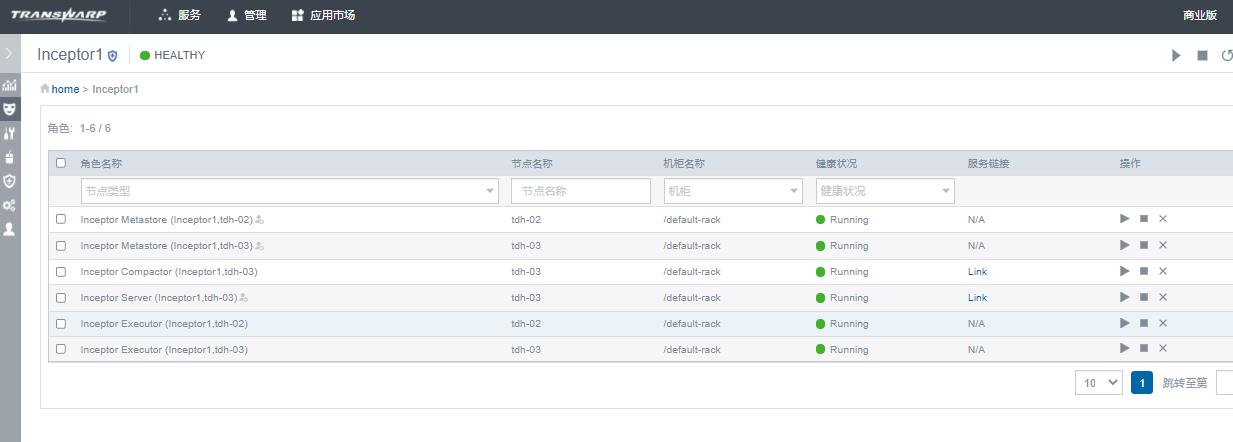
Inceptor 底层有服务角色跟开源版本的服务角色的对应关系,如下表所示:
| TDH服务角色 | 开源版对应服务角色 | 说明 |
|---|---|---|
| Inceptor metastore | hive metastore | 元数据服务,底层数据库使用RDBMS如mysql,Inceptor中底层数据库是基于mysql的TxSql |
| Inceptor server | HiveServer2 + spark driver | beeline 或其它客户端提交sql到该服务 |
| Inceptor Executor | spark executor | 执行sql作业底层任务的worker |
| Inceptor Compactor | NA | 可选,负责后台小文件合并 |
问题原因
知道了 TDH 中 Inceptor 作业的执行机制,我们就知道应该查看哪些 WEB UI,应该查看哪些服务角色的日志了。
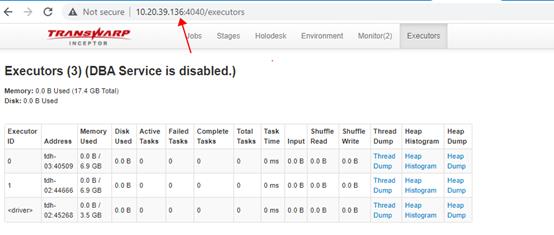
首先查看 Inceptor server 的 webui, 熟悉 Spark 的小伙伴会发现,该 webui 跟 spark 的 webui 很像, 如下图所示:

细心的小伙伴能够发现,上图中 executors 页面只有一个driver, 没有任何 executor! 我们对比下正常的 Inceptor server 的 webui 中 executors 页面,是可以看到注册成功的 executors 的。
我们接下来查看下该集群中都安装了哪些服务角色,如下图所示,可以看到该集群中安装了两个 inceptor metastore, 两个 Inceptor server, 两个 Inceptor executor, 和一个 Inceptor compactor:

接着查看 Inceptor server 日志,发现有报错信息:Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient memory, 即作业没有获得任何资源!

接着查看 Inceptor executor 日志,可以发现两个 executor 都注册到了tdh-02节点!


至此,问题就比较清晰了: 集群中安装了两个 Inceptor server(对应hiveserver2+spark deriver),分别在tdh-02和tdh-03节点;然后集群中只有两个 Inceptor executor (对应 spark executor) 且都注册到了 tdh-02 节点的 Inceptor server, 所以 tdh-03 节点的 Inceptor server 没有掌控任何 Inceptor executor, 刚好用户提交 SQL 到了 tdh-03 节点的 Inceptor server,所以因没有任何 executor 资源而长时间无法执行且没有任何报错!
事实上,熟悉 spark 的小伙伴们,会留意到,当 spark standalone 集群中只有 master 没有 worker时(比如 worker进程因故障异常退出),客户端是能够成功提交作业的,但提交的作业一样会因为申请不到 executors 资源而长时间无法运行结束且不会返回任何信息,跟上述现象是一致的。
问题解决
知道了以上的机制和原理,其实问题的解决就很简单了:让用户提交 SQL 到有inceptor executor 资源的 inceptor server 中即可!为避免混淆和简单起见,我们一般在 TDH 集群中只安装一个 Inceptor server!
所以我们删除了多余的 Inceptor server 服务角色,然后重启了 Inceptor 服务,此后作业成功执行,且仅仅花了几十毫秒!

ps. 我们知道 CDH 中是支持部署多个 HiveServer2 的,甚至可以结合 HA PROXY 做多个 hiveserver2 之间的 load balance,从而做到高可用和较高的并发相应;而从上述问题现象中可以看出,TDH 中似乎不能很好地处理这种部署多个 Inceptor server 的情况,因为 Inceptor Server 需要背后有 Inceptor executor才能正常对外提供服务,没有 Inceptor executor 的 Inceptor server 不但不能对外提供服务,反而容易引起用户混淆从而造成问题。
!关注不迷路~ 各种福利、资源定期分享!欢迎小伙伴们扫码添加明哥微信,后台加群交流学习。

以上是关于大数据问题排查系列 - TDH大数据平台中 HIVE作业长时间无法执行结束的主要内容,如果未能解决你的问题,请参考以下文章
大数据问题排查系列- 同样的HIVE SQL,在CDH与TDH平台执行效率差异的根本原因