TDH 8.0 使用必读 1 :为什么你需要存算解耦的多模型数据管理平台
Posted 资讯汇
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TDH 8.0 使用必读 1 :为什么你需要存算解耦的多模型数据管理平台相关的知识,希望对你有一定的参考价值。
引言
星环科技于2021年3月发布了星环极速大数据平台TDH的8.0版本。相信很多用户都对这款新产品非常感兴趣。
我们将用一系列文章,会向您逐一介绍最新发布的TDH 8.0全新功能和技术创新。帮助企业级数据平台用户更全面、深入地了解最新的大数据技术,更好地技术选型。
【视频号视频】
您也可以在星环科技官方视频号、星环社区服务号、以及bilibili、腾讯视频等站点看到我们的视频。
存算一体VS存算解耦
1983年甲骨文公司推出了第一代数据库产品。同一年,IBM公司推出了第二代数据库产品DB2。这些产品不局限于大型机上使用,也可以部署在小型机甚至PC上。当时的服务器硬件成本高昂,提供的算力和存储有限,网络互连的带宽十分有限。数据库产品集中在关系型数据库,集中处理高价值的数据。
为了及时响应事务和查询的需求,软件性能优化时,需要极致的压榨硬件性能。由于网络带宽的限制,多服务器间的信息交换十分受限。
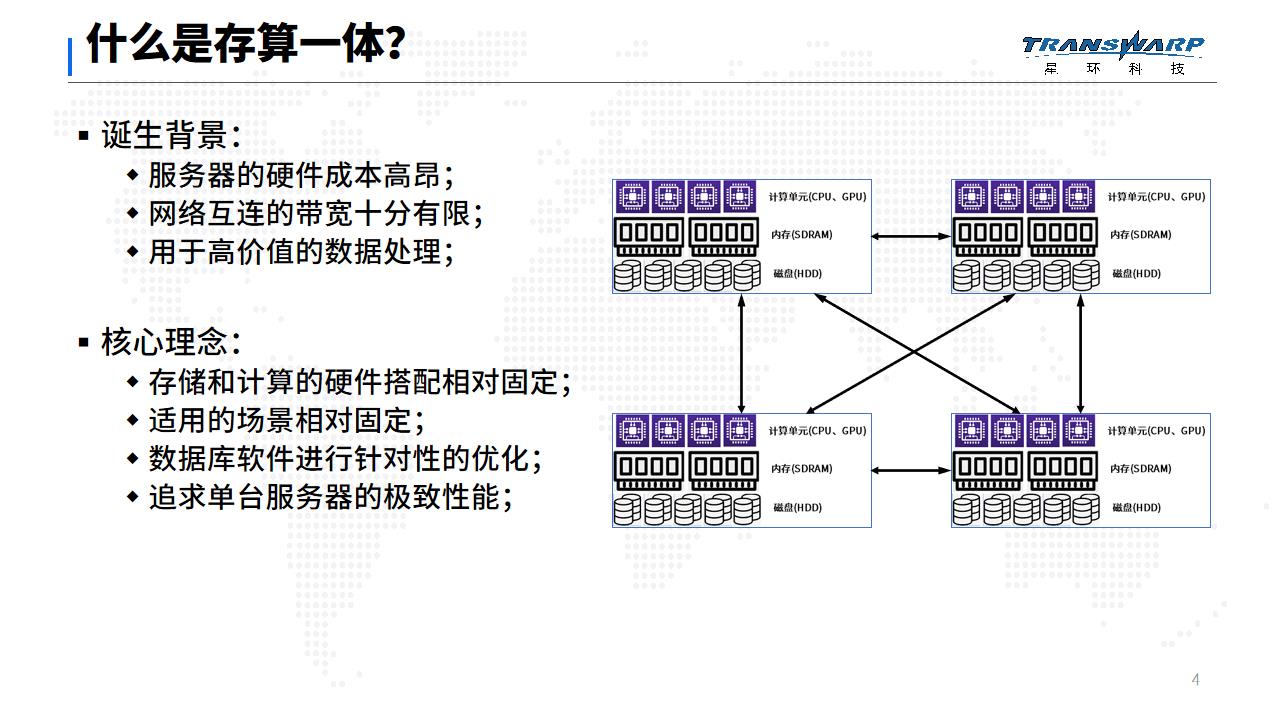
因此,重点考虑单服务器的CPU、内存、磁盘等计算和存储硬件在几种典型的固定配置下,进行针对性的极致优化。软件架构和算法,是存储与计算耦合在一起的。存算一体由此得名,其核心思想是通过存算一体达到性能上的极致优化。
接下来就来说说存算解耦。顾名思义,存算解耦将存储和计算解耦合,使存储和计算有各自相对的独立性。随着信息技术的发展,服务器的硬件成本逐渐下降,算力和存储容量不断增加,网络带宽增大,服务器间的数据交换效率不断提高。

存算解耦在软件架构上使用分布式的计算、分布式存储,确保计算和存储任务都能拆解成保持独立的小任务。在硬件方面,存算解耦对计算和存储单元的配置要求限制少,可以根据需要进行灵活的扩展。因此,存算解耦追求集群总体的高性价比。
计算机硬件、数据规模、用户需求的演变和存算解耦的主流化
回顾一下计算机硬件与网络的历史变迁。从二十世纪七八十年代到今天,计算机硬件的发展速度有目共睹。从1982年英特尔推出286 CPU,到现在的多核至强CPU,相同成本下的算力提升了百万倍以上。内存从几十几百KB,到兆B,到现在256G、512G,容量也有了百万倍的提升。永久存储从机械硬盘HDD,到固态硬盘SSD,再到闪存Flash Memory,容量和速度也有了大幅提升。网络速度和带宽也从几十KB每秒,提升到了今天服务器内网的千兆网、万兆网。
硬件成本的大幅降低,网络带宽的大幅提升,促使大家通过集群化部署,分布式的架构,集合多台服务器的计算和存储能力来解决复杂问题。一台服务器很难解决的问题,就考虑用多台服务器来解决,成为一种必然的趋势。
随着“大数据”概念被提出与实践,现在的一个企业或机构,往往要处理几十、几百TB数据,甚至PB级的数据也不罕见。

在数据规模指数级增长的同时,数据的价值密度也有了分级分层的趋势。不同价值密度的数据,选用的数据存储和计算方案会有差异。核心的数据,往往选用成本较高,但高性能、高可靠的方案。而外围的数据,往往选用成本较低,性能与可靠性稍弱一些的高性价比的方案。
在业务需求方面。早期,由于硬件成本和硬件性能的限制,客户理所当然的希望优先解决高价值核心场景。以“交易”为代表的擅长处理事务型的关系型数据库,首先取得了成功。
而到2010年前后,以Hadoop为代表的开源大数据极大的推动了新技术的发展。处理的数据从单一的结构化数据,到半结构化、非结构化数据也处理。场景方面,从交易型OLTP单一场景,到现在分析型OLAP场景,数据仓库,数据集市,实施计算,综合搜索,图计算图分析等多场景的联合。业务需求越来越多样化,就要求我们的方案能灵活的按需增减数据模型,按需增减分配计算和存储资源。
小结
由于硬件成本的降低,网络带宽的提高,数据量的指数级增长,数据按价值密度分层管理,以及业务场景的多样化发展等一系列市场趋势,用户对大数据和数据库平台在灵活扩展缩减资源,灵活增减数据模型等方面提出了更高的要求。用户从追求单一场景、单机数据库的极致性能,向着总拥有成本更低、总体方案更灵活高效,集群整体性价比更高的方向发展。

存算解耦方案相比与存算一体方案而言,虽然在单机性能方面稍弱一些,但是在硬件的通用性、硬件资源配置的灵活性、按需扩容缩容能力、数据存储均匀性自动化管理等多个方面有明显优势。因此,我们认为存算解耦技术是大势所趋,会成为技术的主流。
怎样的存算解耦能够满足当今用户的需求?
使用过开源产品的观众或多或少有这样的体会。面对明确单一场景数据量合适场景时,使用开源感觉也挺好。但到了需要多产品协同支持复杂的复合场景时,技术难度就大大增加。而如果业务还市场变化时,大数据平台的整体配置调优就更是一门技术活,一不小心就出妖蛾子,让人头晕脑涨。
正是看到了这种不便,我们星环大数据平台定位在服务多种客户场景和业务需求,支持的数据量从几十G、几百G到超过几百T、上PB的非常广泛的业务上。所以,灵活性是我们的存算解耦技术的核心目标。
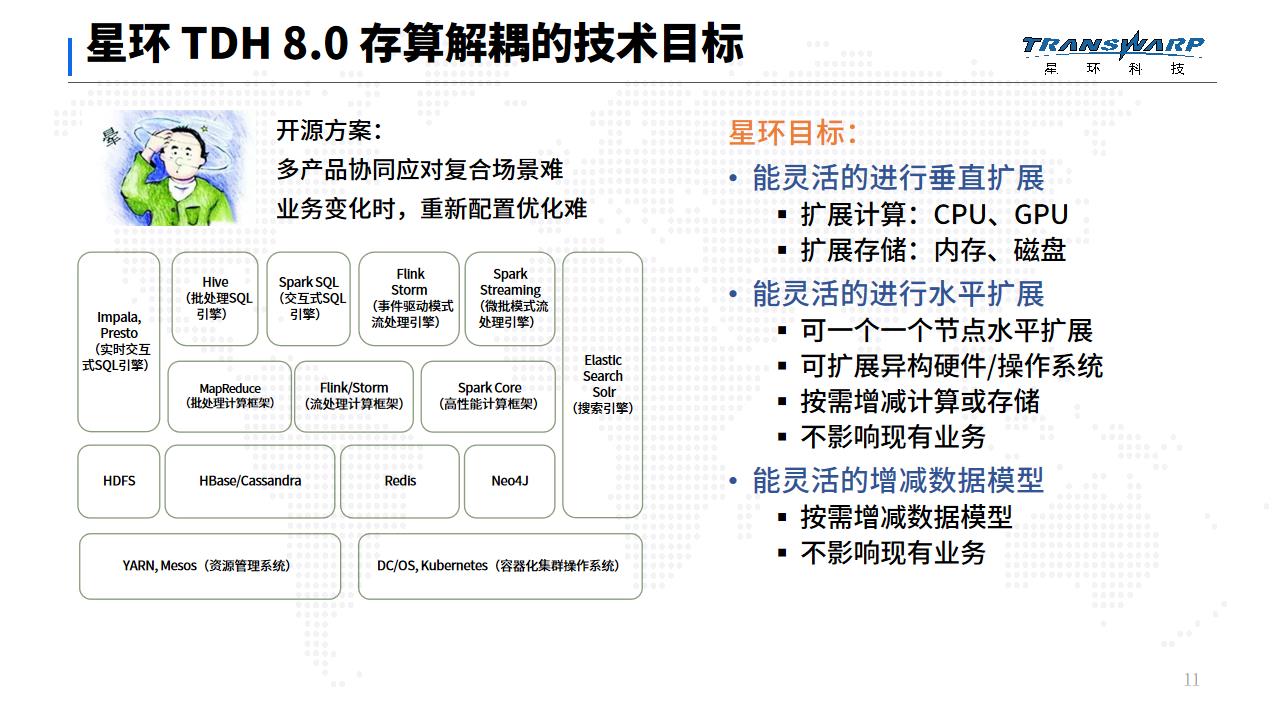
首先,我们要能灵活的进行垂直扩展。用户升级换代服务器时,无论是升级CPU、GPU等计算硬件,还是扩展内存、磁盘等存储硬件,或是计算存储同时升级扩展,我们的平台都能支持。
第二,我们要能灵活的进行水平扩展。不同的业务场景,数据量会因市场的变动,出现不同的增长和萎缩。从性价比而言,用户希望能按需进行水平扩容或缩容。有些MPP架构平台需要两个或三个节点一组为最小单位扩容缩容。我们的平台支持一个节点、一个节点的扩容缩容,方案更灵活。此外,我也支持异构操作系统、异构硬件的服务器在同一个集群中工作,让用户的水平扩展有更多的选择。
第三,我们要能灵活的增加减少数据模型,从而应对复杂多变的业务需求。在创新型的业务中,经常需要灵活的选择不同的查询字段和条件,探索性的进行跨项目、跨不明数据的关联分析和计算,再根据初步的结果决定是否要进一步的深入研究。
由于创新业务无法事先预测,让每个单一数据库预留足量存储和计算资源的方式显然不可取。根据业务按需扩展数据模型,统一在公共资源池中获取存对应的储计算资源,在业务结束后再将资源释放回公共资源池中。这种弹性的按需获取资源的方式显然更贴近业务复杂多变的用户需求。
有了明确的目标,接下来我们看看星环TDH 8.0是如何在技术实现存算解耦的。
TDH 8.0 的存算解耦实现路径
先来说说产品定位。星环 TDH 8.0 是企业级一站式大数据综合平台。
它提供了大数据存储、大数据分析、实时计算、综合搜索、数据挖掘等基础能力。能处理结构化、半结构化、非结构化数据,能处理实时数据和批量数据。
为企业建设数据湖、数据仓库、数据中台提供平台支撑,为企业数字化转型提供助力。客户进行数字化运营、数字化决策、数字营销等创新业务时,更为便捷。

星环TDH采用了分布式计算、分布式存储技术。平台创造性的采用了简明的五层技术架构来实现存算解耦。
这五层架构从下而上依次是资源调度层、存储管理层、存储引擎层、计算引擎层和计算接口层。每一层设计中都考虑了存算解耦的目标要求。
资源调度层 星环云原生操作系统TCOS
资源调度层,我们采用了统一的星环云原生操作系统TCOS(Transwarp Cloud Operating System)。这款生产级的云原生操作系统,基于容器技术Kubernetes构建。
提供了调度服务、网络服务、存储服务、负载管理、GPU管理以及多云管理等服务,满足了大数据分布式存储等有状态工作负载在编排、弹性、隔离、异构计算、多云等方面的多种需求。

在扩缩容方面,得益于 TCOS 强大的编排技术,我们平台的计算引擎和存储引擎都可以独立的弹性扩缩容。
在调度方面,原生的 Kubernetes 调度器无法满足我们平台的应用需求,因此关系型分析引擎Inceptor,使用大数据负载调度策略;实时流计算Slipstream,使用智能负载调度策略;分布式文件系统 TDFS,则使用存储负载调度策略。
此外,TCOS隔离了因服务器硬件架构、操作系统的异构带给计算、存储层的不必要麻烦。通过TCOS对硬件和操作系统的适配和优化,就可以让存储、计算代码工作在异构的服务器上。目前,我们支持X86、ARM、MIPS、Alipha等不同CPU架构的服务器,也支持CentOS、统信UOS、银河麒麟、中标麒麟等不同操作系统。客户可以将异构的服务器和操作系统部署在同一个集群中,扩展更加灵活,选择更加多样化。
存储管理层 统一的分布式文件系统和分布式数据管理系统
先来说说星环分布式文件系统,Transwarp Distributed File System,TDFS。
与开源方案相比,我们的方案充我们基于RAFT协议解决高可用问题,不再依赖Zookeeper等协调组件。同时,充分利用NVME存储介质的高性能,构建自己的元数据服务,解决HDFSNameNode的元数据规模瓶颈等相关问题。从而保障集群水平扩展能力向几百、几千节点规模演进。
再来说说星环分布式数据管理系统,Transwarp Distributed Data Management System,TDDMS。

如右下角图片所示,它分为Master和Tablet Server两部分。
Master采用3、5、7节点的RAFT Group保障高可用性。负责元信息管理,读写分离管理。Tablet Server负责数据分片与均匀分布管理,支持范围分片,哈希分片,支持分割与合并操作。
与开源方案笔,它也提高了节点上限到几百几千。读写分离保障了数据分布变动时,不会影响集群总体服务。而自动化的分布管理,在水平扩展时,无需数据重分布操作,也会影响集群服务,保障了持续服务能力。
存储引擎层,用8种存储引擎,支持10种数据模型
我们选择使用多种异构存储引擎,是因为统一的存储引擎并不能满足不同场景对高性能的要求。不同的场景的高性能保障仍然需要使用不同的数据结构,因此需要多种存储引擎。
我们也与多个数据库简单对接不同,将文件管理和分布式数据管理等公共部分进行了统一。这样做的好处是,一方面我们通过多种存储引擎保障了高性能,另一方面我们通过统一的存储管理,使得扩展不同的数据模型变得容易。

从用户的角度,一份数据,可能一开始只用来做批量分析,后来根据业务需要增加全文搜索,这时用户只需要操作同一个平台,增加一下搜索模型,产品就会扩展相应的计算、存储资源支持搜索。感受上一个产品拥有了多模型弹性扩展的能力,十分便捷。资源也是按需增减而不是长期预留,十分的经济高效。
统一的分布式计算引擎 Transwarp Nucleon
计算引擎方面,市场上许多方案使用针对不同场景使用不同计算引擎。而我们星环使用统一的计算引擎,各类算法都遵从一致的计算框架,从逻辑计划、逻辑优化,到物理计划、物理优化,再到执行引擎。

我们也使用了许多优化技术,包括:基于规则的优化、基于物化的优化、基于代价的优化、向量化执行引擎等等,不再一一详述。
之所以选用统一的计算引擎,就是让产品根据数据模型,自动选择最优算法、算子,保障高性能。而不是由用户人凭经验进行优化。
另一个好处,就是让跨库关联分析与计算变得十分方便,不再需要数据从一个库导入导出到另一个库。用户也不用担心数据模型切换影响计算,最大程度保障了计算弹性。
统一的SQL编译器 Transwarp Quark
最后,我们介绍一下计算接口层。星环开发了统一的SQL编译器Transwarp Quark,确保星环平台中的各个数据库产品遵从一致的SQL规范。支持标准SQL语法;支持标准JDBC、ODBC连接;支持标准Oracle、IBM DB2、Teradata语法方言;
客户即使切换了业务场景、切换了数据库,也不用担忧开发接口、编程语言不兼容的问题。使用统一的SQL,开发的代码可移植性强,技术对接成本低,开发人员学习成本低,能更好的应对复杂多变的业务需求。
总结
TDH 8.0 使用了简明的5层架构,包括:资源调度层、存储管理层、存储引擎层、计算引擎、计算接口层。

在技术实现上,架构中每个层次的技术,都重点考虑了存算解耦的技术目标,允许计算和存储独立扩展,允许用户灵活的进行水平扩展和垂直扩展。此外,还支持按需增减数据模型,使用统一SQL降低学习和迁移成本等。让用户应对各类业务变动时,轻松自如。
以上是关于TDH 8.0 使用必读 1 :为什么你需要存算解耦的多模型数据管理平台的主要内容,如果未能解决你的问题,请参考以下文章