Pytorch—SSD模型训练—步骤一:训练前的了解
Posted Esaka7
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch—SSD模型训练—步骤一:训练前的了解相关的知识,希望对你有一定的参考价值。
以下参考论文SSD: Single Shot MultiBox Detector
SSD:
SSD只需要一个输入图像和参考标准即可
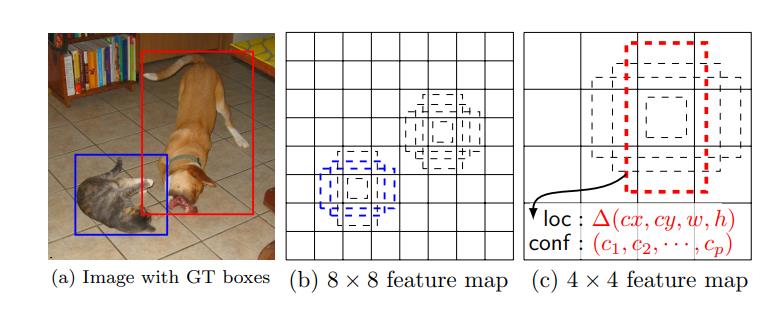
我们在特征地图中每个位置上评估了几个不同比例的默认框(8 × 8和4 × 4)
对于每个默认框,我们预测所有对象类别的形状偏移量和置信度((c1, c2,···,cp))
在训练时,我们首先将这些默认框与参考标准进行匹配
例如,我们将两个默认的盒子分别与猫和狗进行了匹配
模型损失是一个在定位损失(如L1)和置信度损失(如Softmax)之间的加权和
SSD方法基于前馈卷积网络,生成一个固定大小的包围盒集合,并为这些盒中存在的对象类实例评分,然后根据非极大值抑制(Non-Maximum Suppression),以产生最终检测。
PS:非极大值抑制(Non-Maximum Suppression),目标检测的过程中在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,此时我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
Multi-scale feature maps for detection(多尺度特征图检测)
我们在截断的基础网络的末端添加了卷积特征层。这些层的大小逐渐减少,并允许在多个尺度上预测探测。对于每个特征层,预测检测的卷积模型是不同的
Convolutional predictors for detection(用于检测的卷积预测器)
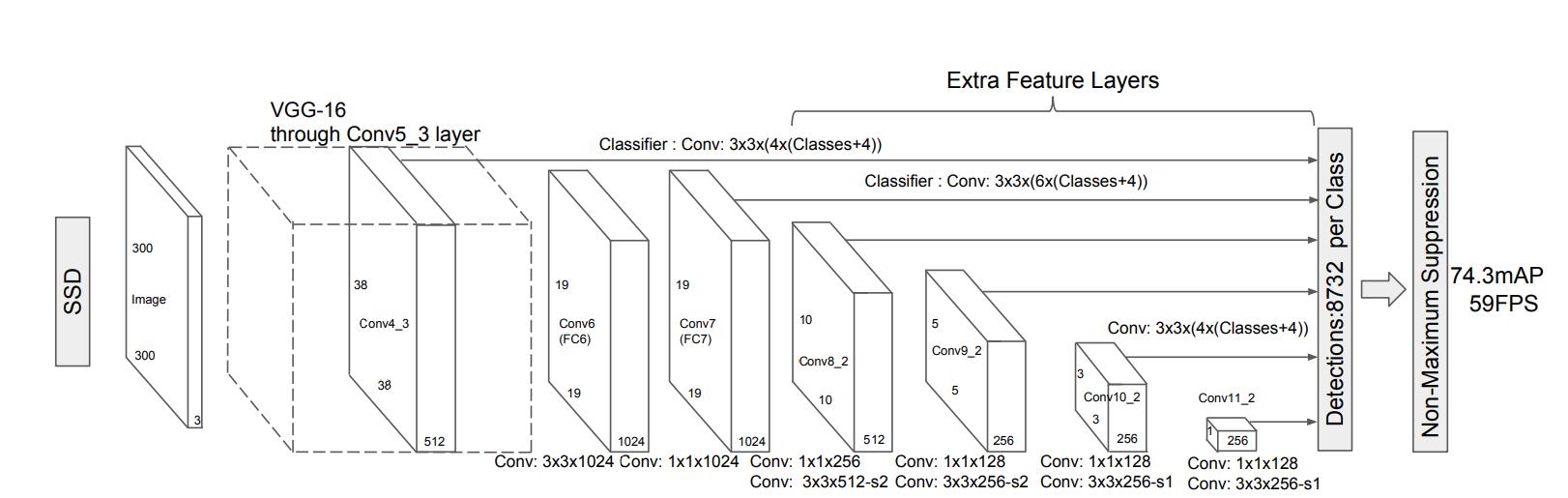
每一个添加的特征层(或可选的来自基础网络的现有特征层)都可以使用一组卷积过滤器产生一组固定的检测预测。这些都显示在SSD网络架构之上。对于大小为m × n、有p个通道的特征层,预测潜在检测参数的基本元素是一个3 × 3 × p的小核,它产生一个类别得分,或相对于默认框坐标的形状偏移。在每个m × n的位置应用核,它产生一个输出值。
我们的SSD模型在基础网络的末端添加了几个特征层,这些特征层可以预测不同规模、宽高比和相关置信度的默认框的偏移量。在VOC2007测试中,300 × 300输入尺寸的SSD在准确性上显著优于其448 × 448YOLO对应版本,同时也提高了速度
Default boxes and aspect ratios(默认框和宽高比)
对于网络顶部的多个特征图,我们将一组默认的边界框与每个特征图单元关联起来。默认的盒子以一种卷积的方式平铺特征图,这样每个盒子相对于它相应的单元格的位置是固定的。在每个特征映射单元格中,我们预测相对于单元格中默认框形状的偏移量,以及在每个框中存在类实例的每个类得分。具体来说,对于给定位置k之外的每个方框,我们计算c类得分和相对于初始默认方框形状的4个偏移量。这将导致在特征图的每个位置周围应用的(c + 4)k个滤波器,会生成m × n特征图的(c + 4)kmn输出。
Training:
训练SSD和训练使用区域建议的典型检测器之间的关键区别是,参考信息需要分配到检测器输出的固定集合中的特定输出。
Matching strategy(匹配策略)
在训练期间,我们需要确定哪些默认框和参考目标有联系,并相应地训练网络。对于每个参考目标,我们从默认框中选择,这些默认框会根据位置、宽高比和比例变化。我们首先将每个参考目标匹配到具有最佳jaccard overlap的默认box(如MultiBox[7])。与MultiBox不同的是,我们将默认框匹配到所有具有大于阈值(0.5)的jaccard overlap的参考目标。这简化了学习问题,允许网络预测多个重叠默认框的高分,而不是只选择最大重叠的那个。
jaccard overlap:

Training objective
总体目标损失函数为定位损失(loc)和置信度损失(conf)的加权和:
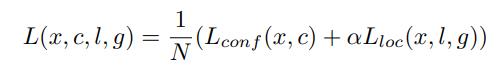
设
x
i
j
p
x^p_{ij}
xijp={
0
,
1
0,1
0,1}是匹配类别p的第i个默认框和第j个参考目标框的指示符。所以
∑
i
x
i
j
p
\\sum_ix_{ij}^p
∑ixijp>=1
其中N是匹配的默认框数。如果N = 0,设置损失为0。
L
l
o
c
L_{loc}
Lloc定位损耗在预测框(l)和参考框(g)参数之间为平滑L1损耗。我们回归到默认边界框(d)的中心(cx, cy)以及它的宽度(w)和高度(h)的偏移量
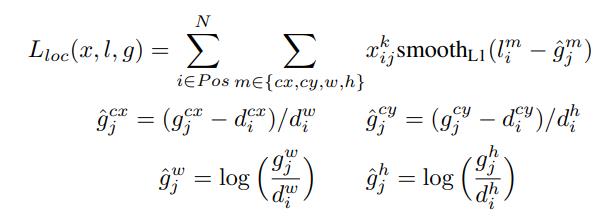
置信损失是多个类的置信( c )上的softmax损失。
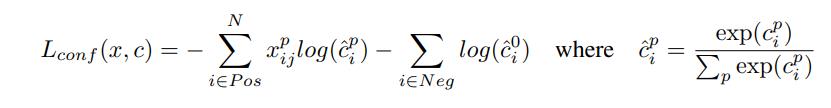
通过交叉验证将权重项α设为1。
Choosing scales and aspect ratios for default boxes(为默认框选择比例和宽高比)
为了处理不同的目标尺度,建议对图像进行不同大小的处理,然后将结果进行合并。然而,通过利用单一网络中不同层次的特征图进行预测,我们可以模拟相同的效果,同时还可以共享所有对象尺度的参数。以往的研究表明,使用较低层的特征图可以提高语义分割的质量,因为较低层能捕获输入对象的更多细节。同样,从特征图中加入全局上下文池可以帮助平滑分割结果。
在这些方法的推动下,我们同时使用上下特征图来检测。上图显示了框架中使用的两个示例特性映射(8×8和4×4)。在实践中,我们可以用较小的计算开销使用更多。
已知来自网络内不同层次的特征图具有不同的(经验的)接受域大小。幸运的是,在SSD框架中,默认框不需要对应每一层的实际接收字段。我们设计了默认盒子的平铺,以便特定的特征地图能够对特定的物体比例做出响应。假设我们要使用m个特征图进行预测。每个feature map的默认方框的比例计算为:
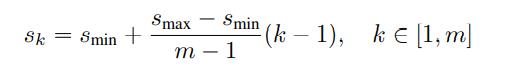
其中
s
m
i
n
s_{min}
smin是0.2,
s
m
a
x
s_{max}
smax是0.9,这意味着最低层的比例为0.2,最高层的比例为0.9,中间各层之间的间隔是有规律的。我们对默认框施加不同的长宽比,并将它们表示为ar∈{
1
,
2
,
3
,
1
/
2
,
1
/
3
1,2,3,1/2,1/3
1,2,3,1/2,1/3},我们可以计算每个默认框的宽度(
W
k
a
=
s
k
a
r
W_k^a = s_k\\sqrt{a_r}
Wka=skar)和高度(
H
k
a
=
s
k
/
a
r
H_k^a = s_k/\\sqrt{a_r}
Hka=sk/ar)。对于宽高比为1的情况,我们还添加了一个默认的比例为
s
k
′
=
s
k
s
k
+
1
s_k^{'}= \\sqrt{s_ks_{k+1}}
sk′=sksk+1导致每个特征地图位置有6个默认方框
我们将每个默认框的中心设置为(
i
+
0.5
∣
f
k
∣
,
j
+
0.5
∣
f
k
∣
\\frac{i+0.5}{|f_k|},\\frac{j+0.5}{|f_k|}
∣fk∣i+0.5,∣fk∣j+0.5),其中|fk|为第k个正方形特征映射的大小 i, j∈[0,|fk|)
在实践中,还可以设计默认框的分布,以最适合特定的数据集
通过结合许多特征地图的所有位置的不同比例和宽高比的所有默认框的预测,我们有了一套不同的预测,涵盖了各种输入对象的大小和形状。例如,在图1中,狗被匹配到4 × 4特征图中的一个默认框,而没有匹配到8 × 8特征图中的任何默认框。这是因为这些盒子有不同的规模并且不匹配的狗的盒子,因此被认为是消极的训练。
Hard negative mining
在匹配步骤之后,大多数默认框都是负数,特别是当可能的默认框的数量很大时。这在积极和消极的训练例子之间引入了严重的不平衡。我们不使用所有的负面例子,而是使用每个默认框的最高置信度损失来排序,并选择最上面的,这样消极和积极的比例最多为3:1。我们发现,这将导致更快的优化和更稳定的训练。
Data augmentation(数据增强)
为了使模型对不同的输入对象大小和形状具有更强的鲁棒性,每个训练图像都被以下选项之一随机采样:
-使用整个原始输入图像。
-采样一个补丁,使 jaccard overlap的对象是0.1,0.3,0.5,0.7或0.9。
-随机采样一个补丁。
每个采样patch的大小为原始图像大小的[0.1,1],长宽比介于1和2之间。如果参考样例的中心在采样的patch中,我们保留参考样例的重叠部分。在上述采样步骤之后,每个采样的补丁大小调整为固定大小,并以0.5的概率水平翻转,此外还应用一些类似于photo-metric deformation。
以上是关于Pytorch—SSD模型训练—步骤一:训练前的了解的主要内容,如果未能解决你的问题,请参考以下文章