Pytorch模型训练&保存/加载(搭建完整流程)
Posted 'or 1 or 不正经の泡泡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch模型训练&保存/加载(搭建完整流程)相关的知识,希望对你有一定的参考价值。
文章目录
前言
我们这边还是以CIARF10这个模型为例子。
现在的话先说明一下,关于CIARF10的一个输出
这个是一个十分类的模型,所以输出结果是一个矩阵一个tensor其中它的shape是你的(batch_size,10)这样的结果。假设你的batch_size = 1
那么你得到的结果应该是[[1,2,3,4,5,6,7,8,9,10]]这种类型的。你的输入的标签是这样的[ 9 ]
所以,如果你想要判断你的结果,你只需要看看这个输出的列表里面最大的那个数字的下标,这里是9,刚好和我们的这个标签的数值一样,那么预测正确。在pytorch里面提供了一个方法,叫做argmax(1)表示横向获得最大值的下标,argmax(0)表示纵向。所以用这种方法我们可以去获取我们训练的一个准确度。
模型训练完整步骤
我们的训练集一般时分两个部分的,一个是专门拿给你训练的,一个是专门用来做验证的。当然你自己定义的数据集也一样类似。
总之需要两个部分,验证的那个部分的不要进入训练网络就行。
完整代码如下:有注释
import torchvision
from torch import nn
import torch
from torch.utils.data import DataLoader
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, CrossEntropyLoss
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
trans = transforms.Compose([transforms.ToTensor()])
#获取训练集
dataset = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=trans,download=True)
dataset2 = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=trans,download=True)
train_dataloader = DataLoader(dataset,batch_size=64)
test_dataloader = DataLoader(dataset2,batch_size=64)
test_len = len(dataset2)
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.model = Sequential(
Conv2d(3, 32, kernel_size=(5, 5), padding=2),
MaxPool2d(2),
Conv2d(32, 32, (5, 5), padding=2),
MaxPool2d(2),
Conv2d(32, 64, (5, 5), padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
writer = SummaryWriter()
mymodule = MyModule()
loss = torch.nn.CrossEntropyLoss()
learnstep = 0.01
optim = torch.optim.SGD(mymodule.parameters(),lr=learnstep)
epoch = 1000
train_step = 0 #每轮训练的次数
mymodule.train()#模型在训练状态
for i in range(epoch):
print("第轮训练".format(i+1))
train_step = 0
for data in train_dataloader:
imgs,targets = data
outputs = mymodule(imgs)
result_loss = loss(outputs,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
train_step+=1
if(train_step%100==0):
print("第轮的第次训练的loss:".format((i+1),train_step,result_loss.item()))
# 在测试集上面的效果
mymodule.eval() #在验证状态
test_total_loss = 0
right_number = 0
with torch.no_grad(): # 验证的部分,不是训练所以不要带入梯度
for test_data in test_dataloader:
imgs,label = test_data
outputs_ = mymodule(imgs)
test_result_loss=loss(outputs_,label)
right_number += (outputs_.argmax(1)==label).sum()
# writer.add_scalar("在测试集上的准确率",(right_number/test_len),(i+1))
print("第轮训练在测试集上的准确率为".format((i+1),(right_number/test_len)))
if((i+1)%500==0):
# 保存模型
torch.save(mymodule.state_dict(),"mymodule_.pth".format((i+1)))
模型保存与加载
模型的保存的话很简单,这里主要有两种方法。
一个是直接把模型和是训练好的数据也保存。
torch.save(yourmodlue,path)
modlue = torch.load(path)
第二个方法是保存数据,你把数据加载到你的模型里面就行
torch.save(yourmodlue.state_dict(),path)
modlue.load_state_dict(torch.load(path))
GPU训练
首先说一下的是哪些东西可以放置GPU上面
模型,数据,损失函数
只要是你一点,后面有cuda()这个提示的就可以~前提是你得先判断一下是不是可以在GPU上面跑,也就是你的本地环境行不行。
torch.cuda.is_available()
于是代码改成了这样
import torchvision
from torch import nn
import torch
from torch.utils.data import DataLoader
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential, CrossEntropyLoss
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
trans = transforms.Compose([transforms.ToTensor()])
#获取训练集
dataset = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=trans,download=True)
dataset2 = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=trans,download=True)
train_dataloader = DataLoader(dataset,batch_size=64)
test_dataloader = DataLoader(dataset2,batch_size=64)
test_len = len(dataset2)
if(torch.cuda.is_available()):
device = torch.device("cuda")
print("使用GPU训练中:".format(torch.cuda.get_device_name()))
else:
device = torch.device("cpu")
print("使用CPU训练")
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.model = Sequential(
Conv2d(3, 32, kernel_size=(5, 5), padding=2),
MaxPool2d(2),
Conv2d(32, 32, (5, 5), padding=2),
MaxPool2d(2),
Conv2d(32, 64, (5, 5), padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
writer = SummaryWriter()
mymodule = MyModule()
mymodule = mymodule.to(device) #模型转移GPU
loss = torch.nn.CrossEntropyLoss()
learnstep = 0.01
optim = torch.optim.SGD(mymodule.parameters(),lr=learnstep)
epoch = 1000
train_step = 0 #每轮训练的次数
mymodule.train()#模型在训练状态
for i in range(epoch):
print("第轮训练".format(i+1))
train_step = 0
for data in train_dataloader:
imgs,targets = data
imgs = imgs.to(device)
targets =targets.to(device)
outputs = mymodule(imgs)
result_loss = loss(outputs,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
train_step+=1
if(train_step%100==0):
print("第轮的第次训练的loss:".format((i+1),train_step,result_loss.item()))
# 在测试集上面的效果
mymodule.eval() #在验证状态
test_total_loss = 0
right_number = 0
with torch.no_grad(): # 验证的部分,不是训练所以不要带入梯度
for test_data in test_dataloader:
imgs,label = test_data
imgs = imgs.to(device)
label = label.to(device)
outputs_ = mymodule(imgs)
test_result_loss=loss(outputs_,label)
right_number += (outputs_.argmax(1)==label).sum()
# writer.add_scalar("在测试集上的准确率",(right_number/test_len),(i+1))
print("第轮训练在测试集上的准确率为".format((i+1),(right_number/test_len)))
if((i+1)%500==0):
# 保存模型
torch.save(mymodule.state_dict(),"mymodule_.pth".format((i+1)))
然后我们简单地,测试一下,也就是跑一下
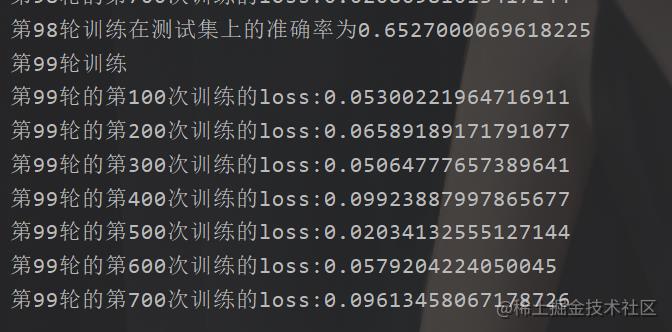
这个速度,不行,得训练到猴年马月。
“借鸡生蛋“
自家电脑哪里顶得住这个。
我们还是直接使用谷歌的平台吧,这个得那啥~只要有谷歌账号就是免费的。
而且是国外的,一些数据集下载贼快
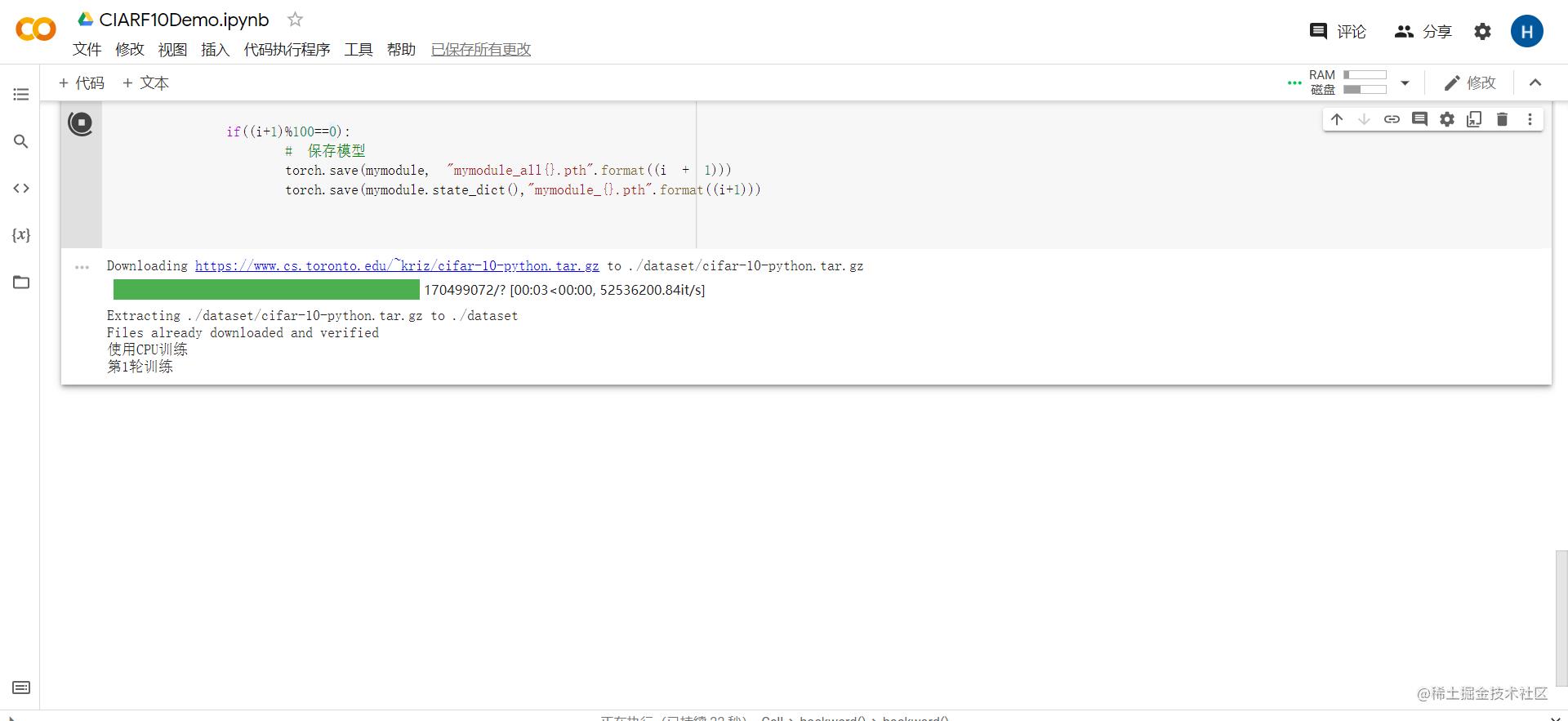
然后睡一觉就好了。
模型使用
这个其实和我们校验的时候使用一样,我们主需要调用我们的模型,然后把你的图片搞进去。

这个是我们对于的那个下标的动物。
from PIL import Image
import torchvision
import torch
from MyModule import MyModule
path_img = "dog.jpg"
image = Image.open(path_img)
compose = torchvision.transforms.Compose([
torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()
])
#看你是那种保存的模型
module_path = "mymodule_500.pth"
image = compose(image)
module = MyModule()
module.load_state_dict(torch.load("mymodule_500.pth"))
image = torch.reshape(image,(1,3,32,32))
module.eval()
with torch.no_grad():
out = module(image)
print(out.argmax(1))
然后我们可以看到输出
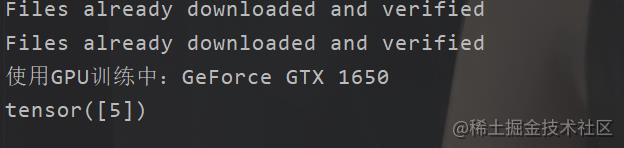
然后我这边也是下载了一张图片

不过值得一提的是,我这里训练了500次的模型只是得到了62%左右的准确率
那么后面我就可以跟换数据集,对神经网络进行稍微调整~实现不同的目的。
此外我们还有很多神经网络模型,例如 VGG,那个层数太多了,而且官方有封装好了的,就在torchvision里面。
以上是关于Pytorch模型训练&保存/加载(搭建完整流程)的主要内容,如果未能解决你的问题,请参考以下文章