二叉树13:二叉树的所有路径
Posted 纵横千里,捭阖四方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了二叉树13:二叉树的所有路径相关的知识,希望对你有一定的参考价值。
LeetCode257:给定一个二叉树,返回所有从根节点到叶子节点的路径。

1.深度优先的递归写法
深度优先搜索就是从根节点开始,一直往左子节点走,直到左子节点为空,让后返回到上一步从右子节点在执行同样的操作,就像下面图中这样:
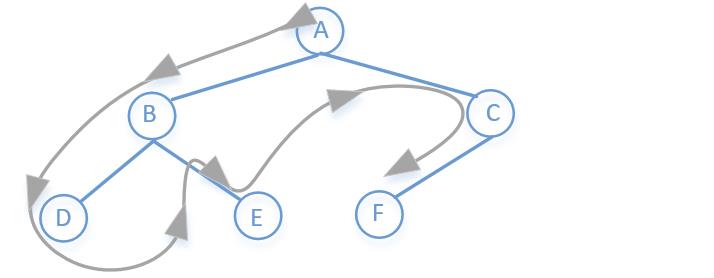
二叉树的深度优先搜索代码如下:
public static void treeDFS(TreeNode root) {
//当前节点为空直接返回
if (root == null)
return;
//打印当前节点的值
System.out.println(root.val);
//然后递归遍历左右子节点
treeDFS(root.left);
treeDFS(root.right);
}
我们完全可以仿照上面的代码来写,不同的是每个节点访问的时候不是把他打印出来,而是先把他存储起来,到叶子结点的时候再添加到集合中,最后返回集合的值
public List<String> binaryTreePaths(TreeNode root) {
List<String> res = new ArrayList<>();
dfs(root, "", res);
return res;
}
private void dfs(TreeNode root, String path, List<String> res) {
//如果为空,直接返回
if (root == null)
return;
//如果是叶子节点,说明找到了一条路径,把它加入到res中
if (root.left == null && root.right == null) {
res.add(path + root.val);
return;
}
//如果不是叶子节点,在分别遍历他的左右子节点
dfs(root.left, path + root.val + "->", res);
dfs(root.right, path + root.val + "->", res);
}
2.深度优先的迭代写法
深度优先搜索的非递归写法可以使用一个栈来实现,代码如下
public static void treeDFS(TreeNode root) {
Stack<TreeNode> stack = new Stack<>();
stack.add(root);
while (!stack.empty()) {
TreeNode node = stack.pop();
System.out.println(node.val);
if (node.right != null) {
stack.push(node.right);
}
if (node.left != null) {
stack.push(node.left);
}
}
}
我们也可以参照这种方式来写:
public List<String> binaryTreePaths(TreeNode root) {
List<String> res = new ArrayList<>();
if (root == null)
return res;
//栈中节点和路径都是成对出现的,路径表示的是从根节点到当前
//节点的路径,如果到达根节点,说明找到了一条完整的路径
Stack<Object> stack = new Stack<>();
//当前节点和路径同时入栈
stack.push(root);
stack.push(root.val + "");
while (!stack.isEmpty()) {
//节点和路径同时出栈
String path = (String) stack.pop();
TreeNode node = (TreeNode) stack.pop();
//如果是根节点,说明找到了一条完整路径,把它加入到集合中
if (node.left == null && node.right == null) {
res.add(path);
}
//右子节点不为空就把右子节点和路径压栈
if (node.right != null) {
stack.push(node.right);
stack.push(path + "->" + node.right.val);
}
//左子节点不为空就把左子节点和路径压栈
if (node.left != null) {
stack.push(node.left);
stack.push(path + "->" + node.left.val);
}
}
return res;
}
3.广度优先
BFS是一层一层的遍历的,就像下面这样
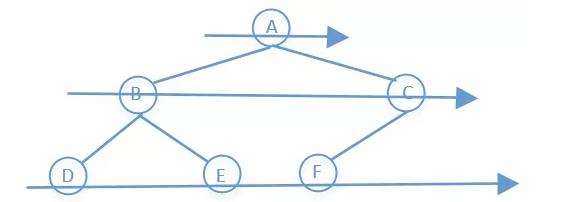
BFS的代码如下:
public static void levelOrder(TreeNode tree) {
if (tree == null)
return;
Queue<TreeNode> queue = new LinkedList<>();
queue.add(tree);//相当于把数据加入到队列尾部
while (!queue.isEmpty()) {
//poll方法相当于移除队列头部的元素
TreeNode node = queue.poll();
System.out.println(node.val);
if (node.left != null)
queue.add(node.left);
if (node.right != null)
queue.add(node.right);
}
}
我们来参照这种方式来写一下:
public List<String> binaryTreePaths(TreeNode root) {
List<String> res = new ArrayList<>();
if (root == null)
return res;
//队列,节点和路径成对出现,路径就是从根节点到当前节点的路径
Queue<Object> queue = new LinkedList<>();
queue.add(root);
queue.add(root.val + "");
while (!queue.isEmpty()) {
TreeNode node = (TreeNode) queue.poll();
String path = (String) queue.poll();
//如果到叶子节点,说明找到了一条完整路径
if (node.left == null && node.right == null) {
res.add(path);
}
//右子节点不为空就把右子节点和路径存放到队列中
if (node.right != null) {
queue.add(node.right);
queue.add(path + "->" + node.right.val);
}
//左子节点不为空就把左子节点和路径存放到队列中
if (node.left != null) {
queue.add(node.left);
queue.add(path + "->" + node.left.val);
}
}
return res;
}
无论是DFS还是BFS,最终都会把所以的结点都遍历一遍,遍历到每个节点的时候我们要把这个节点和从根节点到当前节点的路径都存储起来,等到达叶子节点的时候再把路径加入到集合中
4.根据左右子树的特征递归实现
我们来思考这样一个问题,如果我知道了左子树和右子树的所有路径,我们在用根节点和他们连在一起,是不是就是从根节点到所有叶子节点的所有路径,所以这里最容易想到的就是递归
代码如下:
public List<String> binaryTreePaths(TreeNode root) {
List<String> res = new LinkedList<>();
if (root == null)
return res;
//到达叶子节点,把路径加入到集合中
if (root.left == null && root.right == null) {
res.add(root.val + "");
return res;
}
//遍历左子节点的路径
for (String path : binaryTreePaths(root.left)) {
res.add(root.val + "->" + path);
}
//遍历右子节点的路径
for (String path : binaryTreePaths(root.right)) {
res.add(root.val + "->" + path);
}
return res;
}
以上是关于二叉树13:二叉树的所有路径的主要内容,如果未能解决你的问题,请参考以下文章