Python爬虫:通过爬取CSDN博客信息,学习lxml库与XPath语法
Posted 李元静
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫:通过爬取CSDN博客信息,学习lxml库与XPath语法相关的知识,希望对你有一定的参考价值。

目录
lxml库
lxml是Python的一个解析库,专门用于解析XML与html,支持XPath解析方式。由于lxml库的底层是使用C语言编写的,所以其解析效率非常的高。
在我们后面讲解使用该库之前,我们需要安装该库。一般通过如下命令进行安装即可,代码如下:
pip install lxml
lxml基本用法
既然,lxml库支持解析XML以及HTML,那么肯定就需要学会这2种文档的解析方式。下面,我们来分别讲解。
解析XML文件
首先,我们需要使用lxml库解析XML文件,这里XML文件其实有很多种类,这里博主随便定义一个XML进行解析。
XML代码如下:
<?xml version="1.0" encoding="utf-8"?>
<people>
<zhangsan class="法外狂徒">
<sex>男</sex>
<age>21</age>
</zhangsan>
<lisi class="法外狂徒的伙伴">
<sex>男</sex>
<age>21</age>
</lisi>
</people>
解析示例代码如下所示:
from lxml import etree
tree = etree.parse("lxml_xml.xml")
print(str(etree.tostring(tree, encoding='utf-8'), 'utf-8'))
root = tree.getroot()
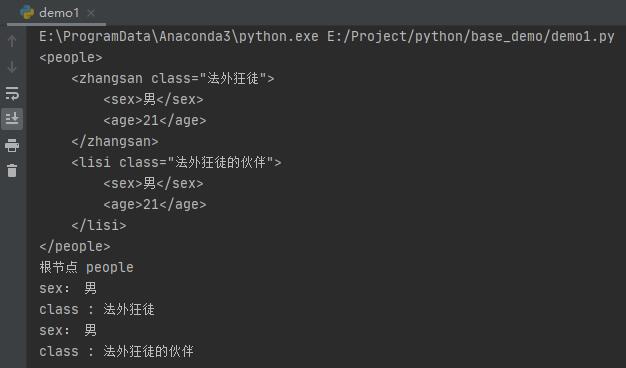
print("根节点", root.tag)
children = root.getchildren()
for child in children:
print("sex:", child[0].text)
print("class :", child.get('class'))
运行之后,效果如下所示:
解析HTML文件
解析HTML比XML稍微复杂一点,它需要创建一个HTMLParser()对象传入到parser()方法中,因为其默认是解析XML的。
HTML代码如下:
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="utf-8">
<title>我是一个测试页面</title>
</head>
<body>
</body>
</html>
解析代码如下所示:
from lxml import etree
parser = etree.HTMLParser()
tree = etree.parse('demo.html', parser)
root = tree.getroot()
result = etree.tostring(root, encoding='UTF-8', pretty_print=True, method='html')
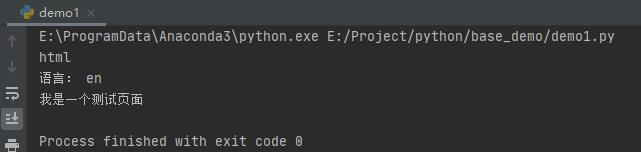
print(root.tag)
children = root.getchildren()
print("语言:", children[0].get('lang'))
print(root[0][1].text)
运行之后,效果如下所示:
XPath
估计细心的小伙伴,已经看出lxml库直接使用的弊端了。因为这是小编写的一个简单的HTML与XML,所以它的层级很低。
如果是真实的网页,那么可能层级会很多,如果还按数组这样一层一层往下查找,估计能搞出个十几维的数组。这样太复杂了。
所以,这里我们需要引入XPath进行辅助解析。
什么是XPath
XPath于1991年11月6日称为W3C标准,它被设计为可以在XSLT、XPointer以及其他XML解析软件中使用,其中文文档为:
https://www.w3school.com.cn/xpath/index.asp
XPath全称XML Path Language,中文叫XML路径语言,它是一种在XML文档中查询信息的语言。
最初虽然只支持XML文件,但是后来随着版本的迭代,已经可以支持HTML文件的解析与搜索,因为HTML与XML同源。
XPath语法
XPath语言的基本语法就是多级目录的层级结构,但比数组那种容易理解的多。下表是博主归纳总结的XPath语法规则:
| 语法 | 意义 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父亲节点 |
| @ | 选取属性 |
XPath实战
既然,我们已经了解XPath具体的语法结构,那么我们将一一实战这些语法,让读者更清晰,更快捷的掌握。
测试HTML文件如下所示:
<!DOCTYPE html>
<html>
<head lang="en">
<meta charset="utf-8">
<title>我是一个测试页面</title>
</head>
<body>
<ul>
<li><a href="https://liyuanjinglyj.blog.csdn.net/">我的主页</a></li>
<li><a href="https://www.csdn.net/">CSDN首页</a></li>
<li class="li"><a href="https://www.csdn.net/nav/python" class="aaa">Python板块</a></li>
</ul>
</body>
</html>
选取某节点的所有子孙节点
假设我们需要获取上面HTML文件中<ul>标签的所有<a>子节点的链接与文本。我们需要如果去操作呢?示例代码如下:
from lxml import etree
parser = etree.HTMLParser()
html = etree.parse('demo.html', parser)
nodes = html.xpath("//ul//a")
for index in range(0, len(nodes)):
print("网址:", nodes[index].get('href'), " 文本:", nodes[index].text)
运行之后,效果如下:

双斜杠“//”代表获取当前节点下的子孙节点,也就是说,直接在根节点操作,就是获取根节点下面的所有该标签。
选取某节点的所有子节点
还是上面这个例子,我们如果使用单斜杠“/”获取所有的<a>标签呢?
因为<a>标签是<li>标签的子节点,所以我们需要获取<li>,再通过单斜杠"/"获取<a>标签。示例代码如下:
from lxml import etree
parser = etree.HTMLParser()
html = etree.parse('demo.html', parser)
nodes = html.xpath("//li/a")
for index in range(0, len(nodes)):
print("网址:", nodes[index].get('href'), " 文本:", nodes[index].text)
如上面代码所示,我们把xpath语法改成“//li/a”即可。运行之后,效果与上面一模一样。
通过属性选取某节点的父节点
对于当前节点来说,我们只需要通过其标签与属性确认,自然就可以获取当前节点。所以.这里就不赘述了。
我们直接介绍后两种语法,通过"@“查找属性,然后通过”.."查找其父节点。
实战,通过class等于aaa的节点获取父亲节点,然后获取其属性class的值。示例代码如下所示:
from lxml import etree
parser = etree.HTMLParser()
html = etree.parse('demo.html', parser)
nodes = html.xpath("//a[@class='aaa']/../@class")
print(nodes)
运行之后,效果如下:

除了通过/…获取父节点之外,我们还可以通过parent::*获取父节点。那么同样的转换语法也可以得到如上图所示的结果。(把…替换成即可)
多属性匹配
我们还是来获取那个有class的<a>标签,这里使用多属性匹配原则。
也就是,我们匹配其父节点class等于li以及class等于aaa的标签<a>。那么如何首先呢?示例如下:
from lxml import etree
parser = etree.HTMLParser()
html = etree.parse('demo.html', parser)
nodes = html.xpath("//a[contains(@class,'aaa') and ../@class='li']")
print(nodes[0].text)
运行之后,效果如下:

看看上面的输出图,是不是最后一个<a>标签的文本内容?这里通过and进行多属性条件判断。
XPath运算符规则
不过,这里就涉及XPath运算符规则了。博主这里,也列出了一个专门的运算符规则的表格,方便读者查阅参考。
| 运算符 | 描述 | 示例 | 意义 |
|---|---|---|---|
| and | 与 | class=‘name’ and href=‘www’ | 如果class等于name并且href等于www,则返回true,否则false |
| mod | 取余 | 10 mod 3 | 1 |
| or | 或 | class=‘name’ or class=‘www’ | 如果class等于name或者www,则返回true,都不等于则返回false |
| div | 除法 | 10 div 5 | 2 |
| + | 加法 | 10+5 | 15 |
| - | 减法 | 10-5 | 5 |
| * | 乘法 | 10*5 | 50 |
| = | 等于 | value=520 | 如果value等于520,返回true,否则返回false |
| != | 不等于 | value!=520 | 如果value不等于520,返回true,否则返回false |
| < | 小于 | value<520 | 如果value小于520,返回true,否则返回false |
| > | 大于 | value>520 | 如果value大于520,返回true,否则返回false |
| <= | 小于等于 | value<=520 | 如果value小于等于520,返回true,否则返回fals |
| >= | 大于等于 | value>=520 | 如果value大于等于520,返回true,否则返回false |
实战:爬取CSDN个人博文
我们先通过chrome,或者任意浏览器按F12打开查看CSDN个人主页的元素,可以看到,这里的div是整个主页内容的div。
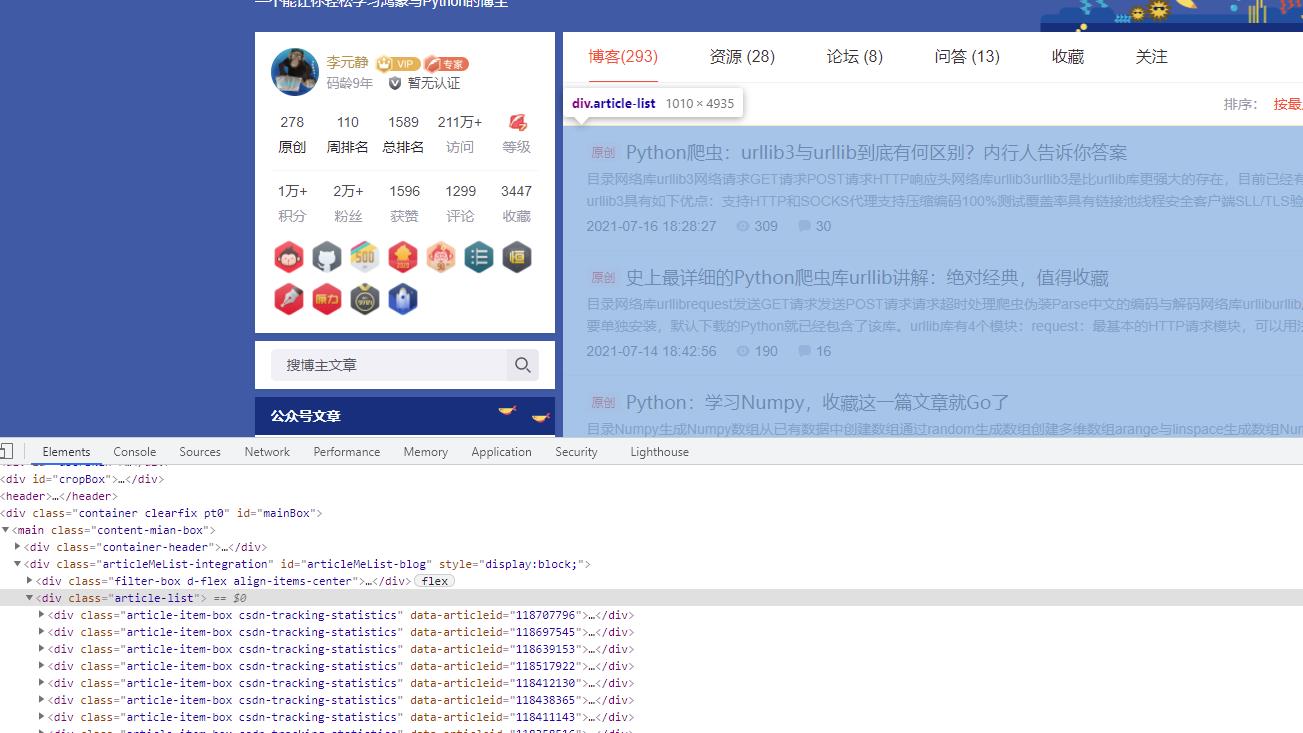
同时,其下边的所有子div都是一篇篇作者的博文内容。那么我们就可以先通过class="article-list"找到主页博文列表。
然后,在一条一条的遍历子div获取里面的每篇博文信息即可。不过,我们首先需要获取网页的HTML文本,通过requests进行获取。
然后,我们再来看看其标题与链接到底在哪里?如下图所示:
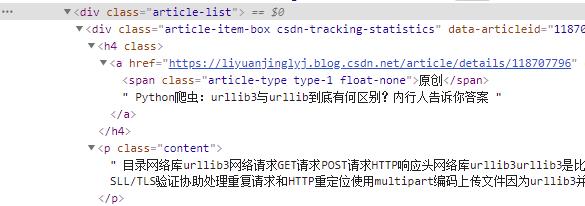
可以看到,标题与链接都在每个div的<h4>标签中,而描述信息在class='content’的<p>标签中,知道了这些,我们来获取主页的所有博文。
示例代码如下:
from lxml import etree
import requests
url = "https://blog.csdn.net/liyuanjinglyj"
session = requests.session()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
}
result = requests.get(url, headers=headers)
result.encoding = result.apparent_encoding
html = etree.HTML(result.text)
urlStr = html.xpath("//div[@class='article-list']//div/h4/a/@href")
titleStr = html.xpath("//div[@class='article-list']//div/h4/a/text()")
titleStr = [i for i in titleStr if i.strip() != '']
contentStr = html.xpath("//div[@class='article-list']//div/p[@class='content']/text()")
for url, title, content in zip(urlStr, titleStr, contentStr):
print("博文链接:", url)
print("博文标题:", title.strip())
print("博文描述:", content.strip())
运行之后,效果如下:
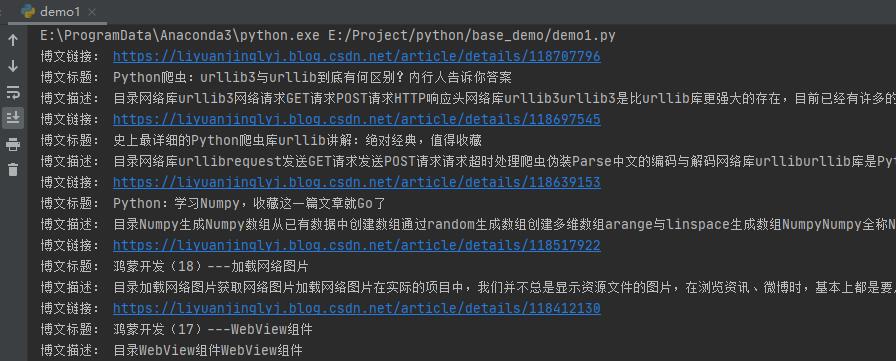
这里有一个很奇怪的问题,相信大家也发现了,我们titleStr遍历了2遍,其他的只遍历的一遍这是为什么呢?我们先来看一张图:

这里获取<a>标签文本的时候,默认是获取了2个,一个是空,一个才是下面的标题。所以,这里每次获取<a>标签文本标题时,都是一个空白,一个标题。
所以,我们在后续遍历的时候,应该去除掉空白字符串。只要标题。
XPath最简单的玩法
如果你是安装的Chrome,那么XPath语法,你可以不必学。因为这个浏览器可以直接生成XPath。
比如,我们获取上面的<a>标签,那么如何获取呢?只要选中<a>标签,然后按住右键选择Copy-Copy XPath即可。如下图所示:
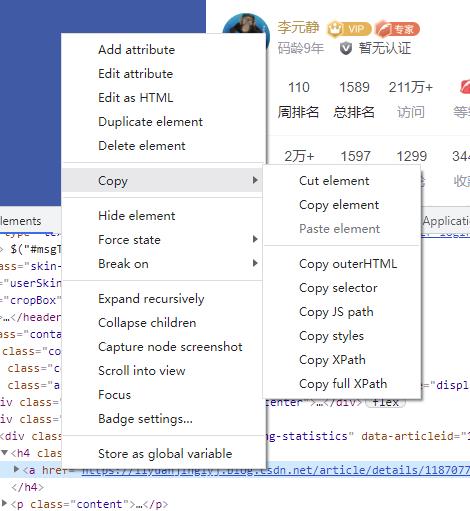
不过,博主不建议这么做。因为这里Copy的XPath仅仅只是针对当前的标签,而我们上面获取的标签是一个有规则的标签列表。而你不学习的XPath语法的话,这要是有100个列表标签,你难道还复制XPath语法100次不成?而学习过XPath只需要一行代码,然后遍历即可。
以上是关于Python爬虫:通过爬取CSDN博客信息,学习lxml库与XPath语法的主要内容,如果未能解决你的问题,请参考以下文章
Python3 爬虫 -- BeautifulSoup之再次爬取CSDN博文
Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量