[python爬虫] Selenium爬取内容并存储至MySQL数据库
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[python爬虫] Selenium爬取内容并存储至MySQL数据库相关的知识,希望对你有一定的参考价值。
前面我通过一篇文章讲述了如何爬取CSDN的博客摘要等信息。通常,在使用Selenium爬虫爬取数据后,需要存储在TXT文本中,但是这是很难进行数据处理和数据分析的。这篇文章主要讲述通过Selenium爬取我的个人博客信息,然后存储在数据库MySQL中,以便对数据进行分析,比如分析哪个时间段发表的博客多、结合WordCloud分析文章的主题、文章阅读量排名等。
这是一篇基础性的文章,希望对您有所帮助,如果文章中出现错误或不足之处,还请海涵。下一篇文章会简单讲解数据分析的过程。
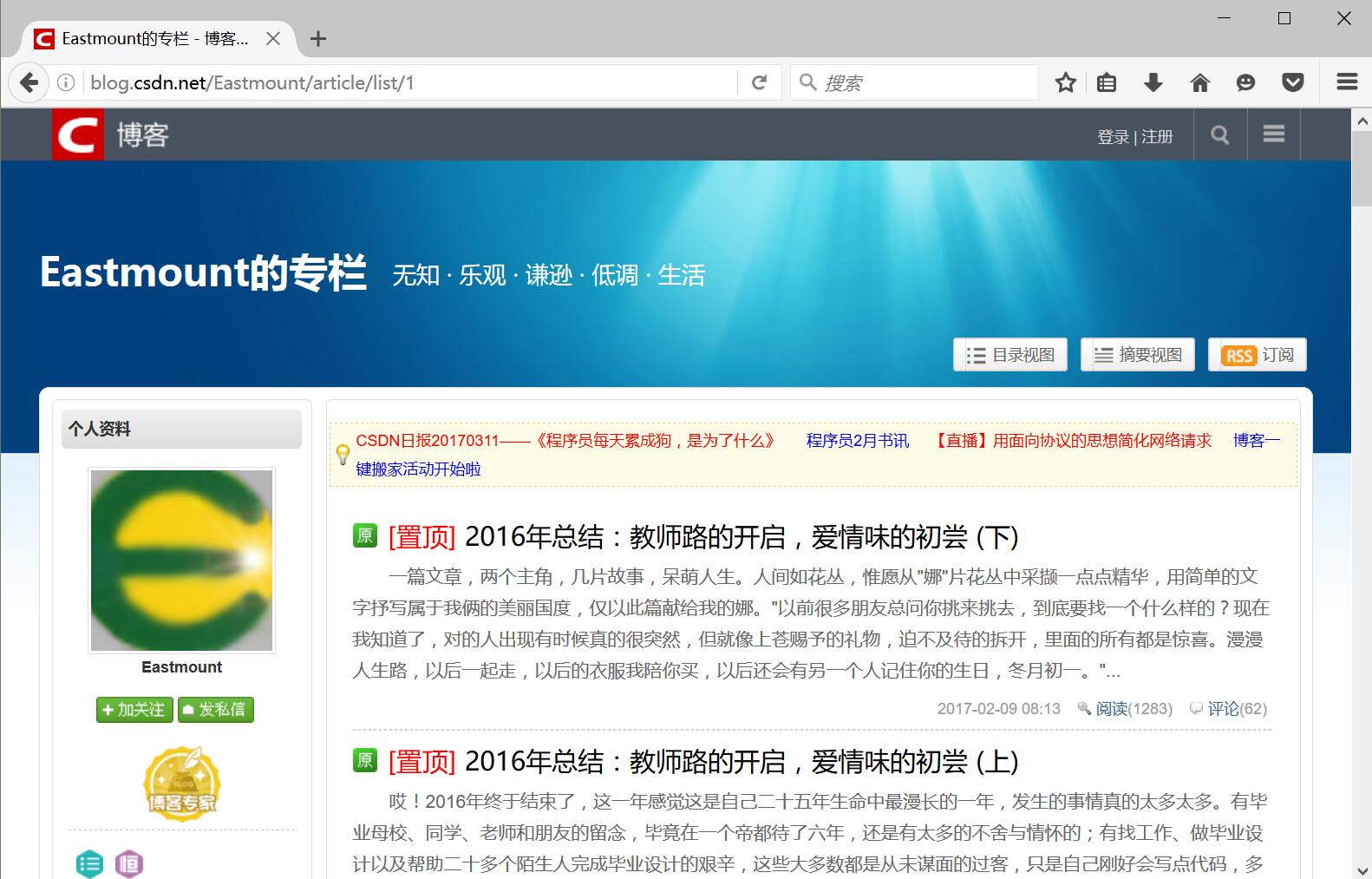
一. 爬取的结果
爬取的地址为:http://blog.csdn.net/Eastmount
以上是关于[python爬虫] Selenium爬取内容并存储至MySQL数据库的主要内容,如果未能解决你的问题,请参考以下文章