Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量相关的知识,希望对你有一定的参考价值。
Python并不是我的主业,当初学Python主要是为了学爬虫,以为自己觉得能够从网上爬东西是一件非常神奇又是一件非常有用的事情,因为我们可以获取一些方面的数据或者其他的东西,反正各有用处。
这两天闲着没事,主要是让脑子放松一下就写着爬虫来玩,上一篇初略的使用BeautifulSoup去爬某个CSDN博客的基本统计信息(http://blog.csdn.net/hw140701/article/details/55048364),今天就想要不就直接根据某个CSDN博客的主页的地址爬取该博客的所有文章链接,进而提取每一篇文章中的元素,我这里是提取每一篇博客
一、主要思路
通过分析CSDN博客的网站源码,我们发现当我们输入某博客主页网址时,如:http://blog.csdn.net/hw140701
在主页会有多篇文章,以及文章的链接,默认的是15篇。在主页博客的底部会有分页的链接,如下图
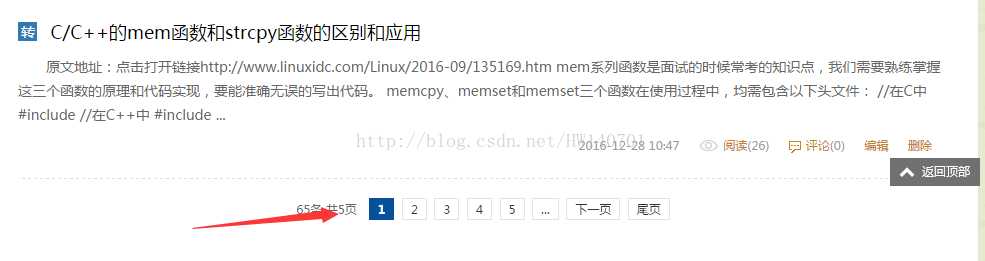
如图所示,一共65篇分5页,每一页中又包含了15篇文章的链接。
所以我们总体的思路是:
1.输入博客主页地址,先获取当前页所有文章的链接;
2.获取每个分页的链接地址
3.通过每个分页的链接地址获取每一个分页上所有文章的链接地址
4.根据每一篇文章的链接地址,获取每一篇文章的内容,直到该博客所有文章都爬取完毕
二、代码分析
2.1分页链接源码分析
用浏览器打开网页地址,使用开发者工具查看博客主页网站源码,发现分页链接地址隐藏在下列标签之中
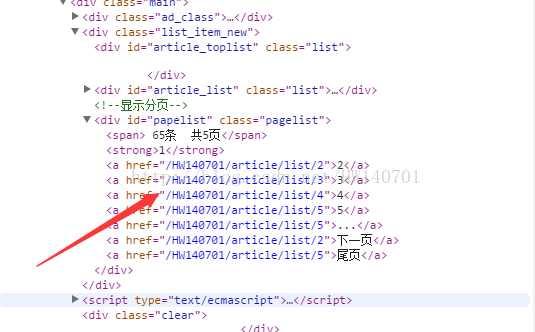
所以我们通过下列代码所有分页链接进行匹配
[python] view plain copy
- bsObj.findAll("a",href=re.compile("^/([A-Za-z0-9]+)(/article)(/list)(/[0-9]+)*$")):#正则表达式匹配分页的链接
bsObj为BeautifulSoup对象
2.2分页上每一篇文章链接源码分析
得到每一个分页的链接后,对每一个分页上的文章链接源码进行分析,其源码如下
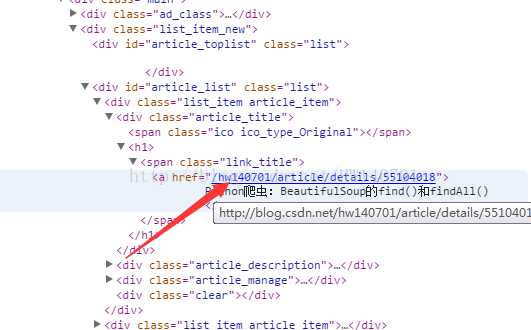
通过分析,所以我们采取以下的方法进行匹配
[python] view plain copy
- bsObj.findAll("a",href=re.compile("^/([A-Za-z0-9]+)(/article)(/details)(/[0-9]+)*$"))
或者
[python] view plain copy
- bsObj.findAll("span",{"class":"link_title"})
2.3每一篇文章中文字内容源码分析
通过对每一篇文章中的网站源码进行分析,发现其内容位于源码中的以下位置
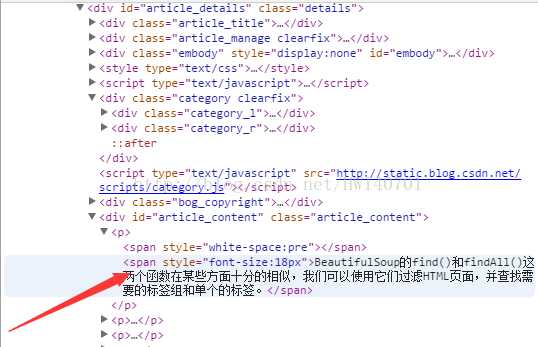
所以通过下列代码进行匹配
[python] view plain copy
- bsObj.findAll("span",style=re.compile("font-size:([0-9]+)px"))
3.全部代码以及结果
现附上全部代码,注释部分可能有错,可以根据此代码自行修改,去爬取某CSDN博客中的任意元素
[python] view plain copy
- #__author__ = ‘Administrat
- #coding=utf-8
- import io
- import os
- import sys
- import urllib
- from urllib.request import urlopen
- from urllib import request
- from bs4 import BeautifulSoup
- import datetime
- import random
- import re
- import requests
- import socket
- socket.setdefaulttimeout(5000)#设置全局超时函数
- sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030‘)
- headers1={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0‘}
- headers2={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36‘}
- headers3={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11‘}
- #得到CSDN博客某一个分页的所有文章的链接
- articles=set()
- def getArticleLinks(pageUrl):
- #设置代理IP
- #代理IP可以上http://zhimaruanjian.com/获取
- proxy_handler=urllib.request.ProxyHandler({‘post‘:‘210.136.17.78:8080‘})
- proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
- opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
- urllib.request.install_opener(opener)
- #获取网页信息
- req=request.Request(pageUrl,headers=headers1 or headers2 or headers3)
- html=urlopen(req)
- bsObj=BeautifulSoup(html.read(),"html.parser")
- global articles
- #return bsObj.findAll("a",href=re.compile("^/([A-Za-z0-9]+)(/article)(/details)(/[0-9]+)*$"))
- #return bsObj.findAll("a")
- #for articlelist in bsObj.findAll("span",{"class":"link_title"}):
- for articlelist in bsObj.findAll("span",{"class":"link_title"}):#正则表达式匹配每一篇文章链接
- #print(articlelist)
- if ‘href‘ in articlelist.a.attrs:
- if articlelist.a.attrs["href"] not in articles:
- #遇到了新界面
- newArticle=articlelist.a.attrs["href"]
- #print(newArticle)
- articles.add(newArticle)
- #articlelinks=getArticleLinks("http://blog.csdn.net/hw140701")
- #for list in articlelinks:
- #print(list.attrs["href"])
- #print(list.a.attrs["href"])
- #写入文本
- #def data_out(data):
- # with open("E:/CSDN.txt","a+") as out:
- # out.write(‘\\n‘)
- # out.write(data,)
- #得到CSDN博客每一篇文章的文字内容
- def getArticleText(articleUrl):
- #设置代理IP
- #代理IP可以上http://zhimaruanjian.com/获取
- proxy_handler=urllib.request.ProxyHandler({‘https‘:‘111.76.129.200:808‘})
- proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
- opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
- urllib.request.install_opener(opener)
- #获取网页信息
- req=request.Request(articleUrl,headers=headers1 or headers2 or headers3)
- html=urlopen(req)
- bsObj=BeautifulSoup(html.read(),"html.parser")
- #获取文章的文字内容
- for textlist in bsObj.findAll("span",style=re.compile("font-size:([0-9]+)px")):#正则表达式匹配文字内容标签
- print(textlist.get_text())
- #data_out(textlist.get_text())
- #得到CSDN博客某个博客主页上所有分页的链接,根据分页链接得到每一篇文章的链接并爬取博客每篇文章的文字
- pages=set()
- def getPageLinks(bokezhuye):
- #设置代理IP
- #代理IP可以上http://zhimaruanjian.com/获取
- proxy_handler=urllib.request.ProxyHandler({‘post‘:‘121.22.252.85:8000‘})
- proxy_auth_handler=urllib.request.ProxyBasicAuthHandler()
- opener = urllib.request.build_opener(urllib.request.HTTPHandler, proxy_handler)
- urllib.request.install_opener(opener)
- #获取网页信息
- req=request.Request(bokezhuye,headers=headers1 or headers2 or headers3)
- html=urlopen(req)
- bsObj=BeautifulSoup(html.read(),"html.parser")
- #获取当前页面(第一页)的所有文章的链接
- getArticleLinks(bokezhuye)
- #去除重复的链接
- global pages
- for pagelist in bsObj.findAll("a",href=re.compile("^/([A-Za-z0-9]+)(/article)(/list)(/[0-9]+)*$")):#正则表达式匹配分页的链接
- if ‘href‘ in pagelist.attrs:
- if pagelist.attrs["href"] not in pages:
- #遇到了新的界面
- newPage=pagelist.attrs["href"]
- #print(newPage)
- pages.add(newPage)
- #获取接下来的每一个页面上的每一篇文章的链接
- newPageLink="http://blog.csdn.net/"+newPage
- getArticleLinks(newPageLink)
- #爬取每一篇文章的文字内容
- for articlelist in articles:
- newarticlelist="http://blog.csdn.net/"+articlelist
- print(newarticlelist)
- getArticleText(newarticlelist)
- #getArticleLinks("http://blog.csdn.net/hw140701")
- getPageLinks("http://blog.csdn.net/hw140701")
- #getArticleText("http://blog.csdn.net/hw140701/article/details/55104018")
结果

在其中有时候会出现乱码,这是由于有空格的存在,暂时还有找到方法解决。
另外在有的时候会出现服务器没有响应的错误,如下:

以上是关于Python爬虫小实践:爬取任意CSDN博客所有文章的文字内容(或可改写为保存其他的元素),间接增加博客访问量的主要内容,如果未能解决你的问题,请参考以下文章
Python3 爬虫 -- BeautifulSoup之再次爬取CSDN博文
Python爬虫:通过爬取CSDN博客信息,学习lxml库与XPath语法
Python爬虫:通过爬取CSDN博客信息,学习lxml库与XPath语法