编译原理让我们来构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 6.)(python/c/c++版)(笔记)
Posted Dontla
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理让我们来构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 6.)(python/c/c++版)(笔记)相关的知识,希望对你有一定的参考价值。
【编译原理】让我们来构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 4.)
今天是这一天:) “为什么?” 你可能会问。原因是今天我们结束了对算术表达式的讨论(好吧,几乎)通过在我们的语法中添加括号表达式并实现一个解释器,该解释器将能够评估具有任意深度嵌套的括号表达式,例如表达式 7 + 3 * (10 / (12 / (3 + 1) - 1))。
让我们开始吧,好吗?
首先,让我们修改语法以支持括号内的表达式。正如您在第 5 部分 中记得的那样,因子规则用于表达式中的基本单位。在那篇文章中,我们唯一的基本单位是整数。今天我们要添加另一个基本单位——括号表达式。我们开始做吧。
这是我们更新的语法:
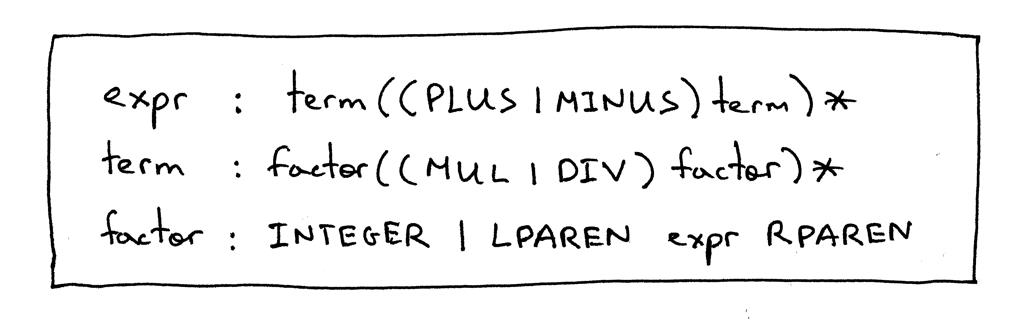
的EXPR和术语制作完全相同如在第5部分和唯一的变化是在因子生产其中终端LPAREN表示左括号“(”,终端RPAREN表示右括号“)”,和非括号之间的终结符 expr指的是expr 规则。
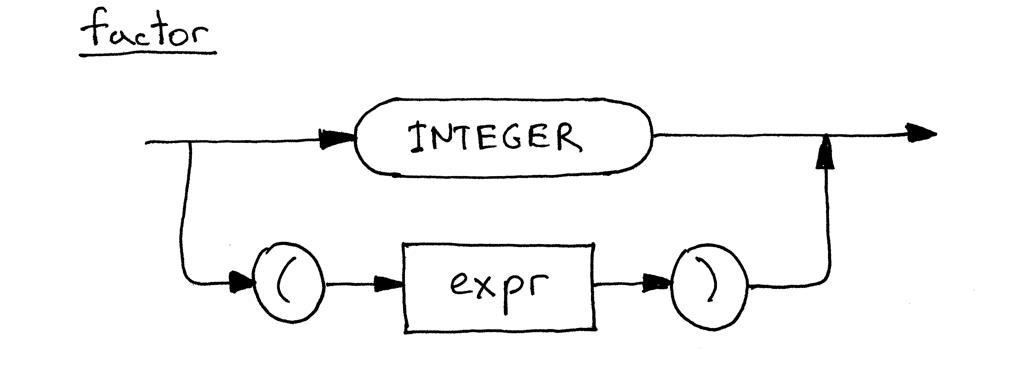
这是factor的更新语法图,现在包括替代方案:
(翻译不完全准确,将就着看吧!大致也能看懂)
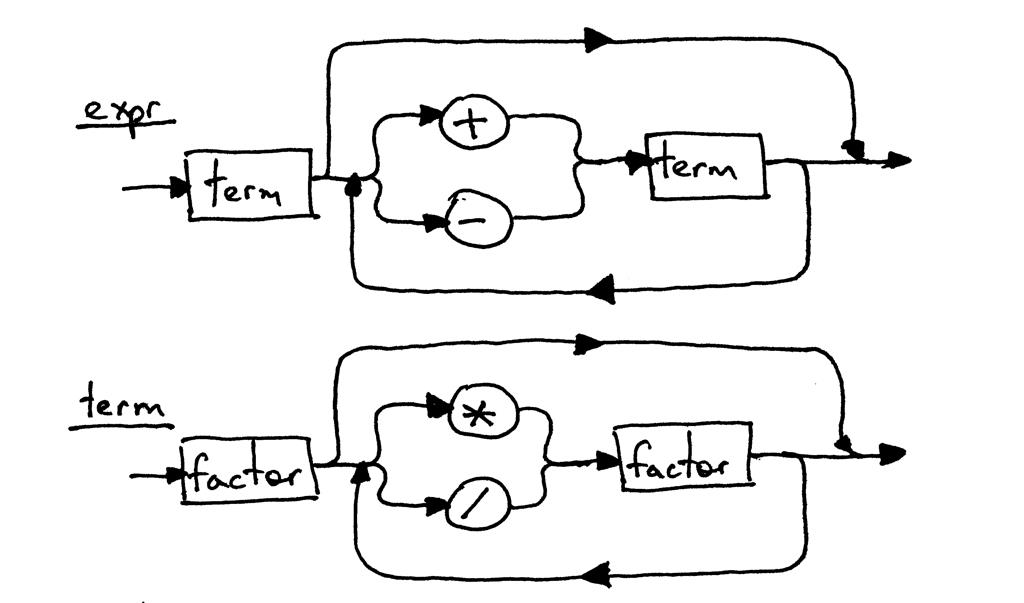
因为expr和术语的语法规则没有改变,它们的语法图看起来与第 5 部分中的相同:
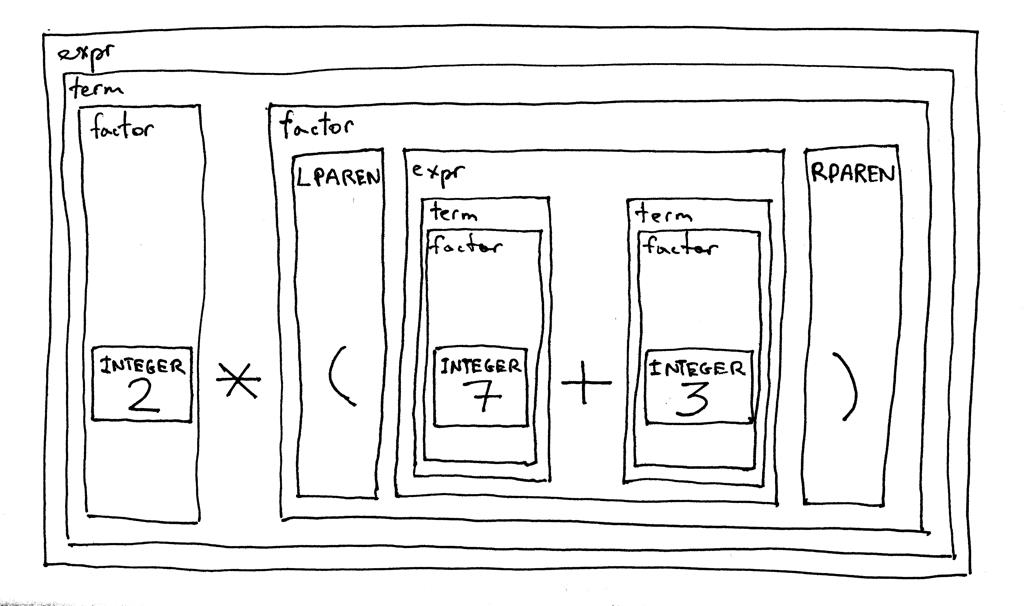
这是我们新语法的一个有趣特性——它是递归的。如果您尝试推导表达式 2 * (7 + 3),您将从expr开始符号开始,最终您将再次递归使用expr规则推导 (7 + 3) 部分原始算术表达式。
让我们根据语法对表达式 2 * (7 + 3) 进行分解,看看它的样子:
顺便说一句:如果您需要复习递归,请看一看 Daniel P. Friedman 和 Matthias Felleisen 的The Little Schemer一书——它真的很棒。
好的,让我们开始吧,将我们新更新的语法翻译成代码。
以下是对上一篇文章中代码的主要更改:
该词法已被修改为返回两个标记:LPAREN的左括号和RPAREN一个右括号。
该解释的因素法已略有更新解析除了整数括号表达式。
这是可以计算包含整数的算术表达式的计算器的完整代码;任意数量的加法、减法、乘法和除法运算符;和带有任意深度嵌套的括号表达式:
python代码
# -*- coding: utf-8 -*-
"""
@File : calc6.py
@Time : 2021/7/21 10:00
@Author : Dontla
@Email : sxana@qq.com
@Software: PyCharm
"""
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, MINUS, MUL, DIV, LPAREN, RPAREN, EOF = (
'INTEGER', 'PLUS', 'MINUS', 'MUL', 'DIV', '(', ')', 'EOF'
)
class Token(object):
def __init__(self, type, value):
self.type = type
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS, '+')
Token(MUL, '*')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Lexer(object):
def __init__(self, text):
# client string input, e.g. "4 + 2 * 3 - 6 / 2"
self.text = text
# self.pos is an index into self.text
self.pos = 0
self.current_char = self.text[self.pos]
def error(self):
raise Exception('Invalid character')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
if self.current_char == '*':
self.advance()
return Token(MUL, '*')
if self.current_char == '/':
self.advance()
return Token(DIV, '/')
if self.current_char == '(':
self.advance()
return Token(LPAREN, '(')
if self.current_char == ')':
self.advance()
return Token(RPAREN, ')')
self.error()
return Token(EOF, None)
class Interpreter(object):
def __init__(self, lexer):
self.lexer = lexer
# set current token to the first token taken from the input
self.current_token = self.lexer.get_next_token()
def error(self):
raise Exception('Invalid syntax')
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.lexer.get_next_token()
else:
self.error()
def factor(self):
"""factor : INTEGER | LPAREN expr RPAREN"""
token = self.current_token
if token.type == INTEGER:
self.eat(INTEGER)
return token.value
elif token.type == LPAREN:
self.eat(LPAREN)
result = self.expr()
self.eat(RPAREN)
return result
def term(self):
"""term : factor ((MUL | DIV) factor)*"""
result = self.factor()
while self.current_token.type in (MUL, DIV):
token = self.current_token
if token.type == MUL:
self.eat(MUL)
result = result * self.factor()
elif token.type == DIV:
self.eat(DIV)
result = result / self.factor()
return result
def expr(self):
"""Arithmetic expression parser / interpreter.
calc> 7 + 3 * (10 / (12 / (3 + 1) - 1))
22
expr : term ((PLUS | MINUS) term)*
term : factor ((MUL | DIV) factor)*
factor : INTEGER | LPAREN expr RPAREN
"""
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
# text = raw_input('calc> ')
text = input('calc> ')
except EOFError:
break
if not text:
continue
lexer = Lexer(text)
interpreter = Interpreter(lexer)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
运行结果:
D:\\python_virtualenv\\my_flask\\Scripts\\python.exe C:/Users/Administrator/Desktop/编译原理/python/calc6.py
calc> 5 * ( 3 - 2)/(2 -1) + ( 4 - 2)
7.0
calc>
C语言代码
将首次初始化token放在函数外执行,之前放在函数内执行老出错找了好久才找到问题,第一次初始化怎么能放在反复调用的函数内呢?
#include <stdio.h>
#include <stdlib.h>
#include <memory.h>
#include <string.h>
#include<math.h>
#define flag_digital 0
#define flag_plus 1
#define flag_minus 2
#define flag_multiply 3
#define flag_divide 4
#define flag_LPAREN 5
#define flag_RPAREN 6
#define flag_EOF 5
struct Token
{
int type;
int value;
};
struct Lexer
{
char* text;
int pos;
};
struct Interpreter
{
struct Lexer* lexer;
struct Token current_token;
};
void error() {
printf("输入非法!\\n");
exit(-1);
}
void skip_whitespace(struct Lexer* le) {
while (le->text[le->pos] == ' ') {
le->pos++;
}
}
//判断Interpreter中当前pos是不是数字
int is_integer(char c) {
if (c >= '0' && c <= '9')
return 1;
else
return 0;
}
void advance(struct Lexer* le) {
le->pos++;
}
char current_char(struct Lexer* le) {
return(le->text[le->pos]);
}
//获取数字token的数值(把数字字符数组转换为数字)
int integer(struct Lexer* le) {
char temp[20];
int i = 0;
while (is_integer(le->text[le->pos])) {
temp[i] = le->text[le->pos];
i++;
advance(le);
}
int result = 0;
int j = 0;
int len = i;
while (j < len) {
result += (temp[j] - '0') * pow(10, len - j - 1);
j++;
}
return result;
}
void get_next_token(struct Interpreter* pipt) {
//先跳空格,再判断有没有结束符
if (current_char(pipt->lexer) == ' ')
skip_whitespace(pipt->lexer);
if (pipt->lexer->pos > (strlen(pipt->lexer->text) - 1)) {
pipt->current_token = { flag_EOF, NULL };
return;
}
char current = current_char(pipt->lexer);
if (is_integer(current)) {
pipt->current_token = { flag_digital, integer(pipt->lexer)};
return;
}
if (current == '+') {
pipt->current_token = { flag_plus, NULL };
advance(pipt->lexer);
return;
}
if (current == '-') {
pipt->current_token = { flag_minus, NULL };
advance(pipt->lexer);;
return;
}
if (current == '*') {
pipt->current_token = { flag_multiply, NULL };
advance(pipt->lexer);;
return;
}
if (current == '/') {
pipt->current_token = { flag_divide, NULL };
advance(pipt->lexer);;
return;
}
if (current == '(') {
pipt->current_token = { flag_LPAREN, NULL };
advance(pipt->lexer);;
return;
}
if (current == ')') {
pipt->current_token = { flag_RPAREN, NULL };
advance(pipt->lexer);;
return;
}
error();//如果都不是以上的字符,则报错并退出程序
}
int eat(struct Interpreter* pipt, int type) {
int current_token_value = pipt->current_token.value;
if (pipt->current_token.type == type) {
get_next_token(pipt);
return current_token_value;
}
else {
error();
}
}
int expr(struct Interpreter* pipt);//expr定义在后面,在这里要声明才能使用
int factor(struct Interpreter* pipt) {
if (pipt->current_token.type == flag_digital) {
return eat(pipt, flag_digital);
}
else if(pipt->current_token.type == flag_LPAREN) {
eat(pipt, flag_LPAREN);
int result = expr(pipt);
eat(pipt, flag_RPAREN);
return result;
}
}
//判断乘除
int term(struct Interpreter* pipt) {
int result = factor(pipt);
while (true) {
int token_type = pipt->current_token.type;
if (token_type == flag_multiply) {
eat(pipt, flag_multiply);
result = result * factor(pipt);
}
else if (token_type == flag_divide) {
eat(pipt, flag_divide);
result = result / factor(pipt);
}
else {
return result;
}
}
}
int expr(struct Interpreter* pipt) {
int result = term(pipt);
while (true) {
int token_type = pipt->current_token.type;
if (token_type == flag_plus) {
eat(pipt, flag_plus);
result = result + term(pipt);
}else if (token_type == flag_minus) {
eat(pipt, flag_minus);
result = result - term(pipt);
}
else {
return result;
}
}
}
int main() {
char text[50];
while (1)
{
printf("请输入算式:\\n");
//scanf_s("%s", text, sizeof(text));//sanf没法输入空格?
int i 编译原理让我们来构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 6.)(python/c/c++版)(笔记)
编译原理让我们来构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 4.)(python/c/c++版)(笔记)
编译原理让我们来构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 3.)(python/c/c++版)(笔记)
编译原理让我们来构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 5.)(python/c/c++版)(笔记)Lexer词法分析程序
编译原理构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 8.)(笔记)一元运算符正负(+,-)
编译原理构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 9.)(笔记)语法分析(未完,先搁置了!)