编译原理构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 9.)(笔记)语法分析(未完,先搁置了!)
Posted Dontla
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 9.)(笔记)语法分析(未完,先搁置了!)相关的知识,希望对你有一定的参考价值。
【编译原理】让我们来构建一个简单的解释器(Let’s Build A Simple Interpreter. Part 9.)
我记得当我在大学(很久以前)学习系统编程时,我相信唯一“真正”的语言是汇编和 C。而 Pascal 是——怎么说好一点——一种非常高级的语言不想知道幕后发生了什么的应用程序开发人员。
那时我几乎不知道我会用 Python 编写几乎所有东西(并且喜欢它的每一点)来支付我的账单,而且我还会因为我在第一篇文章中提到的原因为 Pascal 编写解释器和编译器该系列的。
这些天,我认为自己是一个编程语言爱好者,我对所有语言及其独特的功能都很着迷。话虽如此,我必须指出,我比其他语言更喜欢使用某些语言。我有偏见,我将是第一个承认这一点的人。😃
这是我之前:
好的,让我们进入正题。以下是您今天要学习的内容:
如何解析和解释 Pascal 程序定义。
1、如何解析和解释复合语句(compound statements)。
2、如何解析和解释赋值语句(assignment statements),包括变量(variables)。
3、关于符号表(symbol tables)以及如何存储和查找变量的一些知识。
我将使用以下示例 Pascal-like 程序来介绍新概念:
BEGIN
BEGIN
number := 2;
a := number;
b := 10 * a + 10 * number / 4;
c := a - - b
END;
x := 11;
END.
您可以说,按照本系列的前几篇文章,到目前为止您编写的命令行解释器是一个很大的跳跃,但我希望这种跳跃会带来兴奋。它不再“只是”一个计算器,我们在这里变得认真了,Pascal 是认真的。😃
让我们深入了解新语言结构的语法图(syntax diagrams)及其相应的语法规则(grammar rules)。
在你的标记上:准备好了。放。出发!
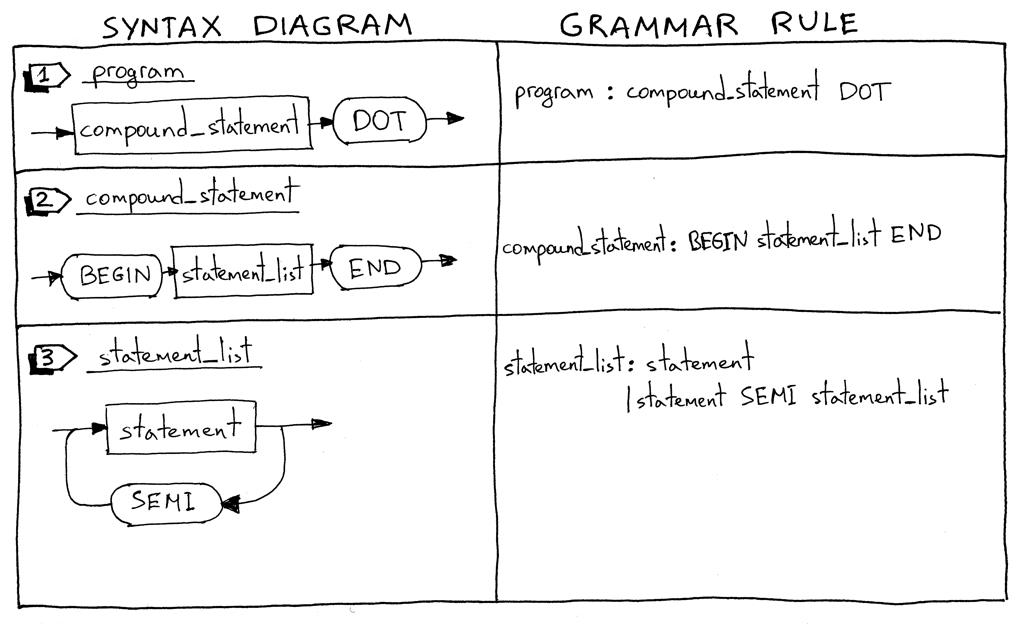

1、我将从描述什么是 Pascal程序开始。Pascal程序由一个以点结尾的复合语句组成。下面是一个程序示例:
“BEGIN END.”
我必须提示,这不是一个完整的程序定义,我们将在本系列的后面对其进行扩展。
2、什么是复合语句?复合语句(compound statement)是标有块BEGIN和END 语句包括其它复合语句,它可以包含一个列表(list)(可能为空)。复合语句中的每一条语句,除了最后一条,都必须以分号(semicolon)结束。块中的最后一条语句可能有也可能没有终止分号。以下是一些有效复合语句的示例:
“BEGIN END”
“BEGIN a := 5; x := 11 END”
“BEGIN a := 5; x := 11; END”
“BEGIN BEGIN a := 5 END; x := 11 END”
3、语句列表(statement list )是一个复合语句中的零条或多个语句的列表。有关一些示例,请参见上文。
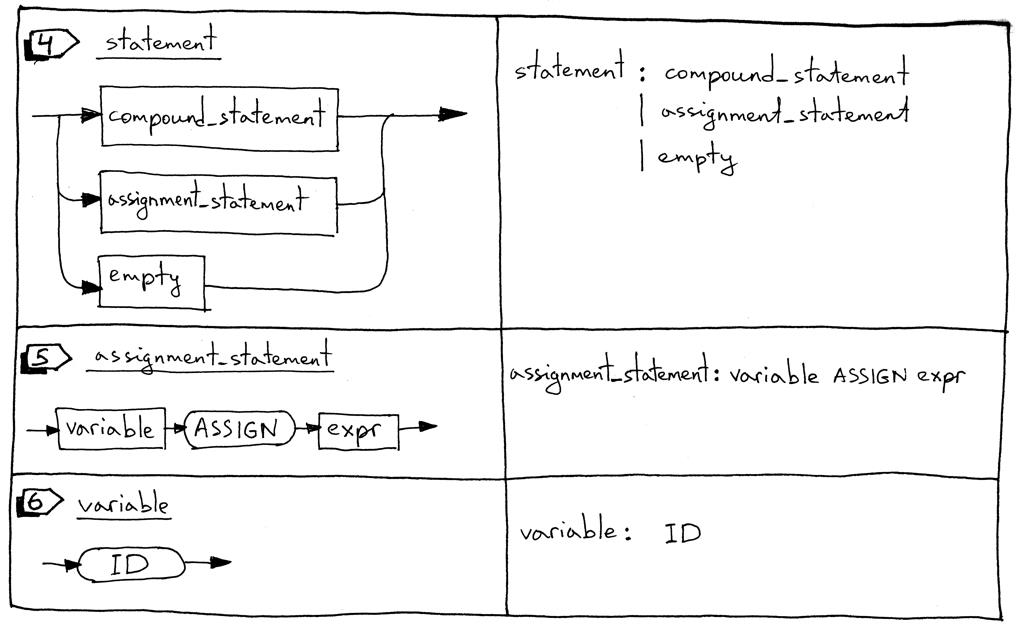
4、语句可以是一个复合语句,一个赋值语句,或者它可以是一个空的 语句。
5、赋值语句(assignment statement)是一个变量后面跟着个ASSIGN标记(两个字符,“:”和“=”),后面再跟着个表达式。
“a := 11”
“b := a + 9 - 5 * 2”
6、变量是一个标识符。我们为变量使用ID标记。标记的值将是变量的名称,如“a”、“number”等。在以下代码块中,‘a’ 和 ‘b’ 是变量:
“BEGIN a := 11; b := a + 9 - 5 * 2 END”
7、一个空的声明表示,没有进一步的生成语法规则。我们使用empty_statement语法规则来指示 解析器中statement_list的结尾,并允许像“ BEGIN END ”中那样的空复合语句。
8、factor规则被用来更新处理变量。
现在让我们来看看我们完整的语法:
program : compound_statement DOT
compound_statement : BEGIN statement_list END
statement_list : statement
| statement SEMI statement_list
statement : compound_statement
| assignment_statement
| empty
assignment_statement : variable ASSIGN expr
empty :
expr: term ((PLUS | MINUS) term)*
term: factor ((MUL | DIV) factor)*
factor : PLUS factor
| MINUS factor
| INTEGER
| LPAREN expr RPAREN
| variable
variable: ID
您可能已经注意到,我没有在复合语句规则中使用星号“*” 来表示零次或多次重复,而是明确指定了statement_list规则。这是表示“零或多个”操作的另一种方式,当我们查看本系列后面的PLY等解析器生成器时,它会派上用场。我还将“( PLUS | MINUS ) factor ”子规则拆分为两个单独的规则。
为了支持更新的语法,我们需要对词法分析器、解析器和解释器进行一些更改。让我们一一回顾这些变化。
以下是词法分析器更改的摘要:
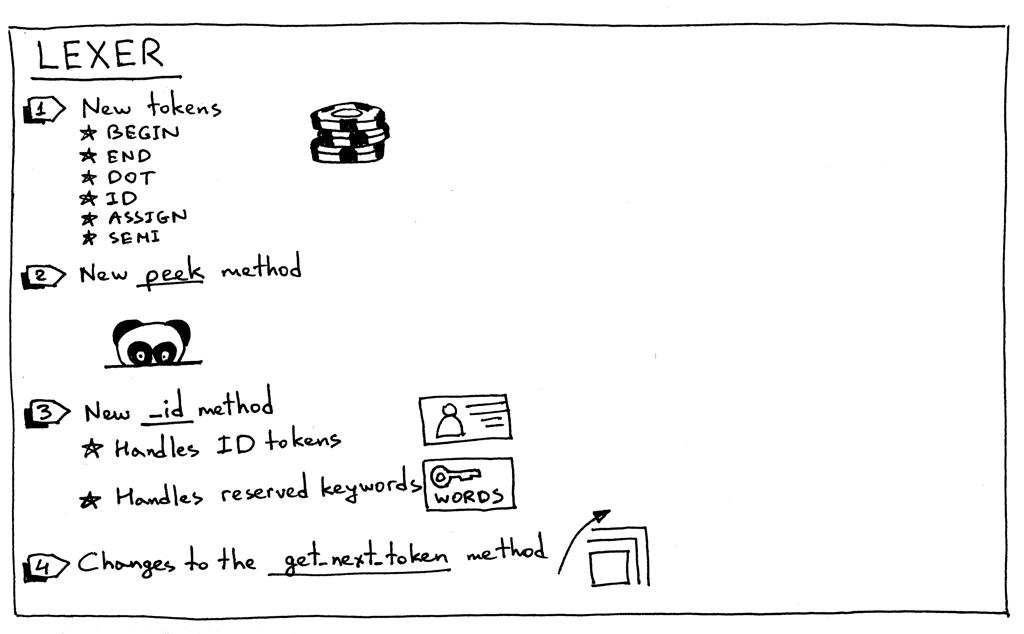
1、为了支持 Pascal 程序的定义、复合语句、赋值语句和变量,我们的词法分析器需要返回新的标记:
- BEGIN(标记复合语句的开始)
- END(标记复合语句的结束)
- DOT(Pascal 程序定义所需的点字符“.”的标记)
- ASSIGN(两个字符序列“:=”的标记)。在 Pascal 中,赋值运算符与 C、Python、Java、Rust 或 Go 等许多其他语言不同,在这些语言中,您可以使用单个字符“=”来表示赋值
- SEMI(分号字符“;”的标记,用于标记复合语句内的语句结束)
- ID(有效标识符的标记。标识符以字母字符开头,后跟任意数量的字母数字字符)
2、有时,为了能够区分以相同字符开头的不同标记,(':' vs ':=' or '==' vs '=>' )我们需要查看输入缓冲区而不实际消耗下一个字符。出于这个特殊目的,我引入了一个peek 方法,它将帮助我们标记赋值语句。该方法不是严格要求的,但我想我会在本系列的前面介绍它,它也会使get_next_token 方法更简洁一些。它所做的只是从文本缓冲区返回下一个字符,而不增加self.pos变量。这是方法本身:
def peek(self):
peek_pos = self.pos + 1
if peek_pos > len(self.text) - 1:
return None
else:
return self.text[peek_pos]
3、因为 Pascal 变量和保留关键字都是标识符,所以我们将它们的处理合并到一个称为_id 的方法中。它的工作方式是词法分析器使用一系列字母数字字符,然后检查该字符序列是否为保留字(reserved word)。如果是,则为该保留关键字返回一个预先构造的标记。如果它不是保留关键字,则返回一个新的ID令牌,其值为字符串(词素【lexeme】)。我打赌此时你会想,“天哪,给我看看代码。” :) 这里是:
RESERVED_KEYWORDS = {
'BEGIN': Token('BEGIN', 'BEGIN'),
'END': Token('END', 'END'),
}
def _id(self):
"""Handle identifiers(标识符) and reserved keywords"""
result = ''
while self.current_char is not None and self.current_char.isalnum():
result += self.current_char
self.advance()
token = RESERVED_KEYWORDS.get(result, Token(ID, result))
return token
现在让我们看看主词法分析器方法get_next_token的变化:
def get_next_token(self):
while self.current_char is not None:
...
if self.current_char.isalpha():
return self._id()
if self.current_char == ':' and self.peek() == '=':
self.advance()
self.advance()
return Token(ASSIGN, ':=')
if self.current_char == ';':
self.advance()
return Token(SEMI, ';')
if self.current_char == '.':
self.advance()
return Token(DOT, '.')
...
是时候看看我们闪亮的新词法分析器的所有荣耀和动作了。从GitHub下载源代码并从保存spi.py 文件的同一目录启动 Python shell :(spi.py代码见文章目录)也可直接见spi_lexer代码,在pycharm中可直接运行或调试看到结果
>>> from spi import Lexer
>>> lexer = Lexer('BEGIN a := 2; END.')
>>> lexer.get_next_token()
Token(BEGIN, 'BEGIN')
>>> lexer.get_next_token()
Token(ID, 'a')
>>> lexer.get_next_token()
Token(ASSIGN, ':=')
>>> lexer.get_next_token()
Token(INTEGER, 2)
>>> lexer.get_next_token()
Token(SEMI, ';')
>>> lexer.get_next_token()
Token(END, 'END')
>>> lexer.get_next_token()
Token(DOT, '.')
>>> lexer.get_next_token()
Token(EOF, None)
>>>
继续解析器更改。
以下是我们的解析器更改的摘要:

让我们从新的AST 节点开始:
复合 AST节点表示复合语句。它在其children 变量中包含一个语句节点列表。
class Compound(AST):
"""Represents a 'BEGIN ... END' block"""
def __init__(self):
self.children = []
Assign AST节点代表一个赋值语句。它的左变量用于存储一个Var节点,它的右变量用于存储由 expr 解析器方法返回的节点:
class Assign(AST):
def __init__(self, left, op, right):
self.left = left
self.token = self.op = op
self.right = right
Var AST节点(你猜对了)代表一个变量。该self.value持有变量的名称。
class Var(AST):
"""The Var node is constructed out of ID token."""
def __init__(self, token):
self.token = token
self.value = token.value
NoOp节点用于表示空语句。例如,’ BEGIN END ’ 是一个没有语句的有效复合语句。
class NoOp(AST):
pass
您还记得,语法中的每个规则在我们的递归下降解析器中都有一个对应的方法。这次我们添加了七个新方法。这些方法负责解析新的语言结构和构建新的AST节点。它们非常简单:(ps. 我就喜欢作者这么说!)
def program(self):
"""program : compound_statement DOT"""
node = self.compound_statement()
self.eat(DOT)
return node
def compound_statement(self):
"""
compound_statement: BEGIN statement_list END
"""
self.eat(BEGIN)
nodes = self.statement_list()
self.eat(END)
root = Compound()
for node in nodes:
root.children.append(node)
return root
def statement_list(self):
"""
statement_list : statement
| statement SEMI statement_list
"""
node = self.statement()
results = [node]
while self.current_token.type == SEMI:
self.eat(SEMI)
results.append(self.statement())
if self.current_token.type == ID:
self.error()
return results
def statement(self):
"""
statement : compound_statement
| assignment_statement
| empty
"""
if self.current_token.type == BEGIN:
node = self.compound_statement()
elif self.current_token.type == ID:
node = self.assignment_statement()
else:
node = self.empty()
return node
def assignment_statement(self):
"""
assignment_statement : variable ASSIGN expr
"""
left = self.variable()
token = self.current_token
self.eat(ASSIGN)
right = self.expr()
node = Assign(left, token, right)
return node
def variable(self):
"""
variable : ID
"""
node = Var(self.current_token)
self.eat(ID)
return node
def empty(self):
"""An empty production"""
return NoOp()
我们还需要更新现有的factor方法来解析变量:
def factor(self):
"""factor : PLUS factor
| MINUS factor
| INTEGER
| LPAREN expr RPAREN
| variable
"""
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
node = UnaryOp(token, self.factor())
return node
...
else:
node = self.variable()
return node
解析器的parse方法更新为通过解析程序定义来启动解析过程:
def parse(self):
node = self.program()
if self.current_token.type != EOF:
self.error()
return node
这是我们的示例程序:
BEGIN
BEGIN
number := 2;
a := number;
b := 10 * a + 10 * number / 4;
c := a - - b
END;
x := 11;
END.
让我们用genastdot.py对其进行可视化(为简洁起见,当显示Var节点时,它只显示节点的变量名称,当显示一个 Assign 节点时,它显示 ‘:=’ 而不是显示 ‘Assign’ 文本):
$ python genastdot.py assignments.txt > ast.dot && dot -Tpng -o ast.png ast.dot
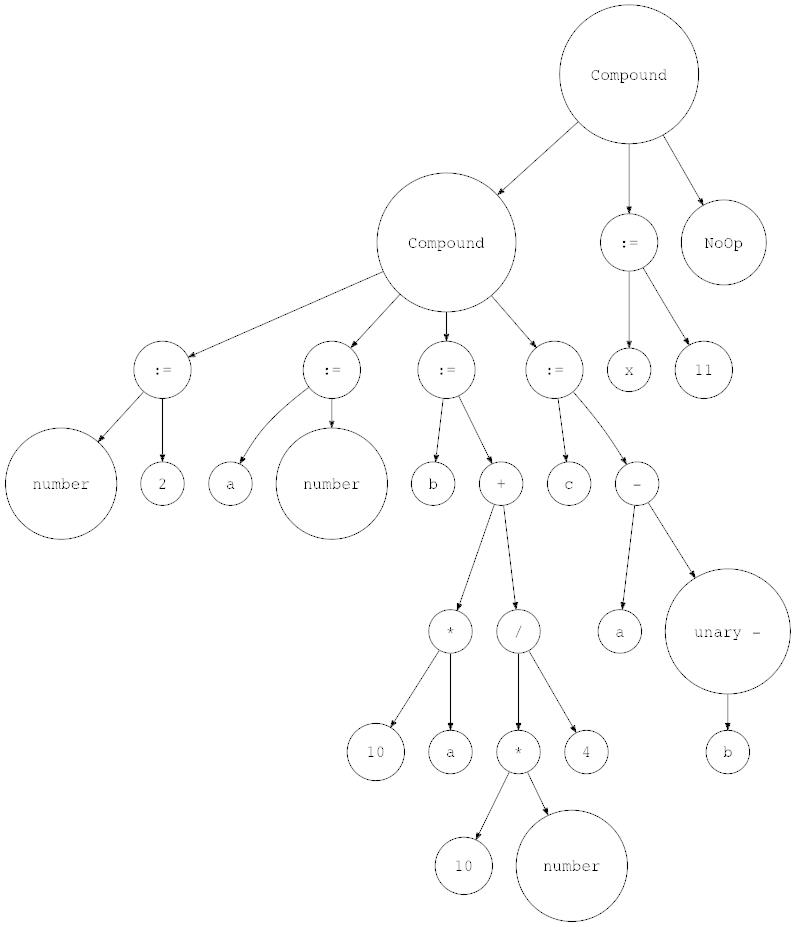
最后,这里是所需的解释器更改:
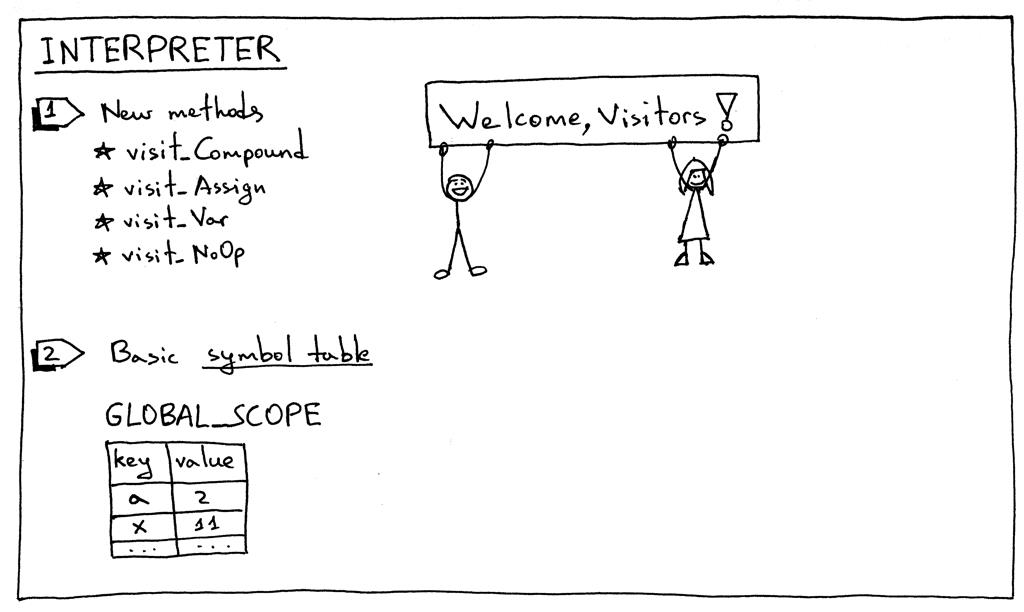
要解释新的AST节点,我们需要向解释器添加相应的访问者方法。有四种新的访问者方法:
访问_Compound
访问_分配
访问_变量
访问_NoOp
Compound和NoOp访问者方法非常简单。该visit_Compound方法遍历它的孩子和参观各一转,和visit_NoOp方法不起作用。
def visit_Compound(self, node):
for child in node.children:
self.visit(child)
def visit_NoOp(self, node):
pass
在分配和瓦尔游客方法值得仔细研究。
当我们为变量赋值时,我们需要将该值存储在某个地方以备日后需要时使用,这正是visit_Assign方法所做的:
def visit_Assign(self, node):
var_name = node.left.value
self.GLOBAL_SCOPE[var_name] = self.visit(node.right)
该方法在符号表GLOBAL_SCOPE 中存储键值对(变量名和与变量关联的值)。什么是符号表?甲符号表是一个抽象数据类型(ADT用于在源代码中追踪各种符号)。我们现在唯一的符号类别是变量,我们使用 Python 字典来实现符号表ADT。现在我只想说,本文中符号表的使用方式非常“hacky”:它不是一个具有特殊方法的单独类,而是一个简单的 Python 字典,它还作为内存空间执行双重任务。在以后的文章中,我将更详细地讨论符号表,我们还将一起删除所有的黑客。
让我们看一下语句“a := 3;”的AST 和visit_Assign方法之前和之后的符号表完成它的工作:
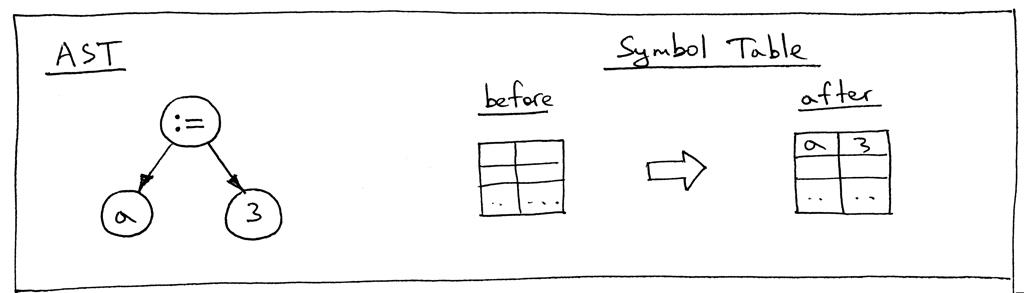
现在让我们看一下语句“b := a + 7;”的AST
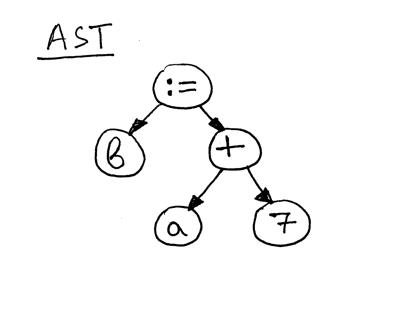
如您所见,赋值语句的右侧 - “a + 7” - 引用了变量 ‘a’,因此在我们评估表达式“a + 7”之前,我们需要找出 ’ 的值a’ 是,这是visit_Var 方法的职责:
def visit_Var(self, node):
var_name = node.value
val = self.GLOBAL_SCOPE.get(var_name)
if val is None:
raise NameError(repr(var_name))
else:
return val
当该方法访问上图AST 中的Var节点时,它首先获取变量的名称,然后使用该名称作为GLOBAL_SCOPE字典中的键来获取变量的值。如果它可以找到该值,则返回该值,否则会引发NameError异常。以下是在评估赋值语句“b := a + 7;”之前的符号表内容:
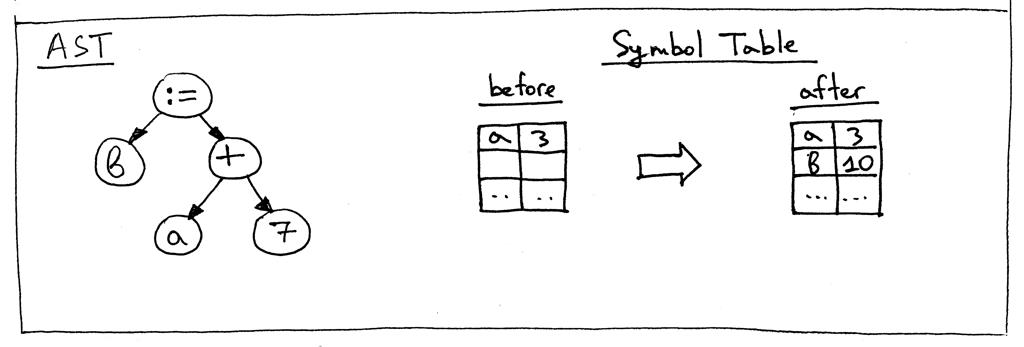
这些都是我们今天需要做的改变,以使我们的解释器打勾。在主程序结束时,我们简单地将符号表 GLOBAL_SCOPE 的内容打印到标准输出。
让我们从 Python 交互式 shell 和命令行中使用我们更新的解释器作为驱动器。确保在测试之前下载了解释器的源代码和assignments.txt文件:
启动你的 Python shell:
$ python
>>> from spi import Lexer, Parser, Interpreter
>>> text = """\\
... BEGIN
...
... BEGIN
... number := 2;
... a := number;
... b := 10 * a + 10 * number / 4;
... c := a - - b
... END;
...
... x := 11;
... END.
... """
>>> lexer = Lexer(text)
>>> parser = Parser(lexer)
>>> interpreter = Interpreter(parser)
>>> interpreter.interpret()
>>> print(interpreter.GLOBAL_SCOPE)
{'a': 2, 'x': 11, 'c': 27, 'b': 25, 'number': 2}
从命令行,使用源文件作为我们解释器的输入:
$ python spi.py assignments.txt
{'a': 2, 'x': 11, 'c': 27, 'b': 25, 'number': 2}
如果您还没有尝试过,现在就尝试一下,亲眼看看解释器是否正确地完成了它的工作。
让我们总结一下你在这篇文章中扩展 Pascal 解释器需要做的事情:
向语法添加新规则
向词法分析器添加新标记和支持方法并更新get_next_token 方法
向解析器添加新的AST节点以获得新的语言结构
将与新语法规则相对应的新方法添加到我们的递归下降解析器中,并在必要时更新任何现有方法(因子方法,我在看着你。😃
向解释器添加新的访问者方法
添加用于存储变量和查找变量的字典
在这一部分中,我不得不介绍一些“技巧”,我们将随着系列的推进而将其删除:
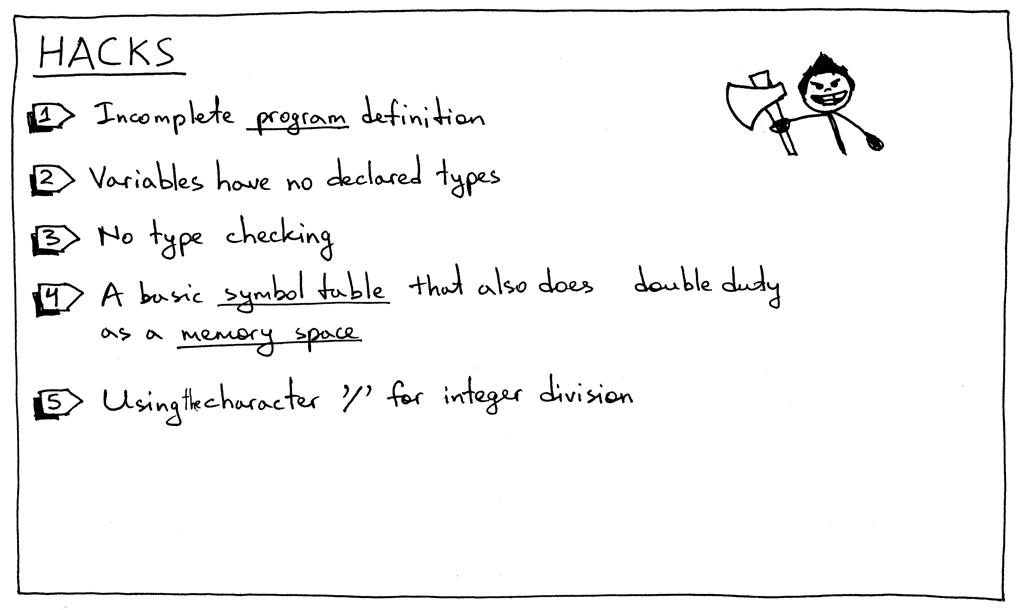
该程序的语法规则是不完整的。稍后我们将使用其他元素对其进行扩展。
Pascal 是一种静态类型语言,您必须在使用它之前声明一个变量及其类型。但是,正如您所看到的,本文中的情况并非如此。
到目前为止没有类型检查。在这一点上这没什么大不了的,但我只是想明确地提到它。例如,一旦我们向解释器添加更多类型,当您尝试添加字符串和整数时,我们将需要报告错误。
这部分中的符号表是一个简单的 Python 字典,它具有双重存储空间的功能。不用担心:符号表是一个非常重要的主题,我将专门针对它们撰写几篇文章。内存空间(运行时管理)本身就是一个话题。
在我们之前文章中的简单计算器中,我们使用正斜杠字符“/”来表示整数除法。但是,在 Pascal 中,您必须使用关键字div来指定整数除法(参见练习 1)。
我还特意引入了一个 hack,以便您可以在练习 2 中修复它:在 Pascal 中,所有保留关键字和标识符都不区分大小写,但本文中的解释器将它们视为区分大小写。
为了让你保持健康,这里有新的练习给你:
Pascal 变量和保留关键字不区分大小写,这与许多其他编程语言不同,因此BEGIN、begin和BeGin它们都引用相同的保留关键字。更新解释器,使变量和保留关键字不区分大小写。使用以下程序对其进行测试:
BEGIN
BEGIN
number := 2;
a := NumBer;
B := 10 * a + 10 * NUMBER / 4;
c := a - - b
end;
x := 11;
END.
我之前在“hacks”部分提到我们的解释器使用正斜杠字符“/”来表示整数除法,但它应该使用 Pascal 的保留关键字div进行整数除法。更新解释器以使用div关键字进行整数除法,从而消除其中一种技巧。
更新解释器,以便变量也可以以下划线开头,如 ‘_num := 5’。
spi.py
""" SPI - Simple Pascal Interpreter. Part 9."""
###############################################################################
# #
# LEXER #
# #
###############################################################################
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
(INTEGER, PLUS, MINUS, MUL, DIV, LPAREN, RPAREN, ID, ASSIGN,
BEGIN, END, SEMI, DOT, EOF) = (
'INTEGER', 'PLUS', 'MINUS', 'MUL', 'DIV', '(', ')', 'ID', 'ASSIGN',
'BEGIN', 'END', 'SEMI', 'DOT', 'EOF'
)
class Token(object):
def __init__(self, type, value):
self.type = type
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS, '+')
Token(MUL, '*')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
RESERVED_KEYWORDS = {
'BEGIN': Token('BEGIN', 'BEGIN'),
'END': Token('END', 'END'),
}
class Lexer(object):
def __init__(self, text):
# client string input, e.g. "4 + 2 * 3 - 6 / 2"
self.text = text
# self.pos is an index into self.text
self.pos = 0
self.current_char = self.text[self.pos]
def error