遇事不决,XGBoost,梯度提升比深度学习更容易赢得Kaggle竞赛
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了遇事不决,XGBoost,梯度提升比深度学习更容易赢得Kaggle竞赛相关的知识,希望对你有一定的参考价值。
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
在Kaggle上参加机器学习比赛,用什么算法最容易拿奖金?
你可能会说:当然是深度学习。
还真不是,据统计获胜最多的是像XGBoost这种梯度提升算法,之前在周志华教授的boosting视频中也有详细介绍。
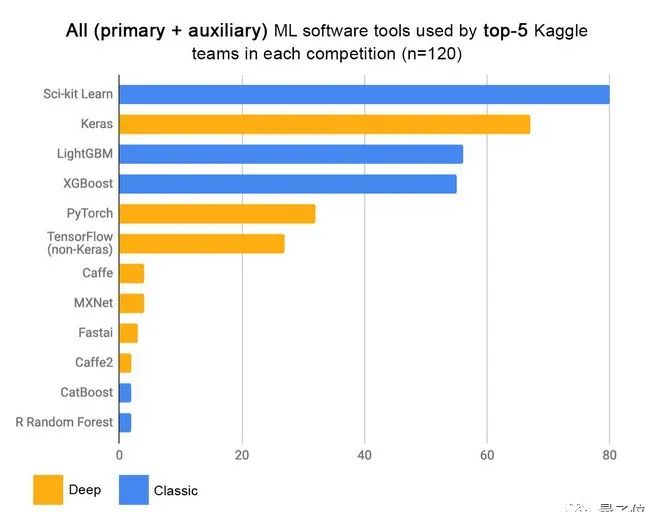
这就奇了怪了,深度学习在图像、语言等领域大放异彩,怎么在机器学习比赛里还不如老前辈了。
一位Reddit网友把这个问题发在机器学习板块(MachineLearning),并给出了一个直觉上的结论:
提升算法在比赛中提供的表格类数据中表现最好,而深度学习适合非常大的非表格数据集(例如张量、图片、音频、文本)。
但这背后的原理能不能用数学原理来解释?
更进一步,能不能仅通过数据集的类型和规模来判断哪种算法更适用于手头的任务。
这能节省很多时间啊,举个极端点的例子,如果尝试用AlphaGo做Logistic回归,你就走远了。
问题吸引了很多人参与讨论,有人回复到:
这是一个十分活跃的研究领域,完全可以就这个主题做一篇博士论文了。
关键在能不能人工提取特征
有网友表示,虽然很难给出详细论证,但可以猜测一下。
基于树的梯度提升算法可以简单的分离数据,就像这样:
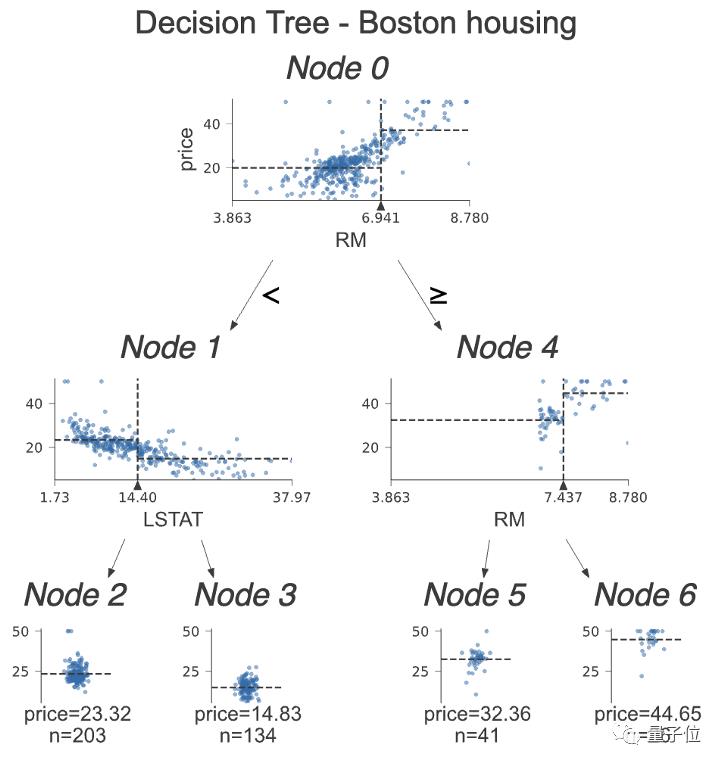
如果特征小于某个值就向左,反之就向右,一步一步把数据拆解。
在深度学习中,要用到多个隐藏层才能把输入空间变换成线性可分割:
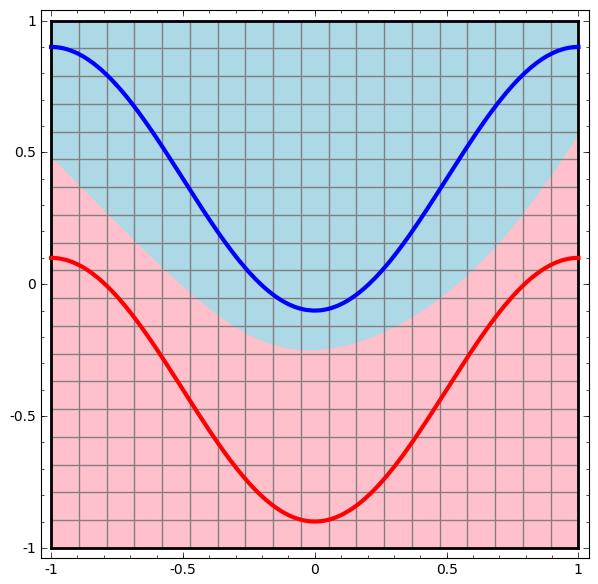
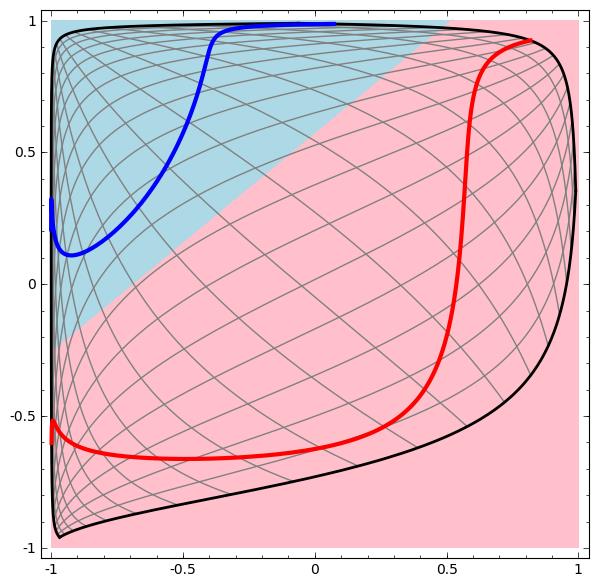
这个过程就像是把输入空间在高维进行“揉捏”:
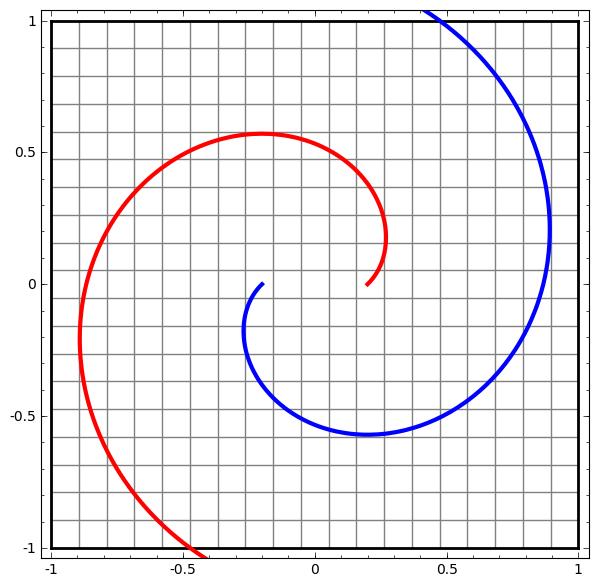
数据集越复杂,需要的隐藏层就越多,变换过程很可能失败,反而让数据更加缠在一起:
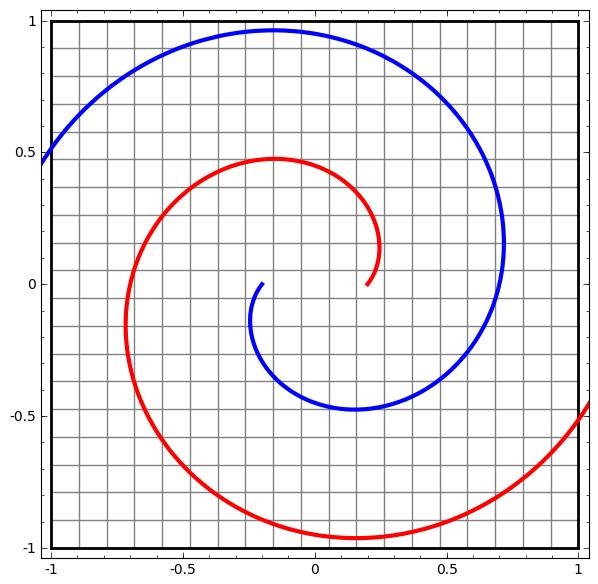
即使成功了,相对梯度提升树来说也是效率极低的。
深度学习的优势是,面对人类很难手工提取特征的复杂数据可以自动创建隐藏特征。
而且即使你手工创建了特征,深度网络无论如何还是会自己创建隐藏特征。
而Kaggle比赛中使用的表格数据,特征往往已经有了,就是表头,那么直接使用梯度提升就好。
就像Kaggle Avito挑战的冠军所说:“遇事不决,XGBoost”。

吃数据的怪物
另一个高赞回复是:
大多数Kaggle比赛的数据集都不够喂出一个神经网络怪物。

在小数据集上深度学习容易过拟合,正则化的方法又依赖许多条件。在给定数据集的比赛上,还是梯度提升比较迅速、稳定。
而参数越多的深度神经网络需要越多的数据,比赛提供的数据集有限,数据维度也比较低,发挥不出深度学习的实力。
一位在Kaggle上成绩很好的大神补充到:
不同的深度网络适用于某种数据集,如CNN适合处理图像,RNN适合处理特定的序列等。比赛给的数据集很难找到合适的预训练模型可用。
总的来看,深度学习在表格数据上的性能肯定优于梯度提升,但是需要大量时间优化网络架构。
Kaggle上的胜出方案一般是将二者结合,加上梯度提升,有经验的选手在几个小时内就能得到不错的结果。
参考链接:
[1]https://www.reddit.com/r/MachineLearning/comments/nxn65x/d_can_we_begin_to_understand_possible/
[2]https://www.reddit.com/r/MachineLearning/comments/9826bt/d_why_is_deep_learning_so_bad_for_tabular_data/
[3]http://colah.github.io/posts/2014-03-NN-Manifolds-Topology/
— 完 —
我在GitHub开源电子书
GitHub开源的电子书《计算机视觉实战演练:算法与应用》,很快火热!在线电子文档、免费GPU代码运行、常用网络代码开源。
- GitHub项目地址
https://github.com/Charmve/computer-vision-in-action
- 在线电子书
https://charmve.github.io/computer-vision-in-action
推荐阅读
(点击标题可跳转阅读)

# CV技术社群邀请函 #

△长按添加迈微官方微信号
备注:姓名-学校/公司-研究方向-城市(如:小C-北大-目标检测-北京)
△点击卡片关注迈微AI研习社,获取最新CV干货
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:yidazhang1@gmail.com
由于微信公众号试行乱序推送,您可能不再能准时收到迈微AI研习社的推送。为了第一时间收到报道, 请将“迈微AI研习社”设为星标账号,以及常点文末右下角的“在看”。
以上是关于遇事不决,XGBoost,梯度提升比深度学习更容易赢得Kaggle竞赛的主要内容,如果未能解决你的问题,请参考以下文章
遇事不决,XGBoost,梯度提升比深度学习更容易赢得Kaggle竞赛
深度 | 对比TensorFlow提升树与XGBoost:我们该使用怎样的梯度提升方法
Matlab基于极端梯度提升XGBoost实现分类预测(Excel可直接替换数据)