深度 | 对比TensorFlow提升树与XGBoost:我们该使用怎样的梯度提升方法
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度 | 对比TensorFlow提升树与XGBoost:我们该使用怎样的梯度提升方法相关的知识,希望对你有一定的参考价值。
选自Nicolo Blog
机器之心编译
参与:蒋思源
几个月前,TensorFlow 发布了梯度提升方法的调用接口,即 TensorFlow 提升树(TFBT)。不幸的是,描述该接口的论文并没有展示任何测试效果和基准的对比结果,所以 Nicolò Valigi 希望能对 TFBT 和 XGBoost 做一个简要的对比,并分析它们之间的性能差异。机器之心介绍了该测试与 TFBT 的原论文,且 TF 1.4 及以上的版本也可测试该提升树模型。
本文将先介绍 Nicolò Valigi 的对比试验结果,然后再简述谷歌新提出来的 TensorFlow 提升树。此外,该试验之所以选择 XGBoost,是因为自从它发布以来,它就是许多数据挖掘问题的首选解决方案。而且因为 XGBoost 对未归一化或缺失数据的高效处理方式,以及快速和准确的训练过程,它很适合与 TFBT 进行基准测试。
试验
作者使用适当大小的航线数据集以测试两个解决方案,该数据集包含了从 1987 到 2008 年的美国商业航班记录,共计 1.2 亿个数据点。它的特征包含始发站、目的地、登记时间与日期、航线和飞行距离等,而作者尝试使用这些特征做一个二元分类器,以判断航班是否会延误超过 15 分钟。
作者从 2006 年抽取 10 万个航班以作为训练集,并从 2007 年抽取 10 万个航班作为测试集。大约有 20% 的航班延误是超过 15 分钟的,这和当前的航班延误情况有些不一样。下图展示了该数据集航班延迟情况和起飞时间的关系:
作者并没有执行任何特征工程,因此采用的特征都十分基础:
Month
DayOfWeek
Distance
CRSDepTime
UniqueCarrier
Origin
Dest
对于 XGBoost 来说,作者使用 scikit 风格的封装,这令训练和预测只需要使用几行代码和几个 NumPy 数组。对于 TensorFlow,他使用 tf.Experiment、tf.learn.runner 方法和 NumPy 输入函数以节省一些代码。
试验结果
作者从 XGBoost 开始测试,并采用适当的超参数。很快我们就能得到非常不错的 AUC 曲线。但是作者表明 TFBT 训练较慢,可能我们需要耐心等一段时间。当他为这两个模型设置超参数 num_trees=50 和 learning_rate=0.1 后,作者不得不使用一个留出的数据子集以调整 TensorFlow 提升树的 TF Boosted Trees 和 examples_per_layer 两个超参数。这很可能与 TFBT 论文中提到的新型逐层学习算法相关,但我们并不详细探讨这个问题。作为对比的出发点,作者选择了两个值(1K 和 5K),它们在 XGBoost 中有相似的训练时间和准确度。
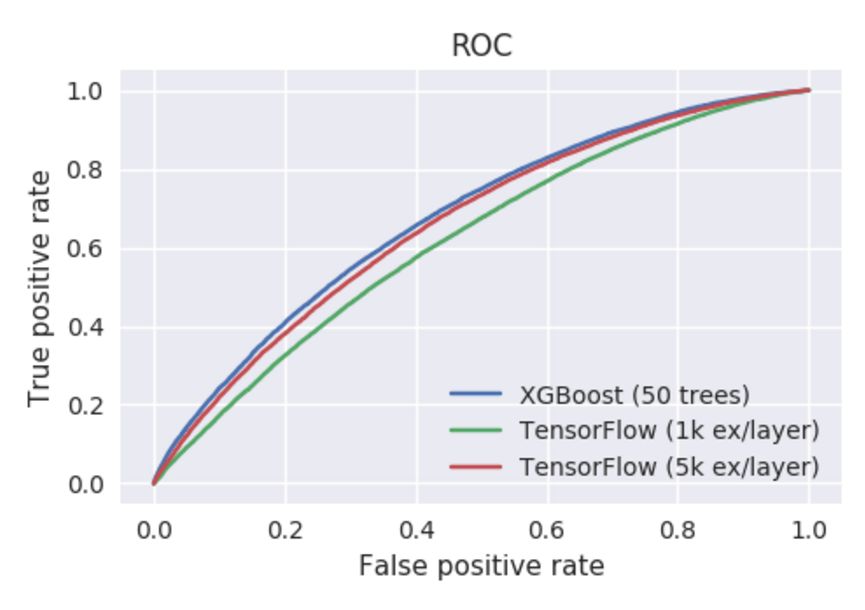
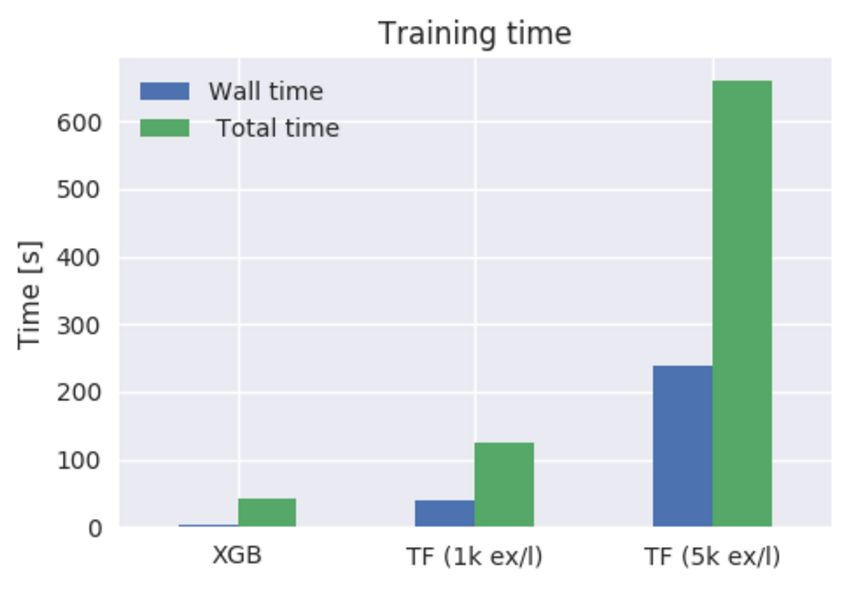
准确度数值:
Model AUC score
-----------------------------------
XGBoost 67.6
TensorFlow (1k ex/layer) 62.1
TensorFlow (5k ex/layer) 66.1
训练运行时:
./do_xgboost.py --num_trees=50
42.06s user 1.82s system 1727% cpu 2.540 total
./do_tensorflow.py --num_trees=50 --examples_per_layer=1000
124.12s user 27.50s system 374% cpu 40.456 total
./do_tensorflow.py --num_trees=50 --examples_per_layer=5000
659.74s user 188.80s system 356% cpu 3:58.30 total
两套配置都显示 TensorFlow 提升树的结果不能匹配 XGBoost 的性能,包括训练时间和训练准确度。除了 CPU 使用时间过长的缺点外,TFBT 似乎在多核并行训练的效率上也不高,因此导致了总运行时的巨大差别。XGBoost 可以轻松加载 32 个核心中的 16 个,这在使用更多树的时候会有更好的效果,而 TFBT 只能使用 4 个核。
Nicolò Valigi 最后表明,即使通过几个小时的调整,他也无法使用 TFBT 实现与 XGBoost 相匹配的结果,无论训练时间还是准确性。而并行训练的实现也有限制,这意味着它也不能扩展到大型数据集。
前面 Nicolò Valigi 的试验表明 TensorFlow 提升树接口仍然达不到 XGBoost 的性能,但在 TensorFlow 上构建提升树的调用接口很有意义。因为这也意味着即使是传统的数据分析和机器学习算法,我们也可以直接调用 TensorFlow 完成。以下是提出 TFBT 的论文,我们对此作了简要介绍。
论文:TF Boosted Trees: A scalable TensorFlow based framework for gradient boosting

TF 提升树(TFBT)是一种用于分布式训练梯度提升树的新型开源框架。该框架基于 TensorFlow,并且它独特的特征还包括新颖的架构、损失函数自动微分、逐层级(layer-by-layer)的提升方法、条理化的多类别处理和一系列可以防止过拟合的正则化技术,其中逐层级的提升方法可以减少集成的数量以更快地执行预测。
1. 前言
梯度提升树是最受欢迎的机器学习模型之一,自从梯度提升树算法被提出以来,它就主宰了许多带有真实数据的竞赛,包括 Kaggle、KDDCup[2] 等顶尖竞赛。除了出色的准确度,提升方法同样很容易使用,因为它们擅长处理非归一化、共线性或异常感染的数据。该算法同样支持自定义损失函数,并且通常要比神经网络或大型线性模型更具可解释性。由于梯度提升树非常受欢迎,目前有非常多的实现库,包括 scikit-learn [7]、R gbm [8]、Spark MLLib [5]、LightGBM [6] 和 XGBoost [2] 等。
在本论文中,我们介绍了另外一个可优化和可扩展的梯度提升树软件库,即 TF 提升树(TFBT),该算法库构建在 TensorFlow 框架 [1] 的顶层。TFBT 合并了一组新颖的算法以提升梯度提升树的性能,包括使用新的逐层提升过程提高一些问题的性能。TFBT 是一个开源的库,它可以在 TensorFlow 主流发行版的 contrib/boosted_trees 下找到。
2.TFBT 特征
在表 1 中,我们提供了一个简要地对比,从上可以了解当前主流梯度提升树软件库的特性:
除了上述描述的分布式训练、损失函数形式和正则化技术等特征以外,TF 梯度提升树主要还有以下两个特征:
逐层的提升方法(Layer-by-layer boosting):TFBT 支持两种树型构建的模式,即标准的方式和新颖的逐层提升方式。其中标准模式即使用随机梯度的方式构建提升树序列,而逐层提升的方式允许构建更强的树和更深的模型。
多类别支持:TFBT 支持一对多(one-vs-rest)的方式,此外它还通过在每一个叶结点上储存每一个类别的分数而减少树的数目要求,这和其它一些变体一样。
因为 TFBT 是使用 TensorFlow 实现的,所以所有 TensorFlow 具体的特征都是可获取的:
易于编写自定义的损失函数,因为 TensorFlow 提供了自动微分工具 [1],而其它如 XGBoost 那样的库要求使用者提供一阶导数和二阶导数。
我们能无缝转换和对比 TFBT 与其它 TensorFlow 封装模型,还能通过其它 TensorFlow 模型生成的特征轻松组合梯度提升树模型。
很容易通过 TensorBoard 进行调试。
模型能多块 CPU/GPU 和多个平台上运行,包括移动端,它们都很容易通过 TF serving[9] 进行部署。
3.TFBT 系统设计
TFBT 架构如下,我们的计算模型基于以下需求:
能够在数据集中训练且不需要适配工作站的内存。
能够处理特征数目众多的深度树模型。
支持不同模式构建提升树:标准的 one-tree-perbatch 模式和逐层提升树模式。
极小化平行化损失。
图 1:TFBT 的架构
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
以上是关于深度 | 对比TensorFlow提升树与XGBoost:我们该使用怎样的梯度提升方法的主要内容,如果未能解决你的问题,请参考以下文章
深度|PaddlePaddle与TensorFlow的对比分析