赠书TensorFlow和CaffeMXNetKeras等其他深度学习框架的对比
Posted 人工智能头条
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了赠书TensorFlow和CaffeMXNetKeras等其他深度学习框架的对比相关的知识,希望对你有一定的参考价值。
赠!书!啦!
只需两步就有机会获得
Google TensorFlow团队官方推荐的国内首本教程
《TensorFlow实战》
!免!邮!哦!
2月22日晚22时前,我们将随机选择三位读者赠送
本文节选自《TensorFlow实战》第二章 |
Google近日发布了TensorFlow 1.0候选版,这第一个稳定版将是深度学习框架发展中的里程碑的一步。自TensorFlow于2015年底正式开源,距今已有一年多,这期间TensorFlow不断给人以惊喜。在这一年多时间,TensorFlow已从初入深度学习框架大战的新星,成为了几近垄断的行业事实标准。
主流深度学习框架对比
深度学习研究的热潮持续高涨,各种开源深度学习框架也层出不穷,其中包括TensorFlow、Caffe、Keras、CNTK、Torch7、MXNet、Leaf、Theano、DeepLearning4、Lasagne、Neon,等等。然而TensorFlow却杀出重围,在关注度和用户数上都占据绝对优势,大有一统江湖之势。表2-1所示为各个开源框架在GitHub上的数据统计(数据统计于2017年1月3日),可以看到TensorFlow在star数量、fork数量、contributor数量这三个数据上都完胜其他对手。
究其原因,主要是Google在业界的号召力确实强大,之前也有许多成功的开源项目,以及Google强大的人工智能研发水平,都让大家对Google的深度学习框架充满信心,以至于TensorFlow在2015年11月刚开源的第一个月就积累了10000+的star。其次,TensorFlow确实在很多方面拥有优异的表现,比如设计神经网络结构的代码的简洁度,分布式深度学习算法的执行效率,还有部署的便利性,都是其得以胜出的亮点。如果一直关注着TensorFlow的开发进度,就会发现基本上每星期TensorFlow都会有1万行以上的代码更新,多则数万行。产品本身优异的质量、快速的迭代更新、活跃的社区和积极的反馈,形成了良性循环,可以想见TensorFlow未来将继续在各种深度学习框架中独占鳌头。
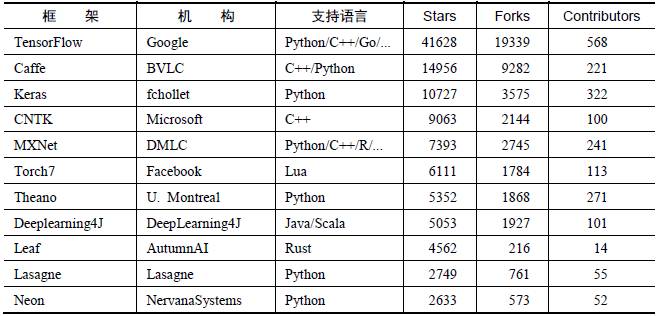
表2-1 各个开源框架在GitHub上的数据统计
观察表1还可以发现,Google、Microsoft、Facebook等巨头都参与了这场深度学习框架大战,此外,还有毕业于伯克利大学的贾扬清主导开发的Caffe,蒙特利尔大学Lisa Lab团队开发的Theano,以及其他个人或商业组织贡献的框架。另外,可以看到各大主流框架基本都支持Python,目前Python在科学计算和数据挖掘领域可以说是独领风骚。虽然有来自R、Julia等语言的竞争压力,但是Python的各种库实在是太完善了,Web开发、数据可视化、数据预处理、数据库连接、爬虫等无所不能,有一个完美的生态环境。仅在数据挖据工具链上,Python就有NumPy、SciPy、Pandas、Scikit-learn、XGBoost等组件,做数据采集和预处理都非常方便,并且之后的模型训练阶段可以和TensorFlow等基于Python的深度学习框架完美衔接。
表2-1和图2-1所示为对主流的深度学习框架TensorFlow、Caffe、CNTK、Theano、Torch在各个维度的评分,本书2.2节会对各个深度学习框架进行比较详细的介绍。
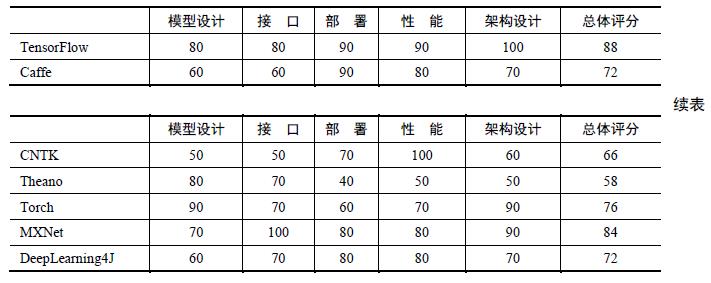
表2-2 主流深度学习框架在各个维度的评分
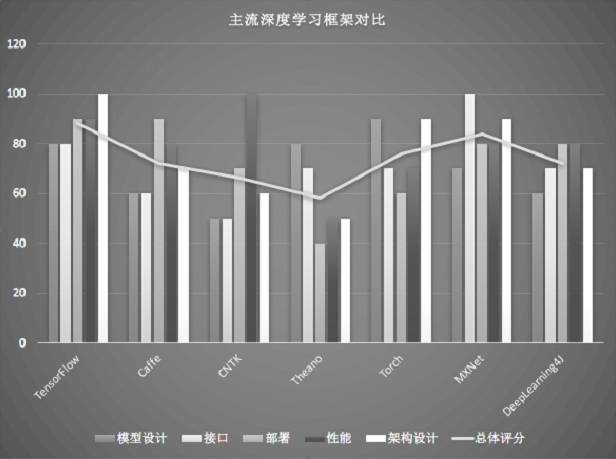
图2-1 主流深度学习框架对比图
各深度学习框架简介
在本节,我们先来看看目前各流行框架的异同,以及各自的特点和优势。
TensorFlow
Julia: github.com/malmaud/TensorFlow.jl
Node.js: github.com/node-tensorflow/node-tensorflow
R: github.com/rstudio/tensorflow
TensorFlow也有内置的TF.Learn和TF.Slim等上层组件可以帮助快速地设计新网络,并且兼容Scikit-learn estimator接口,可以方便地实现evaluate、grid search、cross validation等功能。同时TensorFlow不只局限于神经网络,其数据流式图支持非常自由的算法表达,当然也可以轻松实现深度学习以外的机器学习算法。事实上,只要可以将计算表示成计算图的形式,就可以使用TensorFlow。用户可以写内层循环代码控制计算图分支的计算,TensorFlow会自动将相关的分支转为子图并执行迭代运算。TensorFlow也可以将计算图中的各个节点分配到不同的设备执行,充分利用硬件资源。定义新的节点只需要写一个Python函数,如果没有对应的底层运算核,那么可能需要写C++或者CUDA代码实现运算操作。
在数据并行模式上,TensorFlow和Parameter Server很像,但TensorFlow有独立的Variable node,不像其他框架有一个全局统一的参数服务器,因此参数同步更自由。TensorFlow和Spark的核心都是一个数据计算的流式图,Spark面向的是大规模的数据,支持SQL等操作,而TensorFlow主要面向内存足以装载模型参数的环境,这样可以最大化计算效率。
TensorFlow的另外一个重要特点是它灵活的移植性,可以将同一份代码几乎不经过修改就轻松地部署到有任意数量CPU或GPU的PC、服务器或者移动设备上。相比于Theano,TensorFlow还有一个优势就是它极快的编译速度,在定义新网络结构时,Theano通常需要长时间的编译,因此尝试新模型需要比较大的代价,而TensorFlow完全没有这个问题。TensorFlow还有功能强大的可视化组件TensorBoard,能可视化网络结构和训练过程,对于观察复杂的网络结构和监控长时间、大规模的训练很有帮助。TensorFlow针对生产环境高度优化,它产品级的高质量代码和设计都可以保证在生产环境中稳定运行,同时一旦TensorFlow广泛地被工业界使用,将产生良性循环,成为深度学习领域的事实标准。
除了支持常见的网络结构[卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurent Neural Network,RNN)]外,TensorFlow还支持深度强化学习乃至其他计算密集的科学计算(如偏微分方程求解等)。TensorFlow此前不支持symbolic loop,需要使用Python循环而无法进行图编译优化,但最近新加入的XLA已经开始支持JIT和AOT,另外它使用bucketing trick也可以比较高效地实现循环神经网络。TensorFlow的一个薄弱地方可能在于计算图必须构建为静态图,这让很多计算变得难以实现,尤其是序列预测中经常使用的beam search。
TensorFlow的用户能够将训练好的模型方便地部署到多种硬件、操作系统平台上,支持Intel和AMD的CPU,通过CUDA支持NVIDIA的GPU(最近也开始通过OpenCL支持AMD的GPU,但没有CUDA成熟),支持Linux和Mac,最近在0.12版本中也开始尝试支持Windows。在工业生产环境中,硬件设备有些是最新款的,有些是用了几年的老机型,来源可能比较复杂,TensorFlow的异构性让它能够全面地支持各种硬件和操作系统。同时,其在CPU上的矩阵运算库使用了Eigen而不是BLAS库,能够基于ARM架构编译和优化,因此在移动设备(android和ios)上表现得很好。
TensorFlow在最开始发布时只支持单机,而且只支持CUDA 6.5和cuDNN v2,并且没有官方和其他深度学习框架的对比结果。在2015年年底,许多其他框架做了各种性能对比评测,每次TensorFlow都会作为较差的对照组出现。那个时期的TensorFlow真的不快,性能上仅和普遍认为很慢的Theano比肩,在各个框架中可以算是垫底。但是凭借Google强大的开发实力,很快支持了新版的cuDNN(目前支持cuDNN v5.1),在单GPU上的性能追上了其他框架。表2-3所示为https://github.com/soumith/convnet-benchmarks给出的各个框架在AlexNet上单GPU的性能评测。
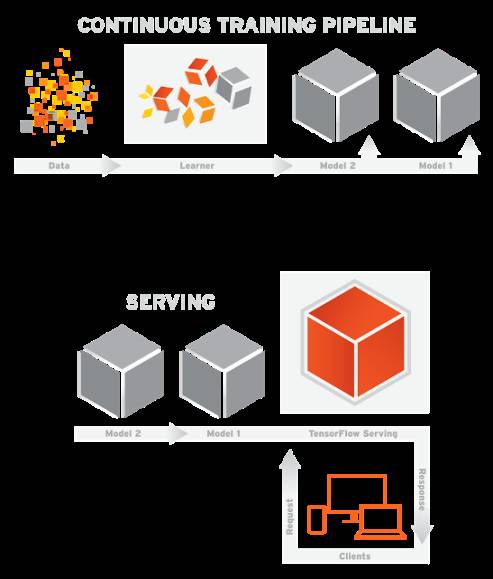
表2-3 各深度学习框架在AlexNet上的性能对比
目前在单GPU的条件下,绝大多数深度学习框架都依赖于cuDNN,因此只要硬件计算能力或者内存分配差异不大,最终训练速度不会相差太大。但是对于大规模深度学习来说,巨大的数据量使得单机很难在有限的时间完成训练。这时需要分布式计算使GPU集群乃至TPU集群并行计算,共同训练出一个模型,所以框架的分布式性能是至关重要的。TensorFlow在2016年4月开源了分布式版本,使用16块GPU可达单GPU的15倍提速,在50块GPU时可达到40倍提速,分布式的效率很高。目前原生支持的分布式深度学习框架不多,只有TensorFlow、CNTK、DeepLearning4J、MXNet等。不过目前TensorFlow的设计对不同设备间的通信优化得不是很好,其单机的reduction只能用CPU处理,分布式的通信使用基于socket的RPC,而不是速度更快的RDMA,所以其分布式性能可能还没有达到最优。
Google 在2016年2月开源了TensorFlow Serving,这个组件可以将TensorFlow训练好的模型导出,并部署成可以对外提供预测服务的RESTful接口,如图2-2所示。有了这个组件,TensorFlow就可以实现应用机器学习的全流程:从训练模型、调试参数,到打包模型,最后部署服务,名副其实是一个从研究到生产整条流水线都齐备的框架。这里引用TensorFlow内部开发人员的描述:“TensorFlow Serving是一个为生产环境而设计的高性能的机器学习服务系统。它可以同时运行多个大规模深度学习模型,支持模型生命周期管理、算法实验,并可以高效地利用GPU资源,让TensorFlow训练好的模型更快捷方便地投入到实际生产环境”。除了TensorFlow以外的其他框架都缺少为生产环境部署的考虑,而Google作为广泛在实际产品中应用深度学习的巨头可能也意识到了这个机会,因此开发了这个部署服务的平台。TensorFlow Serving可以说是一副王牌,将会帮TensorFlow成为行业标准做出巨大贡献。
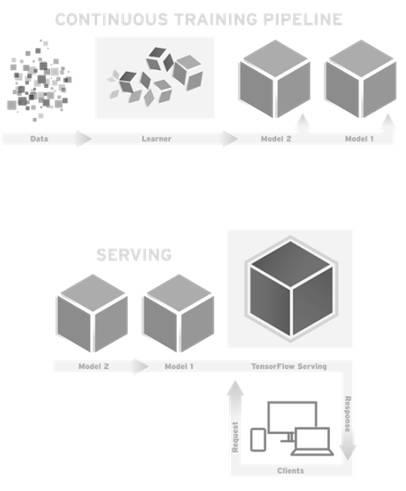
图2-2 TensorFlow Serving架构
TensorBoard是TensorFlow的一组Web应用,用来监控TensorFlow运行过程,或可视化Computation Graph。TensorBoard目前支持5种可视化:标量(scalars)、图片(images)、音频(audio)、直方图(histograms)和计算图(Computation Graph)。TensorBoard的Events Dashboard可以用来持续地监控运行时的关键指标,比如loss、学习速率(learning rate)或是验证集上的准确率(accuracy);Image Dashboard则可以展示训练过程中用户设定保存的图片,比如某个训练中间结果用Matplotlib等绘制(plot)出来的图片;Graph Explorer则可以完全展示一个TensorFlow的计算图,并且支持缩放拖曳和查看节点属性。TensorBoard的可视化效果如图2-3和图2-4所示。
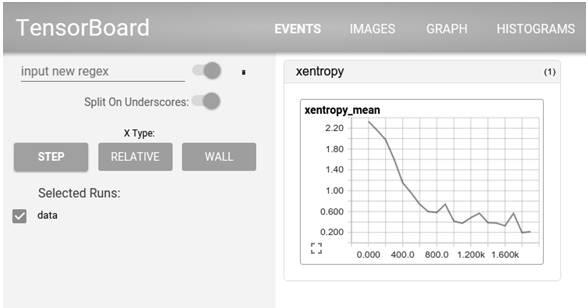
图2-3 TensorBoard的loss标量的可视化
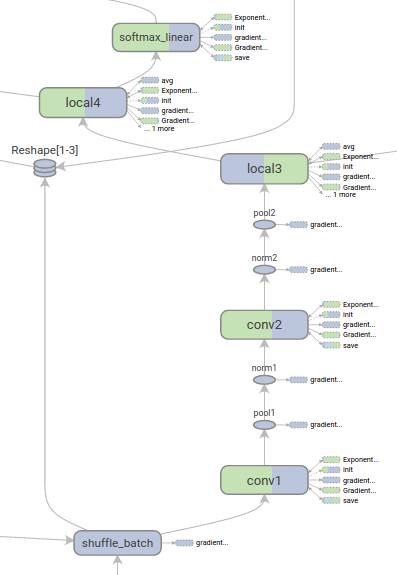
图2-4 TensorBoard的模型结构可视化
TensorFlow拥有产品级的高质量代码,有Google强大的开发、维护能力的加持,整体架构设计也非常优秀。相比于同样基于Python的老牌对手Theano,TensorFlow更成熟、更完善,同时Theano的很多主要开发者都去了Google开发TensorFlow(例如书籍Deep Learning的作者Ian Goodfellow,他后来去了OpenAI)。Google作为巨头公司有比高校或者个人开发者多得多的资源投入到TensorFlow的研发,可以预见,TensorFlow未来的发展将会是飞速的,可能会把大学或者个人维护的深度学习框架远远甩在身后。
Caffe
官方网址:caffe.berkeleyvision.org/
GitHub:github.com/BVLC/caffe
Caffe全称为Convolutional Architecture for Fast Feature Embedding,是一个被广泛使用的开源深度学习框架(在TensorFlow出现之前一直是深度学习领域GitHub star最多的项目),目前由伯克利视觉学中心(Berkeley Vision and Learning Center,BVLC)进行维护。Caffe的创始人是加州大学伯克利的Ph.D.贾扬清,他同时也是TensorFlow的作者之一,曾工作于MSRA、NEC和Google Brain,目前就职于Facebook FAIR实验室。Caffe的主要优势包括如下几点。
容易上手,网络结构都是以配置文件形式定义,不需要用代码设计网络。
训练速度快,能够训练state-of-the-art的模型与大规模的数据。
组件模块化,可以方便地拓展到新的模型和学习任务上。
Caffe的核心概念是Layer,每一个神经网络的模块都是一个Layer。Layer接收输入数据,同时经过内部计算产生输出数据。设计网络结构时,只需要把各个Layer拼接在一起构成完整的网络(通过写protobuf配置文件定义)。比如卷积的Layer,它的输入就是图片的全部像素点,内部进行的操作是各种像素值与Layer参数的convolution操作,最后输出的是所有卷积核filter的结果。每一个Layer需要定义两种运算,一种是正向(forward)的运算,即从输入数据计算输出结果,也就是模型的预测过程;另一种是反向(backward)的运算,从输出端的gradient求解相对于输入的gradient,即反向传播算法,这部分也就是模型的训练过程。实现新Layer时,需要将正向和反向两种计算过程的函数都实现,这部分计算需要用户自己写C++或者CUDA(当需要运行在GPU时)代码,对普通用户来说还是非常难上手的。正如它的名字Convolutional Architecture for Fast Feature Embedding所描述的,Caffe最开始设计时的目标只针对于图像,没有考虑文本、语音或者时间序列的数据,因此Caffe对卷积神经网络的支持非常好,但对时间序列RNN、LSTM等支持得不是特别充分。同时,基于Layer的模式也对RNN不是非常友好,定义RNN结构时比较麻烦。在模型结构非常复杂时,可能需要写非常冗长的配置文件才能设计好网络,而且阅读时也比较费力。
Caffe的一大优势是拥有大量的训练好的经典模型(AlexNet、VGG、Inception)乃至其他state-of-the-art(ResNet等)的模型,收藏在它的Model Zoo(github.com/BVLC/ caffe/wiki/Model-Zoo)。因为知名度较高,Caffe被广泛地应用于前沿的工业界和学术界,许多提供源码的深度学习的论文都是使用Caffe来实现其模型的。在计算机视觉领域Caffe应用尤其多,可以用来做人脸识别、图片分类、位置检测、目标追踪等。虽然Caffe主要是面向学术圈和研究者的,但它的程序运行非常稳定,代码质量比较高,所以也很适合对稳定性要求严格的生产环境,可以算是第一个主流的工业级深度学习框架。因为Caffe的底层是基于C++的,因此可以在各种硬件环境编译并具有良好的移植性,支持Linux、Mac和Windows系统,也可以编译部署到移动设备系统如Android和iOS上。和其他主流深度学习库类似,Caffe也提供了Python语言接口pycaffe,在接触新任务,设计新网络时可以使用其Python接口简化操作。不过,通常用户还是使用Protobuf配置文件定义神经网络结构,再使用command line进行训练或者预测。Caffe的配置文件是一个JSON类型的.prototxt文件,其中使用许多顺序连接的Layer来描述神经网络结构。Caffe的二进制可执行程序会提取这些.prototxt文件并按其定义来训练神经网络。理论上,Caffe的用户可以完全不写代码,只是定义网络结构就可以完成模型训练了。Caffe完成训练之后,用户可以把模型文件打包制作成简单易用的接口,比如可以封装成Python或MATLAB的API。不过在.prototxt文件内部设计网络节构可能会比较受限,没有像TensorFlow或者Keras那样在Python中设计网络结构方便、自由。更重要的是,Caffe的配置文件不能用编程的方式调整超参数,也没有提供像Scikit-learn那样好用的estimator可以方便地进行交叉验证、超参数的Grid Search等操作。Caffe在GPU上训练的性能很好(使用单块GTX 1080训练AlexNet时一天可以训练上百万张图片),但是目前仅支持单机多GPU的训练,没有原生支持分布式的训练。庆幸的是,现在有很多第三方的支持,比如雅虎开源的CaffeOnSpark,可以借助Spark的分布式框架实现Caffe的大规模分布式训练。
Theano
官方网址:http://www.deeplearning.net/software/theano/
GitHub:github.com/Theano/Theano
Theano诞生于2008年,由蒙特利尔大学Lisa Lab团队开发并维护,是一个高性能的符号计算及深度学习库。因其出现时间早,可以算是这类库的始祖之一,也一度被认为是深度学习研究和应用的重要标准之一。Theano的核心是一个数学表达式的编译器,专门为处理大规模神经网络训练的计算而设计。它可以将用户定义的各种计算编译为高效的底层代码,并链接各种可以加速的库,比如BLAS、CUDA等。Theano允许用户定义、优化和评估包含多维数组的数学表达式,它支持将计算装载到GPU(Theano在GPU上性能不错,但是CPU上较差)。与Scikit-learn一样,Theano也很好地整合了NumPy,对GPU的透明让Theano可以较为方便地进行神经网络设计,而不必直接写CUDA代码。Theano的主要优势如下。
集成NumPy,可以直接使用NumPy的ndarray,API接口学习成本低。
计算稳定性好,比如可以精准地计算输出值很小的函数(像log(1+x))。
动态地生成C或者CUDA代码,用以编译成高效的机器代码。
因为Theano非常流行,有许多人为它编写了高质量的文档和教程,用户可以方便地查找Theano的各种FAQ,比如如何保存模型、如何运行模型等。不过Theano更多地被当作一个研究工具,而不是当作产品来使用。虽然Theano支持Linux、Mac和Windows,但是没有底层C++的接口,因此模型的部署非常不方便,依赖于各种Python库,并且不支持各种移动设备,所以几乎没有在工业生产环境的应用。Theano在调试时输出的错误信息非常难以看懂,因此DEBUG时非常痛苦。同时,Theano在生产环境使用训练好的模型进行预测时性能比较差,因为预测通常使用服务器CPU(生产环境服务器一般没有GPU,而且GPU预测单条样本延迟高反而不如CPU),但是Theano在CPU上的执行性能比较差。
Theano在单GPU上执行效率不错,性能和其他框架类似。但是运算时需要将用户的Python代码转换成CUDA代码,再编译为二进制可执行文件,编译复杂模型的时间非常久。此外,Theano在导入时也比较慢,而且一旦设定了选择某块GPU,就无法切换到其他设备。目前,Theano在CUDA和cuDNN上不支持多GPU,只在OpenCL和Theano自己的gpuarray库上支持多GPU训练,速度暂时还比不上CUDA的版本,并且Theano目前还没有分布式的实现。不过,Theano在训练简单网络(比如很浅的MLP)时性能可能比TensorFlow好,因为全部代码都是运行时编译,不需要像TensorFlow那样每次feed mini-batch数据时都得通过低效的Python循环来实现。
Theano是一个完全基于Python(C++/CUDA代码也是打包为Python字符串)的符号计算库。用户定义的各种运算,Theano可以自动求导,省去了完全手工写神经网络反向传播算法的麻烦,也不需要像Caffe一样为Layer写C++或CUDA代码。Theano对卷积神经网络的支持很好,同时它的符号计算API支持循环控制(内部名scan),让RNN的实现非常简单并且高性能,其全面的功能也让Theano可以支持大部分state-of-the-art的网络。Theano派生出了大量基于它的深度学习库,包括一系列的上层封装,其中有大名鼎鼎的Keras,Keras对神经网络抽象得非常合适,以至于可以随意切换执行计算的后端(目前同时支持Theano和TensorFlow)。Keras比较适合在探索阶段快速地尝试各种网络结构,组件都是可插拔的模块,只需要将一个个组件(比如卷积层、激活函数等)连接起来,但是设计新模块或者新的Layer就不太方便了。除Keras外,还有学术界非常喜爱的Lasagne,同样也是Theano的上层封装,它对神经内网络的每一层的定义都非常严谨。另外,还有scikit-neuralnetwork、nolearn这两个基于Lasagne的上层封装,它们将神经网络抽象为兼容Scikit-learn接口的classifier和regressor,这样就可以方便地使用Scikit-learn中经典的fit、transform、score等操作。除此之外,Theano的上层封装库还有blocks、deepy、pylearn2和Scikit-theano,可谓是一个庞大的家族。如果没有Theano,可能根本不会出现这么多好用的Python深度学习库。同样,如果没有Python科学计算的基石NumPy,就不会有SciPy、Scikit-learn和 Scikit-image,可以说Theano就是深度学习界的NumPy,是其他各类Python深度学习库的基石。虽然Theano非常重要,但是直接使用Theano设计大型的神经网络还是太烦琐了,用 Theano实现Google Inception就像用NumPy实现一个支持向量机(SVM)。且不说很多用户做不到用Theano实现一个Inception网络,即使能做到但是否有必要花这个时间呢?毕竟不是所有人都是基础科学工作者,大部分使用场景还是在工业应用中。所以简单易用是一个很重要的特性,这也就是其他上层封装库的价值所在:不需要总是从最基础的tensor粒度开始设计网络,而是从更上层的Layer粒度设计网络。
Torch
官方网址:http://torch.ch/
GitHub:github.com/torch/torch7
Torch给自己的定位是LuaJIT上的一个高效的科学计算库,支持大量的机器学习算法,同时以GPU上的计算优先。Torch的历史非常悠久,但真正得到发扬光大是在Facebook开源了其深度学习的组件之后,此后包括Google、Twitter、NYU、IDIAP、Purdue等组织都大量使用Torch。Torch的目标是让设计科学计算算法变得便捷,它包含了大量的机器学习、计算机视觉、信号处理、并行运算、图像、视频、音频、网络处理的库,同时和Caffe类似,Torch拥有大量的训练好的深度学习模型。它可以支持设计非常复杂的神经网络的拓扑图结构,再并行化到CPU和GPU上,在Torch上设计新的Layer是相对简单的。它和TensorFlow一样使用了底层C++加上层脚本语言调用的方式,只不过Torch使用的是Lua。Lua的性能是非常优秀的(该语言经常被用来开发游戏),常见的代码可以通过透明的JIT优化达到C的性能的80%;在便利性上,Lua的语法也非常简单易读,拥有漂亮和统一的结构,易于掌握,比写C/C++简洁很多;同时,Lua拥有一个非常直接的调用C程序的接口,可以简便地使用大量基于C的库,因为底层核心是C写的,因此也可以方便地移植到各种环境。Lua支持Linux、Mac,还支持各种嵌入式系统(iOS、Android、FPGA等),只不过运行时还是必须有LuaJIT的环境,所以工业生产环境的使用相对较少,没有Caffe和TensorFlow那么多。
为什么不简单地使用Python而是使用LuaJIT呢?官方给出了以下几点理由。
LuaJIT的通用计算性能远胜于Python,而且可以直接在LuaJIT中操作C的pointers。
Torch的框架,包含Lua是自洽的,而完全基于Python的程序对不同平台、系统移植性较差,依赖的外部库较多。
LuaJIT的FFI拓展接口非常易学,可以方便地链接其他库到Torch中。Torch中还专门设计了N-Dimension array type的对象Tensor,Torch中的Tensor是一块内存的视图,同时一块内存可能有许多视图(Tensor)指向它,这样的设计同时兼顾了性能(直接面向内存)和便利性。同时,Torch还提供了不少相关的库,包括线性代数、卷积、傅里叶变换、绘图和统计等,如图2-5所示。

图2-5 Torch提供的各种数据处理的库
Torch的nn库支持神经网络、自编码器、线性回归、卷积网络、循环神经网络等,同时支持定制的损失函数及梯度计算。Torch因为使用了LuaJIT,因此用户在Lua中做数据预处理等操作可以随意使用循环等操作,而不必像在Python中那样担心性能问题,也不需要学习Python中各种加速运算的库。不过,Lua相比Python还不是那么主流,对大多数用户有学习成本。Torch在CPU上的计算会使用OpenMP、SSE进行优化,GPU上使用CUDA、cutorch、cunn、cuDNN进行优化,同时还有cuda-convnet的wrapper。Torch有很多第三方的扩展可以支持RNN,使得Torch基本支持所有主流的网络。和Caffe类似的是,Torch也是主要基于Layer的连接来定义网络的。Torch中新的Layer依然需要用户自己实现,不过定义新Layer和定义网络的方式很相似,非常简便,不像Caffe那么麻烦,用户需要使用C++或者CUDA定义新Layer。同时,Torch属于命令式编程模式,不像Theano、TensorFlow属于声明性编程(计算图是预定义的静态的结构),所以用它实现某些复杂操作(比如beam search)比Theano和TensorFlow方便很多。
Lasagne
官网网址:http://lasagne.readthedocs.io/
GitHub:github.com/Lasagne/Lasagne
Lasagne是一个基于Theano的轻量级的神经网络库。它支持前馈神经网络,比如卷积网络、循环神经网络、LSTM等,以及它们的组合;支持许多优化方法,比如Nesterov momentum、RMSprop、ADAM等;它是Theano的上层封装,但又不像Keras那样进行了重度的封装,Keras隐藏了Theano中所有的方法和对象,而Lasagne则是借用了Theano中很多的类,算是介于基础的Theano和高度抽象的Keras之间的一个轻度封装,简化了操作同时支持比较底层的操作。Lasagne设计的六个原则是简洁、透明、模块化、实用、聚焦和专注。
Keras
官方网址:keras.io
GitHub:github.com/fchollet/keras
Keras是一个崇尚极简、高度模块化的神经网络库,使用Python实现,并可以同时运行在TensorFlow和Theano上。它旨在让用户进行最快速的原型实验,让想法变为结果的这个过程最短。Theano和TensorFlow的计算图支持更通用的计算,而Keras则专精于深度学习。Theano和TensorFlow更像是深度学习领域的NumPy,而Keras则是这个领域的Scikit-learn。它提供了目前为止最方便的API,用户只需要将高级的模块拼在一起,就可以设计神经网络,它大大降低了编程开销(code overhead)和阅读别人代码时的理解开销(cognitive overhead)。它同时支持卷积网络和循环网络,支持级联的模型或任意的图结构的模型(可以让某些数据跳过某些Layer和后面的Layer对接,使得创建Inception等复杂网络变得容易),从CPU上计算切换到GPU加速无须任何代码的改动。因为底层使用Theano或TensorFlow,用Keras训练模型相比于前两者基本没有什么性能损耗(还可以享受前两者持续开发带来的性能提升),只是简化了编程的复杂度,节约了尝试新网络结构的时间。可以说模型越复杂,使用Keras的收益就越大,尤其是在高度依赖权值共享、多模型组合、多任务学习等模型上,Keras表现得非常突出。Keras所有的模块都是简洁、易懂、完全可配置、可随意插拔的,并且基本上没有任何使用限制,神经网络、损失函数、优化器、初始化方法、激活函数和正则化等模块都是可以自由组合的。Keras也包括绝大部分state-of-the-art的Trick,包括Adam、RMSProp、Batch Normalization、PReLU、ELU、LeakyReLU等。同时,新的模块也很容易添加,这让Keras非常适合最前沿的研究。Keras中的模型也都是在Python中定义的,不像Caffe、CNTK等需要额外的文件来定义模型,这样就可以通过编程的方式调试模型结构和各种超参数。在Keras中,只需要几行代码就能实现一个MLP,或者十几行代码实现一个AlexNet,这在其他深度学习框架中基本是不可能完成的任务。Keras最大的问题可能是目前无法直接使用多GPU,所以对大规模的数据处理速度没有其他支持多GPU和分布式的框架快。Keras的编程模型设计和Torch很像,但是相比Torch,Keras构建在Python上,有一套完整的科学计算工具链,而Torch的编程语言Lua并没有这样一条科学计算工具链。无论从社区人数,还是活跃度来看,Keras目前的增长速度都已经远远超过了Torch。
MXNet
官网网址:mxnet.io
GitHub:github.com/dmlc/mxnet
MXNet是DMLC(Distributed Machine Learning Community)开发的一款开源的、轻量级、可移植的、灵活的深度学习库,它让用户可以混合使用符号编程模式和指令式编程模式来最大化效率和灵活性,目前已经是AWS官方推荐的深度学习框架。MXNet的很多作者都是中国人,其最大的贡献组织为百度,同时很多作者来自cxxnet、minerva和purine2等深度学习项目,可谓博采众家之长。它是各个框架中率先支持多GPU和分布式的,同时其分布式性能也非常高。MXNet的核心是一个动态的依赖调度器,支持自动将计算任务并行化到多个GPU或分布式集群(支持AWS、Azure、Yarn等)。它上层的计算图优化算法可以让符号计算执行得非常快,而且节约内存,开启mirror模式会更加省内存,甚至可以在某些小内存GPU上训练其他框架因显存不够而训练不了的深度学习模型,也可以在移动设备(Android、iOS)上运行基于深度学习的图像识别等任务。此外,MXNet的一个很大的优点是支持非常多的语言封装,比如C++、Python、R、Julia、Scala、Go、MATLAB和javascript等,可谓非常全面,基本主流的脚本语言全部都支持了。在MXNet中构建一个网络需要的时间可能比Keras、Torch这类高度封装的框架要长,但是比直接用Theano等要快。MXNet的各级系统架构(下面为硬件及操作系统底层,逐层向上为越来越抽象的接口)如图2-6所示。
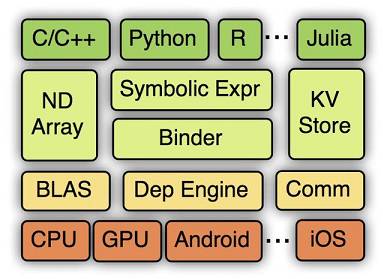
图2-6 MXNet系统架构
DIGITS
官方网址:developer.nvidia.com/digits
GitHub: github.com/NVIDIA/DIGITS
DIGITS(Deep Learning GPU Training System)不是一个标准的深度学习库,它可以算是一个Caffe的高级封装(或者Caffe的Web版培训系统)。因为封装得非常重,以至于你不需要(也不能)在DIGITS中写代码,即可实现一个深度学习的图片识别模型。在Caffe中,定义模型结构、预处理数据、进行训练并监控训练过程是相对比较烦琐的,DIGITS把所有这些操作都简化为在浏览器中执行。它可以算作Caffe在图片分类上的一个漂亮的用户可视化界面(GUI),计算机视觉的研究者或者工程师可以非常方便地设计深度学习模型、测试准确率,以及调试各种超参数。同时使用它也可以生成数据和训练结果的可视化统计报表,甚至是网络的可视化结构图。训练好的Caffe模型可以被DIGITS直接使用,上传图片到服务器或者输入url即可对图片进行分类。
CNTK
官方网址:cntk.ai
GitHub:github.com/Microsoft/CNTK
CNTK(Computational Network Toolkit)是微软研究院(MSR)开源的深度学习框架。它最早由start the deep learning craze的演讲人创建,目前已经发展成一个通用的、跨平台的深度学习系统,在语音识别领域的使用尤其广泛。CNTK通过一个有向图将神经网络描述为一系列的运算操作,这个有向图中子节点代表输入或网络参数,其他节点代表各种矩阵运算。CNTK支持各种前馈网络,包括MLP、CNN、RNN、LSTM、Sequence-to-Sequence模型等,也支持自动求解梯度。CNTK有丰富的细粒度的神经网络组件,使得用户不需要写底层的C++或CUDA,就能通过组合这些组件设计新的复杂的Layer。CNTK拥有产品级的代码质量,支持多机、多GPU的分布式训练。
CNTK设计是性能导向的,在CPU、单GPU、多GPU,以及GPU集群上都有非常优异的表现。同时微软最近推出的1-bit compression技术大大降低了通信代价,让大规模并行训练拥有了很高的效率。CNTK同时宣称拥有很高的灵活度,它和Caffe一样通过配置文件定义网络结构,再通过命令行程序执行训练,支持构建任意的计算图,支持AdaGrad、RmsProp等优化方法。它的另一个重要特性就是拓展性,CNTK除了内置的大量运算核,还允许用户定义他们自己的计算节点,支持高度的定制化。CNTK在2016年9月发布了对强化学习的支持,同时,除了通过写配置文件的方式定义网络结构,CNTK还将支持其他语言的绑定,包括Python、C++和C#,这样用户就可以用编程的方式设计网络结构。CNTK与Caffe一样也基于C++并且跨平台,大部分情况下,它的部署非常简单。PC上支持Linux、Mac和Windows,但是它目前不支持ARM架构,限制了其在移动设备上的发挥。图2-7所示为CNTK目前的总体架构图。
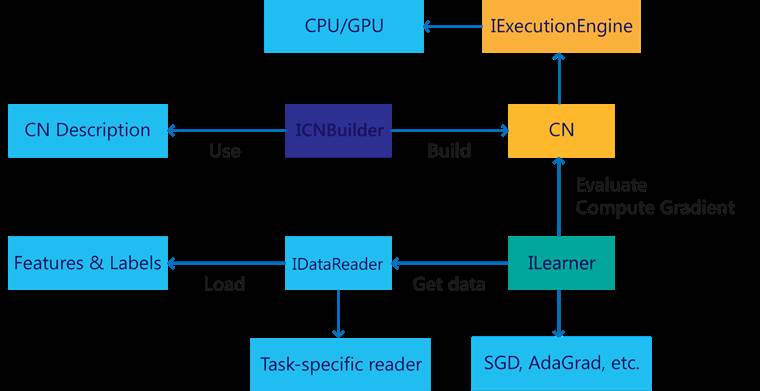
图2-7 CNTK的总体架构图
CNTK原生支持多GPU和分布式,从官网公布的对比评测来看,性能非常不错。在多GPU方面,CNTK相对于其他的深度学习库表现得更突出,它实现了1-bit SGD和自适应的mini-batching。图2-8所示为CNTK官网公布的在2015年12月的各个框架的性能对比。在当时,CNTK是唯一支持单机8块GPU的框架,并且在分布式系统中可以超越8块GPU的性能。
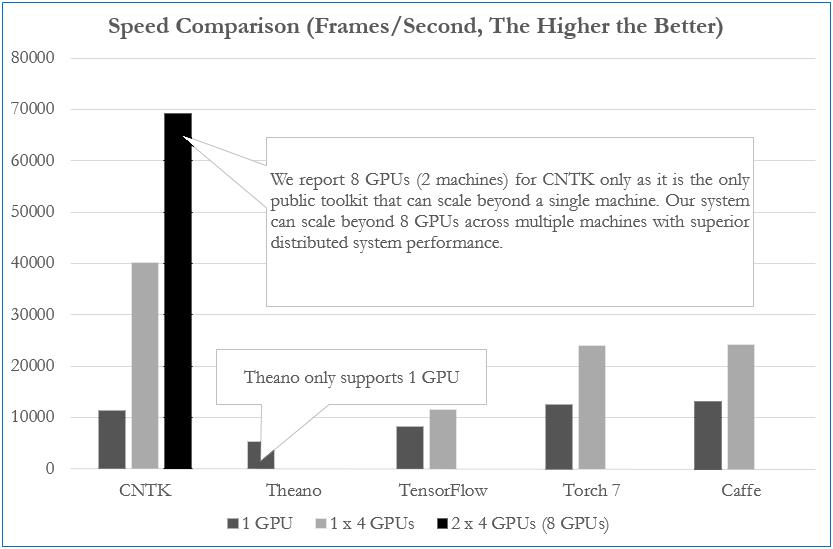
图2-8 CNTK与各个框架的性能对比
Deeplearning4J
官方网址:http://deeplearning4j.org/
GitHub: github.com/deeplearning4j/deeplearning4j
Chainer
官方网址:chainer.org
GitHub:github.com/pfnet/chainer
Chainer是由日本公司Preferred Networks于2015年6月发布的深度学习框架。Chainer对自己的特性描述如下。
Powerful:支持CUDA计算,只需要几行代码就可以使用GPU加速,同时只需少许改动就可以运行在多GPU上。
Flexible:支持多种前馈神经网络,包括卷积网络、循环网络、递归网络,支持运行中动态定义的网络(Define-by-Run)。
Intuitive:前馈计算可以引入Python的各种控制流,同时反向传播时不受干扰,简化了调试错误的难度。
绝大多数的深度学习框架是基于“Define-and-Run”的,也就是说,需要首先定义一个网络,再向网络中feed数据(mini-batch)。因为网络是预先静态定义的,所有的控制逻辑都需要以data的形式插入网络中,包括像Caffe那样定义好网络结构文件,或者像Theano、Torch、TensorFlow等使用编程语言定义网络。而Chainer则相反,网络是在实际运行中定义的,Chainer存储历史运行的计算结果,而不是网络的结构逻辑,这样就可以方便地使用Python中的控制流,所以无须其他工作就可以直接在网络中使用条件控制和循环。
Leaf
官方网址:autumnai.com/leaf/book
GitHub:github.com/autumnai/leaf
Leaf是一个基于Rust语言的直观的跨平台的深度学习乃至机器智能框架,它拥有一个清晰的架构,除了同属Autumn AI的底层计算库Collenchyma,Leaf没有其他依赖库。它易于维护和使用,并且拥有非常高的性能。Leaf自身宣传的特点是为Hackers定制的,这里的Hackers是指希望用最短的时间和最少的精力实现机器学习算法的技术极客。它的可移植性非常好,可以运行在CPU、GPU和FPGA等设备上,可以支持有任何操作系统的PC、服务器,甚至是没有操作系统的嵌入式设备,并且同时支持OpenCL和CUDA。Leaf是Autumn AI计划的一个重要组件,后者的目标是让人工智能算法的效率提高100倍。凭借其优秀的设计,Leaf可以用来创建各种独立的模块,比如深度强化学习、可视化监控、网络部署、自动化预处理和大规模产品部署等。
Leaf拥有最简单的API,希望可以最简化用户需要掌握的技术栈。虽然才刚诞生不久,Leaf就已经跻身最快的深度学习框架之一了。图2-9所示为Leaf官网公布的各个框架在单GPU上训练VGG网络的计算时间(越小越好)的对比(这是和早期的TensorFlow对比,最新版的TensorFlow性能已经非常好了)。
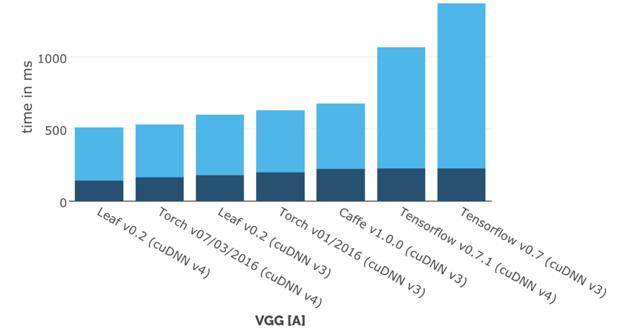
图2-9 Leaf和各深度学习框架的性能对比(深色为forawrd,浅色为backward)
DSSTNE
GitHub:github.com/amznlabs/amazon-dsstne
DSSTNE(Deep Scalable Sparse Tensor Network Engine)是亚马逊开源的稀疏神经网络框架,在训练非常稀疏的数据时具有很大的优势。DSSTNE目前只支持全连接的神经网络,不支持卷积网络等。和Caffe类似,它也是通过写一个JSON类型的文件定义模型结构,但是支持非常大的Layer(输入和输出节点都非常多);在激活函数、初始化方式及优化器方面基本都支持了state-of-the-art的方法,比较全面;支持大规模分布式的GPU训练,不像其他框架一样主要依赖数据并行,DSSTNE支持自动的模型并行(使用数据并行需要在训练速度和模型准确度上做一定的trade-off,模型并行没有这个问题)。
在处理特征非常多(上亿维)的稀疏训练数据时(经常在推荐、广告、自然语言处理任务中出现),即使一个简单的3个隐层的MLP(Multi-Layer Perceptron)也会变成一个有非常多参数的模型(可能高达上万亿)。以传统的稠密矩阵的方式训练方法很难处理这么多的模型参数,更不必提超大规模的数据量,而DSSTNE有整套的针对稀疏数据的优化,率先实现了对超大稀疏数据训练的支持,同时在性能上做了非常大的改进。
在DSSTNE官方公布的测试中,DSSTNE在MovieLens的稀疏数据上,在单M40 GPU上取得了比TensorFlow快14.8倍的性能提升(注意是和老版的TensorFlow比较),如图2-10所示。一方面是因为DSSTNE对稀疏数据的优化;另一方面是TensorFlow在数据传输到GPU上时花费了大量时间,而DSSTNE则优化了数据在GPU内的保留;同时DSSTNE还拥有自动模型并行功能,而TensorFlow中则需要手动优化,没有自动支持。
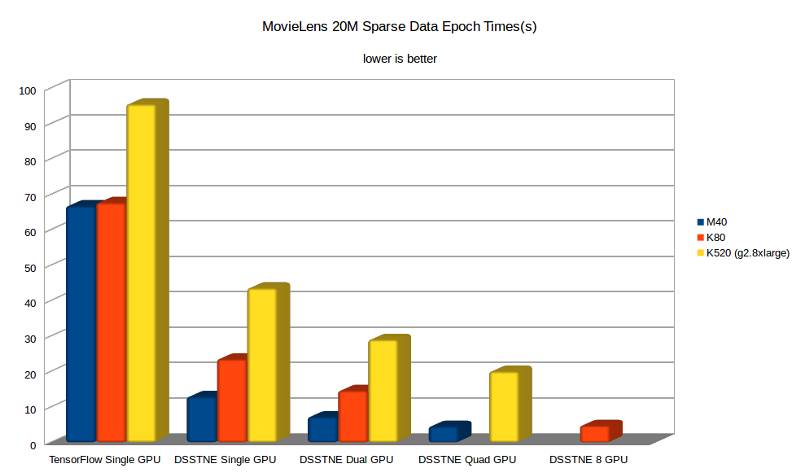
图2-10 DSSTNE在稀疏数据上与TensorFlow的性能对比
《TensorFlow实战》是国内首本由Google TensorFlow团队官方推荐的教程,两位作者也均是TensorFlow开发者,其中唐源是TensorFlow开发团队的committer。本书结合了大量实例代码,深入浅出地介绍了如何使用TensorFlow创建各种深度学习模型,是初学者入门的最佳书籍。订购链接:https://item.jd.com/12125568.html
以上是关于赠书TensorFlow和CaffeMXNetKeras等其他深度学习框架的对比的主要内容,如果未能解决你的问题,请参考以下文章
赠书 | JavaScript 武力值飙升!用 TensorFlow.js 轻松在浏览器里搞深度学习
送书 |《TensorFlow+PyTorch 深度学习从算法到实战》