深度|PaddlePaddle与TensorFlow的对比分析
Posted AI推手
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度|PaddlePaddle与TensorFlow的对比分析相关的知识,希望对你有一定的参考价值。
本文主要从框架概览、系统架构、编程模型、分布式架构、框架对比这五大方面比较TensorFlow和PaddlePaddle框架。作为国际两大搜索引擎研发的深度学习框架,使用侧重点不同,却同样提供了优雅简洁的设计架构,并且还在不断发展。
对于PaddlePaddle来说,它的易用性和本土性、快速业务集成性,对国内以速度致胜的互联网公司是一个非常有利的武器;而TensorFlow的灵活性和相对偏科研性,是AI研究领域的一大利好。
框架概览
PaddlePaddle的研发始于2013年,伴随着百度广告、文本、图像、语音等训练数据的快速增长,以及百度外卖、搜索、无人驾驶领域的算法要求,百度深度学习实验室在基于单GPU训练平台的基础上,研发了Paddle(Parallel Asynchronous Distributed Deep Learning)这个多机并行GPU这个训练平台。
PaddlePaddle自开源以来,它的设计和定位就一直集中在“易用、高效、灵活、可扩展”上。正如官网的设计定位: An Easy-to-use, Efficient, Flexible and Scalable Deep Learning Platform 。下图是Paddle的官方网站:
PaddlePaddle框架的开源始于2016年9月份,它最大的特点和定位是easy to use,因此对很多算法进行了完整的封装,不仅是针对只目前现成的CV、NLP等算法 (如VGG、ResNet、LSTM、GRU等),它在模型库models(https://github.com/PaddlePaddle/models)模块下,封装了词向量(包括Hsigmoid加速词向量训练和噪声对比估计加速词向量训练)、RNN 语言模型、点击率预估、文本分类、排序学习(信息检索和搜索引擎研究的核心问题之一)、结构化语义模型、命名实体识别、序列到序列学习、阅读理解、自动问答、图像分类、目标检测、场景文字识别、语音识别等多个技术领域人工智能的通用解决方案。
上述的每个解决方案都是针对某个技术场景而设计,因此,开发者可能只需要略微了解下源码原理,按照官网的示例执行运行的命令,更换成自己的数据、修改一些超参数就能运行起来。并且因为没有向用户暴露过多的python接口,理解和使用起来还比较容易。但是因为侧重在使用,在科研或者新增功能方面,如果修改算法,需要从框架的C++底层开始实现。
它的第二大特色是分布式部署,并且是目前是唯一很好的支持Kubernetes的深度学习库。在本文的“分布式架构”中会进一步说明。
TensorFlow官网上对TensorFlow的描述是 An open-source software library for Machine Intelligence,一个开源的机器学习库。

从使用人数和活跃度上来说,TensorFlow是目前最流行的人工智能的算法引擎。它提供了深度学习的基本元素的实现,例如conv、pooling、lstm和其它的基本算子。如下图是TensorFlow支持的常用算子:
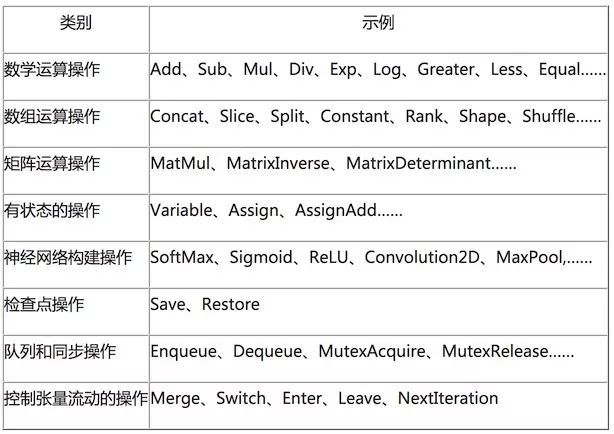
2016年4月,TensorFlow的0.8版本就支持了分布式、支持多GPU运算。2016年6月,TensorFlow的0.9版本改进了对移动设备的支持。
2017年2月,TensorFlow的1.0正式版本中,增加了Java和Go的实验性API,以及专用编译器XLA和调试工具Debugger,还发布了tf.transform,专门用来数据预处理。
同时,围绕着模型部署推出了TensorFlow Serving,用于将算法动态部署到线上;以及逐步完善的类似于scikit-learn功能的tf.contrib.learn。并且还推出了“动态图计算”TensorFlow Fold,这是被评价为“第一次清晰地在设计理念上领先”
用户还可以使用谷歌公司的PaaS TensorFlow产品Cloud Machine Learning来做分布式训练。现在也已经有了完整的TensorFlow Model Zoo。
2018年1月,TensorFlow已经支持到1.5.0版本,完整开放了TensorFlow Lite移动端应用以及动态图机制Eager Execution,使得调试即刻的运行错误并和Python 工具进行整合。
TensorFlow的一大亮点是支持异构设备分布式计算
何为异构?信息技术当中的异构是指包含不同的成分,有异构网络(如互联网,不同厂家的硬件软件产品组成统一网络且互相通信)、异构数据库(多个数据库系统的集合,可以实现数据的共享和透明访问)。
这里的异构设备是指使用CPU、GPU等核心进行有效地协同合作;与只依靠CPU相比,性能更高,功耗更低。
那何为分布式?分布式架构目的在于帮助我们调度和分配计算资源(甚至容错,如某个计算节点宕机或者太慢),使得上千万、上亿数据量的模型能够有效地利用机器资源进行训练。
总结来看,目前AI领域有几大主流的框架,而今天我们所对比的这两个框架的共性就是有都有下面的一些特点。我们参考《The Unreasonable Effectiveness of Recurrent Neural Networks》,这篇文章梳理了一个有效框架应该具有的功能。
Tensor库是对CPU/GPU透明的,并且实现了很多操作(如切片、数组或矩阵操作等)。这里的透明是指,在不同设备上如何运行,都是框架帮用户去实现的,用户只需要指定在哪个设备上进行哪种运算即可。
有一个完全独立的代码库,用脚本语言(最理想的是Python)来操作Tensors,并且实现所有深度学习的内容,包括前向传播/反向传播、图形计算等。
可以轻松地共享预训练模型(如Caffe的模型及TensorFlow中的slim模块、PaddlePaddle的models模块)。
没有编译过程。深度学习是朝着更大、更复杂的网络发展的,因此在复杂图算法中花费的时间会成倍增加。而且,进行编译的话会丢失可解释性和有效进行日志调试的能力。
那么PaddlePaddle 对开发者来说有什么优势?
首先,是易用性。相比偏底层的谷歌 TensorFlow,PaddlePaddle 的易用特点非常明显:它让开发者开发精力放在构建深度学习模型的高层部分。
除此之外,PaddlePadddle 是国内巨头百度开源的框架,他的本土性不仅非常符合国人的使用习惯,而且非常重视主流互联网技术的使用场景和解决方法。
其次,是更快的速度。如上所说,PaddlePaddle 的代码和设计更加简洁,用它来开发模型显然能为开发者省去一些时间。这使得 PaddlePaddle 很适合于工业应用,尤其是需要快速开发的场景。
我们知道,系统架构就直接决定了框架设计的根本不同,现在我们就一起窥探一番。
系统架构
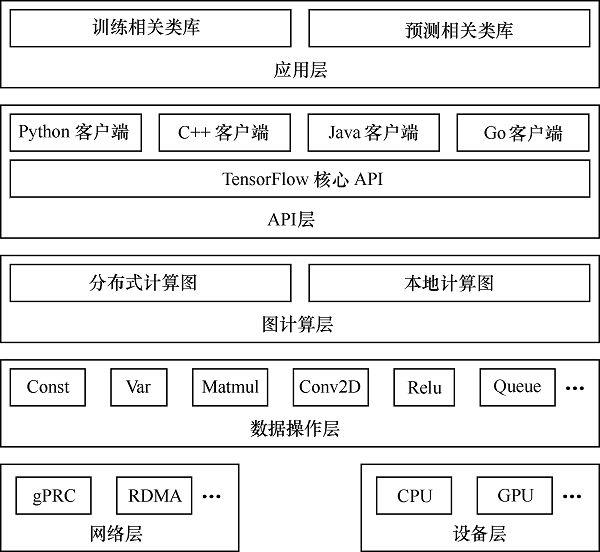
下图给出的是TensorFlow的系统架构,自底向上分为设备层和网络层、数据操作层、图计算层、API层、应用层,其中设备层和网络层、数据操作层、图计算层是TensorFlow的核心层。
下面就自底向上详细介绍一下TensorFlow的系统架构。最下层是网络通信层和设备管理层。网络通信层包括gRPC(google Remote Procedure Call Protocol)和远程直接数据存取(Remote Direct Memory Access,RDMA),这都是在分布式计算时需要用到的。设备管理层包括TensorFlow分别在CPU、GPU、FPGA等设备上的实现,也就是对上层提供了一个统一的接口,使上层只需要处理卷积等逻辑,而不需要关心在硬件上的卷积的实现过程。
其上是数据操作层,主要包括卷积函数、激活函数等操作。再往上是图计算层,也是我们要了解的核心,包含本地计算图和分布式计算图的实现(包括图的创建、编译、优化和执行)。再往上是API层和应用层。
可能因为历史遗留原因,PaddlePaddle整体架构思路和caffe有些类似,是基于神经网络中的功能层来开发的,一个层包括了许多复杂的操作,如下图中展示了目前包括FCN、CTC、BN、LSTM多种功能层。

并且它将数据读取(DataProvider)、功能层(Layers)、优化方式(Optimizer)、评估(Evaluators)、激活函数(Activation)、池化(Pooling)这几个过程分布实现成类,构建PaddlePaddle的神经网络的过程就是组合这些层构成整个网络。
如下图所示:

同时,在一层一层累加之外,为了提高灵活性,还额外封装好了的networks类,也就是设置mixed_layer来组合不同的输入,
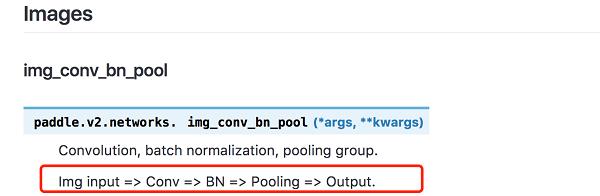
如下图。这里面封装了一些可能需要的组合,如conv+batchnorm+pooling,它可以极大的简化构建神经网络的方式。使用更少的代码,依据成熟的算法构建网络的同时,修改数据的输入就可以顺利运行。
编程模型
Paddle目前整体模块如下图所示:
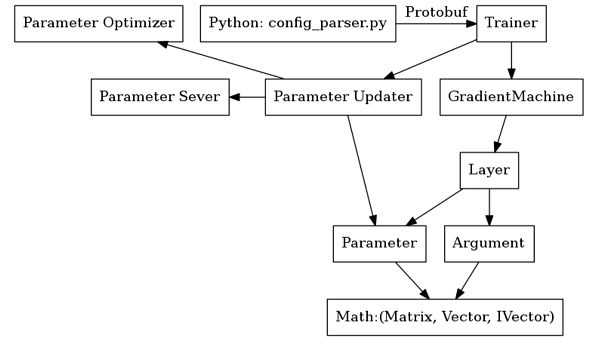
Math模块是Paddle的数学计算模块。其中有各种矩阵和向量的实现,矩阵和向量基类是BaseMatrix。这个模块里主体分为两个部分。
Matrix/Vector: Paddle中实现计算逻辑的类型。本质上是MemoryHandle的一个view。
矩阵和向量组成了神经网络的参数Parameter和神经网络层的输入和输出Arguments。
Parameter和Arguments表示神经网络中所有的数据和参数。其中Parameter表示神经网络中层与层之间的连接参数,而Argument表示每一层的输入和输出。即Parameter表示下图中的黄色连线,而Argument表示下图中的的输入和输出(Input, Output)。
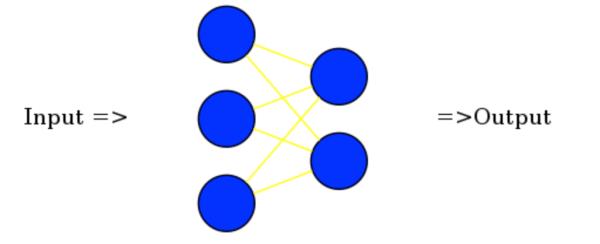
并且Parameter与Argument并不只保存了参数值,还同时保存了梯度,动量等信息。
Layer使用Argument和Parameter完成计算。
PaddlePaddle整体是一个基于Layer配置的神经网络框架。为了支持更细粒度的神经网络配置,支持配置op和projection,Paddle提供了MixedLayer。
MixedLayer和其他Layer不同,使用的输入类型不直接是其他Layer本身,而是其他Layer的projection或者operation。其他Layer的projection和operation的结果依次相加到MixedLayer的输出中。
GradientMachine是一个把神经网络各个层组合在一起调用的类型。这是个基类,具有神经网络常见的forward、backward函数,并且处理了单机多线程和多显卡的功能。
GradientMachine是PaddlePaddle中对于神经网络的一种抽象,即该数据类型可以计算出Gradient,进而将计算后的结果放入Parameter中即可。一个GradientMachine一般用来计算一个神经网络的拓扑结构。
进而,根据拓扑结构的形态,GradientMachine会创建一些parameters_,而forward根据输入的args和本地的参数,计算神经网络的前馈,而backward函数根据之前前馈的结果,计算出各个参数的梯度,并将各个参数的梯度保存在parameters_中。
Trainer调用GradientMachine计算出参数的梯度。
ParameterUpdaterParameterUpdater主要用于在gradientMachine通过forward backward计算出gradient之后,调用update算法更新参数。
Trainer优化的拓扑结构是Python端的config_parser.py程序生成的。
TensorFlow是用数据流图做计算的,因此我们先创建一个数据流图(也称为网络结构图),如图所示,看一下数据流图中的各个要素。
图中讲述了TensorFlow的运行原理。图中包含输入(input)、塑形(reshape)、Relu层(Relu layer)、Logit层(Logit layer)、Softmax、交叉熵(cross entropy)、梯度(gradient)、SGD训练(SGD Trainer)等部分,是一个简单的回归模型。
它的计算过程是,首先从输入开始,经过塑形后,一层一层进行前向传播运算。Relu层(隐藏层)里会有两个参数,即Wh1和bh1,在输出前使用ReLu(Rectified Linear Units)激活函数做非线性处理。然后进入Logit层(输出层),学习两个参数Wsm和bsm。用Softmax来计算输出结果中各个类别的概率分布。用交叉熵来度量两个概率分布(源样本的概率分布和输出结果的概率分布)之间的相似性。
然后开始计算梯度,这里是需要参数Wh1、bh1、Wsm和bsm,以及交叉熵后的结果。随后进入SGD训练,也就是反向传播的过程,从上往下计算每一层的参数,依次进行更新。也就是说,计算和更新的顺序为bsm、Wsm、bh1和 Wh1。
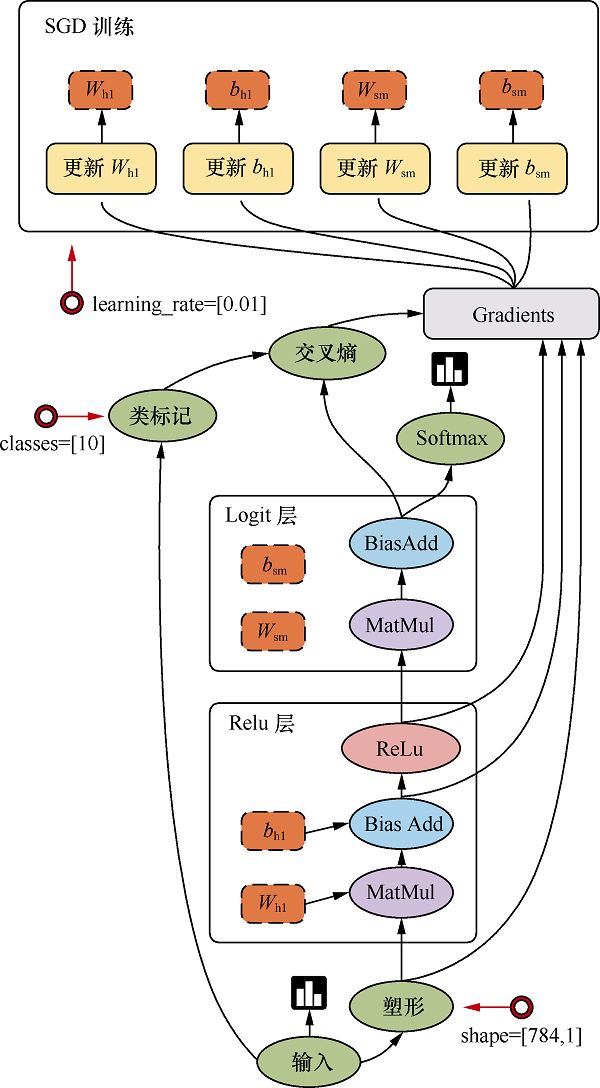
顾名思义,TensorFlow是指“张量的流动”。TensorFlow的数据流图是由节点(node)和边(edge)组成的有向无环图(directed acycline graph,DAG)。
TensorFlow由Tensor和Flow两部分组成,Tensor(张量)代表了数据流图中的边,而Flow(流动)这个动作就代表了数据流图中节点所做的操作。
那么,在分布式计算下,两种框架又各自有哪些实现特点呢?
分布式架构
PaddlePaddle的分布式结构主要有两个部分,trainer和parameter server。分布式训练架构如下图所示:
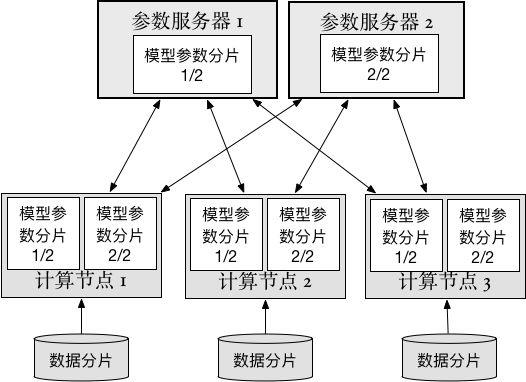
数据分片(Data shard): 用于训练神经网络的数据,被切分成多个部分,每个部分分别给每个trainer使用。
计算节点(Trainer): 每个trainer启动后读取切分好的一部分数据,开始神经网络的“前馈”和“后馈”计算,并和参数服务器通信。在完成一定量数据的训练后,上传计算得出的梯度(gradients),然后下载优化更新后的神经网络参数(parameters)。
参数服务器(Parameter server):每个参数服务器只保存整个神经网络所有参数的一部分。参数服务器接收从计算节点上传的梯度,并完成参数优化更新,再将更新后的参数下发到每个计算节点。
在使用同步SGD训练神经网络时,PaddlePaddle使用同步屏障(barrier),使梯度的提交和参数的更新按照顺序方式执行。在异步SGD中,则并不会等待所有trainer提交梯度才更新参数,这样极大地提高了计算的并行性:参数服务器之间不相互依赖,并行地接收梯度和更新参数,参数服务器也不会等待计算节点全部都提交梯度之后才开始下一步,计算节点之间也不会相互依赖,并行地执行模型的训练。可以看出,虽然异步SGD方式会提高参数更新并行度, 但是并不能保证参数同步更新,在任意时间某一台参数服务器上保存的参数可能比另一台要更新,与同步SGD相比,梯度会有噪声。
同时,Paddle本身支持多种分布式集群的部署和运行方式,包括fabric集群、openmpi集群、Kubernetes单机、Kubernetes distributed分布式等。
TensorFlow的分布式架构主要由客户端(client)和服务端(server)组成,服务端又包括主节点(master)和工作节点(worker)两者组成。我们需要关注客户端、主节点和工作节点这三者间的关系和它们的交互过程.
客户端、主节点和工作节点的关系
简单地来说,在TensorFlow中,客户端通过会话来联系主节点,实际的工作交由工作节点实现。每个工作节点占据一台设备(是TensorFlow具体计算的硬件抽象,即CPU或GPU)。在单机模式下,客户端、主节点和工作节点都在同一台服务器上;在分布式模式下,它们可以位于不同的服务器上。下图展示了这三者之间的关系。
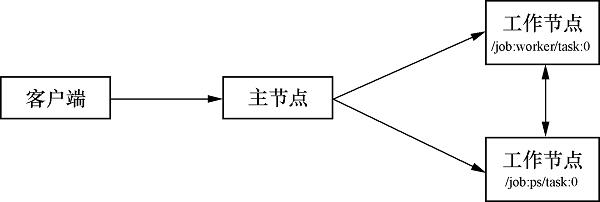
1.客户端
客户端用于建立TensorFlow计算图,并建立与集群进行交互的会话层。因此,代码中只要包含Session()就是客户端。一个客户端可以同时与多个服务端相连,同时一个服务端也可以与多个客户端相连
2.服务端
服务端是一个运行了tf.train.Server实例的进程,是TensorFlow执行任务的集群(cluster)的一部分,并有主节点服务(Master service,也叫主节点)和工作节点服务(Worker service,也叫工作节点)之分。运行中由一个主节点进程和数个工作节点进程组成,主节点进程和工作节点进程之间通过接口通信。单机多卡和分布式都是这种结构,因此只需要更改它们之间通信的接口就可以实现单机多卡和分布式的切换。
3.主节点服务
主节点服务实现了tensorflow::Session接口,通过RPC服务程序来远程连接工作节点,与工作节点的服务进程中的工作任务进行通信。在TensorFlow服务端中,一般是task_index为0的作业(job)。
4.工作节点服务
工作节点服务实现了worker_service.proto接口,使用本地设备对部分图进行计算。在TensorFlow服务端中,所有工作节点都包含工作节点的服务逻辑。每个工作节点负责管理一个或者多个设备。工作节点也可以是本地不同端口的不同进程,或者多台服务器上的多个进程。
下图左边是单机多卡的交互,右边是分布式的交互。
框架对比
下面是PaddlePaddle和TensorFlow在框架流行度和代码稳定性上的比较。可以看出,两个框架在活跃度、稳定性上都是一流,并且在代码质量上也不分伯仲。
对PaddlePaddle我这里列举以下Paddle的几个亮点的地方:
更易用的API,更好的封装,更快速的业务集成;
占用内存小,速度快,因为Paddle在百度内部也服务了众多大并发大数据场景,工业经验也很丰富;
本土化支持,也是唯一有官方中文文档的深度学习框架;
在自然语言处理上有很多现成的应用,比如情感分类,神经机器翻译,阅读理解、自动问答等,使用起来相对简单;
PaddlePaddle支持多机多卡训练,并且本身支持多种集群方式。
总结
本文主要从框架概览、系统架构、编程模型、分布式架构、框架对比等几个方面说明了PaddlePaddle和TensorFlow。总而言之,“易学易用、灵活高效”是PaddlePaddle的最大亮点,非常适合传统互联网引入AI模块的集成,设计清晰也在研究方面也有所助力;除此之前,分布式架构支持的多种集群环境,可以较轻松地和企业的分布式架构结合。相信随着众多好用的模型的不断释出,一定会让你在业务中找到满意易用的算法方案。
以上是关于深度|PaddlePaddle与TensorFlow的对比分析的主要内容,如果未能解决你的问题,请参考以下文章