飞桨PaddlePaddle最新升级:更低门槛使用深度学习
Posted NEWS SCIENCES LITERATURE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了飞桨PaddlePaddle最新升级:更低门槛使用深度学习相关的知识,希望对你有一定的参考价值。
飞桨(PaddlePaddle)是国内唯一功能完备的端到端开源深度学习平台,集深度学习训练和预测框架、模型库、工具组件、服务平台为一体,其兼具灵活和效率的开发机制、工业级应用效果的模型、超大规模并行深度学习能力、推理引擎一体化设计以及系统化的服务支持,致力于让深度学习技术的创新与应用更简单。
从Paddle Fluid v1.0以来,飞桨致力于打造更好的用户体验,趁着百度开发者大会,也为用户精心准备了一份大礼,在开发、训练及部署全流程上进行了全新升级,发布了飞桨的五大优势,接下来将一一解读。
一、动态图&静态图 - 兼具动态图和静态图两种计算图的优势
从飞桨核心框架Padlde Fluid v1.5开始,飞桨同时为用户提供动态图和静态图两种机制。
静态图是先定义网络结构而后运行,对定义好的图结构进行分析,可以使运行速度更快,显存占用更低,在业务部署上线上的具有非常大的优势,为用户的AI应用落地提供高效支持。但是静态图组网和执行阶段是分开,对于新用户理解起来不太友好。
飞桨从最新版本开始,提供了更方便的动态图模式,所有操作可以立即获得执行结果,而不必等到执行阶段才能获取到结果,这样可以更方便进行模型的调试,同时还减少了大量用于构建Executor等代码,使得编写、调试网络的过程变得更加便捷。
用户可以使用更加便捷的动态图模式进行调试、训练,然后可以把训练好的模型转换为静态图的结构,快速上线部署。
二、应用效果最佳的官方模型 – 覆盖三大主流任务
基于百度多年的产业应用经验,以及百度生态伙伴的人工智能解决方案实践,飞桨为用户提供70+精选经过真实业务场景验证的、应用效果最佳的官方算法模型,涵盖视觉、NLP、语音和推荐等AI核心技术领域。
飞桨自然语言处理模型库PaddleNLP:基于飞桨打造的工业级中文NLP开源工具集,拥有当前业内效果最好的中语义表示模型和基于百亿级大数据训练的预训练模型,并将自然语言处理领域的多种模型用一套共享骨架代码实现,可大大减少用户在开发过程中的重复工作。
用户在极大地减少研究和开发成本的同时,也可以获得更好的基于工业实践的应用效果。本次发布PaddleNLP-Research,支持NLP前沿研究,现已开源MRQA2019阅读理解竞赛Paddle Fluid基线、 DuConv (ACL2019)、ARNOR(ACL2019)、MMPMS(IJCAI2019)、MPM(NAACL2019) 等近期百度在 NLP 学术领域的工作。
飞桨视觉模型库PaddleCV:基于飞桨打造的业界效果最好的CV开源工具集,并开源多个百度自研、国际赛事夺冠方案模型。物体检测统一框架、图像分类库、图像生成库、视频识别库多个基础任务库中,既具备高精度模型、也具备高速推理模型。基于易扩展、易模块化的操作,用户可以高效完成各类视觉任务的工业应用。
PaddleDetection物体检测统一框架,覆盖主流的检测算法,即具备高精度模型、也具备高速推理模型,包含Faster-RCNN (支持FPN), Mask-RCNN (支持FPN), Cascade-RCNN, RetinaNet, Yolo v3, SSD算法并提供一系列的预训练模型,具有工业化、模块化、高性能的优势。结合飞桨核心框架的高速推理引擎,训练到部署无缝衔接;提供模块化设计,模型网络结构和数据数据处理均可定制;基于高效的核心框架,训练速度和显存占用上有一定的优势,例如,YOLO v3训练速度相比同类框架快1.6倍。此外,本次除了统一检测框架,还发布一系列预训练模型,例如基于改进版的ResNet的检测模型,不增加计算量的情况下,精度普遍提高约1%左右。
图像分类库本次新增9个图像分类模型,截至目前,覆盖10种、超过25个ImageNet预训练模型,其中ResNet模型持续改进,发布计算量相当的改进模型,例如ResNet50 Top1准确率从76.5%提升到79.84%(+3.34%)。
PaddleGAN为用户提供易上手的、一键式可运行的GAN模型,覆盖主流GAN算法,包括CGAN、DCGAN、Pix2Pix,CycleGAN,StarGAN,STGAN,ATTGAN,其中STGAN是百度自研的人脸属性编辑编辑模型,发表于CVPR 2019。
PaddleVideo业界首个视频识别与定位工具集继4月份发布, 本次持续优化训练速度,部分模型速度优于同类产品的30%;本次新增加C-TCN,百度自研的视频动作定位模型,也是2018年ActivityNet夺冠方案,在飞桨上首次开源。
基于预训练模型,用户可以更便捷地完成自己的AI应用,飞桨为用户提供预训练模型管理和迁移学习组件PaddleHub,可一键加载工业级预训练模型。本次新增发布29个预训练模型,共为用户提供40+预训练模型,覆盖文本、图像、视频三大领域八类模型。
PaddleHub提供Fine-tune API,10行代码即可完成大规模预训练模型的迁移学习。PaddleHub还引入「模型即软件」的理念,通过Python API或者命令行工具,一行代码完成预训练模型的预测。
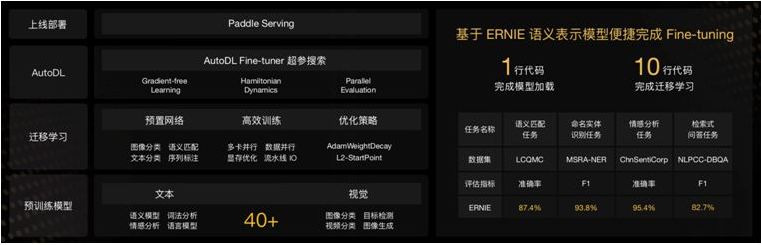 、大规模分布式训练 - 业界最强的超大规模并行深度学习能力
、大规模分布式训练 - 业界最强的超大规模并行深度学习能力
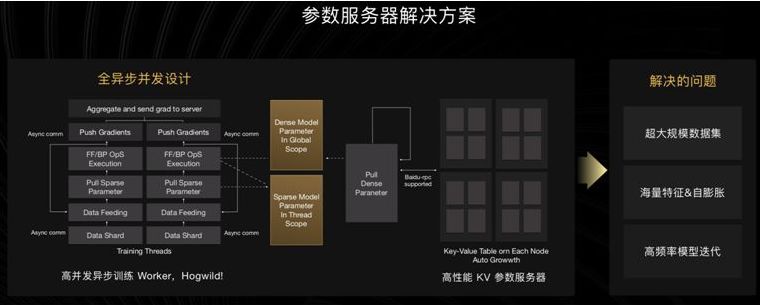
飞桨同时支持稠密参数和稀疏参数场景的超大规模深度学习并行训练,支持千亿规模参数、数百个节点的高效并行训练,也是最早提供如此强大的深度学习并行技术的深度学习平台。
飞桨提供高性价比的多机CPU参数服务器解决方案,基于真实的推荐场景的数据验证,可有效地解决超大规模推荐系统、超大规模数据、自膨胀的海量特征及高频率模型迭代的问题,实现高吞吐量和高加速比。
基于Paddle Fluid v1.5,分布式训练新发布High-level API Fleet,单机转分布式训练成本显著降低;GPU多机多卡性能显著提升,在ResNet50、BERT、ERNIE等模型中4x8 v100配置下相比此前发布的Benchmark提速超过50%。
四、端到端部署 - 推理引擎一体化设计,训练到多端推理的无缝对接移动端加速
基于Paddle Fluid v1.5,飞桨完整支持多框架、多平台、多操作系统,为用户提供高兼容性、高性能的多端部署能力、全面领先的底层加速库和推理引擎Paddle Mobile 和Paddle Serving。
对于开发者来说,除了模型的训练,在产品化过程中还会遇到各种各样的工程化问题。随着移动设备被广泛使用,在移动互联网产品应用深度学习和神经网络技术已经成为必然趋势。例如在移动端部署,就需要面临很多的问题,例如安装包大小、运行内存占用大小、推理速度和效果等。当前主流的模型很难直接部署到移动设备中。
在4月份的发布中,PaddleSlim 实现了目前主流的网络量化、剪枝、蒸馏三种压缩策略,并可快速配置多种压缩策略组合使用。针对体积已经很小的 MobileNet 模型,在模型效果不损失的前提下实现 70% 以上的体积压缩。
本次版本PaddleSlim更是进一步升级,新增基于模拟退火的自动剪枝策略和轻量级模型结构自动搜索功能Light-NAS,对比MobileNet v2在ImageNet 1000类分类任务上精度无损情况下FLOPS 减少17%,并在百度的OCR识别、人体检测、人脸关键点检测等业务线应用,精度无损甚至提高的情况下,速度带来了30%~40%的提升。

五、服务支持 – 唯一提供系统化深度学习技术服务的平台
飞桨已经实现了API的稳定和向后兼容,为用户提供从入门教程到安装编译文档、使用手册、模型文档、API接口及索引文档在内的完善的中英双语使用文档。同时,提供系统的服务体系为企业合作伙伴护航,帮助高校和教育伙伴构建完善体系,为开发者提供不同层次的培养体系。

我们尊重原创者版权,除我们确实无法确认作者外,我们都会注明作者和来源。在此向原创者表示感谢。若涉及版权问题,烦请原作者联系小编(邮箱:1966423770@qq.com)删除,谢谢!
以上是关于飞桨PaddlePaddle最新升级:更低门槛使用深度学习的主要内容,如果未能解决你的问题,请参考以下文章
视频分类最新高效算法,PaddlePaddle-NeXtVLAD初体验
飞桨EasyDL助力哲元科技零门槛用起AI,撬动食品行业质检智变升级