视频分类最新高效算法,PaddlePaddle-NeXtVLAD初体验
Posted Charlotte数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频分类最新高效算法,PaddlePaddle-NeXtVLAD初体验相关的知识,希望对你有一定的参考价值。
关注&置顶“Charlotte数据挖掘”
每日9:00,干货速递!
导读:本文转载自「飞桨PaddlePaddle」官方公众号,视频分类问题很热门,使用深度学习的方法大规模进行视频分类逐渐成为了趋势。除了TSM之外,目前深度学习领域还有一系列优秀的视频分类模型,我们会慢慢为大家介绍。今天,我们将为大家介绍由飞桨官方复现并开源的另一个重要模型:NeXtVLAD。
1. 视频分类概述
视频分类是指给定一个视频片段,对其中包含的内容进行分类。视频分类任务中,又以视频动作分类最为热门(如做蛋糕,打篮球,亲吻,喝酒,哭泣)等(详见下节数据集介绍),毕竟动作本身就包含“动”态的因素,不是“静“态的图像所能描述的,因此也是最体现视频分类功底的。
2. 常见数据集
近年来,视频理解相关的领域涌现了大量的新模型、新方法,与之相伴的,也有多个新的大规模的视频理解数据集。不同的数据集的概要情况如下:
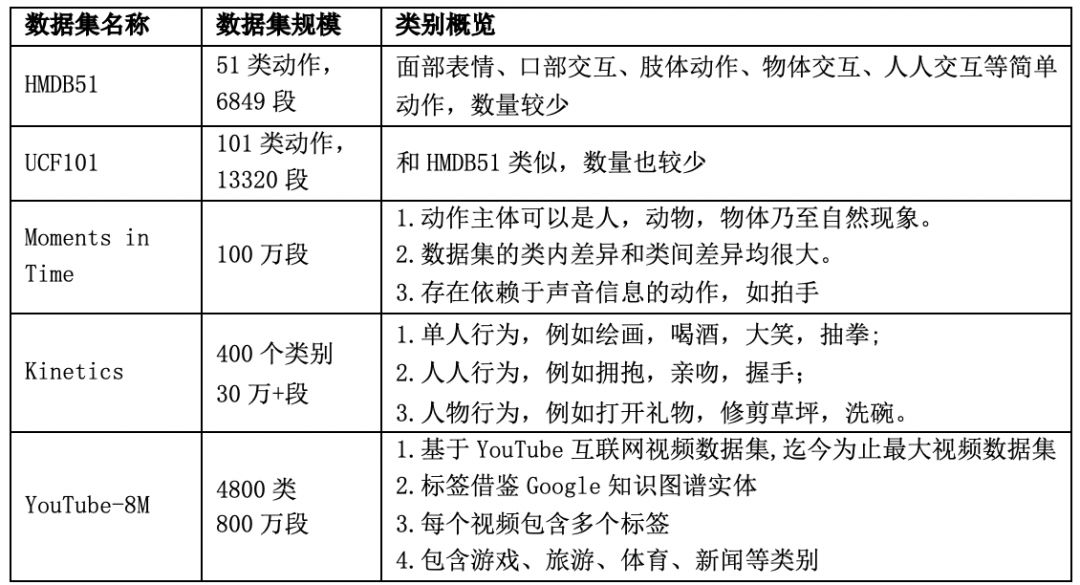
其中,Youtube-8M为谷歌开源的视频数据集,视频来自youtube,共计8百万个视频,总时长50万小时,V1版有4800个视觉实体标签,V2版有3862个视觉实体标签,是视频理解领域规模最大的数据集。为了保证标签视频数据库的稳定性和质量,谷歌只采用浏览量超过1000的公共视频资源。谷歌对视频进行了预处理,并提取了帧级别的特征,提取的特征被压缩到可以放到一个硬盘中(大小约为1.5T)。
Kinetics 数据集包括Kinetics-400和Kinetics-600以及今年刚发布的Kinetics-700。Kinetics是一个大规模、高质量的 Youtube视频网址数据集,其中包含各种以人为主题的行为动作。每个视频剪辑持续大约10秒中,并标有一个人类动作,所有剪辑都经过多轮人工,每个剪辑均来自一个独特的 YouTube视频。这些动作涵盖了广泛的课程,包括人物体交互,如演奏乐器,以及人与人之间的互动,如握手和拥抱。
Kinetics-400发布于2017年,该数据集由306,245个视频剪辑组成,涵盖400个人类动作。Kinetics-600发布于2018年,该数据集由495,547个视频剪辑组成, 涵盖600个人类动作类。Kinetics-700发布于2019年,该数据集由650,317个视频剪辑组成,涵盖700个人类动作。
3. NeXtVLAD简介
在深度学习之前,研究者们已经提出了许多传统的局部特征融合的算法,例如BoW,FV,VLAD等,旨在建模更紧凑的视觉特征表示,从而提升大规模视觉识别任务的性能。2016年的CVPR会议上研究者们又提出了一个可微分的网络模块NetVLAD,将传统的VLAD描述子与神经网络相结合,成功应用于场景识别的任务中。但是NetVLAD的缺陷是编码得到的特征维度过高,导致神经网络中含有上亿的参数,计算量巨大难以优化,容易产生过拟合。
为了解决NetVLAD中参数爆炸的问题,同时受ResNeXt的工作所启发,NeXtVLAD应运而生。NeXtVLAD首先对输入的特征做升维操作,然后将该特征划分成多个群组分别进行建模,并引入Group Convolution层减少模型参数,提高计算性能。此外该模型中还引入视觉Attention机制对不同的群组赋予不同权重,建模视频中不同帧的分类贡献度。最后为了捕获特征之间的依赖关系,在分类层之前加入Context Gating模块来重塑特征和输出标签,同时引入SE(Squeeze-and-Excitation)操作进一步减小模型参数。通过图像和音频特征的两路融合,NeXtVLAD取得了0.87的GAP指标,是该赛事中效果最好的单模型结构。
NeXtVLAD模型提供了一种将帧级别的视频特征转化并压缩成特征向量,以适用于任意数目帧输入的视频分类方法。其基本出发点是在NetVLAD模型的基础上,将高维度的特征先进行分组,再引入attention机制聚合提取时间维度的信息,这样既可以获得较高的准确率,又可以节省参数量。模型的主要结构如下:
图1. NeXtVLAD模型结构图
关于模型结构的更多细节,请参阅论文:NeXtVLAD: AnEfficient Neural Network to Aggregate Frame-level Features for Large-scaleVideo Classification,https://arxiv.org/abs/1811.05014
4. 飞桨NeXtVLAD快速上手
飞桨官方实现了论文中的NeXtVLAD单模型结构,并将其开源,赶快来试试吧。
数据准备
下载2nd-Youtube-8M数据集。
模型训练
(1)随机初始化开始训练
在PaddleVideo目录下运行如下脚本:
bash ./scripts/train/train_nextvlad.sh(2)使用预训练模型做finetune
https://paddlemodels.bj.bcebos.com/video_classification/nextvlad_youtube8m.tar.gz并在上述脚本文件中添加“--resume”为所保存的预模型存放路径。使用4卡Nvidia Tesla P40,总的batch size数是160。
(3)训练策略
使用Adam优化器,初始learning_rate=0.0002,每2,000,000个样本做一次学习率衰减,learning_rate_decay =0.8,正则化使用l2_weight_decay = 1e-5
模型评估
用户可以下载预训练的模型参数,或者使用自己训练好的模型参数。请在./scripts/test/test_nextvald.sh 文件中修改“--weights”参数为保存模型参数的目录,并运行如下命令:
bash ./scripts/test/test_nextvlad.sh由于YouTube-8M提供的数据中test数据集是没有ground truth标签的,所以这里使用validation数据集来做测试。
模型参数列表如下:
参数 |
取值 |
cluster_size |
128 |
hidden_size |
2048 |
groups |
8 |
expansion |
2 |
drop_rate |
0.5 |
gating_reduction |
8 |
计算指标列表如下:
精度指标 |
模型精度 |
Hit@1 |
0.8960 |
PERR |
0.8132 |
GAP |
0.8709 |
4. 模型推断
用户可以下载预训练的模型参数,也可以使用自己训练好的模型参数。请在./scripts/infer/infer_nextvald.sh 文件中修改“—weights”参数为保存模型参数的目录,运行如下脚本:
bash ./scripts/infer/infer_nextvald.sh
推断结果将会保存在NEXTVLAD_infer_result文件中,使用pickle格式存储。
快快自己动手尝试下吧!
如果您想详细了解更多飞桨PaddlePaddle的相关内容,请参阅以下文档。
https://www.paddlepaddle.org.cn
https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV/PaddleVideo
推荐阅读
(点击标题可跳转阅读)
以上是关于视频分类最新高效算法,PaddlePaddle-NeXtVLAD初体验的主要内容,如果未能解决你的问题,请参考以下文章
视频时间序列分类方法:动态时间规整算法DTW和R语言实现|附代码数据