(第9篇)大数据的的超级应用——数据挖掘-推荐系统
Posted 何石的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(第9篇)大数据的的超级应用——数据挖掘-推荐系统相关的知识,希望对你有一定的参考价值。
摘要: 当我们搜集好了庞大的数据,那我们要怎么利用他们来指导推荐系统呢?
博主福利 给大家赠送一套hadoop视频课程
授课老师是百度 hadoop 核心架构师
内容包括hadoop入门、hadoop生态架构以及大型hadoop商业实战案例。
讲的很细致, MapReduce 就讲了 15 个小时。
学完后可以胜任 hadoop 的开发工作,很多人学的这个课程找到的工作。
(包括指导书、练习代码、和用到的软件都打包了)
先到先得先学习。联系老师微信ganshiyu1026,备注OSchina。即可免费领取
部分视频截图展示

数据挖掘——推荐系统
大数据可以认为是许多数据的聚合,数据挖掘是把这些数据的价值发掘出来,比如有过去10年的气象数据,通过数据挖掘,几乎可以预测明天的天气是怎么样的,有较大概率是正确的。
机器学习是人工智能的核心,对大数据进行发掘,靠人工肯定是做不来的,那就得靠机器代替人工得到一个有效模型,通过该模型将大数据中的价值体现出来。
本章内容:
1) 数据挖掘和机器学习概念
2) 一个机器学习应用方向——推荐系统
3) 推荐算法——基于内容的推荐方法
4) 推荐算法——基于协同过滤的推荐方法
5) 基于MapReduce的协同过滤算法的实现
1. 数据挖掘和机器学习概念
机器学习和数据挖掘技术已经开始在多媒体、计算机图形学、计算机网络乃至操作系统、软件工程等计算机科学的众多领域中发挥作用,特别是在计算机视 觉和自然语言处理领域,机器学习和数据挖掘已经成为最流行、最热门的技术,以至于在这些领域的顶级会议上相当多的论文都与机器学习和数据挖掘技术有关。总的来看,引入机器学习和数据挖掘技术在计算机科学的众多分支领域中都是一个重要趋势。
对于数据挖掘,数据库提供数据管理技术,机器学习提供数据分析技术。通常我们要处理的大数据通过HDFS云存储平台来进行数据管理,目前Hadoop生态圈已经发展成熟,各种工具和接口基本满足大多数数据管理的需要。面对这样庞大的数据资源,需要有一种方法需要让其中的价值体现出来,机器学习提供了一系列的分析挖掘数据的方法。
Hadoop生态圈中有一个机器学习开源库的项目——Mahout,提供了丰富的可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序,Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。
2. 一个机器学习应用方向——推荐领域
推荐算法是最为大众所知的一种机器学习模型。推荐是很多网站背后的核心组件之一,有时也是一个重要的收入来源。
一般来讲,推荐系统试图对用户与某类物品之间的联系建模。比如我们利用推荐系统来告诉用户有哪些电影他们会可能喜欢。如果这一点做的很好的话,就能够吸引更多的用户持续使用我们的服务。这对双方都有好处。同样,如果能准确告诉用户有哪些电影与某一个电影相似,就能方便用户在站点上找到更多感兴趣的信息。这也能提升用户的体验、参与度以及站点内容对用户的吸引力。对于大型网站来说,很多内容是来自于独立的第三方——内容提供商,比如淘宝的商品宝贝基本来自各个店铺、奇艺上的电影很多来自与专业的传媒集团和工作室、微信上制作精良的广告也是来自于各个行业的广告主。
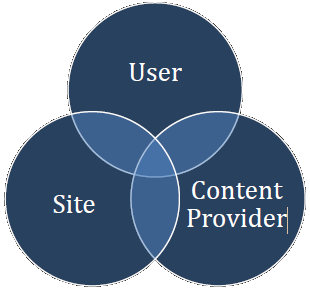
建立一个良好的推荐生态圈,对于用户、网站平台以及内容提供商,都是有好处的,首先用户得到他们想要的物品,平台获得更多的流量和收入,内容提供商售卖其物品的效率也会提高,所以是一个三者共赢的一个场景,所以一个好的推荐系统会带来很大的价值。
3. 推荐算法——基于内容的推荐方法
基于内容的推荐(Content Based)应该算最早被使用的推荐方法,它根据用户过去喜欢的产品(本文统称为item),为用户推荐和他过去喜欢的产品相似的产品。例如,一个推荐饭店的系统可以依据某个用户之前喜欢很多的烤肉店而为他推荐烤肉店。 CB最早主要是应用在信息检索系统当中,所以很多信息检索及信息过滤里的方法都能用于CB中。
CB的过程一般包括以下三步:
1) Item Representation:为每个item抽取出一些特征(也就是item的content了)来表示此item;
2) Profile Learning:利用一个用户过去喜欢(及不喜欢)的item的特征数据,来学习出此用户的喜好特征(profile);
3) Recommendation Generation:通过比较上一步得到的用户profile与候选item的特征,为此用户推荐一组相关性最大的item。

举个例子说明前面的三个步骤。对于个性化阅读来说,一个item就是一篇文章。根据上面的第一步,我们首先要从文章内容中抽取出代表它们的属性。常用的方法就是利用出现在一篇文章中词来代表这篇文章,而每个词对应的权重往往使用信息检索中的tf-idf来计算。比如对于本文来说,词“CB”、“推荐”和“喜好”的权重会比较大,而“烤肉”这个词的权重会比较低。利用这种方法,一篇抽象的文章就可以使用具体的一个向量来表示了。第二步就是根据用户过去喜欢什么文章来产生刻画此用户喜好的 profile了,最简单的方法可以把用户所有喜欢的文章对应的向量的平均值作为此用户的profile。比如某个用户经常关注与推荐系统有关的文章,那么他的profile中“CB”、“CF”和“推荐”对应的权重值就会较高。在获得了一个用户的profile后,CB就可以利用所有item与此用户profile的相关度对他进行推荐文章了。一个常用的相关度计算方法是cosine。最终把候选item里与此用户最相关(cosine值最大)的N个item作为推荐返回给此用户。
接下来我们详细介绍下上面的三个步骤。
1) Item Representation:
真实应用中的item往往都会有一些可以描述它的属性。这些属性通常可以分为两种:结构化的(structured)属性与非结构化的(unstructured)属性。所谓结构化的属性就是这个属性的意义比较明确,其取值限定在某个范围;而非结构化的属性往往其意义不太明确,取值也没什么限制,不好直接使用。比如在交友网站上,item就是人,一个item会有结构化属性如身高、学历、籍贯等,也会有非结构化属性(如item自己写的交友宣言,博客内容等等)。对于结构化数据,我们自然可以拿来就用;但对于非结构化数据(如文章),我们往往要先把它转化为结构化数据后才能在模型里加以使用。真实场景中碰到最多的非结构化数据可能就是文章了(如个性化阅读中)。下面我们就详细介绍下如何把非结构化的一篇文章结构化。
如何代表一篇文章在信息检索中已经被研究了很多年了,下面介绍的表示技术其来源也是信息检索,其名称为向量空间模型(Vector Space Model,简称VSM)。
记我们要表示的所有文章集合为 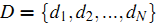 ,而所有文章中出现的词(对于中文文章,首先得对所有文章进行分词)的集合(也称为词典)为
,而所有文章中出现的词(对于中文文章,首先得对所有文章进行分词)的集合(也称为词典)为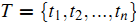 。也是说,我们有N篇要处理的文章,而这些文章里包含了n个不同的词。我们最终要使用一个向量来表示一篇文章,比如第j篇文章被表示为
。也是说,我们有N篇要处理的文章,而这些文章里包含了n个不同的词。我们最终要使用一个向量来表示一篇文章,比如第j篇文章被表示为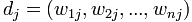 ,其中
,其中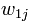 表示第1个词
表示第1个词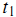 在文章j中的权重,值越大表示越重要;
在文章j中的权重,值越大表示越重要;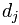 中其他向量的解释类似。所以,为了表示第j篇文章,现在关键的就是如何计算
中其他向量的解释类似。所以,为了表示第j篇文章,现在关键的就是如何计算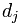 各分量的值了。例如,我们可以选取
各分量的值了。例如,我们可以选取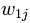 为1,如果词
为1,如果词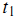 出现在第 j 篇文章中;选取为0,如果
出现在第 j 篇文章中;选取为0,如果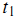 未出现在第j篇文章中。我们也可以选取
未出现在第j篇文章中。我们也可以选取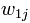 为词
为词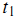 出现在第 j 篇文章中的次数(frequency)。但是用的最多的计算方法还是信息检索中常用的词频-逆文档频率(term frequency–inverse document frequency,简称tf-idf)。第j篇文章中与词典里第k个词对应的tf-idf为:
出现在第 j 篇文章中的次数(frequency)。但是用的最多的计算方法还是信息检索中常用的词频-逆文档频率(term frequency–inverse document frequency,简称tf-idf)。第j篇文章中与词典里第k个词对应的tf-idf为:
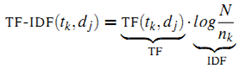
其中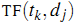 是第k个词在文章j中出现的次数,而
是第k个词在文章j中出现的次数,而 是所有文章中包括第k个词的文章数量。
是所有文章中包括第k个词的文章数量。
最终第k个词在文章j中的权重由下面的公式获得:
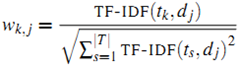
做归一化的好处是不同文章之间的表示向量被归一到一个量级上,便于下面步骤的操作。
2) Profile Learning
假设用户u已经对一些item给出了他的喜好判断,喜欢其中的一部分item,不喜欢其中的另一部分。那么,这一步要做的就是通过用户u过去的这些喜好判断,为他产生一个模型。有了这个模型,我们就可以根据此模型来判断用户u是否会喜欢一个新的item。所以,我们要解决的是一个典型的有监督分类问题,理论上机器学习里的分类算法都可以照搬进这里。
下面我们简单介绍下CB里常用的学习算法——KNN:
对于一个新的item,最近邻方法首先找用户u已经评判过并与此新item最相似的k个item,然后依据用户u对这k个item的喜好程度来判断其对此新item的喜好程度。这种做法和CF中的item-based kNN很相似,差别在于这里的item相似度是根据item的属性向量计算得到,而CF中是根据所有用户对item的评分计算得到。
对于这个方法,比较关键的可能就是如何通过item的属性向量计算item之间的两两相似度。[2]中建议对于结构化数据,相似度计算使用欧几里得距离;而如果使用向量空间模型(VSM)来表示item的话,则相似度计算可以使用cosine。
3) Recommendation Generation
通过上一步的学习,会得到一个推荐列表,我们直接把这个列表中与用户属性最相关的n个item作为推荐返回给用户即可。
4. 推荐算法——基于协同过滤的推荐方法
俗话说“物以类聚、人以群分”,继续拿看电影这个例子来说,如果你喜欢《蝙蝠侠》、《碟中谍》、《星际穿越》、《源代码》等电影,另外有个人也都喜欢这些电影,而且他还喜欢《钢铁侠》,则很有可能你也喜欢《钢铁侠》这部电影。
所以说,当一个用户 A 需要个性化推荐时,可以先找到和他兴趣相似的用户群体G,然后把 G 喜欢的、并且 A 没有听说过的物品推荐给 A,这就是基于用户的系统过滤算法。
根据上述基本原理,我们可以将基于用户的协同过滤推荐算法拆分为两个步骤:
1) 发现兴趣相似的用户
通常用 Jaccard 公式或者余弦相似度计算两个用户之间的相似度。设 N(u) 为用户 u 喜欢的物品集合,N(v) 为用户 v 喜欢的物品集合,那么 u 和 v 的相似度是多少呢:
Jaccard 公式:
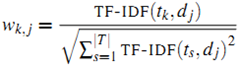
余弦相似度:
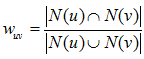
假设目前共有4个用户: A、B、C、D;共有5个物品:a、b、c、d、e。用户与物品的关系(用户喜欢物品)如下图所示:
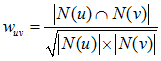
如何一下子计算所有用户之间的相似度呢?为计算方便,通常首先需要建立“物品—用户”的倒排表,如下图所示:

然后对于每个物品,喜欢他的用户,两两之间相同物品加1。例如喜欢物品 a 的用户有 A 和 B,那么在矩阵中他们两两加1。如下图所示:

计算用户两两之间的相似度,上面的矩阵仅仅代表的是公式的分子部分。以余弦相似度为例,对上图进行进一步计算:
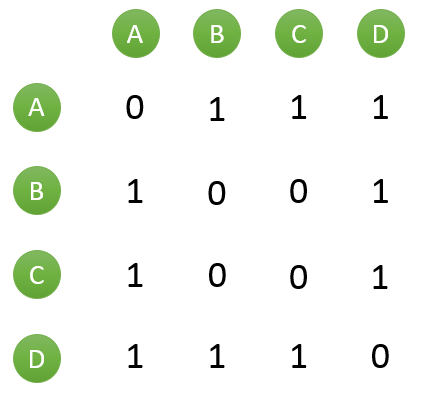
到此,计算用户相似度就大功告成,可以很直观的找到与目标用户兴趣较相似的用户。
2) 推荐物品
首先需要从矩阵中找出与目标用户 u 最相似的 K 个用户,用集合 S(u, K) 表示,将 S 中用户喜欢的物品全部提取出来,并去除 u 已经喜欢的物品。对于每个候选物品 i ,用户 u 对它感兴趣的程度用如下公式计算:

其中 rvi 表示用户 v 对 i 的喜欢程度,在本例中都是为 1,在一些需要用户给予评分的推荐系统中,则要代入用户评分。
举个例子,假设我们要给 A 推荐物品,选取 K = 3 个相似用户,相似用户则是:B、C、D,那么他们喜欢过并且 A 没有喜欢过的物品有:c、e,那么分别计算 p(A, c) 和 p(A, e):
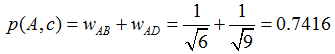
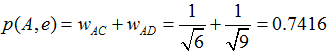
看样子用户 A 对 c 和 e 的喜欢程度可能是一样的,在真实的推荐系统中,只要按得分排序,取前几个物品就可以了。
以上是关于(第9篇)大数据的的超级应用——数据挖掘-推荐系统的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之_24_电影推荐系统项目_04_推荐系统算法详解