CentOS版hadoop完全分布初步搭建
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CentOS版hadoop完全分布初步搭建相关的知识,希望对你有一定的参考价值。
(之前学习时的记录)
整理一下在搭建hadoop完全分布模式时的相关步骤,及搭建过程中遇到的一些问题。
相关环境:
环境:基于win7的VM中CentOS64位系统
台数:3台;分别为master、slave1、slave2
hadoop版本:CDH3-U6
所用到的工具:Xshell(远程链接管理工具)、filezilla(可以远程移动文件)

第一部分:在VM中安装CentOS
1、下载
VM自己从网上下载,尽量不要装最新版本的;CentOS选择后缀为iso版本下载
2、安装
VM自己安装;
安装好VM后,开始安装CentOS;相关安装可以参考链接如下:
http://www.91linux.com/html/2014/CentOS_0415/9725.html
刚开始安装可以照着教程来装,参考教程上安装的是Desktop(桌面版)的,比较熟练的话尽量安装成Basic Serve版,相关步骤一样,只是后者没有操作界面,完全是代码行。
3、每个CentOS信息
对于初步搭建hadoop完全分布来说,安装三台Linux系统已足以。对于此,我分别安装了命名为master、slave1、slave2三台虚拟机,为Basic Serve版,相关配置后续再说。
第二部分、在CentOS中搭建hadoop集群
1、修改主机名和用户名(root用户执行,所有节点都需执行)
1)对上一步已搭建完的三个虚拟机,分别增加hadoop用户(root用户执行,所有节点都执行):

[[email protected] ~]#useradd hadoop
#添加以hadoop为用户名的用户
[[email protected] ~]#passwd hadoop
#修改该用户密码,密码统一设置为hadoop
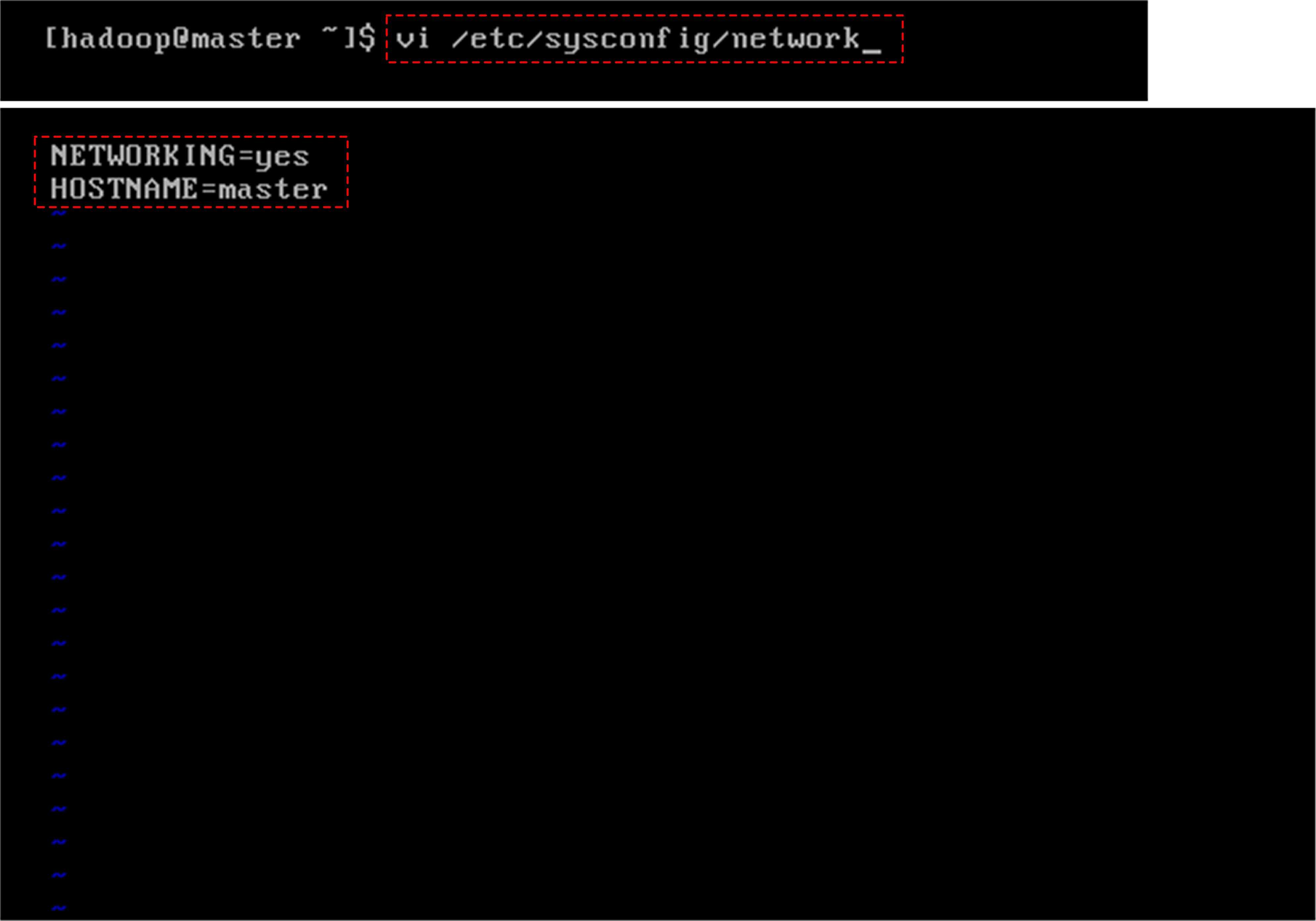
[[email protected] ~]#vi /etc/sysconfig/network
NETWORK=yes
HOSTNAME=localhost.localhost
按键盘的I键进行编辑,对于完全分布式来说,分别修改其“localhost.localhost”为“master”“slave1”“slave2”,修改完之后按Esc+Shift:+wq进行保存退出。
3)节点之间互访配置(这一步可以在配置完IP地址后在执行,所有节点均执行)
[[email protected] ~]#vi /etc/hosts
192.168.1.10 master
#masterIP地址与主机名
192.168.1.11 slave1
# slave1IP地址与主机名
192.168.1.12 slave2
# slave2IP地址与主机名
1)相关注意:在安装上CentOS后,会存在一个如何与宿主机进行正常通信的问题,在这一步中,首先在VM的网络虚拟配置中找到网络链接方式,选择为“桥接”模式,并选择具体网卡,
接着在系统设置中,设置虚拟机的连接方式为“桥接”;打开宿主机(Win7)中的cmd,输入ipconfig查看宿主机网段并记下,我的这台网段是10.129.49.xxx,所以在虚拟机桥接模式下,
所有虚拟机IP都应设为10.129.49.xxx(所有节点后边的数都不能相同)。
2)修改ifcfg-eth0文件(eth0代表网卡,可能有的虚拟机的网卡会不同,具体为哪个视虚拟机而定,root用户执行,所有节点都需执行)
在root用户下,输入
[[email protected] ~]#cd /etc/sysconfig/network-scripts
#进入network-scripts目录
[[email protected] ~]#ll
#查看目录下所有文件,看你的网卡是否是eth0,如果不是,视具体虚拟机而定
[[email protected] ~]#vi /etc/sysconfig/network-scripts/ifcfg-eth0
#进ifcfg-eth0文件,并进行编辑修改:(红色为修改部分)
DEVICE=eth0
BOOTPROTO=static
NM_CONTROLLED=yes
ONBOOT=yes
IPADDR=192.168.1.10
#静态IP地址
NETMASK=255.255.255.0
#掩码地址
GATWAY=192.168.1.1
#网关地址
3)修改UUID
[[email protected] ~]#vi /etc/sysconfig/network-scripts/ifcfg-eth0
#删除MAC地址行
[[email protected] ~]#rm -rf /etc/udev/rules.d/70-persistent-net.rules
#删除网卡和MAC地址绑定文件
4)重启并查看IP
[[email protected] ~]#reboot
[[email protected] ~]#ifconfig
打开宿主机的cmd,输入ping 192.168.1.10查看是否能进行通信,如果能则表示配置成功;分别配置slave1、slave2。
3、使用Xshell进行远程登录
使用Xshell登录是因为CentOS自带界面不可更改,也无法调整字体大小
对配置好IP的虚拟机用Xshell进行远程登录(即IP地址、用户名、用户密码),登陆后设置界面,调整字体大小。
4、配置SSH无密码链接
1)永久关闭防火墙(root用户)
[[email protected] ~]#chkconfig iptables off
2)启动SSH服务命令(root用户)
[[email protected] ~]#service ssh restart
#重启SSH
[[email protected] ~]#rpm -qa | grep openssh
#检查SSH是否安装成功
如果出现下面的信息:
openssh-askpass-5.3p1-81.e16.x86_64
openssh-5.3p1-81.e16.x86_64
openssh-clients-5.3p1-81.e16.x86_64
openssh-server-5.3p1-81.e16.x86_64
再执行命令:
[[email protected] ~]#rpm -qa | grep rsync
如果出现以下信息:
rsync-3.0.6-9.e16.x86_64
说明SSH安装成功。
3)生成SSH公匙(hadoop用户)
[[email protected] ~]$ssh-keygen -t rsa
#遇到提示回车即可,最后显示图形为公匙的指纹加密
[[email protected] ~]$ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[[email protected] ~]$ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
[[email protected] ~]$ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
#将公匙发至从节点的slave1、slave2用户
注意:对于完全分布来说,只在主节点配置SSH无密码链接即可,之后把公匙发至从节点
4)验证安装(hadoop用户)
[[email protected] ~]$ssh master
[[email protected] ~]$ssh slave1
[[email protected] ~]$ssh slave2
#如果没有出现输入密码提示则表示安装成功,执行这条命令后会远程登录从节点,返回主节点需执行exit
若按照上面步骤执行任然不成功,有可能是/home/hadoop/.ssh文件夹的权限问题。以hadoop用户执行
[[email protected] ~]$chmod 700 /home/hadoop/.ssh
[[email protected] ~]$chmod 700 /home/hadoop/.ssh/authorized_keys
CentOS预装的是Open JDK,但还是要推荐用Oracle JDK,下载地址为:
http://www.oracle.com/technetwork/Java/Javase/downloads/index.html
[[email protected] ~]#chown -R hadoop /opt
2)卸载Open JDK
[[email protected] ~]#java -version
#查看Java版本
[[email protected] ~]#rpm -qa | grep java
#查看Java详细信息
显示如下信息:
java-1.4.2-gcj-compat-1.4.2.0-40jpp.115
java-1.6.0-openjdk-1.6.0.0-1.7.b09.el5
卸载:
[[email protected]
~]#rpm -e –nodeps
java-1.4.2-gcj-compat-1.4.2.0-40jpp.115
[[email protected] ~]#rpm -e –nodeps java-1.6.0-openjdk-1.6.0.0-1.7.b09.el5
或者执行指令卸载:
[[email protected]
~]#yum -y remove java java-1.4.2-gcj-compat-1.4.2.0-40jpp.115
[[email protected]
~]#yum -y remove java java-1.6.0-openjdk-1.6.0.0-1.7.b09.el5
3)安装Oracle JDK(hadoop用户也可)
在第1)步给/opt文件夹加权限后,就可以使filezilla工具直接把在Windows中的JDK安装包直接拖至/opt文件夹下,然后进行解压:
[[email protected]
~]#tar -xzvf jdk-6u43-linux-x64.tar.gz
#解压JDK至/opt文件夹下
解压完后,删除JDK安装包
[[email protected]
~]#rm -rf jdk-6u43-linux-x64.tar.gz
#移除JDK安装包
4)配置环境变量
[[email protected] ~]#vi /etc/profile
#对profile文件进行编辑
对文件追加:
export JAVA_HOME=/opt/jdk1.6.0
export PATH=$PATH:$JAVA_HOME/bin
使环境变量立即生效,执行命令:
[[email protected] ~]#source /etc/profile
5)验证安装
[[email protected] ~]#java -version
出现如下信息,则安装成功:
#查看Java版本
Java version “1.6.0_31”
Java(TM) SE Runtime Environment (build 1.6.0_31-b04)
Java HotSpot(TM) 64-Bit Server VM (build 20.6-b01,mixed mode)

前面已经对/opt权限进行过修改,这一步就直接在/opt文件中安装配置即可;
利用filezilla工具把安装包发送至/opt文件夹下(只在hadoop主节点即master节点执行),执行解压缩。
1)解压文件
[[email protected] ~]$tar -zxvf hadoop-0.20.2-cdh3u6.tar.gz
#解压缩hadoop安装包
Hadoop的配置文件都在/opt/ hadoop-0.20.2-cdh3u6/conf下,对其中主要文件进行配置:
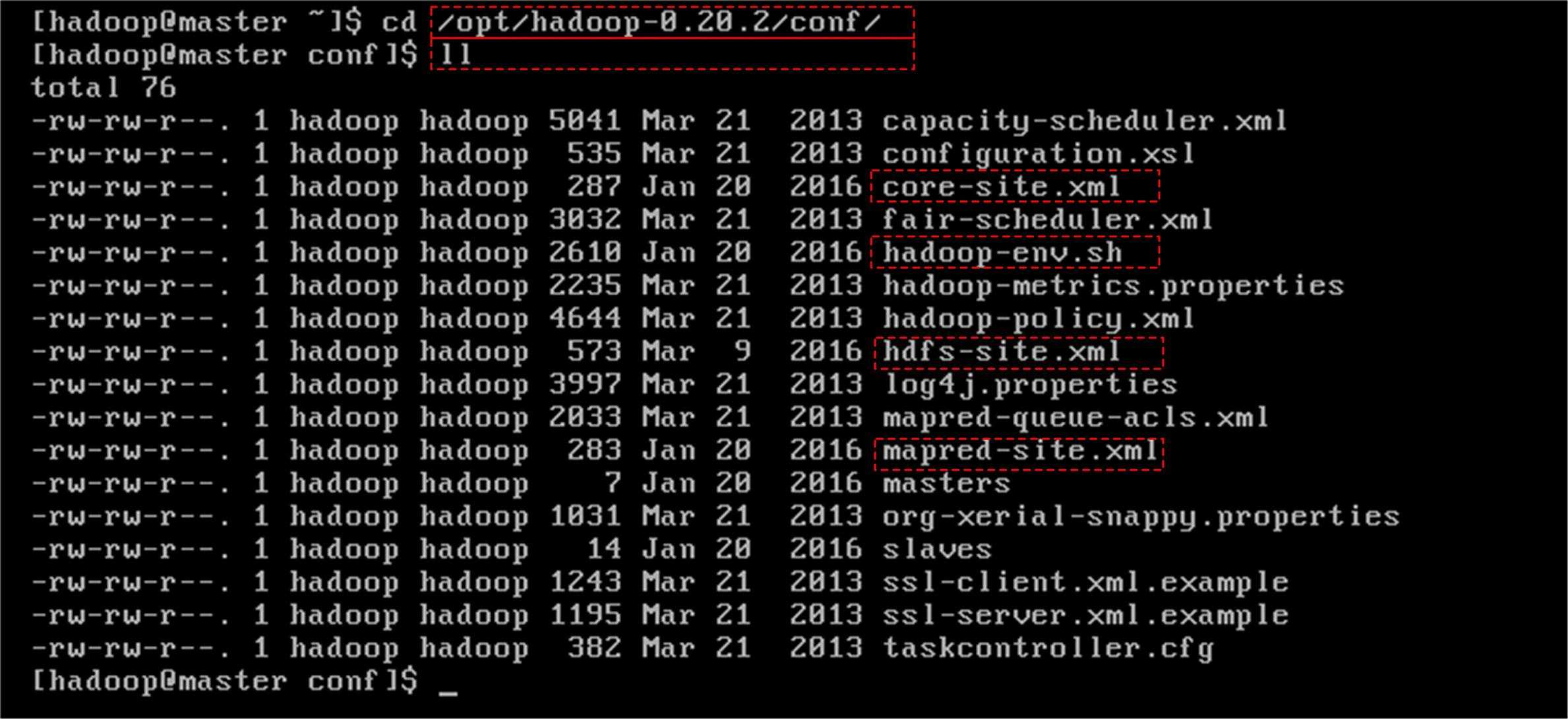
修改hadoop-env.sh
在文件hadoop-env.sh末尾追加环境变量
export JAVA_HOME=/opt/jdk1.6.0
export HADOOP_HOME=/opt/hadoop-0.20.2-cdh3u6
修改core-site.xml
修改core-site.xml为:
<configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> </configuration>
修改hdfs-site.xml
修改hdfs-site.xml为:
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration> <name>dfs.name.dir</name> <value>/opt/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/opt/hdfs/data</value> </property> </configuration>
修改mapred-site.xml
修改mapred-site.xml为:
<configuration> <property> <name>mapred.job.tracker</name> <value>master:9001</value> </property> </configuration>
master
slave1
slave2
[[email protected] ~]$scp -r /opt/hadoop-0.20.2-cdh3u6 [email protected]:/opt
[[email protected] ~]$scp -r /opt/hadoop-0.20.2-cdh3u6 [email protected]:/opt
至此,Hadoop安装配置工作全部完成,为了能在任何路径下使用Hadoop命令,还需要配置环境变量(root用户执行,所有节点都需要执行)。对文件/etc/profile追加如下信息:
export HADOOP_HOME=/home/hadoop/hadoop-0.20.2-cdh3u6
export PATH=$PATH:$HADOOP_HOME/bin
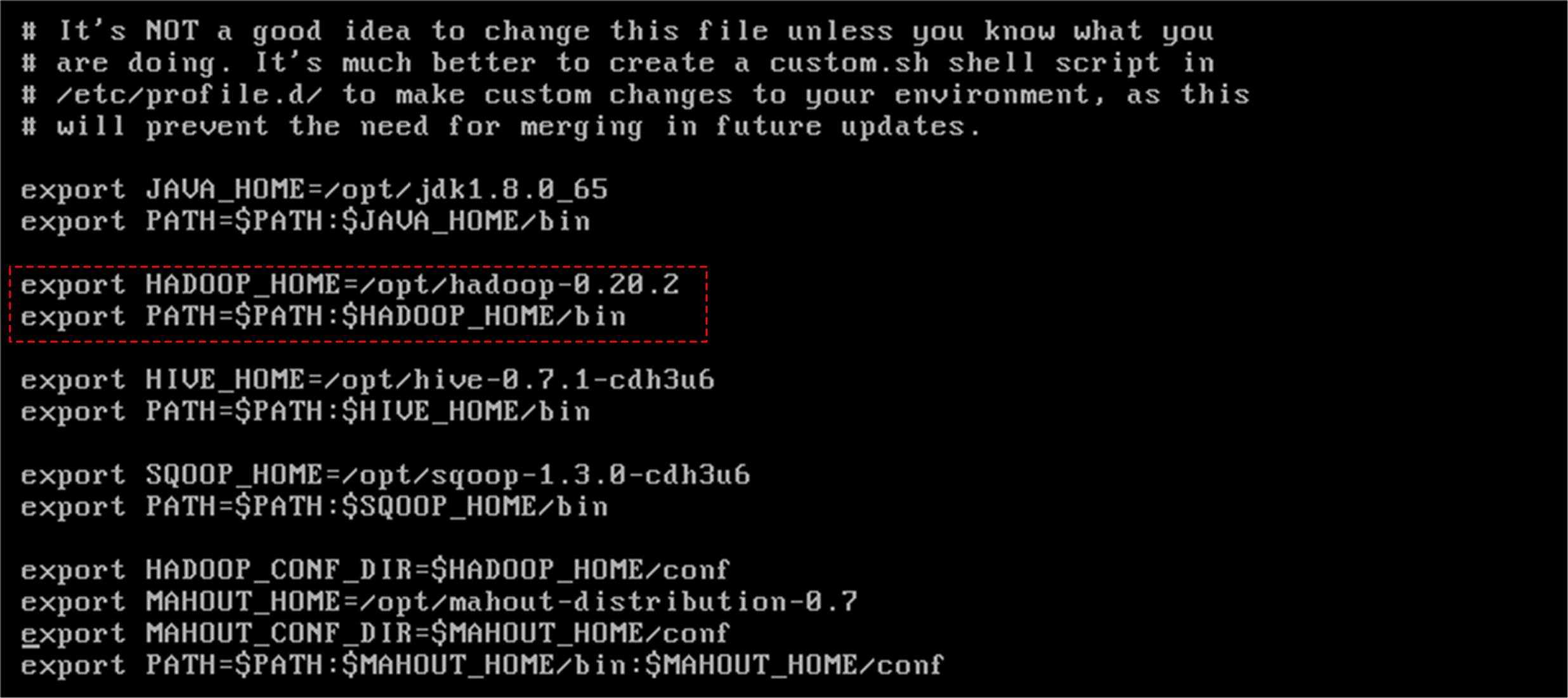
修改完后,执行命令行(root用户执行,所有节点都需要执行):
[[email protected] ~]#source /etc/profile
7、格式化HDFS
在第一次启动Hadoop之前,必须先将HDFS格式化。执行命令:
[[email protected] ~]$hadoop namenode -format
#如果别的路径执行不了,则进入/opt/hadoop-0.20.2-cdh3u6/bin文件下执行
按照提示输入Y,格式化成功后会出现格式化成功的信息:
16/1/20 10:50:51 INFO common.Storage: Storage directory /opt/hdfs/name has been successfully formatted.
8、启动Hadoop并验证安装
1)启动Hadoop
首先赋予脚本可执行权限(hadoop用户所有节点都需要执行),执行命令:
[[email protected] ~]$chmod +x -R /opt/hadoop-0.20.2-cdh3u6/bin
然后执行启动脚本(hadoop用户,主节点执行),执行命令:
[[email protected] ~]$./opt/ hadoop-0.20.2-cdh3u6/bin/start-all.sh

[[email protected] ~]$jps
主节点会出现:
NameNode
JobTracker
SecondaryNameNode
slave1节点出现:
DateNode
TaskTracker
slave2节点出现:
DateNode
TaskTracker
9、验证是否安装成功
在新安装的集群上运行一个MapReduce程序,判断集群是否安装成功,Hadoop例库中自带多中已经写好的可以运行的MR程序,此处,此处以最简单的单词计数程序WordCount进行集群平台验证:
1)在集群的任何一台电脑上创建一个文本文件命名为words,这里以master为例。对文本文件添加内容:如“data mining on data warehouse”,如果程序正常运行,最终结果为:
data 2
mining 1
on 1
warehouse 1
#HDFS中新建目录
[[email protected] ~]$hadoop dfs –mkdir /user/hadoop/input
#将本地文件上传
[[email protected] ~]$hadoop dfs –put /opt/words /user/hadoop/input
3)运行程序并查看结果
#运行单词统计程序
[[email protected] ~]$hadoop jar /opt/hadoop-0.20.2/hadoop-examples-0.20.2- cdh3u6.jar wordcount /user/hadoop/input /user/hadoop/output
#查看程序输出
[[email protected] ~]$hadoop dfs –cat /user/hadoop/output/part-r-00000
屏幕打印为:
data 2
mining 1
on 1
warehouse 1
表示集群可以正常运行,到此Hadoop安装结束。
以上是关于CentOS版hadoop完全分布初步搭建的主要内容,如果未能解决你的问题,请参考以下文章