Hadoop环境快速搭建(伪分布式和完全分布式步骤版)
Posted 我的思路很明确
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop环境快速搭建(伪分布式和完全分布式步骤版)相关的知识,希望对你有一定的参考价值。
目录
Ⅵ、hadoop集群启动和HDFS,YARN集群的UI信息状态查询
一、初始准备:
1.linux虚拟机一台,克隆两台后修改hostname和ip地址再按下列步骤操作(或者创建三个虚拟机,在初始安装界面设置好ip地址和hostname,笔者这里采用第一种)。
2.linux联网,采用NAT模式,可以ping通。(不会安装和连不上网的自寻搜索)
3. ——》资源下载地址
——》资源下载地址
二、环境搭建:
IP地址 主机名
192.168.1.111 bigdata111 #第一台主机
192.168.1.112 bigdata112 #第二台主机
192.168.1.113 bigdata113 #第三台主机
1.修改第二台和第三台主机的IP和主机名
创建好第一台bigdata111主机后,克隆出两个主机,然后都开启连接上网络并打开第二台主机的终端。
su root
hostname 查看主机名
vim /etc/hostname 修改主机名
ip addr/ifconfig 查看主机IP
cd /etc/sysconfig/network-scripts
vi ifcfg-ens33 修改网络配置文件:
将BOOTPROTO=dhcp改为static
ONBOOT=NO改为yes
IPADDR=192.168.1.112
NETMASK=255.255.255.0
GATEWAY=192.168.80.2 #到编辑里面打开虚拟网络编辑器然后找到NAT模式点击NAT设置就可以看到网关,这个需要和虚拟机的网关保持一致
DNS1=8.8.8.8
systemctl restart network
ip addr或者ifconfig 查看是否修改成功
同理在bigdata113主机上进行主机名和IP地址的修改
改IP地址后,Xshell连不上的原因是虚拟机的子网和改的IP不在同一频道上
2.用Xftp传入JDK和hadoop安装包,并安装
Ⅰ、先删除centos7上自带的openJDK:
方法一:
rpm -qa | grep java 查询java软件
sudo rpm -e 软件包 卸载不要的JDK
which java 查看JDK路径
rm -rf JDK路径 手动删除,最后把profile配置信息删除
方法二:
yum list installed | grep java 查看linux上自带的JDK
yum -y remove java-1.8.0-openjdk* 删除所有自带的JDK
yum -y remove tzdata-java.noarchⅡ、安装JDK并配置JAVA环境
mkdir -p /export/data
mkdir -p /export/servers
mkdir -p /export/software
Xftp把上面的两个安装包传入到/export/software文件夹中
tar -zxvf /export/software/jdk-8u181-linux-x64.tar.gz -C /export/servers/
cd /export/servers
mv jdk1.8.0_181 jdk
vi /etc/profile
#tip:在配置文件末尾追加
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
source /etc/profile
java -versionⅢ、安装Hadoop并配置环境
tar -zxvf /export/software/hadoop-2.7.2.tar.gz -C /export/servers/
vi /etc/profile (shift+G快速到文件末尾)
#tip:在文件末尾追加
export HADOOP_HOME=/export/servers/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
hadoop versioncd /export/servers/hadoop-2.7.2/etc/hadoop/
vi hadoop-env.sh
#tip:找到相应位置,添加这段话
export JAVA_HOME=/export/servers/jdk
vi core-site.xml
#tip:下图中乱码部分为注释代码,可以删掉,不影响
<configuration>
<!--用于设置Hadoop的文件系统,由URI指定-->
<property>
<name>fs.defaultFS</name>
<!--用于指定namenode地址在hadoop01机器上-->
<value>hdfs://bigdata111:9000</value>
</property>
<!--配置Hadoop的临时目录,默认/tem/hadoop-$user.name-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.2/tmp</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<!--指定HDFS的数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondary namenode 所在主机的IP和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata112:50090</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<!--指定MapReduce运行时的框架,这里指定在YARN上,默认在local-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<!--指定YARN集群的管理者(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata111</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
#tip:将文件中的localhost删除,添加主节点和子节点的主机名称
#tip:如主节点bigdata111,bigdata1112和bigdata113
vi slaves
bigdata111
bigdata112
bigdata113Ⅳ、host文件配置,免密登入
配置host文件,每个主机都要
vi /etc/hosts
192.168.1.111 bigdata111
192.168.1.112 bigdata112
192.168.1.113 bigdata113
scp /etc/hosts bigdata112:/etc/hosts
scp /etc/hosts bigdata113:/etc/hosts
在windows下打开C:\\Windows\\System32\\drivers\\etc\\host,在桌面创建一个host文件不带后缀,然后把原本windows下的host文件复制到桌面的hosts文件里在最后加上上面/etc/hosts写入的,最后覆盖时候会提示文件重复,管理员权限继续覆盖即可。
免密登入(这个过程每次主机都要完整执行一次,共三次)
ssh-keygen -t rsa
cd /root
ll -a
cd .ssh/
ssh-copy-id bigdata111
ssh-copy-id bigdata112
ssh-copy-id bigdata113
ssh bigdata112/ssh bigdata111 看看是否能互通Ⅴ、文件传输以及剩余两台机子的环境配置
在bigdata111上传输两个安装包给112和113
scp /export/software/jdk-8u181-linux-x64.tar.gz bigdata112:/export/software/
scp /export/software/jdk-8u181-linux-x64.tar.gz bigdata113:/export/software/
scp /export/software/hadoop-2.7.2.tar.gz bigdata112:/export/software/
scp /export/software/hadoop-2.7.2.tar.gz bigdata113:/export/software/
分别在112和113上安装两个包
tar -zxvf /export/software/jdk-8u181-linux-x64.tar.gz -C /export/servers/
tar -zxvf /export/software/hadoop-2.7.2.tar.gz -C /export/servers/
传输111的环境变量文件给112和113
scp /etc/profile bigdata112:/etc/profile
scp /etc/profile bigdata113:/etc/profile
scp -r /export/ bigdata112:/
scp -r /export/ bigdata113:/
#tip:返回bigdata112和bigdata113节点执行下面命令,使环境变量生效
source /etc/profile
然后在112和113上java -version和hadoop version查看是否安装成功Ⅵ、hadoop集群启动和HDFS,YARN集群的UI信息状态查询
hdfs namenode -format
start-dfs.sh
start-yarn.sh
jps(只能查java编写的进程)
systemctl stop firewalld.service #关闭防火墙
systemctl disable firewalld.service #关闭防火墙开机启动
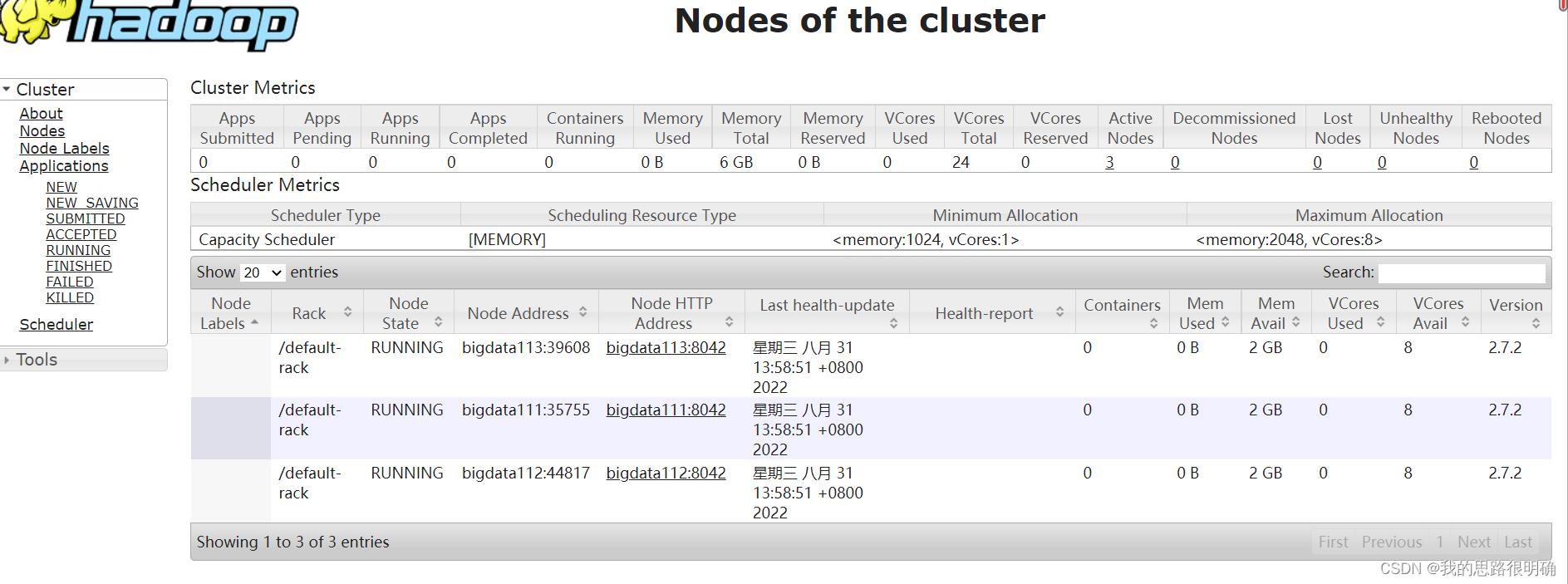
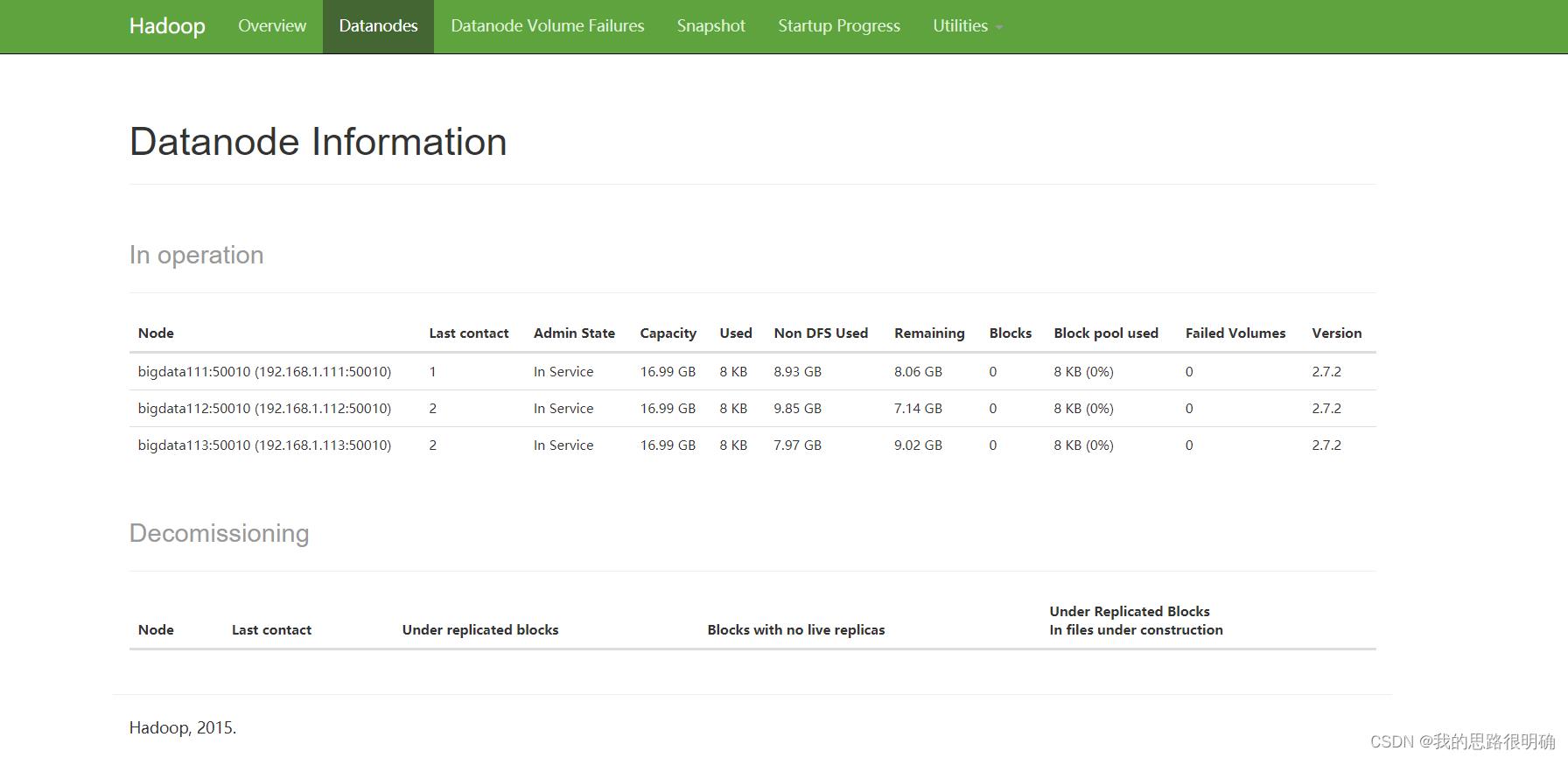
通过UI界面查看Hadoop运行状态,在Windows系统下,访问http://bigdata111:50070,查看HDFS集群状态,在Windows系统下,访问http://bigdata111:8088,查看Yarn集群状态
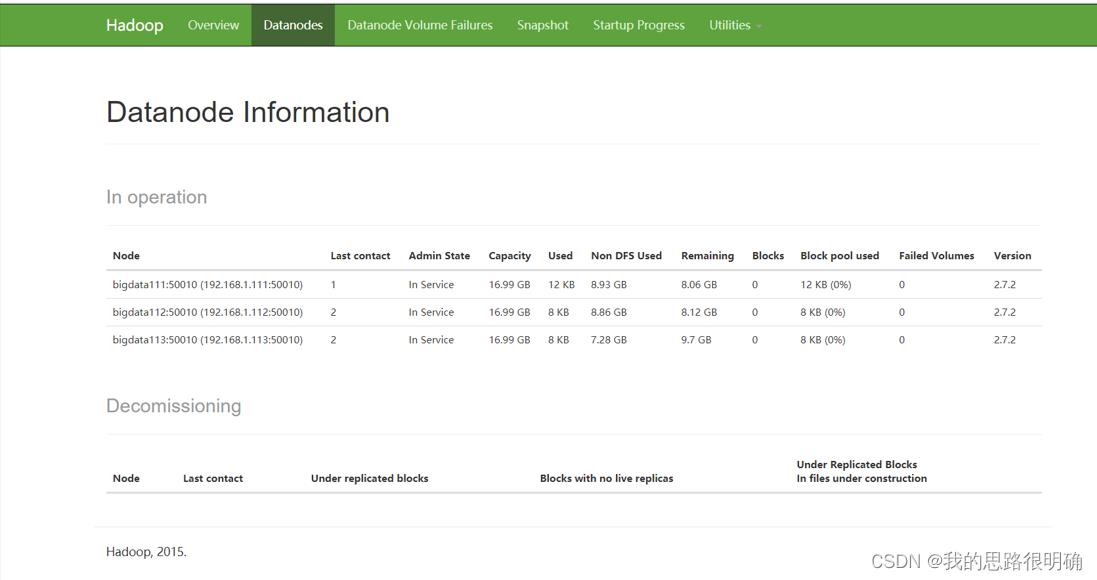
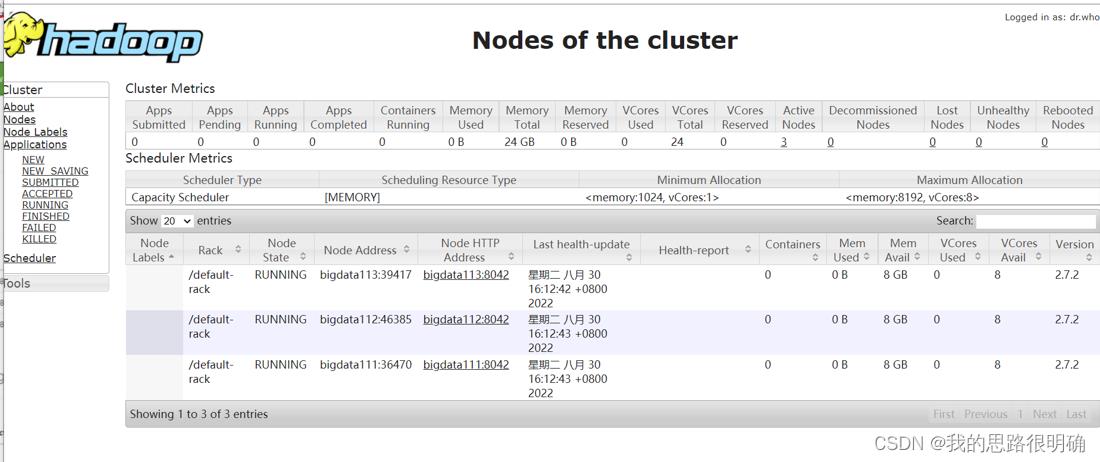
在JPS中找到DataNode的PID,然后kill -9 PID(DataNode),因为集群的心跳机制,10分钟后可以看到HDFS上面出现一个Dead Nodes 死亡节点,即可达到验证。至此就安装完了伪分布式的hadoop框架。
三、完全分布式Hadoop框架
节点分配如图所示:
| 服务 | bigdata111 | bigdata112 | bigdata113 |
|---|---|---|---|
| NameNode | √ | ||
| Secondary NameNode | √ | ||
| DataNode | √ | √ | √ |
| ResourceManager | √ | ||
| NodeManager | √ | √ | √ |
| JobHistoryServer | √ |
按上述伪分布式配置成功后,只需要对几个配置文件进行修改就行,然后在bigdata111上分配文件给bigdata112和113.
cd /export/servers/hadoop-2.7.2/etc/hadoop/
vi core-site.xml
#tip:下图中乱码部分为注释代码,可以删掉,不影响
<configuration>
<!--用于设置Hadoop的文件系统,由URI指定-->
<property>
<name>fs.defaultFS</name>
<!--用于指定namenode地址在bigdata111机器上-->
<value>hdfs://bigdata111:9000</value>
</property>
<!--配置Hadoop的临时目录,默认/tem/hadoop-$user.name-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.2/tmp</value>
</property>
</configuration>
vi hdfs-site.xml
<configuration>
<!--指定HDFS的数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondary namenode 所在主机的IP和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata112:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata111:50070</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
vi mapred-site.xml
<configuration>
<!--指定MapReduce运行时的框架,这里指定在YARN上,默认在local-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>bigdata113:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>bigdata113:19888</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<!--指定YARN集群的管理者(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata113</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
scp -r /export/ bigdata112:/
scp -r /export/ bigdata113:/出现的问题:hdfs namenode -format后start-all.sh,然后通过jps发现没有出现DataNode,这是因为前面的伪分布式安装的时候与现在的环境出现了矛盾,或者是namenode 需要在运行以后尽量避免格式化,否则datanode就找不到相应的cluster ID。
解决办法:cd /export/servers/hadoop-2.7.2/tmp/dfs/后,ls查看发现有data文件,然后rm -rf data删除该文件,再hdfs namenode -format和start-all.sh即可解决,注意三台机子的data文件都要删除一遍!
访问网页端:由于这里把ResourceManager分配给了bigdata113,所以访问的网页是:
bigdata111:50070和bigdta113:8088
以上是关于Hadoop环境快速搭建(伪分布式和完全分布式步骤版)的主要内容,如果未能解决你的问题,请参考以下文章