大数据实战之Centos搭建完全分布式Hadoop集群
Posted 进击的鱼豆腐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据实战之Centos搭建完全分布式Hadoop集群相关的知识,希望对你有一定的参考价值。
集群规划
| 名称 |
ip |
身份 |
| hadoop101 |
192.168.231.121 |
NameNode,DataNode,NodeManager |
| hadoop102 |
192.168.231.122 |
DataNode,ResourceManager |
| hadoop103 |
192.168.231.123 |
DataNode,NodeManager,Secondary NameNode |
环境:虚拟机Centos8
安装包:hadoop3.2.1
1. 先配置一台虚拟机然后克隆两台
1.1 修改主机名
vim /etc/hostname
1.2 修改网络ip
cd /etc/sysconfig/network-scripts
vim ifcfg-ens160

打开后如下图所示
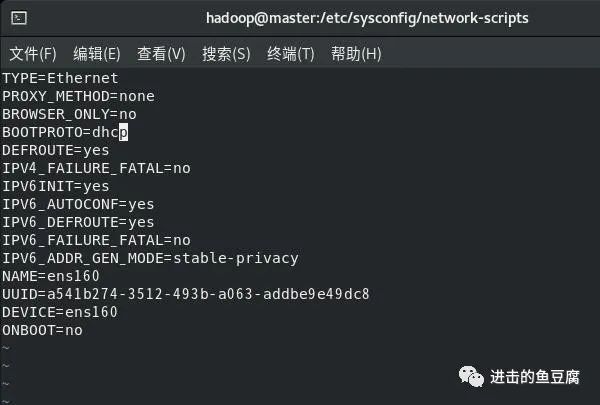
修改成如下
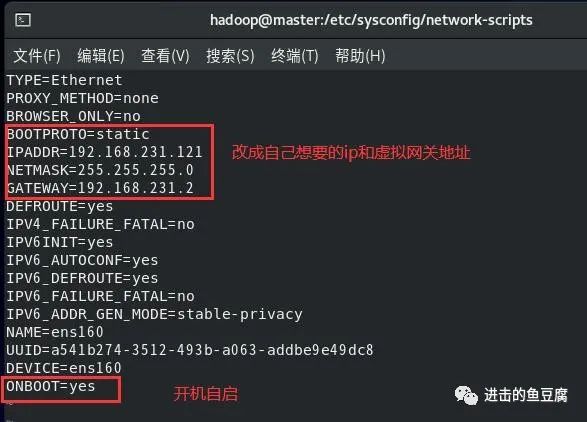
然后输入下面两条命令重启网络服务,ens160是网卡名,即上图中的NAME
nmcli c reload
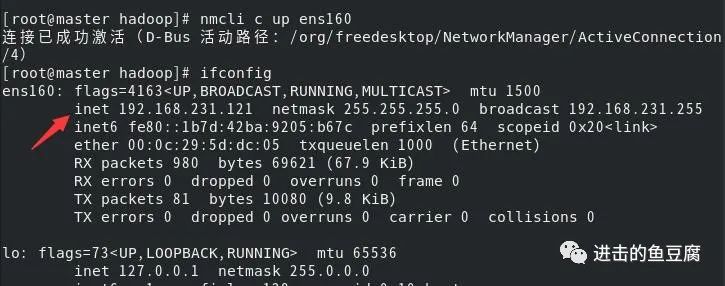
nmcli c up ens160
可以看到ip已经修改成功
上面的配置还无法识别域名,所以要加上dns解析(这里加的是虚拟网关)
vim /etc/resolv.conf
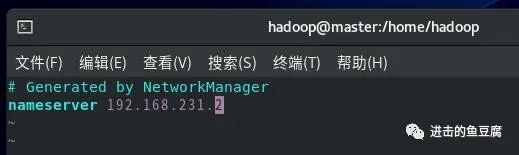
然后可以成功ping通啦

1.3 配置ip和主机名的映射
vim /etc/hosts
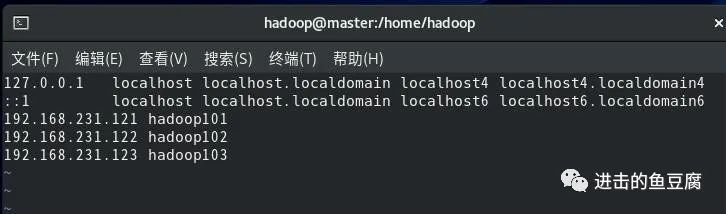
因为之后还有两台也要加映射,所以在这里先添加好
现在重启后修改的主机名就能生效,基本配置工作就完成了,这里先关闭虚拟机然后克隆两台。
对克隆机器依次执行操作:修改主机名->修改网络ip->重启网络服务->重启虚拟机
2. 安装jdk1.8
2.1 下载jdk1.8到windows
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
2.2 下载lsync,方便之后分发同步文件
在hadoop101上执行:yum install rsync (用root用户才能下载)
2.3 编写分发脚本xsync,有了这个后面可以少做很多工作
cd /usr/local/bin
在这个目录下创建脚本可以全局使用
vim xsync
填写如下内容,ip根据自己机器情况改动

给文件附加可执行权限
chmod 777 xsync

2.4 用SecureCRT或Xshell连接到三台虚拟机
2.5 没有hadoop用户的,创建hadoop用户及hadoop用户组
groupadd hadoop(添加组)
useradd -g hadoop hadoop(添加用户并指定组)
passwd hadoop(修改用户密码)
给hadoop用户赋予临时root权限:在root用户下执行visudo
找到root这一行,在其下方添加hadoop的信息

2.6 创建工作目录
用root用户在/opt目录下创建software目录,并将其所属用户和组改为hadoop
cd /opt
mkdir software
chown hadoop:hadoop software
然后分发一下这个目录
xsync /opt/software(此时分发是需要输入密码的,后面配置了ssh之后就不用了)
2.7 将jdk安装包上传到/opt/software目录下,并解压
切换到hadoop用户
tar -zxvf jdk-8u241-linux-x64.tar.gz

2.8 配置环境变量
在root用户下
vim /etc/profile 在文件末尾添加如下内容

保存退出后刷新一下
source /etc/profile
java -version 可以测试看看
2.9 分发文件
xsync /etc/profile
xsync /opt/software/jdk1.8.0_241
再到其它机器上执行一下source /etc/profile就行了
3. 解压hadoop安装包
3.1 配置ssh免密登录
hadoop群起需要ssh免密登录,而且分发文件时免密登录也更加方便,所以接下来就先在hadoop101上的hadoop用户下配置免密登录
先进入到hadoop家目录下
cd /home/hadoop
在进入隐藏文件夹.ssh中,如果没有就先创建
mkdir .ssh
并改权限
chmod 744 .ssh
cd .ssh
执行命令:ssh-keygen -t rsa,然后一直敲回车
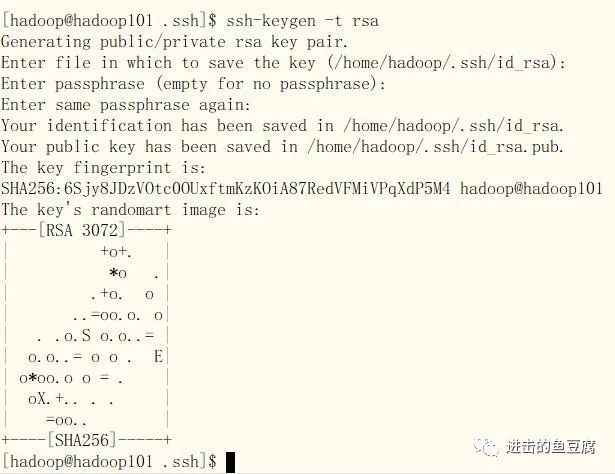
发送公匙,输入yes和对应的密码则添加成功
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh hadoop101测试一下,不需要密码登录成功则完成
(可以在root用户下也配置一下,方便root用户下分发文件)
因为后面resourcemanager在hadoop102上,所以在hadoop102的.ssh中也要配置免密登录。
3.2 下载hadoop3.2.1安装包,然后上传到hadoop101的/opt/software目录下
https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.2.1/
3.3 解压安装包
tar -zxvf hadoop-3.2.1.tar.gz

3.4 配置环境变量
切换为root用户
su root
vim /etc/profile

source /etc/profile
3.5 编写hadoop配置文件
在hadoop用户下
vim $HADOOP_HOME/etc/hadoop/core-site.xml
添加如下配置
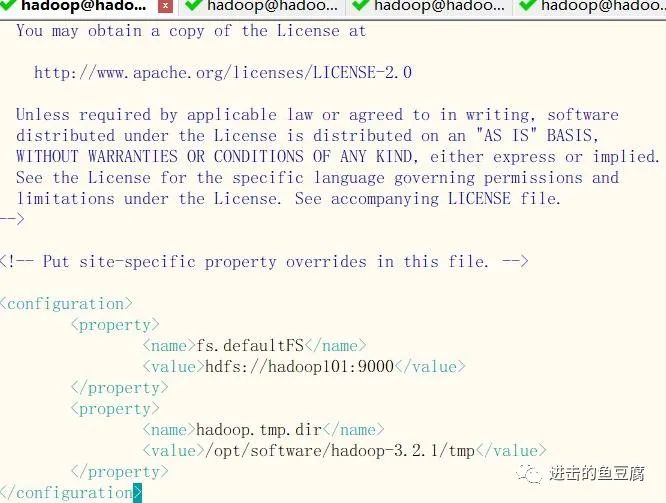
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
添加如下配置

vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
添加如下配置
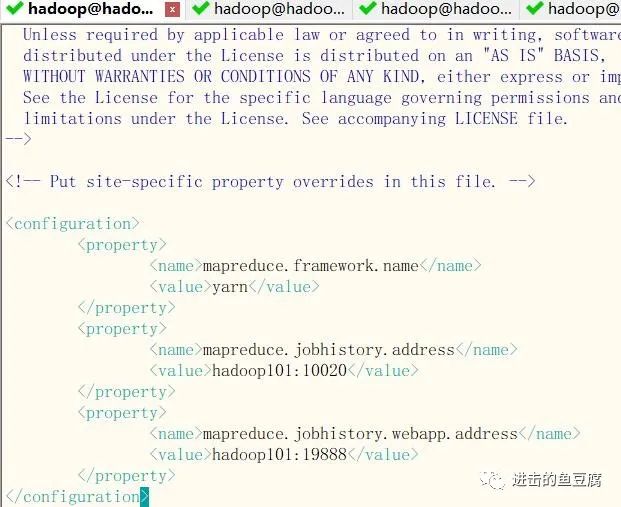
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
添加如下配置

vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
配置JAVA_HOME和HADOOP_HOME的路径

vim $HADOOP_HOME/etc/hadoop/yarn-env.sh
同样配置JAVA_HOME和HADOOP_HOME的路径
vim $HADOOP_HOME/etc/hadoop/workers
配置群起的workers (不能有多余的空格和空行)

3.6 分发hadoop3.2.1文件夹


3.7 格式化NameNode
cd $HADOOP_HOME 进入hadoop根目录
执行bin/hdfs namenode -format

3.8 启动dfs
hadoop101的hadoop根目录下执行sbin/start-dfs.sh
启动成功,并且在另外两台上自动创建了日志文件夹

3.8 启动yarn
hadoop102的hadoop根目录下执行sbin/start-yarn.sh
jps后出现以下进程则一切正常
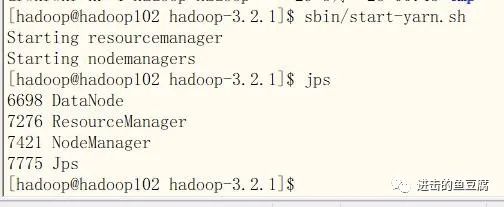


关闭集群命令:
sbin/stop-dfs.sh
sbin/stop-yarn.sh
3.9 编写群起脚本(能够在hadoop101上启动dfs和hadoop102上的yarn)
切换到root用户su root
cd /usr/local/bin
vim hdp
填写如下内容
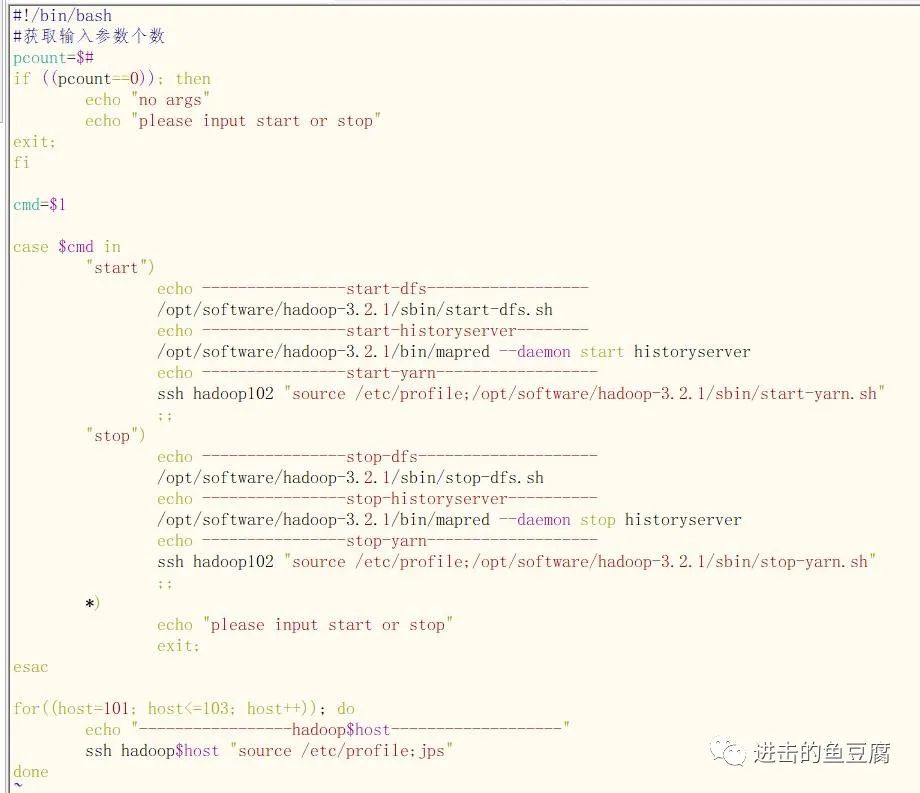
保存退出后给文件附加执行权限
chmod 777 hdp
然后切换到hadoop用户启动脚本,效果如下图所示,启动成功!
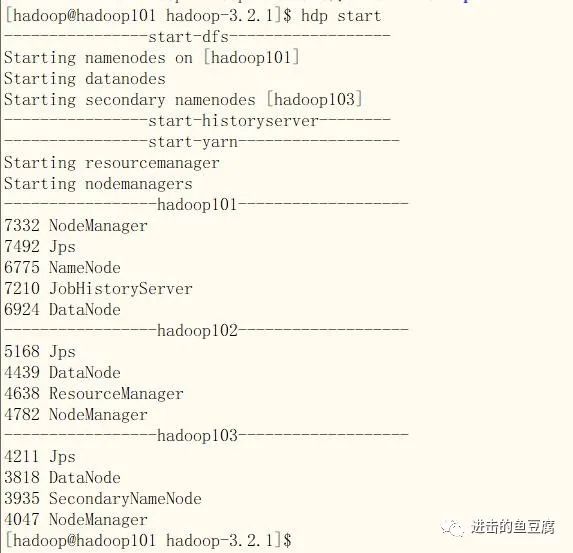
4. 关闭所有机器的防火墙(方便从windows访问集群)
用root用户或sudo执行
systemctl disable firewalld 禁用开机启动
systemctl stop firewalld 禁用防火墙

5. 集群时间同步
5.1 安装chrony
centos8自带chrony,如未安装可用以下命令安装
yum install chrony -y
5.2 开启服务
在root用户下或用sudo执行(三台机器都要执行)
systemctl enable chronyd.service (加入开机自启动)
systemctl start chronyd.service (开启服务)
systemctl status chronyd.service (查看状态)
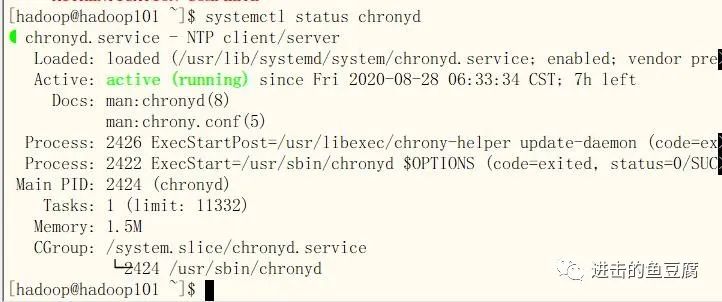
5.3 修改配置文件
vim /etc/chrony.conf
让hadoop101同步阿里云的时钟,集群其它机器同步hadoop101的时钟
hadoop101修改下列两项位置


hadoop102和hadoop103的配置文件修改如下
退出保存后重启服务
systemctl restart chronyd
分布式hadoop搭建到此就结束啦!下一章将介绍hadoop命令的基本使用。
以上是关于大数据实战之Centos搭建完全分布式Hadoop集群的主要内容,如果未能解决你的问题,请参考以下文章