坑挺多 | 联邦学习FATE:训练模型
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了坑挺多 | 联邦学习FATE:训练模型相关的知识,希望对你有一定的参考价值。
本篇参考:pipeline_tutorial_hetero_sbt上一篇为:坑挺多 | 联邦学习FATE:上传数据(一),我们继续来看看这个教程里面的大坑。
文章目录
1 神坑一:guest网络的设置问题
直接给结论好了:
!pipeline init --ip fate-9999.aliyun.xxxx.com --port 9380
!pipeline config check
pipeline = PipeLine() \\
.set_initiator(role='guest', party_id=9999) \\
.c(guest=9999, host=10000, arbiter=10000)
你需要确保,pipeline init初始化的网络 与 PipeLine.set_roles设置的guest网络,一致才能跑通。
不然可能报错:
ValueError: 9999 is not in list
或者:
UPLOADING:||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.00%
一直卡在uploading
或者
data = result["data"][0]
IndexError: list index out of range
这是我觉得整个篇幅比较坑的地方,可能官方觉得:这么一个细节,谁不知道
但是笔者作为新手,为此真的费劲测试了很久。
2 纵向案例一:分类模型-HeteroSecureBoost代码
官方所有案例数据可参考:examples/data
上传数据:
# 分别上传
!pipeline init --ip fate-10000.aliyun.xxxx.com --port 9380
!pipeline config check
# 分别上传
!pipeline init --ip fate-9999.aliyun.xxxx.com --port 9380
!pipeline config check
# 上传数据
from pipeline.backend.pipeline import PipeLine
pipeline_upload = PipeLine().set_initiator(role='guest', party_id=10000).set_roles(guest=10000)
partition = 4
namespace = 'experiment_0616'
dense_data_guest = "name": "breast_hetero_guest", "namespace": namespace
dense_data_host = "name": "breast_hetero_host", "namespace": namespace
tag_data = "name": "breast_hetero_host", "namespace": namespace
import os
data_base = "./"
pipeline_upload.add_upload_data(file=os.path.join(data_base, "data/breast_hetero_guest.csv"),
table_name=dense_data_guest["name"], # table name
namespace=dense_data_guest["namespace"], # namespace
head=1, partition=partition) # data info
pipeline_upload.add_upload_data(file=os.path.join(data_base, "data/breast_hetero_host.csv"),
table_name=dense_data_host["name"],
namespace=dense_data_host["namespace"],
head=1, partition=partition)
pipeline_upload.add_upload_data(file=os.path.join(data_base, "data/breast_hetero_host.csv"),
table_name=tag_data["name"],
namespace=tag_data["namespace"],
head=1, partition=partition)
print('地址:',os.path.join(data_base, "data/breast_hetero_guest.csv"))
pipeline_upload.upload(drop=1)
这里上传需要不同的数据分开上传,不过笔者偷懒,两个服务器所有host/guest数据都上传了,
训练过程中,笔者这边把guest换成了10000,而且数据已经上传了,
来看看:
!pipeline init --ip fate-10000.aliyun.xxxx.com --port 9380
!pipeline config check
# 确认pipeline的状态
from pipeline.backend.pipeline import PipeLine
from pipeline.component import Reader, DataTransform, Intersection, HeteroSecureBoost, Evaluation
from pipeline.interface import Data
guest_id = 10000
host_id = 9999
arbiter_id = 9999
pipeline = PipeLine() \\
.set_initiator(role='guest', party_id=guest_id) \\
.set_roles(guest=guest_id, host=host_id, arbiter=arbiter_id)
namespace = 'experiment_0616'
# Define a Reader to load data
reader_0 = Reader(name="reader_0")
# set guest parameter
reader_0.get_party_instance(role='guest', party_id=guest_id).component_param(
table="name": "breast_hetero_guest", "namespace": namespace)
# set host parameter
reader_0.get_party_instance(role='host', party_id=host_id).component_param(
table="name": "breast_hetero_host", "namespace": namespace)
# 解析数据到DataTransform
data_transform_0 = DataTransform(name="data_transform_0")
# set guest parameter
data_transform_0.get_party_instance(role='guest', party_id=guest_id).component_param(
with_label=True)
data_transform_0.get_party_instance(role='host', party_id=[host_id]).component_param(
with_label=False)
# 新增 Intersection 组件 to perform PSI for hetero-scenario
intersect_0 = Intersection(name="intersect_0")
# HeteroSecureBoost模型初始化
hetero_secureboost_0 = HeteroSecureBoost(name="hetero_secureboost_0",
num_trees=5,
bin_num=16,
task_type="classification",
objective_param="objective": "cross_entropy",
encrypt_param="method": "paillier",
tree_param="max_depth": 3)
# 新增评估组件
evaluation_0 = Evaluation(name="evaluation_0", eval_type="binary")
# 类似keras,分别定义 + 组合使用
pipeline.add_component(reader_0)
pipeline.add_component(data_transform_0, data=Data(data=reader_0.output.data))
pipeline.add_component(intersect_0, data=Data(data=data_transform_0.output.data))
pipeline.add_component(hetero_secureboost_0, data=Data(train_data=intersect_0.output.data))
pipeline.add_component(evaluation_0, data=Data(data=hetero_secureboost_0.output.data))
pipeline.compile();
# 执行
pipeline.fit()
以上是训练代码
保存模型参数
# 保存模型参数文件 .pkl
pipeline.dump("pipeline_saved.pkl");
然后就是重载模型 + 预测:
# 重载模型
pipeline = PipeLine.load_model_from_file('model/pipeline_saved.pkl')
pipeline.deploy_component([pipeline.data_transform_0, pipeline.intersect_0, pipeline.hetero_secureboost_0]);
reader_1 = Reader(name="reader_1")
reader_1.get_party_instance(role="guest", party_id=9999).component_param(table="name": "breast_hetero_guest", "namespace": namespace)
reader_1.get_party_instance(role="host", party_id=10000).component_param(table="name": "breast_hetero_host", "namespace": namespace)
evaluation_0 = Evaluation(name="evaluation_0", eval_type="binary")
predict_pipeline = PipeLine()
predict_pipeline.add_component(reader_1)\\
.add_component(pipeline,
data=Data(predict_input=pipeline.data_transform_0.input.data: reader_1.output.data))\\
.add_component(evaluation_0, data=Data(data=pipeline.hetero_secureboost_0.output.data));
predict_pipeline.predict()
这里重载模型官方教程非常散乱,只能自己摸索:
pipeline.deploy_component([pipeline.data_transform_0, pipeline.intersect_0, pipeline.hetero_secureboost_0]);
这边reader_0作为数据layer是不放入deploy中的,这里可以看到只有数据加工层,交互层,模型层
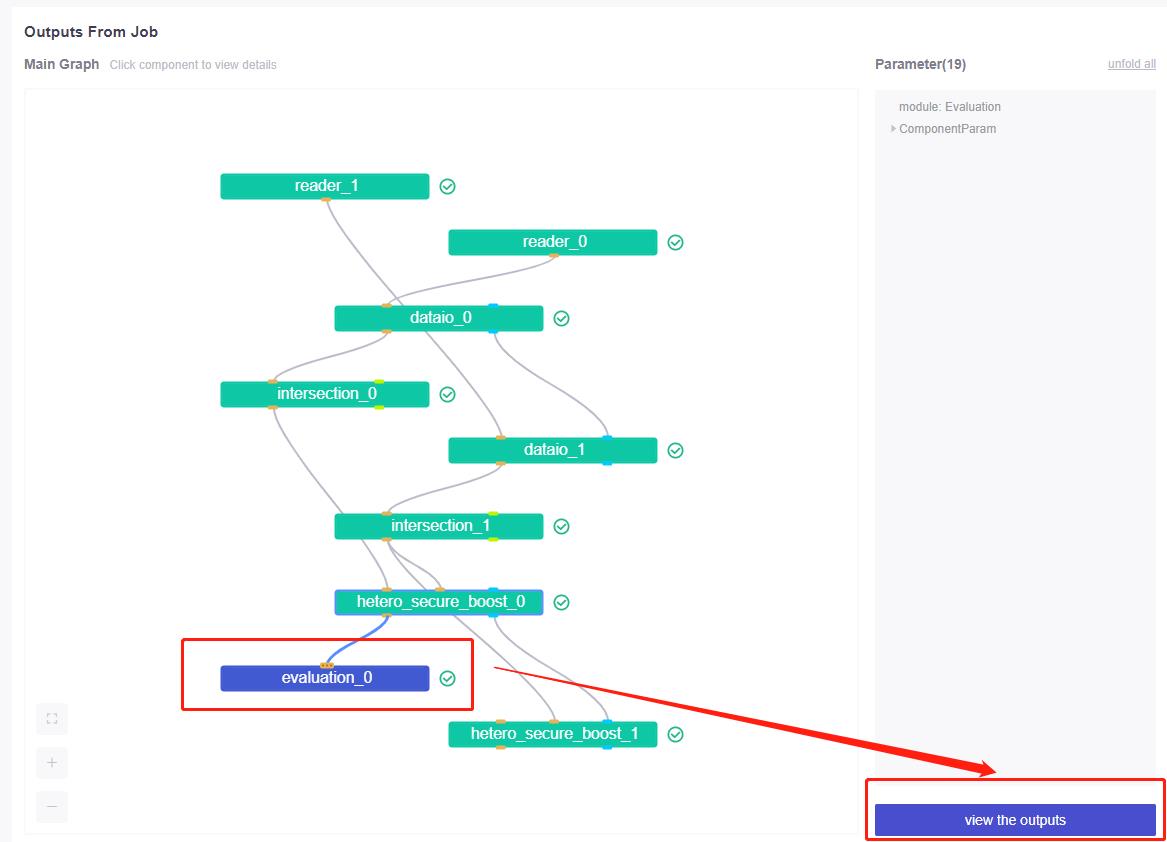
要看评估结果需要到fateboard:
3 纵向案例二:回归模型-hetero_sbt
回归来自官方教程benchmark_quality/hetero_sbt
官方所有案例数据可参考:examples/data
3.1 吐槽官方文档的不友好
当然这里官方真是省略,这么一堆文件一开始你根本看不明白,都是些什么…
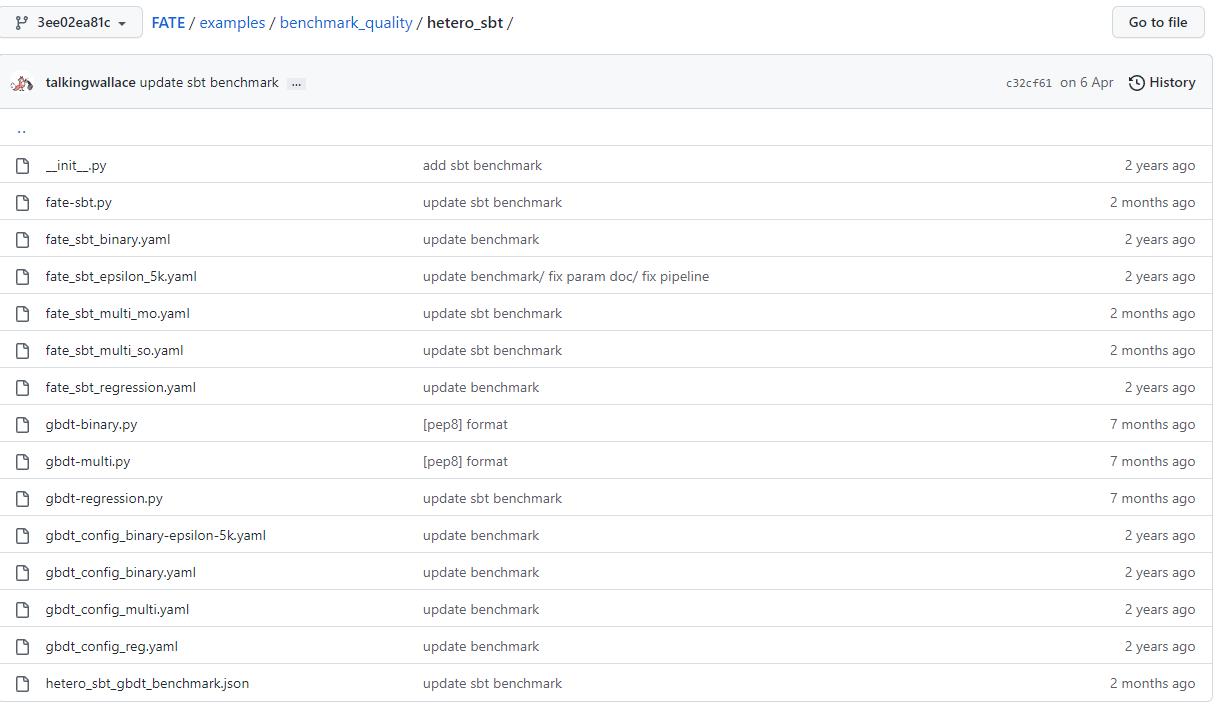
核心要看:
hetero_sbt_gbdt_benchmark.json
这些里面有非常多的案例集:
"hetero_sbt-binary-0":
"local":
"script": "./gbdt-binary.py",
"conf": "./gbdt_config_binary.yaml"
,
"FATE":
"script": "./fate-sbt.py",
"conf": "./fate_sbt_binary.yaml"
,
"compare_setting":
"relative_tol": 0.01
,
"hetero_sbt-binary-1":
"local":
"script": "./gbdt-binary.py",
"conf": "./gbdt_config_binary-epsilon-5k.yaml"
,
"FATE":
"script": "./fate-sbt.py",
"conf": "./fate_sbt_epsilon_5k.yaml"
,
"compare_setting":
"relative_tol": 0.01
,
"hetero_sbt-regression-0":
"local":
"script": "./gbdt-regression.py",
"conf": "./gbdt_config_reg.yaml"
,
"FATE":
"script": "./fate-sbt.py",
"conf": "./fate_sbt_regression.yaml"
,
"compare_setting":
"relative_tol": 0.01
,
比如笔者截取了三个案例配对,hetero_sbt-binary-0代表0/1二分类模型案例1,hetero_sbt-binary-1代表0/1二分类模型案例2;hetero_sbt-regression-0代表回归案例
所以需要跑FATE的话引用的是:
"script": "./fate-sbt.py",
"conf": "./fate_sbt_regression.yaml"
如果需要同一批数据跑GBDT模型的话,需要看以下两个文件:
"local":
"script": "./gbdt-regression.py",
"conf": "./gbdt_config_reg.yaml"
,
3.2 回归实战
这里需要安装federatedml/fate_test这两个,一种方式就是
需要github 里面下载,手动安装,python setup.py install
地址为:https://github.com/FederatedAI/FATE/tree/master/python
# fate_test 需要高版本的prettytable ORGMODE
pip install -i https://pypi.doubanio.com/simple prettytable==2.0.0
同时安装之后笔者报错了prettytable ,于是需要修改一下依赖
笔者改良了代码之后,整理如下:
import argparse
from pipeline.backend.pipeline import PipeLine
from pipeline.component.dataio import DataIO
from pipeline.component.hetero_secureboost import HeteroSecureBoost
from pipeline.component.intersection import Intersection
from pipeline.component.reader import Reader
from pipeline.interface.data import Data
from pipeline.component.evaluation import Evaluation
from pipeline.interface.model import Model
from pipeline.utils.tools import load_job_config
from pipeline.utils.tools import JobConfig
# 加载federatedml的链接,笔者自己引用文件也是可以的
import sys
sys.path.append('FATE-master\\\\python')
from federatedml.evaluation.metrics import regression_metric, classification_metric
# 需安装
from fate_test.utils import extract_data, parse_summary_result
def parse_summary_result(rs_dict):
for model_key in rs_dict:
rs_content = rs_dict[model_key]
if 'validate' in rs_content:
return rs_content['validate']
else:
return rs_content['train']
def HeteroSecureBoost_model(param):
'''
初始化配置
'''
guest = param['guest']
host = param['host']
namespace = param['namespace']
# data sets
guest_train_data = "name": param['data_guest_train'], "namespace": namespace
host_train_data = "name": param['data_host_train'], "namespace": namespace
guest_validate_data = "name": param['data_guest_val'], "namespace": namespace
host_validate_data = "name": param['data_host_val'], "namespace": namespace
# init pipeline
pipeline = PipeLine().set_initiator(role="guest", party_id=guest).set_roles(guest=guest, host=host,)
# set data reader and data-io
'''
计算图构建
留意 guest是需要保留y/target的一方
'''
reader_0, reader_1 = Reader(name="reader_0"), Reader(name="reader_1")
reader_0.get_party_instance(role="guest", party_id=guest).component_param(table=guest_train_data)
reader_0.get_party_instance(role="host", party_id=host).component_param(table=host_train_data)
reader_1.get_party_instance(role="guest", party_id=guest).component_param(table=guest_validate_data)
reader_1.get_party_instance(role="host", party_id=host).component_param(table=host_validate_data)
dataio_0, dataio_1 = DataIO(name="dataio_0"), DataIO(name="dataio_1")
dataio_0.get_party_instance(role="guest", party_id=guest).component_param(with_label=True, output_format="dense")
dataio_0.get_party_instance(role="host", party_id=host).component_param(with_label=False)
dataio_1.get_party_instance(role="guest", party_id=guest).component_param(with_label=True, output_format="dense")
dataio_1.get_party_instance(role="host", party_id=host).component_param(with_label=False)
# data intersect component
# 参数看:https://fate.readthedocs.io/en/latest/federatedml_component/intersect/
intersect_0 = Intersection(name="intersection_0")
intersect_1 = Intersection(name="intersection_1")
# dir(intersect_0)
# intersect_0.join_method
# secure boost component
multi_mode = 'single_output'
if 'multi_mode' in param:
multi_mode = param['multi_mode']
hetero_secure_boost_0 = HeteroSecureBoost(name="hetero_secure_boost_0",
num_trees=param['tree_num'],
task_type=param['task_type'],
objective_param="objective": param['loss_func'],
encrypt_param="method": "Paillier",
tree_param="max_depth": param['tree_depth'],
validation_freqs=1,
learning_rate=param['learning_rate'],
multi_mode=multi_mode
)
else:
hetero_secure_boost_0 = HeteroSecureBoost(name="hetero_secure_boost_0",
num_trees=param['tree_num'],
task_type=param['task_type'],
objective_param="objective": param['loss_func'],
encrypt_param="method": "Paillier",
tree_param="max_depth": param['tree_depth'],
validation_freqs=1,
learning_rate=param['learning_rate']
)
hetero_secure_boost_1 = HeteroSecureBoost(name="hetero_secure_boost_1")
# evaluation component
evaluation_0 = Evaluation(name="evaluation_0", eval_type=param['eval_type'])
pipeline.add_component(reader_0)
pipeline.add_component(reader_1)
pipeline.add_component(dataio_0, data=Data(data=reader_0.output.data))
pipeline.add_component(dataio_1, data=Data(data=reader_1.output.data), model=Model(dataio_0.output.model))
pipeline.add_component(intersect_0, data=Data(data=dataio_0.output.data))
pipeline.add_component(intersect_1, data=Data(data=dataio_1.output.data))
pipeline.add_component(hetero_secure_boost_0, data=Data(train_data=intersect_0.output.data,
validate_data=intersect_1.output.data))
pipeline.add_component(hetero_secure_boost_1, data=Data(test_data=intersect_1.output.data),
model=Model(hetero_secure_boost_0.output.model))
pipeline.add_component(evaluation_0, data=Data(data=hetero_secure_boost_0.output.data))
'''
训练
'''
pipeline.compile()
pipeline.fit()
'''
评估
'''
sbt_0_data = pipeline.get_component("hetero_secure_boost_0").get_output_data().get("data")
sbt_1_data = pipeline.get_component("hetero_secure_boost_1").get_output_data().get("data")
sbt_0_score = extract_data(sbt_0_data, "predict_result")
sbt_0_label = extract_data(sbt_0_data, "label")
sbt_1_score = extract_data(sbt_1_data, "predict_result")
sbt_1_label = extract_data(sbt_1_data, "label")
sbt_0_score_label = extract_data(sbt_0_data, "predict_result", keep_id=True)
# 所有预测的结果找出,训练集预测的结果
sbt_1_score_label = extract_data(sbt_1_data, "predict_result", keep_id=True)
metric_summary = parse_summary_result(pipeline.get_component("evaluation_0").get_summary())
if param['eval_type'] == "regression":
desc_sbt_0 = regression_metric.Describe().compute(sbt_0_score)
desc_sbt_1 = regression_metric.Describe().compute(sbt_1_score)
metric_summary["script_metrics"] = "hetero_sbt_train": desc_sbt_0,
"hetero_sbt_validate": desc_sbt_1
elif param['eval_type'] == "binary":
metric_sbt =
"score_diversity_ratio": classification_metric.Distribution.compute(sbt_0_score_label, sbt_1_score_label),
"ks_2samp": classification_metric.KSTest.compute(sbt_0_score, sbt_1_score),
"mAP_D_value": classification_metric.AveragePrecisionScore().compute(sbt_0_score, sbt_1_score, sbt_0_label,
sbt_1_label)
metric_summary["distribution_metrics"] = "hetero_sbt": metric_sbt
elif param['eval_type'] == "multi":
metric_sbt =
"score_diversity_ratio": classification_metric.Distribution.compute(sbt_0_score_label, sbt_1_score_label)
metric_summary["distribution_metrics"] = "hetero_sbt": metric_sbt
data_summary = "train": "guest": guest_train_data["name"], "host": host_train_data["name"],
"test": "guest": guest_train_data["name"], "host": host_train_data["name"]
# 其他组件全部放一起
component = 'dataio_0':dataio_0,'dataio_1':dataio_1,
'intersect_0':intersect_0,'intersect_1':intersect_1,
'hetero_secure_boost_0':hetero_secure_boost_0,'hetero_secure_boost_1':hetero_secure_boost_1,
'evaluation_0':evaluation_0
return pipeline,data_summary, metric_summary,component
写好参数,执行代码:
# 模型训练与估计
fate_sbt_regression_param = 'data_guest_train': "student_hetero_guest",
'data_guest_val': "student_hetero_guest",
'data_host_train': "student_hetero_host",
'data_host_val': "student_hetero_host",
'eval_type': "regression",
'task_type': "regression",
'loss_func': "lse",
'tree_depth': 3,
'tree_num': 50,
'learning_rate': 0.1
fate_sbt_regression_param['guest'] = 9999
fate_sbt_regression_param['host'] = 10000
fate_sbt_regression_param['namespace'] = 'student_hetero'
!pipeline init --ip fate-9999.aliyun.xxxx.com --port 9380
!pipeline config check
pipeline,data_summary, metric_summary,component = HeteroSecureBoost_model( fate_sbt_regression_param)
来看看注意事项,9999启动的,需要与guest网络9999端口对齐,必要条件;
同时,guest服务器,需要存储y,host是没有y的,component_param(with_label=True, output_format="dense")这个里面,代表数据集是否有label标签
然后整篇回归or分类,你是看不到,他如何知道y是如何指定的,这里就是另一个坑点是,因为你的数据集里面一定要有命名为y的列:
dataio_0, dataio_1 = DataIO(name="dataio_0"), DataIO(name="dataio_1")
dataio_0.get_party_instance(role="guest", party_id=guest).component_param(with_label=True, output_format="dense")
其中dataIO的component_param,自带了默认,可参考文档
- with_label:默认
False - label_name:默认
y
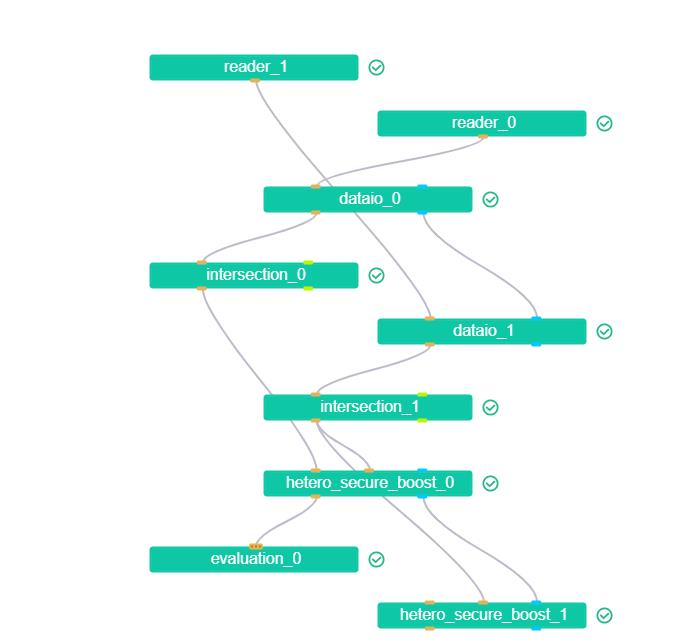
整个计算图为:
3.3 模型保存
pipeline.dump("model/sbt_regression_pipeline_saved.pkl");
3.4 模型预测
没跑通,文档没写,自己也没试验出来…
4 一些属性项
如何在数据载入的过程中定义Y:dataIO
如[3.2]所述,
其中dataIO的component_param,自带了默认,可参考文档
- with_label:默认
False - label_name:默认
y
还有一个比较需要留意的是:Intersection
- intersect_method:it supports
rsa,raw, anddh, default byrsa - join_role:默认
guest,代表合并数据集的时候,往那边对齐 - join_method:
'inner_join', 'left_join',默认inner_join,这个很关键,默认是内连接的
9 报错汇总
9.1 create job failed:Rendezvous of RPC that terminated
job failed很多可能,而且这边你看一堆报错,其实比较不友好,
这里RPC报错,笔者debug下来是,其中一个fate server节点,内存爆了,所以报错了
ValueError: job submit failed, err msg:
'jobId': '202206141318127064460',
'retcode': 103,
'retmsg': 'Traceback (most recent call last):\\n
File "/data/projects/fate/fateflow/python/fate_flow/scheduler/dag_scheduler.py",
line 133, in submit\\n raise Exception("create job failed", response)\\n
Exception: (\\'create job failed\\', \\'guest\\': 9999: \\'retcode\\':
<RetCode.FEDERATED_ERROR: 104>, \\'retmsg\\':
\\'Federated schedule error, Please check rollSite and fateflow
network connectivityrpc request
error: <_Rendezvous of RPC that terminated with:\\\\n\\\\tstatus =
StatusCode.DEADLINE_EXCEEDED\\\\n\\\\tdetails =
"Deadline Exceeded"\\\\n\\\\
tdebug_error_string = ""created":"@1655212788.754145803",
"description":"Error received from peer ipv4:192.167.0.5:9370",
"file":"src/core/lib/surface/call.cc",
"file_line":1055,"grpc_message":"Deadline Exceeded","grpc_status":4"\\\\n>\\',
\\'host\\': 10000: \\'data\\': \\'components\\': \\'data_transform_0\\':
\\'need_run\\': True,
\\'evaluation_0\\': \\'need_run\\': True, \\'hetero_secureboost_0\\':
\\'need_run\\': True,
\\'intersect_0\\': \\'need_run\\': True, \\'reader_0\\': \\'need_run\\': True,
\\'retcode\\': 0, \\'retmsg\\': \\'success\\')\\n'
9.2 数据源上传或无效的问题
ValueError: Job is failed, please check out job 202206150402440818810 by fate board or fate_flow cli
一般如果出现这类情况,是需要到fateboard找问题原因,笔者之前是因为某台节点没有正确上传数据造成的问题
RuntimeError: can not found table name: breast_hetero_host namespace: experiment_0615
同类如果出现这类型,就是namespace有弄错了
以上是关于坑挺多 | 联邦学习FATE:训练模型的主要内容,如果未能解决你的问题,请参考以下文章