坑挺多 | 联邦学习FATE:上传数据
Posted 悟乙己
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了坑挺多 | 联邦学习FATE:上传数据相关的知识,希望对你有一定的参考价值。
吐槽一下这个号称“最流行”的联邦学习框架,对新手入门非常不友好,从安装到上传数据,需要多个文档对着看,列举一下笔者在自己测试时候的坑:
- 代码确实有,但是配套的说明文档不是一气呵成的,需要多个地方对着看才能看懂
- 社群基数还不友好,很多问题难以找到解答,要么就是在官方群里问
- 报错信息乱七八糟,丢了一堆,debug非常困难
- 代码对新手不友好,基本需要你对这款比较熟悉,才能猜到一些默认参数会是什么
- 很多依赖代码没说明白
几个需要对着看的官方文档:
GITHUB
readthedocs
文章目录
1 上传数据之前需要知道的坑点
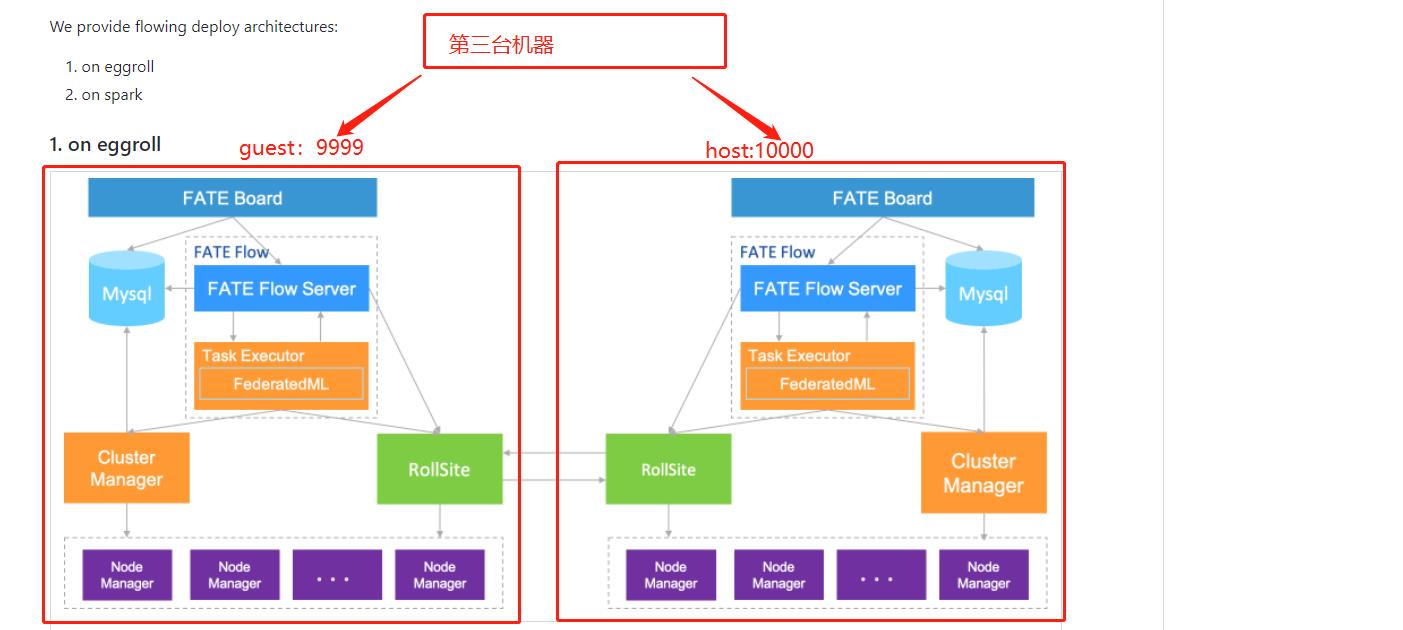
1.1 在哪台机器上传数据?
笔者作为新手,一开始对官方[Pipeline Upload Data Tutorial]教程的以下代码感到很困惑:
!pipeline init --ip 127.0.0.1 --port 9380
因为127.0.0.1代表你启动的是本机的fate,也就是如果你有两台服务器,9999/10000,你应该需要挑选某一台进行上传数据/建模等其他操作?
那能不能由第三台服务器进行上传数据操作呢?
当然,答案是:可以的
1.2 如何连接fate server
首先各类教程里面,pipeline init就是启动了fate flow server,
!pipeline init --ip 127.0.0.1 --port 9380
但是你会发现,最坑的是,不论你ip换成啥,都会显示Pipeline configuration succeeded.
笔者一开始看到succeeded就觉得没问题了,但是跑后面的代码一直报错:
"retcode": 100,
"retmsg": "Connection refused. Please check if the fate flow service is started"
就一直报错,查了半天也没有什么教程解释;终于自己摸索了半天才发现:
!pipeline config check
>>> Flow server status normal, Flow version: 1.7.2
这样才是正确的检查是否启动fate flow server的正确姿势
所以这里最好换成公有IP:
!pipeline init --ip 你的公有IP --port 9380
!pipeline config check
1.3 需要及时切换IP才能上传两台服务器
笔者是在同一个jupyter里面测试,
!pipeline init --ip fate-9999.aliyun.xxxx.com --port 9380
首先我连接9999,然后上传数据;
之后想在10000上传数据,那么笔者当然以为在同一个kernel下pipeline init --ip 10000,就切换到了10000,然后就可以上传了;
但,这样是不行的,需要你restart kernel,才行。
2 上传数据代码
笔者自己根据实验总结如下的上传代码:
from pipeline.backend.pipeline import PipeLine
import os
def upload_fate_data(params,partition = 4,\\
role = 'guest',party_id = 9999,guest=9999):
pipeline_upload = PipeLine().set_initiator(role=role, party_id=party_id).set_roles(guest=guest)
pipeline_upload.add_upload_data(file=params['file_name'],
table_name=params["name"], # table name
namespace=params["namespace"], # namespace
head=1,
partition=partition) # data info
pipeline_upload.upload(drop=1)
print('success upload!')
data_base = "/FATE-master/examples/data" # 数据地址
namespace = 'student_hetero'
host_train_data_params = "name": "student_hetero_host",\\
"namespace": namespace,\\
'file_name':os.path.join(data_base,'student_hetero_host.csv')
host_test_data_params = "name": "student_hetero_host",\\
"namespace": namespace,\\
'file_name':os.path.join(data_base,'student_hetero_host.csv')
guest_train_data_params = "name": "student_hetero_guest",\\
"namespace": namespace,\\
'file_name':os.path.join(data_base,'student_hetero_guest.csv')
guest_test_data_params = "name": "student_hetero_guest",\\
"namespace": namespace,\\
'file_name':os.path.join(data_base,'student_hetero_guest.csv')
#### guest网络
!pipeline init --ip fate-9999.aliyun.xxxx.com --port 9380
!pipeline config check
upload_fate_data(guest_train_data_params,partition = 4)
upload_fate_data(guest_test_data_params,partition = 4)
上面在guest上传了两份数据,然后需要restart kernel,然后继续在10000上传数据
#### host网络
!pipeline init --ip fate-10000.aliyun.xxxx.com --port 9380
!pipeline config check
upload_fate_data(host_train_data_params,partition = 4)
upload_fate_data(host_test_data_params,partition = 4)
当然,这里笔者继续吐槽,看到fateboard,因为笔者pipeline初始化,设置的是role = 'guest',但是现在上传role 显示是local,也把笔者恶心了一阵子…
当然,笔者后面无力继续究其原因,感觉,在上传数据环节,无论你role设置成啥,到最后,还是role为local

你上传了两个数据集,就会生成2个job
3 各类报错小记
3.1 最恶心笔者的:Connection refused. Please check if the fate flow service is started
"retcode": 100,
"retmsg": "Connection refused. Please check if the fate flow service is started"
刚刚提到过了,需要
!pipeline config check
查看
3.2 各类依赖版本不对
AttributeError: type object 'h5py.h5r.Reference' has no attribute '__reduce_cython__'
>>> 需要重新安装h5py,先卸载,再重装
'_ipython_canary_method_should_not_exist_'
2022-06-14 21:09:13.653 | ERROR | IPython.utils.dir2:get_real_method:74 - An error has been caught in function 'get_real_method', process 'MainProcess' (10068), thread 'MainThread' (23392):
遇到很多,反正看提示,重装。。
以上是关于坑挺多 | 联邦学习FATE:上传数据的主要内容,如果未能解决你的问题,请参考以下文章