联邦学习实战基于FATE框架的MNIST手写数字识别——全连接神经网络
Posted HERODING23
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了联邦学习实战基于FATE框架的MNIST手写数字识别——全连接神经网络相关的知识,希望对你有一定的参考价值。
基于FATE框架的MNIST手写数字识别——全连接神经网络
前言
ATE是微众银行开发的联邦学习平台,是全球首个工业级的联邦学习开源框架,在github上拥有超过4000stars,可谓是相当有名气的,该平台为联邦学习提供了完整的生态和社区支持,为联邦学习初学者提供了很好的环境,否则利用python从零开发,那将会是一件非常痛苦的事情。本篇博客是FATE联邦学习实战的第一次实践,目的是在FATE框架上用全连接神经网络成功训练出手写数字识别模型,至于之后联邦学习实战内容,就是在手写数字识别模型的基础上,增加加密算法的应用,下面就让我们开始吧!
1. 下载MNIST数据集
由于在FATE中,所有的数据集都要转换为DTable格式进行训练,而DTable又是通过csv文件的转换生成的数据结构,所以MNIST数据集不是传统的图片格式,而是转化成csv文件格式。转换csv文件格式的方法有两种,一个是直接从Kaggle官网上下载,第二种是自定义转换格式的python代码实现。
1.1 Kaggle
第一种方法是直接在Kaggle的MNIST的csv格式数据集链接下载即可,如果没有注册的朋友需要注册一下才能下载,过程还是很简单的,打开的csv文件内容如下所示: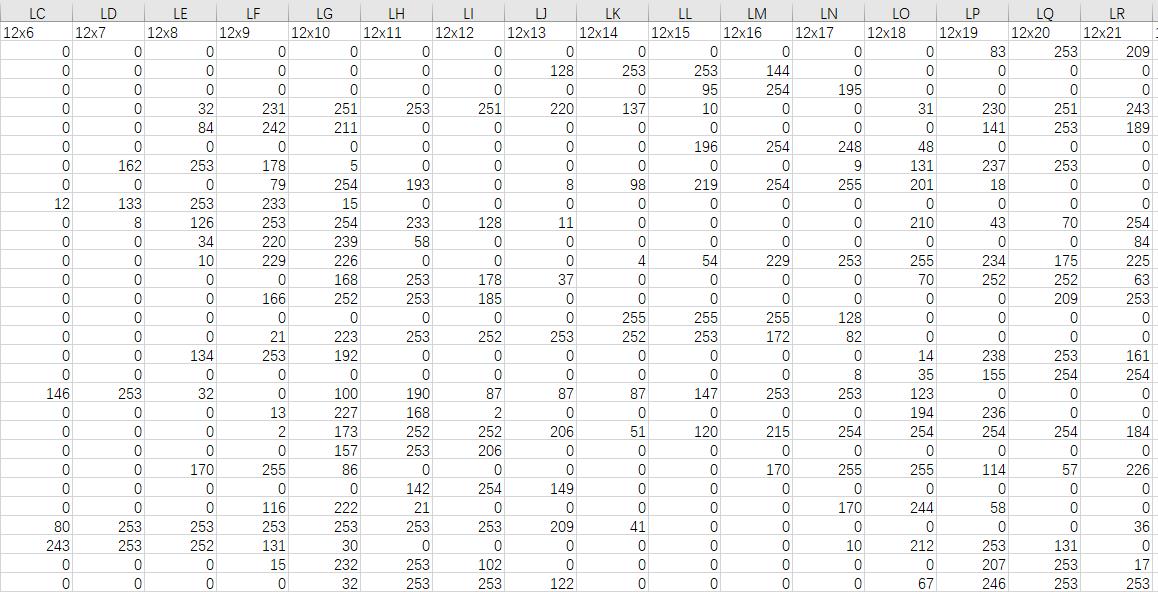 可以看到每张图片以28×28像素点的数据存储下来,每个像素点中的值为灰度值,范围为0~255。
可以看到每张图片以28×28像素点的数据存储下来,每个像素点中的值为灰度值,范围为0~255。
1.2 Python格式转换
第二种方法参考了博主ysk2931文章中的方法,他的思路为首先解压,将gz文件转换成-ubyte,再将ubyte文件转换为csv文件,代码如下:
def convert(imgf, labelf, outf, n):
f = open(imgf, "rb")
o = open(outf, "w")
l = open(labelf, "rb")
f.read(16)
l.read(8)
images = []
for i in range(n):
image = [ord(l.read(1))]
for j in range(28*28):
image.append(ord(f.read(1)))
images.append(image)
for image in images:
o.write(",".join(str(pix) for pix in image)+"\\n")
f.close()
o.close()
l.close()
convert("train-images.idx3-ubyte", "train-labels.idx1-ubyte",
"mnist_train.csv", 60000)
convert("t10k-images.idx3-ubyte", "t10k-labels.idx1-ubyte",
"mnist_test.csv", 10000)
print("Convert Finished!")
2. 数据集分割
2.1 bash命令分割
bash命令参考的是其他博主处理时的操作,将训练数据集分割为同等大小的两部分,即分为两个各有3w条数据的数据集,分别作为两个参与方参与训练的训练集。由于FATE训练必须要有id,所以首先,在第一列label前面加上新的一列id,新的一列第一行为id,之后行为序号。
awk -F'\\t' -v OFS=',' ' NR == 1 print "idx",$0; next print (NR-1),$0' mnist_train.csv > mnist_train_with_id.csv
接着将表头的label换成y,因为FATE训练的conf文件中默认把y作为标签。
sed -i "s/label/y/g" mnist_train_with_id.csv
将mnist_train_with_id.csv文件进行分割,每个文件30001行,其中一行表头,其余都是数据,生成两个文件:mnist_train_3w.csvaa和mnist_train_3w.csvab。
split -l 30001 mnist_train_with_id.csv mnist_train_3w.csv
将生成的两个文件拷贝为csv文件。
mv mnist_train_3w.csvaa mnist_train_3w_a.csv
mv mnist_train_3w.csvab mnist_train_3w_b.csv
再将mnist_train_3w_a.csv的heading复制插入到mnist_train_3w_b.csv中。
sed -i "`cat -n mnist_train_3w_a.csv |head -n 1`" mnist_train_3w_b.csv
同时对测试集数据进行相同的处理,但注意不需要分割。
2.2 python切分数据
用上述方法进行数据分割确实简单方便,但是忽略了数据归一化的操作,这一点对模型的影响是巨大的,博主在跑了两天代码后才意识到这个问题,就是未归一化的数据在训练时,每轮迭代结果常常不稳定,有时候本来都到了80%的accuracy,突然降到60%以下,最终模型AUC为1,precision为1,recall为0,训练过程中loss也几乎没有变化,这显然是遇到了梯度消失或爆炸的问题,而解决此类问题的关键就是进行标准化处理。
标准化的方法采用01标准化的方法,如果采用z-score标准化的方法,会出现NAN的结果。在导入csv文件后,单独把x和y分开(x是灰度值信息,y是标签),然后对x进行标准化处理,再把y拼接上来,注意要给csv文件加上序号,最后打乱序号生成csv文件,代码如下:
import pandas as pd
# 导入并查看数据
mnist_train = pd.read_csv('mnist_train.csv')
mnist_test = pd.read_csv('mnist_test.csv')
# 查看前五行数据
mnist_train.head()
mnist_test.head()
# 01标准化
train_target = mnist_train['label']
test_target = mnist_test['label']
mnist_train.drop('label', axis = 1, inplace=True)
mnist_test.drop('label', axis = 1, inplace=True)
mnist_train = mnist_train / 255.0
mnist_test = mnist_test / 255.0
# 加入y
mnist_train['y'] = train_target
mnist_test['y'] = test_target
# 插入每行序列
idx = range(mnist_train.shape[0])
mnist_train.insert(0, 'idx', idx)
idx = range(mnist_test.shape[0])
mnist_test.insert(0, 'idx', idx)
# 打乱数据并生成csv
mnist_train = mnist_train.sample(frac=1)
mnist_test = mnist_test.sample(frac=1)
mnist_train_3w_a = mnist_train.iloc[:30000]
mnist_train_3w_b = mnist_train.iloc[30000:]
mnist_train_3w_a.to_csv('mnist_train_3w_a.csv', index=False, header=True)
mnist_train_3w_b.to_csv('mnist_train_3w_b.csv', index=False, header=True)
mnist_test.to_csv('mnist_test_temp.csv', index=False, header=True)
3. 数据集上传
数据集从本地上传到FATE中有两种方式,分别是通过docker上传和使用rz工具上传。
3.1 docker上传
在本地文件目录下的终端环境中输入如下代码,将文
docker cp mnist_train_3w_a.csv fate:fate/examples/data/
docker cp mnist_train_3w_b.csv fate:fate/examples/data/
docker cp mnist_test.csv fate:fate/examples/data/
3.2 rz工具
如果docker中没有安装rz,那么就输入如下命令安装:
sudo apt-get install lrzsz
如果是在ubuntu主机上运行的,建议更换设备用xshell远程连接,否则在主机上输入命令会报乱码,在xshell中的docker环境下输入:
rz -be
直接弹出文件框选择文件进行上传。
3.3 FATE数据上传
在FATE中,所有训练的数据都要转换为DTable格式进行训练,所以还需要将之前上传的csv文件通过upload转换为DTable格式。
首先进入FATE容器:
docker exec -it fate bash
csv转换为DTable格式需要编写配置文件,配置文件的实例有两种,对应v1和v2两个版本,这里仅介绍v1版本。示例文件在fate/example/dsl/v1下。
upload_data.json 或 upload_host.json 或 upload_guest.json,结构如下:
"file": "examples/data/breast_hetero_guest.csv", // 数据文件路径,相对于当前所在路径
"head": 1, // 指定数据文件是否包含表头,1: 是,0: 否
"partition": 16, // 指定用于存储数据的分区数
"work_mode": 0, // 指定工作模式,0: 单机版,1: 集群版
"table_name": "breast_hetero_guest", // 需要转换为DTable格式的表名(相当于后续需要使用的表)
"namespace": "experiment" // DTable格式的表名对应的命名空间
在fate:1.6中输入如下命令就可以将csv文件数据转为DTable格式。
python /fate/python/fate_flow/fate_flow_client.py -f upload -c upload_data.json
首先编写host和guest两个参与方的训练数据文件,配置文件如下:
- 参与方A数据上传文件。
"file": "/fate/example/data/mnist_train_3w_a.csv",
"head": 1,
"partition": 8,
"work_mode": 0,
"table_name": "homo_mnist_1_train",
"namespace": "homo_host_mnist_train"
- 参与方B数据上传文件。
"file": "/fate/example/data/mnist_train_3w_b.csv",
"head": 1,
"partition": 8,
"work_mode": 0,
"table_name": "homo_mnist_2_train",
"namespace": "homo_guest_mnist_train"
接着编写host和guest两个参与方的测试数据文件,配置文件如下:
- 参与方A数据上传文件。
"file": "/fate/example/data/mnist_test.csv",
"head": 1,
"partition": 8,
"work_mode": 0,
"table_name": "homo_mnist_1_test",
"namespace": "homo_host_mnist_test"
- 参与方B数据上传文件。
"file": "/fate/example/data/mnist_test.csv",
"head": 1,
"partition": 8,
"work_mode": 0,
"table_name": "homo_mnist_2_test",
"namespace": "homo_guest_mnist_test"
如果运行的结果格式与下面代码相同,并且fate_board不报错,则数据上传成功。
"data":
"board_url": "http://127.0.0.1:8080/index.html#/dashboard?job_id=202204110957045063425&role=local&party_id=0",
"job_dsl_path": "/fate/jobs/202204110957045063425/job_dsl.json",
"job_id": "202204110957045063425",
"job_runtime_conf_on_party_path": "/fate/jobs/202204110957045063425/local/job_runtime_on_party_conf.json",
"job_runtime_conf_path": "/fate/jobs/202204110957045063425/job_runtime_conf.json",
"logs_directory": "/fate/logs/202204110957045063425",
"model_info":
"model_id": "local-0#model",
"model_version": "202204110957045063425"
,
"namespace": "homo_host_mnist_test",
"pipeline_dsl_path": "/fate/jobs/202204110957045063425/pipeline_dsl.json",
"table_name": "homo_mnist_1_test",
"train_runtime_conf_path": "/fate/jobs/202204110957045063425/train_runtime_conf.json"
,
"jobId": "202204110957045063425",
"retcode": 0,
"retmsg": "success"
 查看数据集,也是没有问题的。
查看数据集,也是没有问题的。
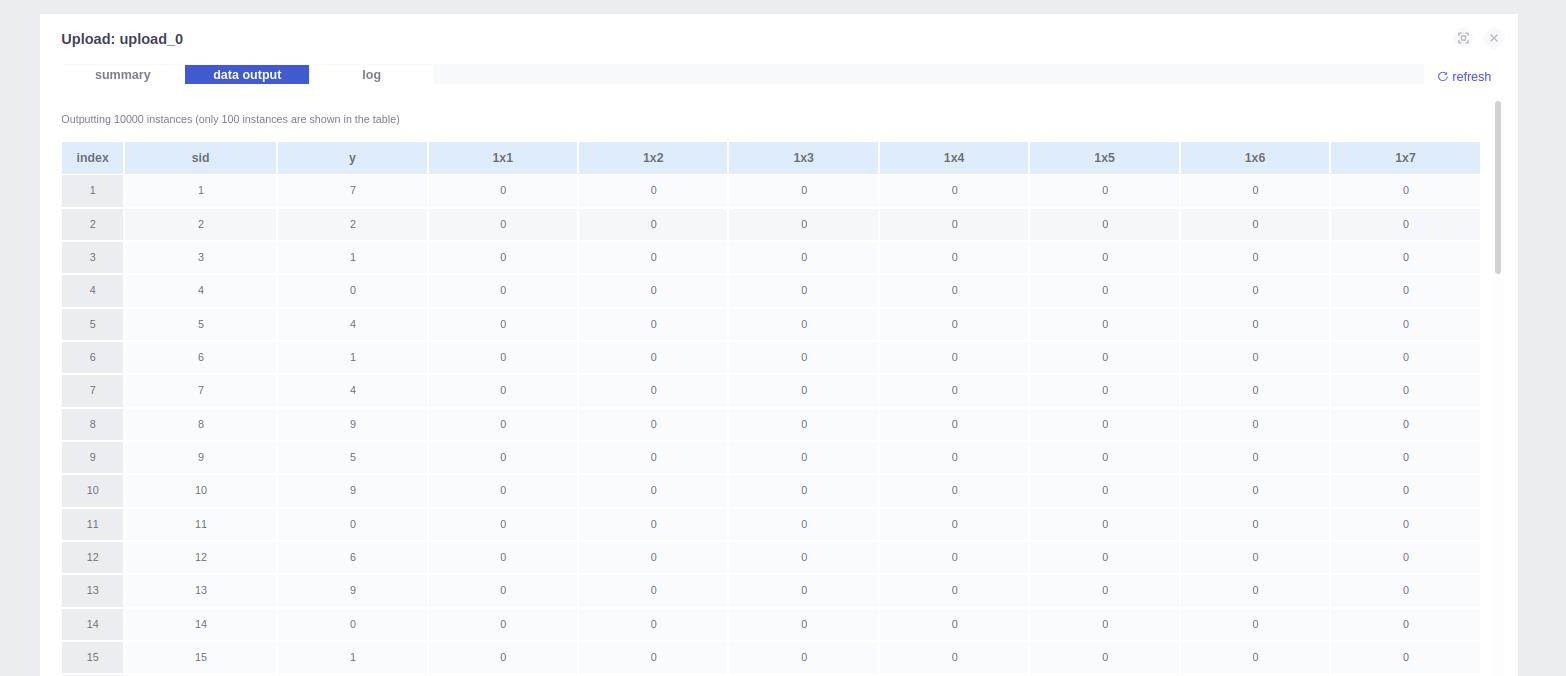
4. 模型训练
4.1 构建模型
对于手写数字识别模型的训练,可以通过很多深度学习模型进行搭建,比如三层隐藏层的全连接神经网络,卷积神经网络等,当然FATE也内置了许多深度学习模型可用,比如ResNet等。这里我们可以采用自定义模型的方法,自定义全连接神经网络来训练模型。
首先创建一个python文件。
vim dense_model.py
在python文件中构建模型,并将模型转换为json格式的数据。
import keras
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(128,activation='relu',input_shape=(784,)))
model.add(Dense(32,activation='relu'))
model.add(Dense(10,activation='softmax'))
json = model.to_json()
print(json)
注意FATE框架中的python环境并没有安装TensorFlow和keras,需要自己用pip安装,这里是keras与TensorFlow对应的版本号链接,各位小伙伴可以根据对应的版本进行下载,这里我提供一个样例。
# 卸载已经安装的工具包
pip uninstall tensorflow
pip uninstall tensorflow-cpu
pip uninstall keras
pip uninstall fate-client
pip uninstall numpy
# 安装对应版本的工具包
pip install tensorflow==1.14 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install keras==2.2.5 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install numpy==1.16.4 -i https://pypi.tuna.tsinghua.edu.cn/simple/
在终端py文件对应的目录下输入:
python dense_model.py
可以得到如下的输出信息。
"class_name": "Sequential", "config": "name": "sequential_1", "layers": ["class_name": "Dense", "config": "name": "dense_1", "trainable": true, "batch_input_shape": [null, 784], "dtype": "float32", "units": 128, "activation": "relu", "use_bias": true, "kernel_initializer": "class_name": "VarianceScaling", "config": "scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null, "bias_initializer": "class_name": "Zeros", "config": , "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null, "class_name": "Dense", "config": "name": "dense_2", "trainable": true, "dtype": "float32", "units": 32, "activation": "relu", "use_bias": true, "kernel_initializer": "class_name": "VarianceScaling", "config": "scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null, "bias_initializer": "class_name": "Zeros", "config": , "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null, "class_name": "Dense", "config": "name": "dense_3", "trainable": true, "dtype": "float32", "units": 10, "activation": "softmax", "use_bias": true, "kernel_initializer": "class_name": "VarianceScaling", "config": "scale": 1.0, "mode": "fan_avg", "distribution": "uniform", "seed": null, "bias_initializer": "class_name": "Zeros", "config": , "kernel_regularizer": null, "bias_regularizer": null, "activity_regularizer": null, "kernel_constraint": null, "bias_constraint": null], "keras_version": "2.2.5", "backend": "tensorflow"
4.2 修改配置文件
- conf文件
conf文件作用是设置模型的输入数据与模型的超参数。FATE中给出的keras的conf的模板为test_homo_nn_keras_temperate.json,拷贝一份命名为homo_dense_conf.json,复制上面的输出json结果,进入配置文件,拷贝到algorithm_parameters:homo_nn_0:位置:
vim /fate/examples/dsl/v1/homo_nn/homo_dense_conf.json

此外还有特别需要注意的,在输入csv文件的时候,y值的范围是0~9,而经过模型训得到的结果是one-hot编码,所以必须把y标签的值转换为one-hot编码才能进行剃度下降,在conf文件的algorithm_parameters下增加一项“encode_label”: true,如图所示。

在conf文件中还需要修改默认的输入数据DTable的namespace和name,改成我们之前上传的namepsace和name。
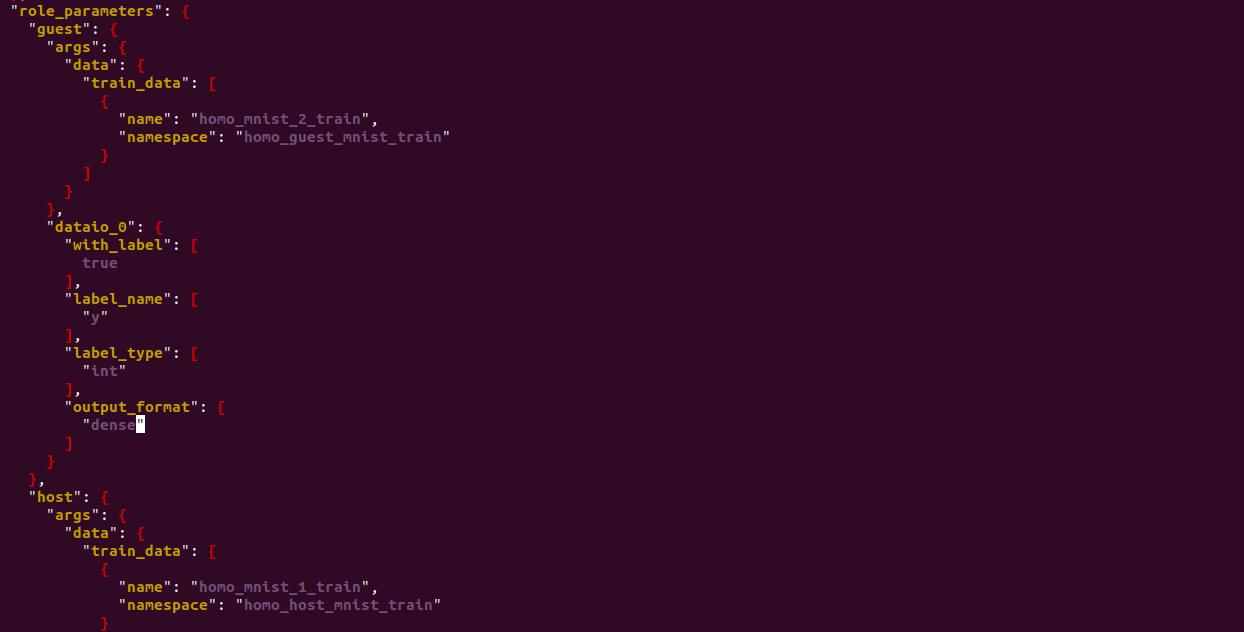 最后还要对超参数进行调整,读者可以自行修改,这里只是给一个参考:
最后还要对超参数进行调整,读者可以自行修改,这里只是给一个参考:

- dsl文件
dsl文件作用是描述任务模块,将任务模型以有向无环图形式组合。范例文件为test_homo_nn_train_then_predict.json,拷贝重命名为homo_dense_dsl.json,内容如下。
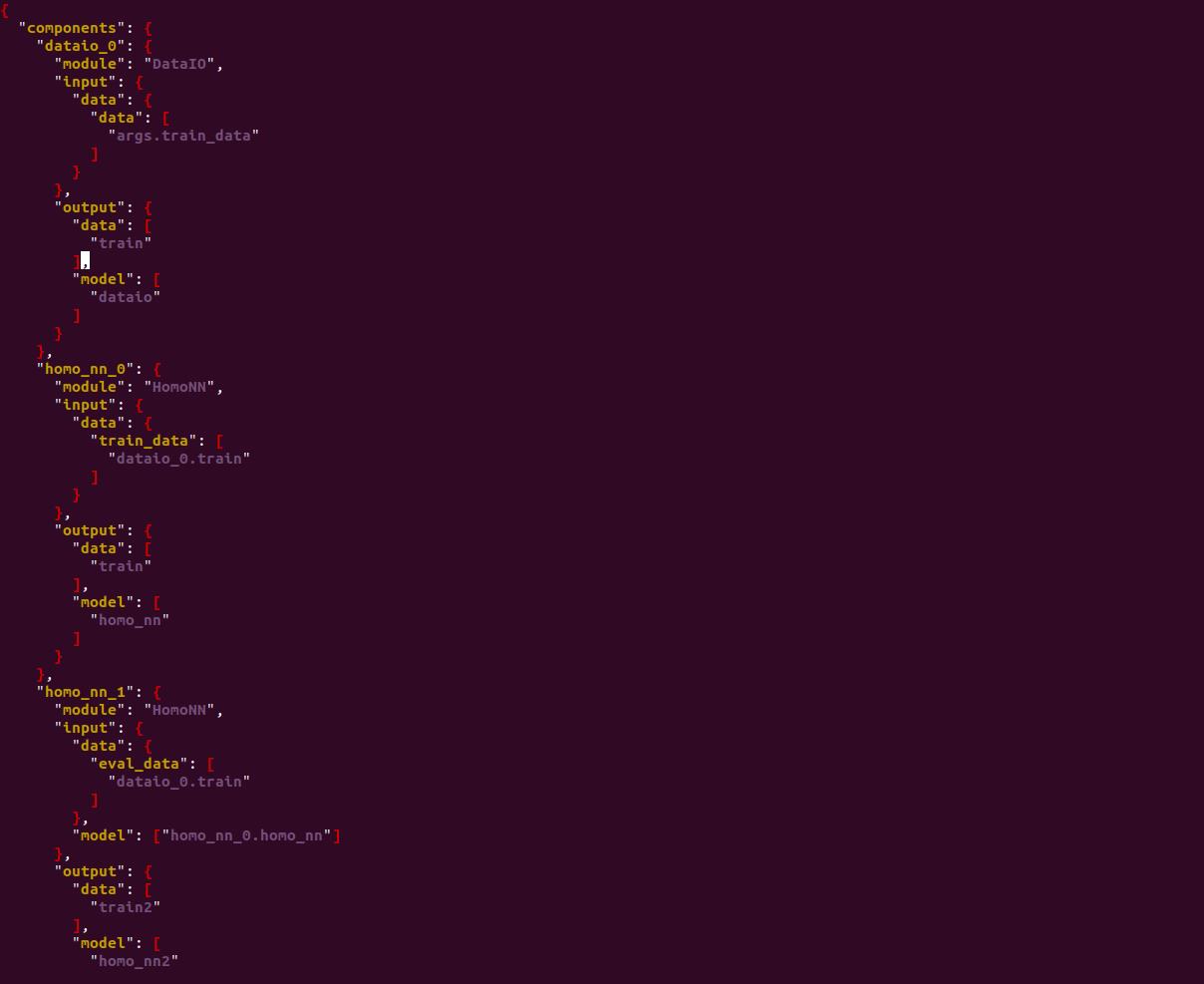
在训练阶段,只有homo_nn_0发挥了模型训练的作用,所以将文件中的homo_nn_1删除,添加评估模块,默认使用训练数据进行模型的评估预测。
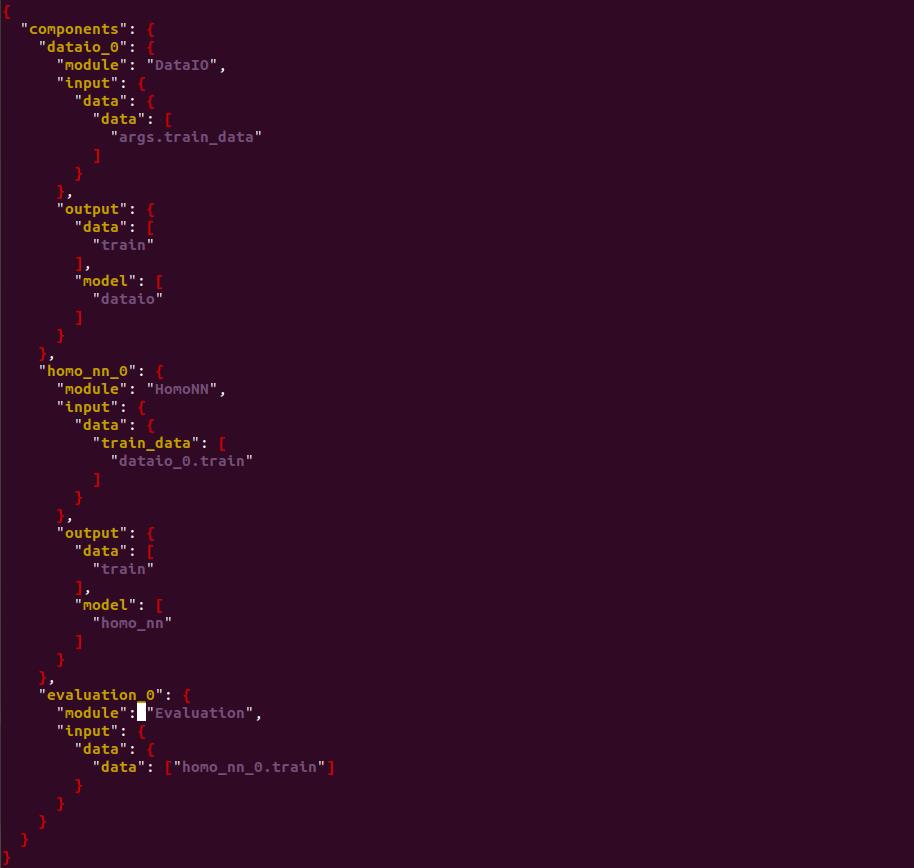
4.3 训练模型
在终端对应目录下输入:
python /fate/python/fate_flow/fate_flow_client.py -f submit_job -c homo_dense_conf.json -d homo_dense_dsl.json
输出如下信息,则文件中没有语法上的错误:
"data":
"board_url": "http://127.0.0.1:8080/index.html#/dashboard?job_id=202204140627093888147&role=guest&party_id=10000",
"job_dsl_path": "/fate/jobs/202204140627093888147/job_dsl.json",
"job_id": "202204140627093888147",
"job_runtime_conf_on_party_path": "/fate/jobs/202204140627093888147/guest/job_runtime_on_party_conf.json",
"job_runtime_conf_path": "/fate/jobs/202204140627093888147/job_runtime_conf.json",
"logs_directory": "/fate/logs/202204140627093888147",
"model_info":
"model_id": "arbiter-10000#guest-10000#host-10000#model",
"model_version": "202204140627093888147"
,
"pipeline_dsl_path": "/fate/jobs/202204140627093888147/pipeline_dsl.json",
"train_runtime_conf_path": "/fate/jobs/202204140627093888147/train_runtime_conf.json"
,
"jobId": "202204140627093888147",
"retcode": 0,
"retmsg": "success"
在FATE-Board上查看训练过程,Graph为模型元件组成的无向图。
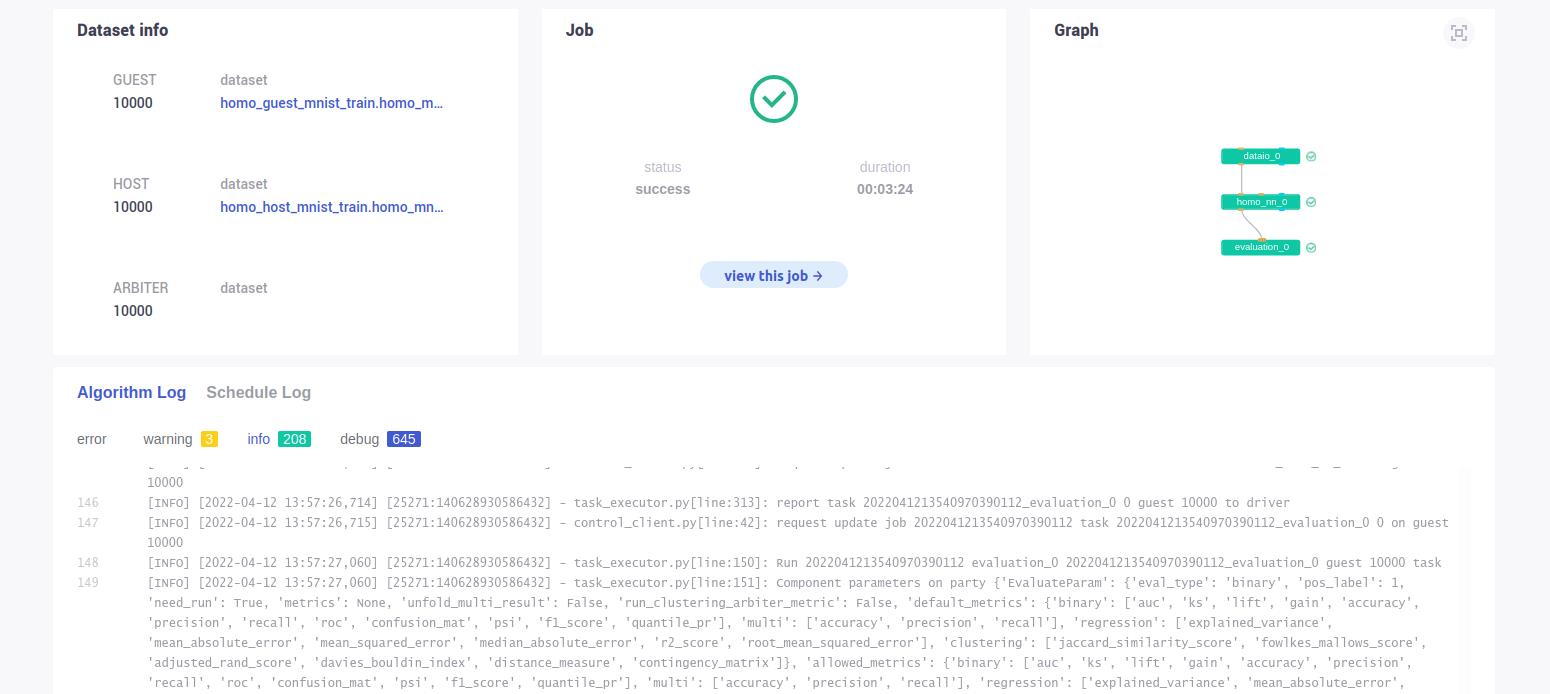
训练结果如下:

可以从训练中的日志得知,经过二十轮的aggregation,模型的精确度能够接近95%。
PS:仔细观察的朋友可能会有所疑惑,看的模型精度是通过查看训练部分的精度,那evalution_0究竟有什么用呢?我的回答是,在我的设计的模型下,其中的evalution_0是没有意义的,如下图所示:
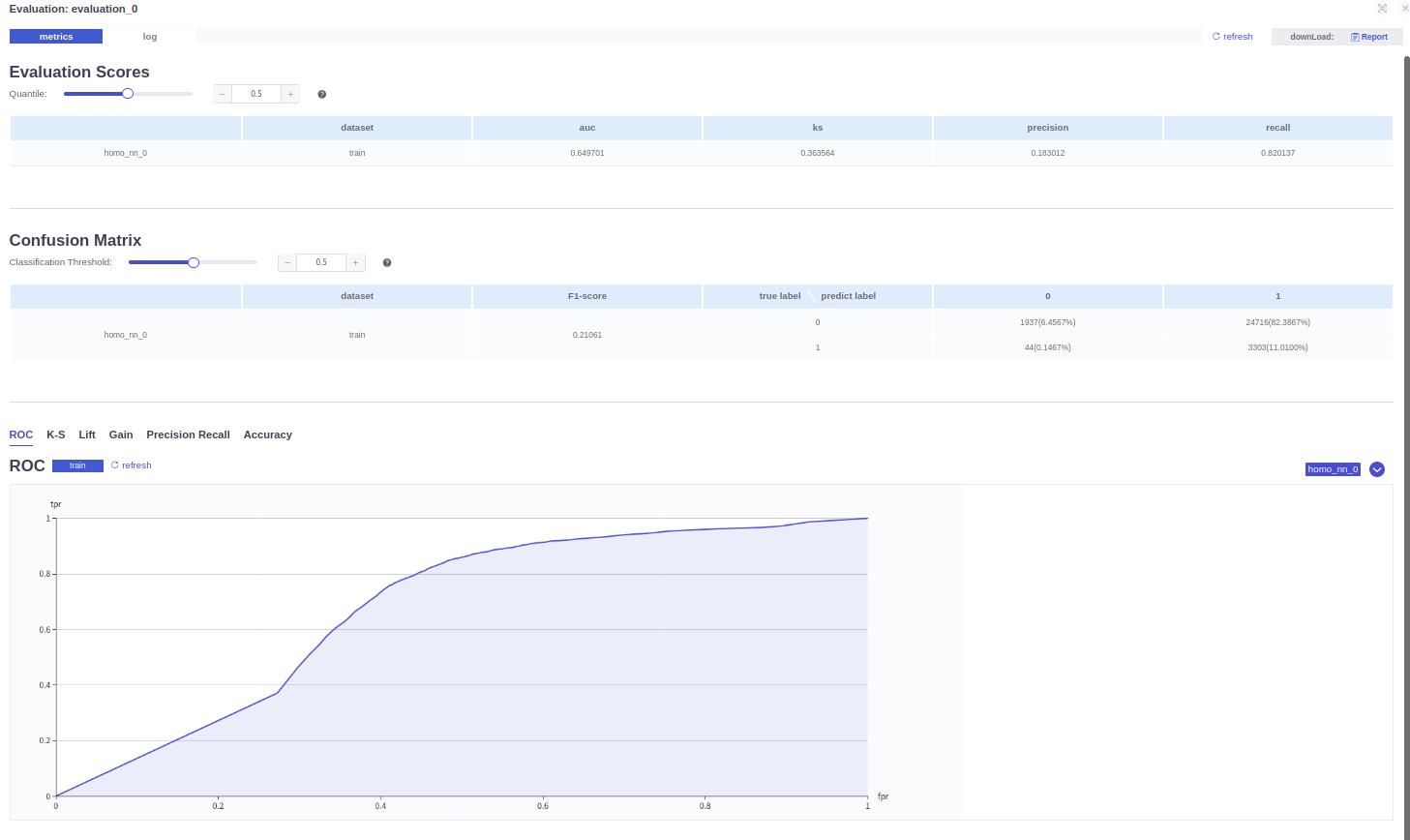
可以说是惨不忍睹了,为此我研究了一周多时间,就为了弄清楚evaluation阶段为什么训练结果那么差,不是用的训练数据预测的么,按理说就是重复了训练中的结果而已,说实话,在这里用train_data来做evaluation本身就是没有意义的,我这么做只是为了得到训练结果的ROC、accuracy、F1-score、recall、precision等指标和图表,帮助自己和读者更好理解训练的过程。这个结果,我个人猜测是之前只是在训练阶段对y进行转换,而在evaluation阶段,y仍然是int型,并不是ont-hot类型,这样得到的结果自然是不正确的了。
那么该如何解决呢?那就是在conf.json中的evaluation_0中添加eval_type="multi",但是注意不要像我一样菜,把evaluation_0写成了evalution_0,属于是贻笑大方了,关键是json还不报错,因为它只根据指定的标签进行判断,错误标签直接忽略…,又是三天的功夫耽搁了,淦!
4.4 训练集评估
那么最终的训练集合评估的文件编写如下,dsl文件不用变换,只用修改conf文件,如下:
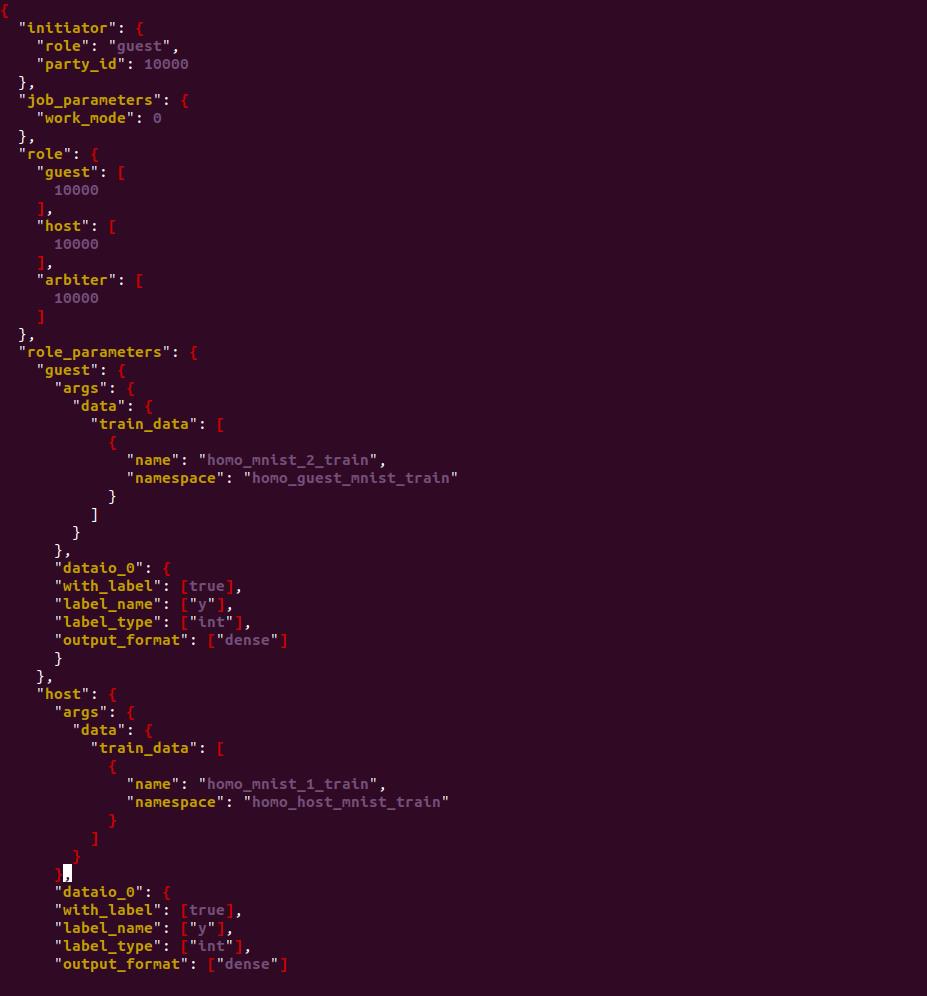

其中data_io可以不写,因为模型默认的配置也是这样的。让我们看看模型训练效果:
 准确率达到93.4%,符合训练时的预期。
准确率达到93.4%,符合训练时的预期。
5. 模型评估
常用的模型评估方法包括留出法和交叉验证法。
- 留出法:将数据按照一定比例切分,预留一部分数据作为评估模型数据。
- 交叉验证法: 将数据集D切分为k份,D1,D2,…,Dk,这样可以获得k组不同的训练数据集和评估数据集,得到k个评估的结果,取其平均值作为最终模型评估结果。
由于之前已经有了额外的数据集作为评估数据集,这里用留出法。为了将留出的数据用于模型评估,需要修改dsl和conf配置文件。
- dsl文件:
在先前训练所用的homo_dense_dsl.conf文件基础上,新建homo_dense_train_and_predict_dsl.conf文件,在components组件下添加一个新的数据输入组件dataio_1,用来读取测试数据,如下所示。
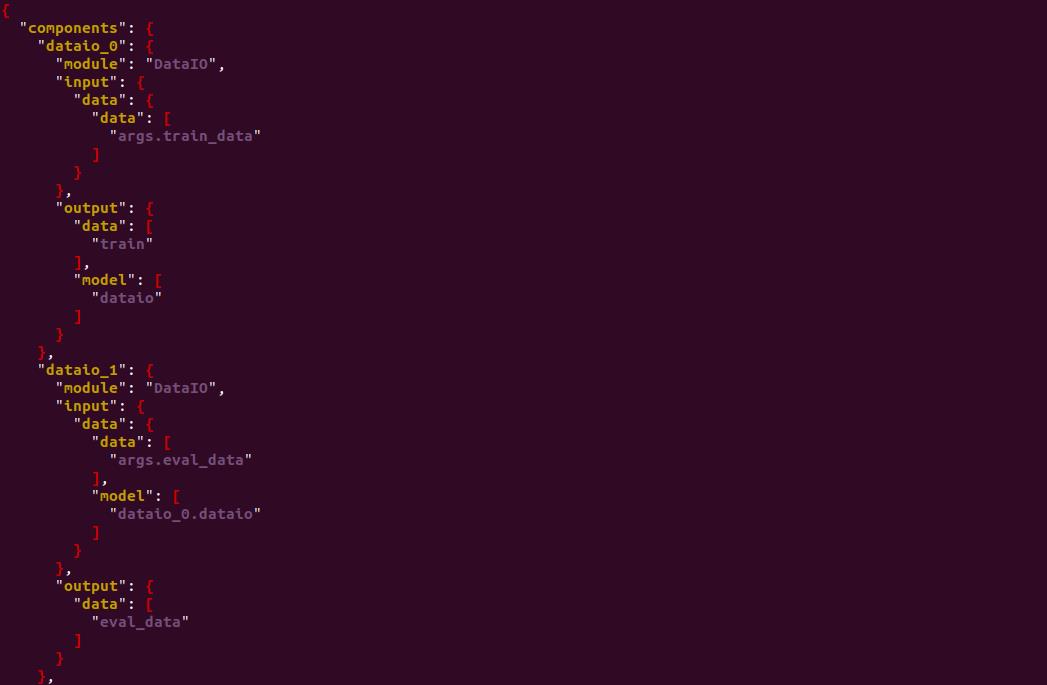
增加模型训练模块,输入为datai0_1处理的测试数据集和训练模块homo_nn_0输出的模型,直接用训练好的模型参数预测测试数据集,思路清晰,这样的预测结果才真正体现模型的泛化能力。
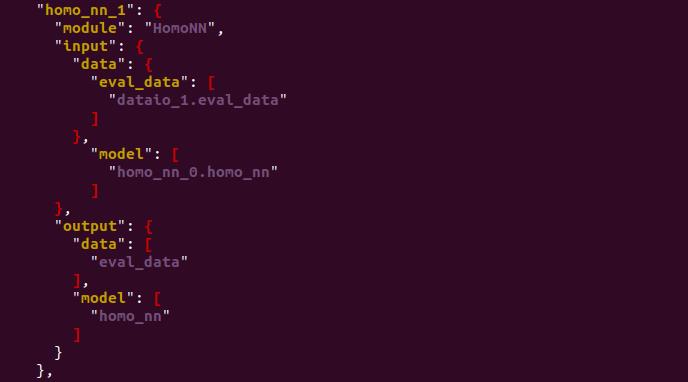
- conf文件:
conf文件中加入测试数据集,如下所示:
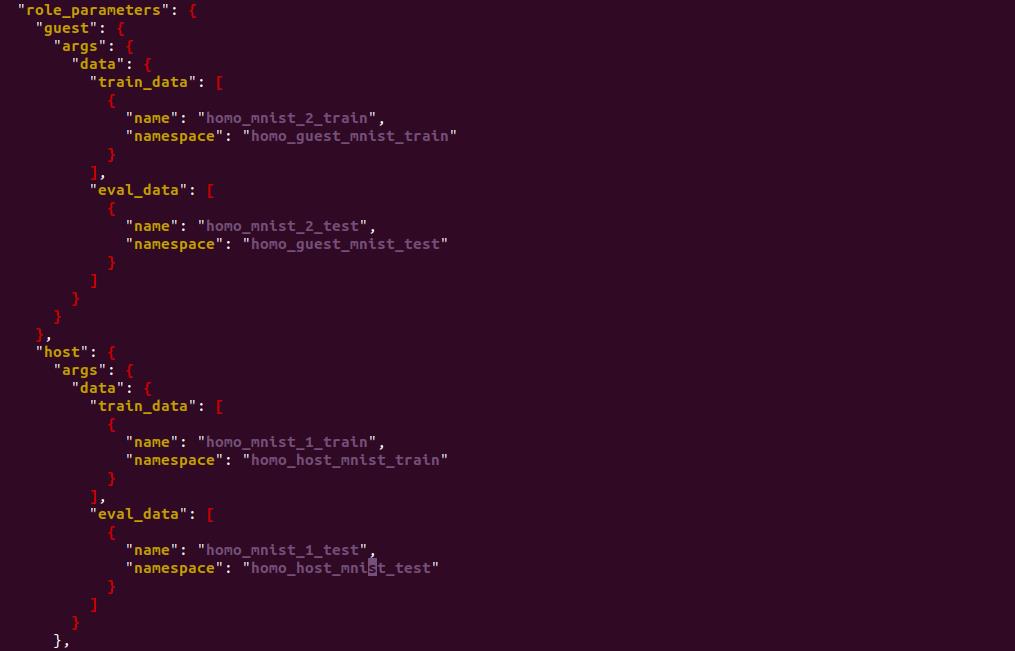
增加了eval_data,这样就能得到训练+预测的模型。执行如下提交:
python /fate/python/fate_flow/fate_flow_client.py -f submit_job -c homo_dense_train_and_predict_conf.json -d homo_dense_train_and_predict_dsl.json
但是,一个离谱的错误又折磨了我一周的时间,先把训练组件图贴上,如下所示:
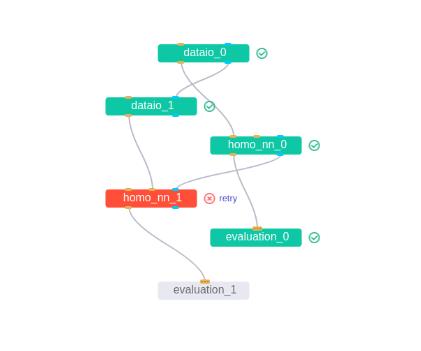
在homo_nn_1阶段竟然出错了!查看错误信息:
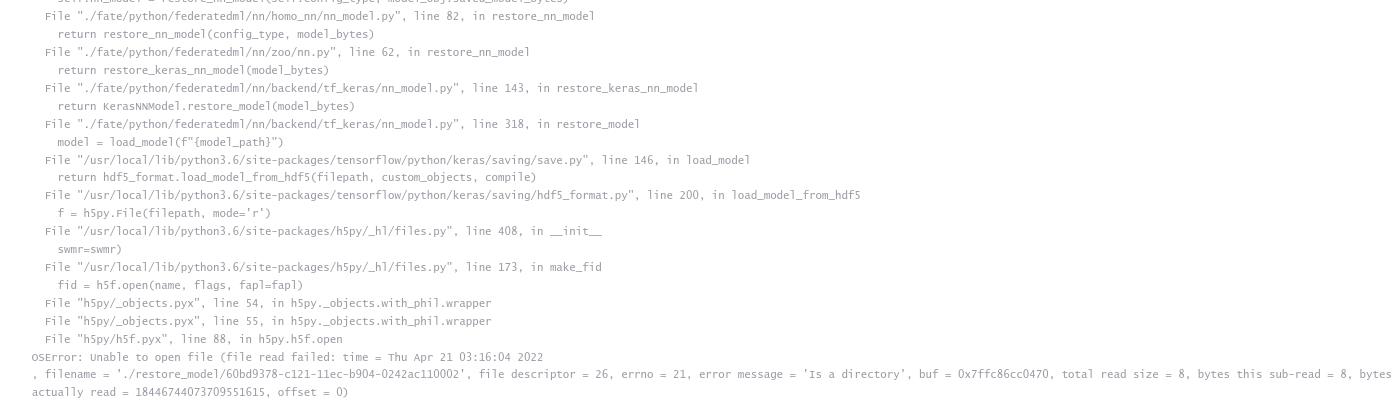
错误信息是‘Is a Directory’,属于OS错误,也就是训练出的模型不能够打开,那自然无法进行下一步的预测了,我人是彻底晕了,查阅了大量资料,奔波于多个社区论坛,依然是一无所获。
6. 实战总结
历经半个月的MNIST手写数字识别——全连接神经网络实战总算落幕,从数据集预处理到上传到FATE的DTable,从编写dsl和conf文件进行模型的训练到模型的预测,算是比较完善的项目了,虽然在预测部分的问题一直没能解决,即泛化性能无法评估,姑且拿训练数据集作为测试集进行预测,相较于其他相关博客也算是有所突破吧,如果对预测阶段问题有所了解的伙伴欢迎评论或私信我,万分感谢!
参考链接
https://blog.csdn.net/WenDong1997/article/details/106744078
https://blog.csdn.net/ysk2931/article/details/120892654
https://blog.csdn.net/WenDong1997/article/details/106946754/
以上是关于联邦学习实战基于FATE框架的MNIST手写数字识别——全连接神经网络的主要内容,如果未能解决你的问题,请参考以下文章